mind x
1.0.0

Ce projet démontre la faisabilité des LLM (ou LMM) personnalisés en tant qu'assistants personnels, en phase avec la croissance rapide de ces modèles.
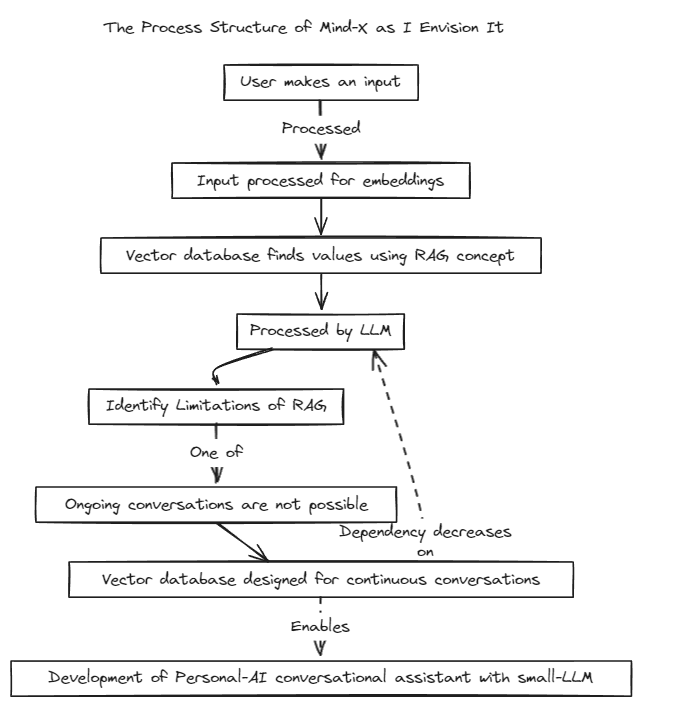
Nous avons introduit une méthode de génération augmentée de récupération (RAG) pour surmonter les limites du réglage d'invite traditionnel, qui a des limites de contexte, et du réglage fin, qui souffre de problèmes de mises à jour de données en temps réel et d'hallucinations.
Traditionnellement, RAG a été utilisé pour rechercher des bases de données comme Chroma via LangChain en tant que magasin, mais cette méthode fonctionne dans des contextes fixes, ce qui est limitant.
Par conséquent, nous prévoyons de construire notre propre système RAG. Ce processus peut impliquer de résoudre les problèmes d'inférence et de régression que LangChain pourrait offrir.
Nous nous engageons à un développement rapide et permettra bientôt une compatibilité multilingue. Actuellement, le système prend entièrement en charge l'anglais, et il est prévu de prendre prochainement en charge le coréen, le japonais et d'autres langues. De plus, des systèmes de régression et d’inférence seront également bientôt intégrés.
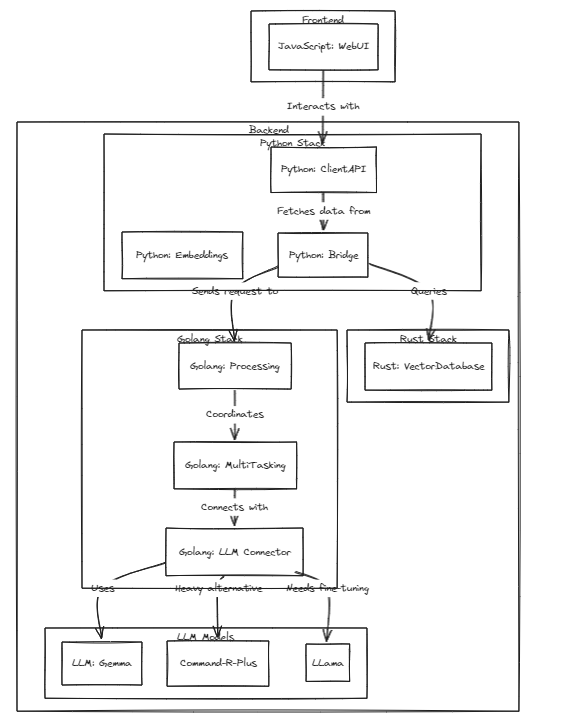
Pour exécuter des tests, exécutez la commande suivante
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
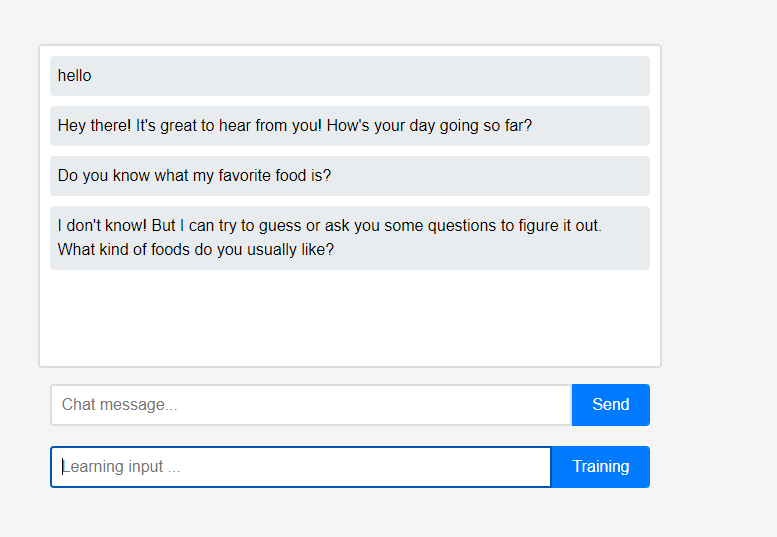 Au départ, l'assistant ne sait rien de l'utilisateur.
Au départ, l'assistant ne sait rien de l'utilisateur.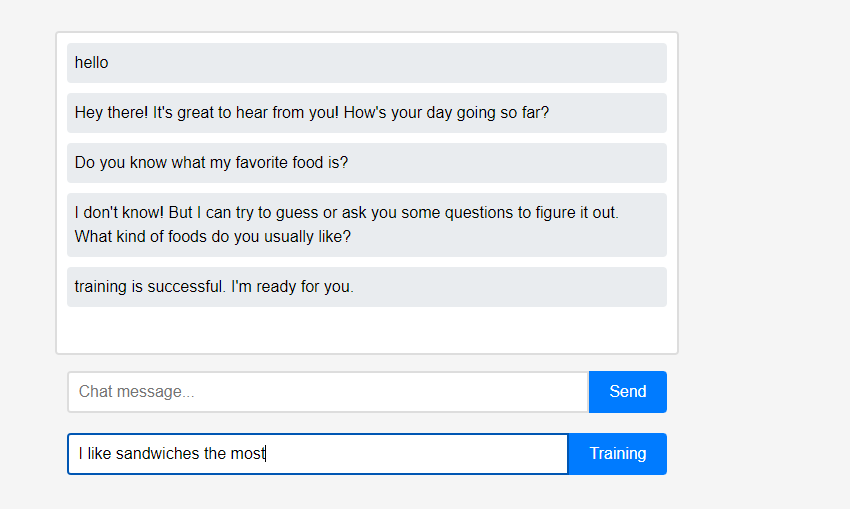 Cependant, les utilisateurs peuvent renseigner l’assistant sur eux-mêmes en temps réel.
Cependant, les utilisateurs peuvent renseigner l’assistant sur eux-mêmes en temps réel.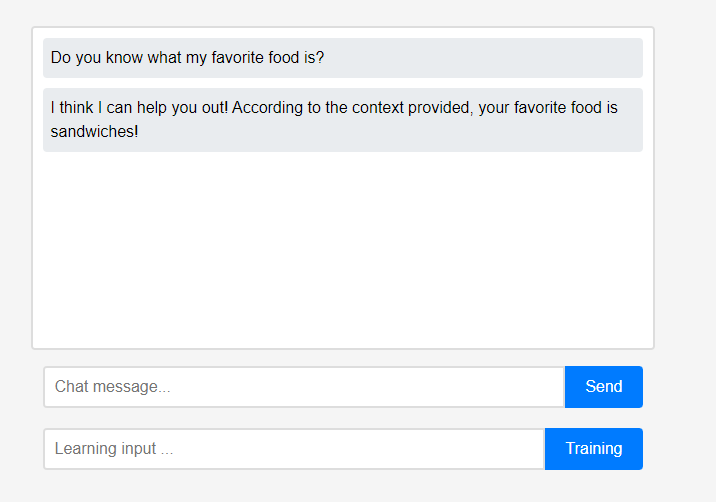 (En raison des caractéristiques du LLM, on pourrait mal comprendre qu'il a été mémorisé comme une chaîne de conversation plutôt que comme un apprentissage, donc cela a été fait après actualisation.) Les données apprises ont été immédiatement reflétées, et cela peut être considéré comme la première personnalisation de l'assistant.
(En raison des caractéristiques du LLM, on pourrait mal comprendre qu'il a été mémorisé comme une chaîne de conversation plutôt que comme un apprentissage, donc cela a été fait après actualisation.) Les données apprises ont été immédiatement reflétées, et cela peut être considéré comme la première personnalisation de l'assistant.
Toutes ces fonctionnalités du projet peuvent être prises en charge localement sans avoir besoin d'une intégration cloud externe ou d'une connexion Internet.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


