Multi Modality Arena
1.0.0
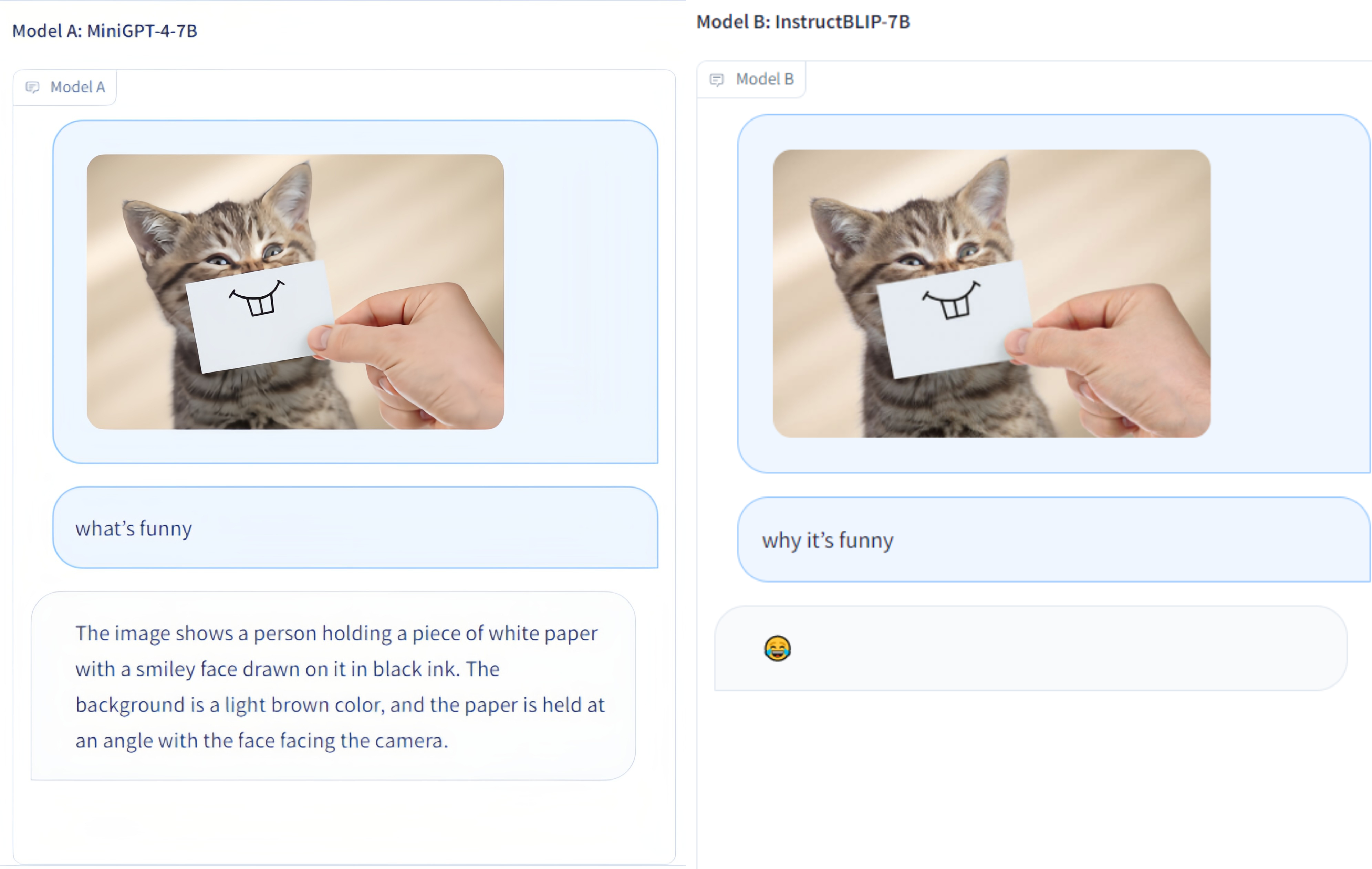
Multi-Modality Arena est une plateforme d'évaluation pour les grands modèles multimodaux. Après Fastchat, deux modèles anonymes côte à côte sont comparés dans le cadre d'une tâche de réponse visuelle à des questions. Nous publions la démo et saluons la participation de tous à cette initiative d'évaluation.
Ensemble de données OmniMedVQA : contient 118 010 images avec 127 995 éléments d’assurance qualité, couvrant 12 modalités différentes et faisant référence à plus de 20 régions anatomiques humaines. L'ensemble de données peut être téléchargé à partir d'ici.
12 modèles : 8 LVLM généralistes et 4 LVLM médico-spécialisés.
Petits ensembles de données : seulement 50 échantillons sélectionnés au hasard pour chaque ensemble de données, soit 42 repères visuels liés au texte et 2,1 000 échantillons au total pour une utilisation facile.
Plus de modèles : 4 autres modèles, soit 12 modèles au total, dont Google Bard .
ChatGPT Ensemble Evaluation : meilleur accord avec l'évaluation humaine que l'approche précédente de correspondance de mots.
LVLM-eHub est une référence d'évaluation complète pour les grands modèles multimodaux (LVLM) accessibles au public. Il évalue de manière approfondie
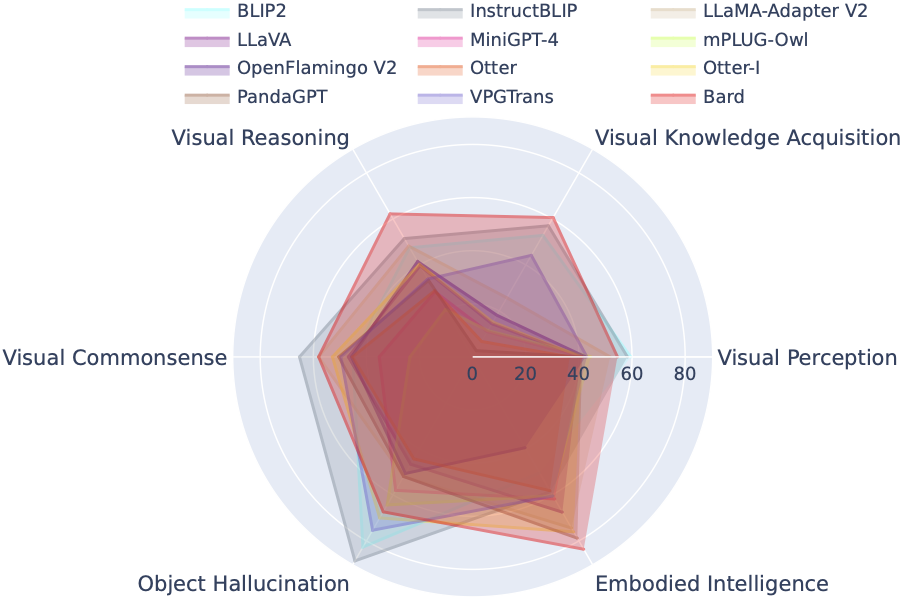
Le classement LVLM classe systématiquement les ensembles de données présentés dans l'évaluation Tiny LVLM en fonction de leurs capacités spécifiques ciblées, notamment la perception visuelle, le raisonnement visuel, le bon sens visuel, l'acquisition de connaissances visuelles et l'hallucination d'objets. Ce classement comprend des modèles récemment publiés pour renforcer son exhaustivité.
Vous pouvez télécharger le benchmark à partir d'ici, et plus de détails peuvent être trouvés ici.
| Rang | Modèle | Version | Score |
|---|---|---|---|
| 1 | StagiaireVL | InternVL-Chat | 327.61 |
| 2 | StagiaireLM-XComposer-VL | StagiaireLM-XComposer-VL-7B | 322.51 |
| 3 | Barde | Barde | 319,59 |
| 4 | Qwen-VL-Chat | Qwen-VL-Chat | 316.81 |
| 5 | LLaVA-1.5 | Vigogne-7B | 307.17 |
| 6 | InstruireBLIP | Vigogne-7B | 300,64 |
| 7 | StagiaireLM-XComposer | StagiaireLM-XComposer-7B | 288,89 |
| 8 | BLIP2 | FlanT5xl | 284,72 |
| 9 | BLIVA | Vigogne-7B | 284.17 |
| 10 | Lynx | Vigogne-7B | 279.24 |
| 11 | Guépard | Vigogne-7B | 258,91 |
| 12 | LLaMA-Adaptateur-v2 | LLaMA-7B | 229.16 |
| 13 | VPGTrans | Vigogne-7B | 218.91 |
| 14 | Image de loutre | Loutre-9B-LA-InContext | 216.43 |
| 15 | VisuelGLM-6B | VisuelGLM-6B | 211,98 |
| 16 | mPLUG-Chouette | LLaMA-7B | 209.40 |
| 17 | LLaVA | Vigogne-7B | 200,93 |
| 18 | MiniGPT-4 | Vigogne-7B | 192,62 |
| 19 | Loutre | Loutre-9B | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176.37 |
| 21 | PandaGPT | Vigogne-7B | 174.25 |
| 22 | LaVIN | LLaMA-7B | 97.51 |
| 23 | MICRO | FlanT5xl | 94.09 |
31 mars 2024. Nous publions OmniMedVQA, un référentiel d'évaluation complet à grande échelle pour les LVLM médicaux. Parallèlement, nous disposons de 8 LVLM généralistes et de 4 LVLM médicaux spécialisés. Pour plus de détails, veuillez visiter le MedicalEval.
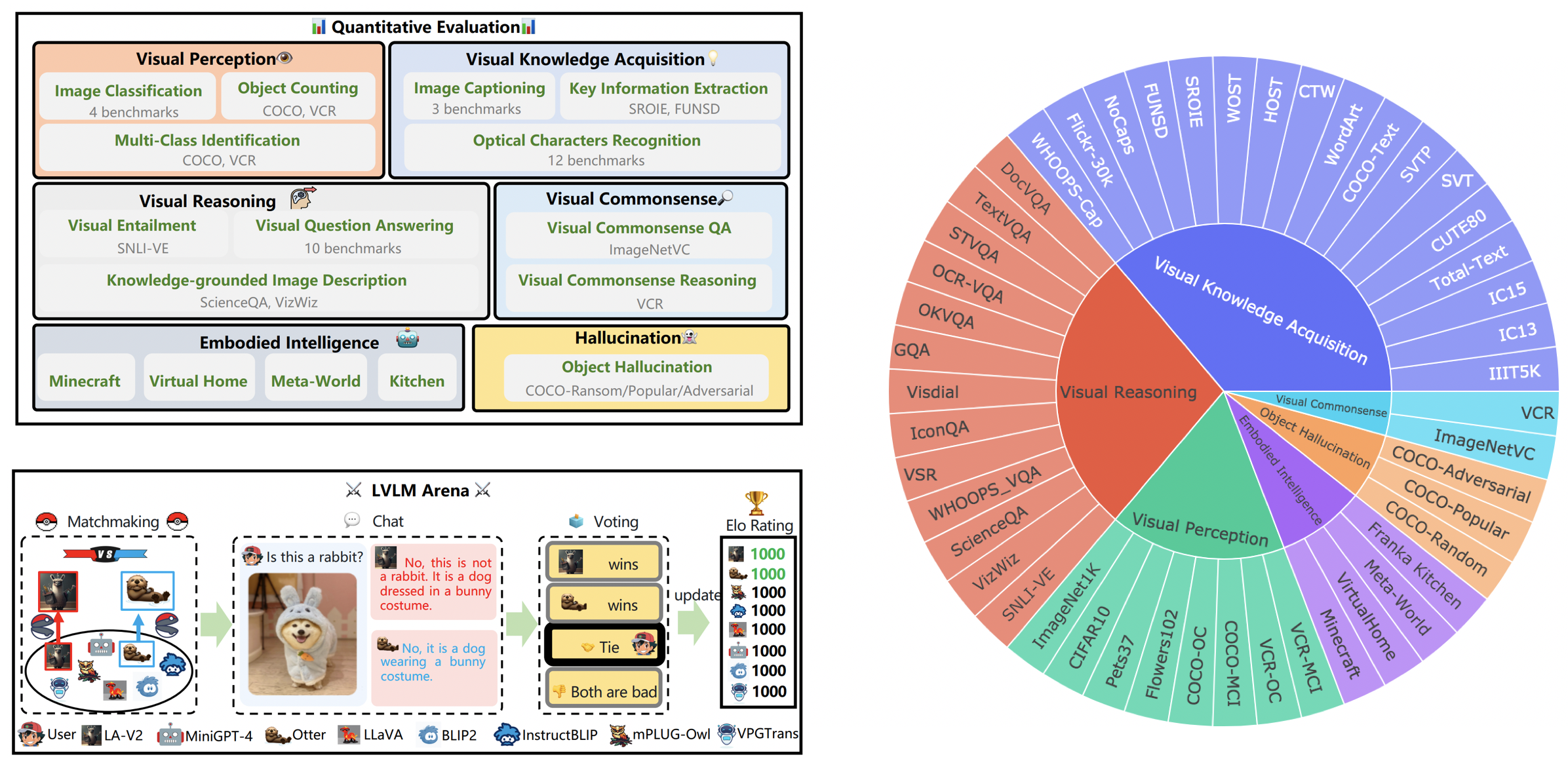
16 octobre 2023. Nous présentons un ensemble de données au niveau des capacités dérivé du LVLM-eHub, complété par l'inclusion de huit modèles récemment publiés. Pour accéder aux répartitions des ensembles de données, au code d'évaluation, aux résultats d'inférence du modèle et aux tableaux de performances complets, veuillez visiter tiny_lvlm_evaluation ✅.
8 août 2023. Nous avons publié [Tiny LVLM-eHub] . Les codes sources d'évaluation et les résultats d'inférence de modèle sont open source sous tiny_lvlm_evaluation.
15 juin 2023. Nous publions [LVLM-eHub] , une référence d'évaluation pour les grands modèles de langage de vision. Le code arrive bientôt.
8 juin 2023. Merci, Dr Zhang, l'auteur de VPGTrans, pour ses corrections. Les auteurs de VPGTrans viennent principalement de la NUS et de l’Université Tsinghua. Nous avons déjà rencontré quelques problèmes mineurs lors de la réimplémentation de VPGTrans, mais nous avons constaté que ses performances sont en réalité meilleures. Pour plus d'auteurs de modèles, veuillez me contacter pour en discuter par e-mail. Veuillez également suivre notre liste de classement des modèles, où des résultats plus précis seront disponibles.
Peut. 22, 2023. Merci, Dr Ye, l'auteur de mPLUG-Owl, pour ses corrections. Nous corrigeons quelques problèmes mineurs dans notre implémentation de mPLIG-Owl.
Les modèles suivants participent actuellement à des batailles aléatoires,
KAUST/MiniGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
DAMO Academy/mPLUG-Chouette
NTU/Loutre
Université du Wisconsin-Madison/LLaVA
Laboratoire d'IA de Shanghai/llama_adapter_v2
NUS/VPGTrans
Plus de détails sur ces modèles peuvent être trouvés sur ./model_detail/.model.jpg . Nous essaierons de planifier les ressources informatiques pour héberger davantage de modèles multimodaux dans l'arène.
Si vous êtes intéressé par des éléments de notre plateforme VLarena, n'hésitez pas à rejoindre le groupe Wechat.

Créer un environnement conda
conda create -n arène python=3.10 conda activer l'arène
Installer les packages requis pour exécuter le contrôleur et le serveur
pip installer numpy gradio uvicorn fastapi
Ensuite, pour chaque modèle, ils peuvent nécessiter des versions conflictuelles des packages python, nous vous recommandons de créer un environnement spécifique pour chaque modèle en fonction de leur dépôt GitHub.
Pour utiliser l'interface utilisateur Web, vous avez besoin de trois composants principaux : des serveurs Web qui s'interfacent avec les utilisateurs, des travailleurs de modèles qui hébergent deux modèles ou plus, et un contrôleur pour coordonner le serveur Web et les travailleurs de modèles.
Voici les commandes à suivre dans votre terminal :
contrôleur python.py
Ce contrôleur gère les travailleurs distribués.
python model_worker.py --model-name SELECTED_MODEL --device TARGET_DEVICE
Attendez que le processus ait fini de charger le modèle et que vous voyiez "Uvicorn fonctionnant sur...". Le travailleur modèle s'enregistrera auprès du contrôleur. Pour chaque travailleur modèle, vous devez spécifier le modèle et l'appareil que vous souhaitez utiliser.
python serveur_demo.py
Il s'agit de l'interface utilisateur avec laquelle les utilisateurs interagiront.
En suivant ces étapes, vous pourrez diffuser vos modèles à l'aide de l'interface utilisateur Web. Vous pouvez ouvrir votre navigateur et discuter avec un modèle maintenant. Si les modèles n'apparaissent pas, essayez de redémarrer le serveur Web Gradio.
Nous apprécions profondément toutes les contributions visant à améliorer la qualité de nos évaluations. Cette section comprend deux segments clés : Contributions to LVLM Evaluation et Contributions to LVLM Arena .
Vous pouvez accéder à la version la plus récente de notre code d'évaluation dans le dossier LVLM_evaluation. Ce répertoire comprend un ensemble complet de codes d'évaluation, accompagné des ensembles de données nécessaires. Si vous souhaitez participer au processus d'évaluation, n'hésitez pas à partager les résultats de votre évaluation ou l'API d'inférence de modèle avec nous par e-mail à [email protected].
Nous vous remercions de l'intérêt que vous portez à l'intégration de votre modèle dans notre LVLM Arena ! Si vous souhaitez intégrer votre modèle dans notre Arena, veuillez préparer un modèle de test structuré comme suit :
class ModelTester:def __init__(self, device=None) -> None:# TODO : initialisation du modèle et des pré-processeurs requisdef move_to_device(self, device) -> None:# TODO : cette fonction est utilisée pour transférer le modèle entre le CPU et GPU (facultatif)def generate(self, image, question) -> str : # TODO : code d'inférence de modèle
De plus, nous sommes ouverts aux liens d'inférence de modèles en ligne, tels que ceux fournis par des plateformes comme Gradio. Vos contributions sont sincèrement appréciées.
Nous exprimons notre gratitude à l'équipe estimée de ChatBot Arena et à leur article Judging LLM-as-a-judge pour leur travail influent, qui a servi d'inspiration pour nos efforts d'évaluation LVLM. Nous souhaitons également exprimer notre sincère gratitude aux fournisseurs de LVLM, dont les précieuses contributions ont contribué de manière significative au progrès et à l'avancement des modèles de langage de vision à grande échelle. Enfin, nous remercions les fournisseurs d'ensembles de données utilisés dans notre LVLM-eHub.
Le projet est un outil de recherche expérimentale à des fins non commerciales uniquement. Il dispose de garanties limitées et peut générer du contenu inapproprié. Il ne peut pas être utilisé à des fins illégales, nuisibles, violentes, racistes ou sexuelles.


