Sound Content Music Recommendation System
1.0.0

Si vous êtes comme moi, vous aimez la musique. J'aime la musique et j'aime découvrir de la nouvelle musique. Spotify est l'un des meilleurs services de streaming de musique sur Internet et il comprend déjà des outils incroyables qui vous aident à découvrir de nouvelles musiques en fonction de ce que vous écoutez. Pour ce faire, il combine différents algorithmes, notamment un filtrage collaboratif où une utilisation similaire entre les utilisateurs est suivie et utilisée pour générer des recommandations ou des recommandations basées sur le contenu qui recommandent de nouvelles chansons sur la base d'informations similaires entre les informations liées à une chanson. Comme une chanson ? Sur Spotify, vous pouvez écouter la « radio » de cette chanson, qui rassemblera un groupe de chansons similaires à cette chanson d'une manière ou d'une combinaison de façons. Que se passe-t-il si vous aimez une chanson, mais que vous ne vous souciez d'aucune information autre que le son qu'elle contient ? Parfois, c'est tout ce que je veux entendre.
J'ai créé ce projet pour créer un système de recommandation musicale basé uniquement sur les informations contenues dans le son de la musique. Cela aidera un utilisateur à trouver de la nouvelle musique à travers des chansons au son similaire. Pour ce faire, il explorera également les similitudes entre toutes les musiques et tentera de capturer mathématiquement le timbre, le rythme et le style d’une chanson.
Le son est toujours autour de nous. Tout au long de notre vie, nous apprenons à discerner des sons différents de ceux des autres. La musique n'est pas différente : il existe de nombreux types de musique et la musique est souvent une combinaison de nombreux types de sons et de rythmes différents que nous pouvons également distinguer des autres. Mais pouvons-nous quantifier cette information par nous-mêmes ? Parfois, la musique est classée en genres, ce qui signifie qu'un genre est un groupe de musiciens ayant des qualités similaires en termes de style, de forme, de rythme, de timbre, d'instruments ou de culture. Mais tous les artistes musicaux ne créent pas du son dans le même genre, et tous les genres ne contiennent pas le même genre de musique. Alors, qu’est-ce que le son et comment discerner différents types de sons ?
Le son est une vibration d'ondes acoustiques que nous percevons à travers nos oreilles lorsque ces ondes font vibrer nos tympans. Une onde sonore est un signal et la vitesse à laquelle ce signal vibre est appelée fréquence. Si une fréquence sonore est plus élevée, nous percevons que ce son a une hauteur plus élevée. En musique, des instruments comme la basse ou la grosse caisse créeront des sons qui vibrent à une fréquence plus basse, tandis que les aigus ont une fréquence plus élevée. On dirait que le choc d'une cymbale ou d'un chapeau haut de forme est une combinaison de nombreuses ondes à différentes fréquences et est représenté par une onde « bruyante », d'apparence presque aléatoire.
A quoi ressemble le son ? Une façon de visualiser le son consiste à tracer un signal dans le temps :
À mesure que nous raccourcissons la fenêtre de temps sur chaque sous-intrigue, nous pouvons voir le signal audio de beaucoup plus près. Remarquez que dans l'image la plus agrandie du signal, l'onde est une collection de fréquences différentes. Il peut y avoir un signal basse fréquence qui se combine avec des signaux haute fréquence plus petits.
Nous pouvons donc visualiser un signal au fil du temps, mais nous pouvons déjà dire qu’il est difficile de comprendre grand-chose de cette onde sonore simplement en regardant cette visualisation. Quels types de fréquences sont présents dans cette fenêtre de 0,01 seconde ? Pour répondre à cela, nous utiliserons une transformée de Fourier pour calculer un spectrogramme.
La transformée de Fourier est une méthode de calcul de l'amplitude des fréquences présentes dans une section d'un signal audio. Comme vous pouvez le voir sur le graphique ci-dessus, les ondes peuvent être complexes et chaque variation du signal représente une fréquence différente (la vitesse de vibration). Une transformée de Fourier extraira essentiellement les fréquences pour chaque tranche de temps et produira un tableau bidimensionnel d'amplitudes de fréquence en fonction du temps. Le produit d'une transformée de Fourier est un spectrogramme. À partir du spectrogramme, nous convertissons les fréquences produites à l’échelle Mel pour créer un spectrogramme Mel. Le spectrogramme Mel représente mieux la distance perçue entre les fréquences telles que nous les entendons.
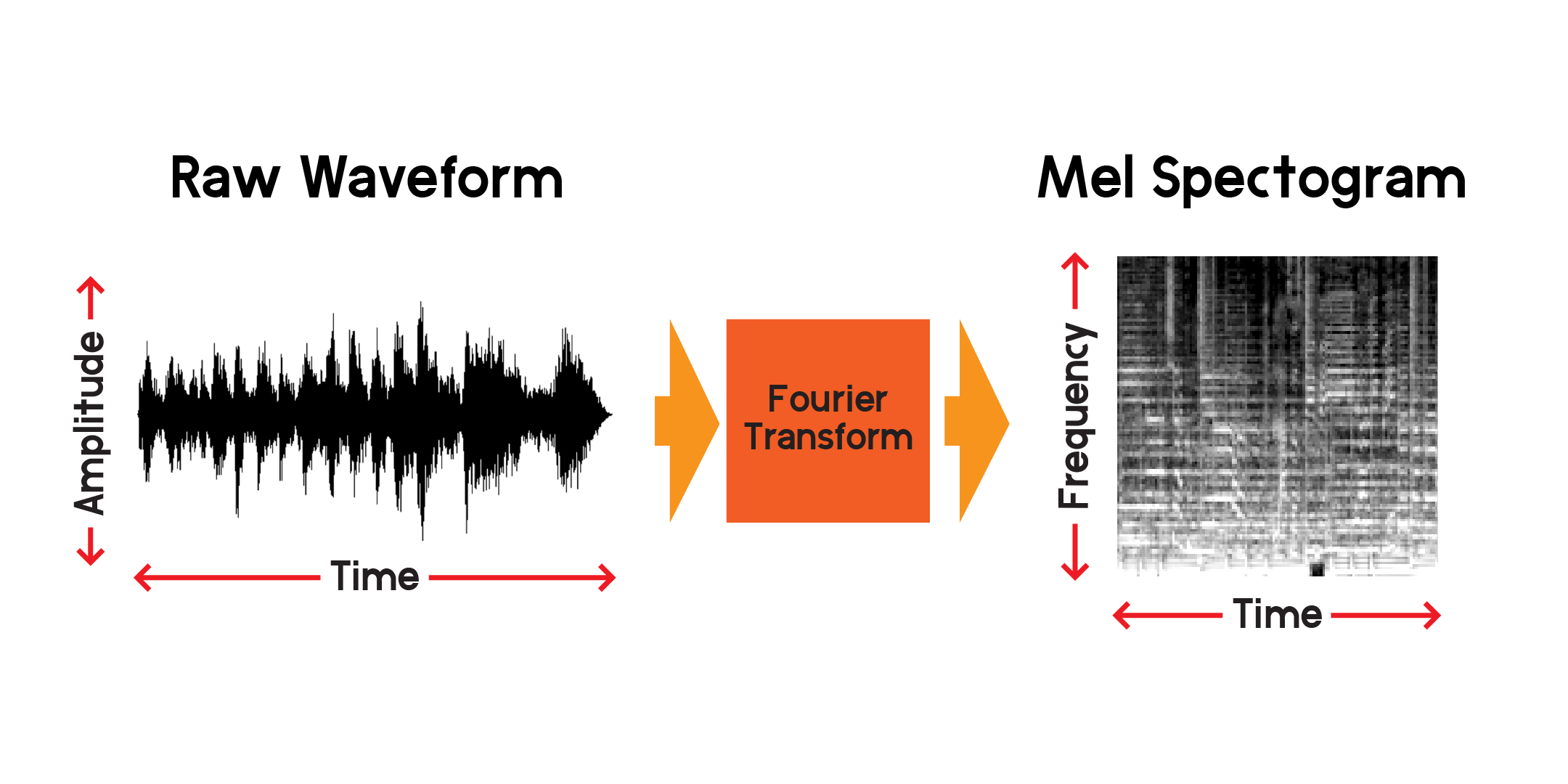
Traçons un exemple de spectrogramme mel à partir du même échantillon audio que nous avons tracé ci-dessus :
À l'aide de l'API publique de Spotify, j'ai récupéré les informations sur les chansons dans un bloc-notes précédent. À partir de là, je peux télécharger un aperçu mp3 de 30 secondes de chaque chanson et le convertir en un spectrogramme Mel à utiliser dans un réseau neuronal qui s'entraîne sur des images. Tout d’abord, jetons un coup d’œil au bloc de données que nous utiliserons pour collecter les aperçus mp3.
Dans un autre cahier, j'ai pris des liens d'aperçu de l'API Spotify, téléchargé les mp3 et converti les fichiers audio en une image composite contenant le spectrogramme Mel, le coefficient cepstral de fréquence Mel et le chromagramme. J'ai créé cette image composite avec l'intention de pouvoir utiliser ces autres transformations, mais pour ce projet, je formerai uniquement le réseau neuronal sur les spectrogrammes Mel.
Pour faire des recommandations pour des chansons similaires basées uniquement sur le contenu sonore, je devrai créer des fonctionnalités qui expliquent d'une manière ou d'une autre le contenu des chansons. De plus, pour le faire rapidement, je devrai compresser les informations de chaque chanson en un ensemble de nombres plus petit que l'entrée des spectrogrammes mel.
Pour chaque fichier d'aperçu de chanson, il existe plus de 600 000 échantillons. Dans chaque spectrogramme Mel, il y a 512 x 128 pixels totalisant 65 536 pixels. Même une image 128x128 contient 16 384 pixels. Ce modèle d'encodeur automatique compressera le contenu d'une chanson en seulement 256 nombres. Une fois l’auto-encodeur suffisamment entraîné, le réseau sera capable de reconstruire une chanson à partir de ce vecteur de longueur 256 avec une perte minimale.
Un auto-encodeur est un type de réseau neuronal composé d'un encodeur et d'un décodeur . Premièrement, l’encodeur compressera les informations de l’entrée en une quantité de données beaucoup plus petite, et le décodeur reconstruira les données pour qu’elles soient aussi proches que possible de la sortie d’origine.
Un auto-encodeur est également un type particulier de réseau neuronal dans le sens où il n’est pas supervisé, même s’il ne l’est pas tout à fait. Il est auto-supervisé car il utilise ses entrées pour entraîner les sorties du modèle.
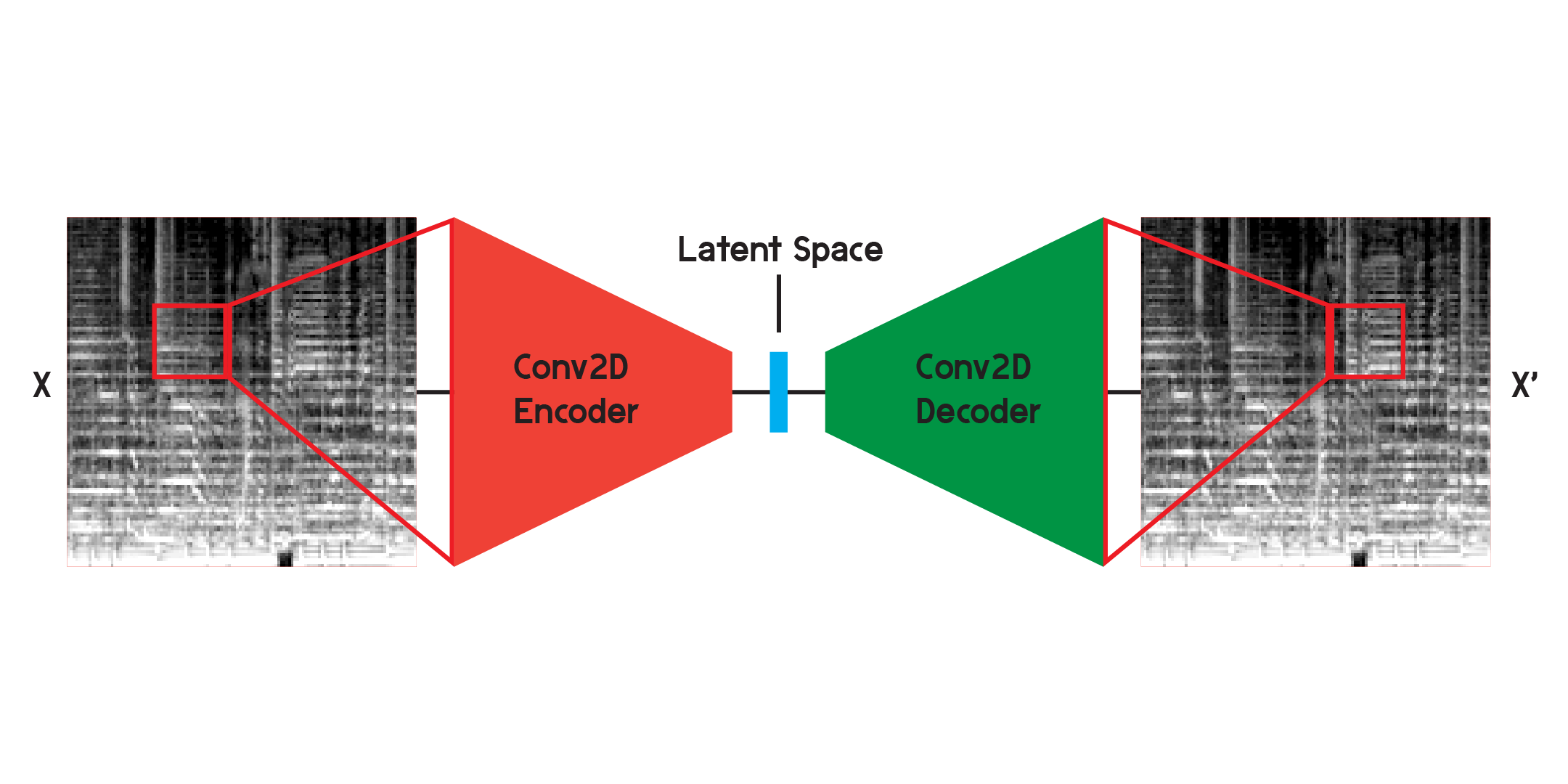
Lorsque vous travaillez avec des images, l'encodeur est une séquence de couches convolutives bidimensionnelles qui créent des filtres pondérés pour extraire des motifs dans l'image, tout en compressant l'image dans une forme de plus en plus petite. Le décodeur est le reflet miroir du processus dans l’encodeur, remodelant et développant une petite quantité de données en une plus grande. Le modèle minimise l'erreur quadratique moyenne entre l'original et la reconstruction. Une fois suffisamment entraînée, l'erreur quadratique moyenne entre l'original et la sortie du modèle sera très faible. Bien que l’erreur quadratique moyenne soit minime, il existe toujours une différence visuelle entre la reconstruction et l’image originale, notamment dans les plus petits détails. L'autoencodeur est un réducteur de bruit. Nous voulons extraire autant de détails que possible, mais en fin de compte, l'auto-encodeur mélangera également certains détails.
J'ai initialement formé le réseau en utilisant la structure illustrée ci-dessus, mais j'ai constaté que de nombreux détails manquaient dans les reconstructions. Les couches convolutives recherchent des motifs qui ne représentent qu'une petite tranche de l'image entière. Mais après entraînement et observation des filtres, il est difficile de comprendre intuitivement les modèles extraits.
Les auto-encodeurs comme ceux-ci peuvent être utilisés sur plusieurs problèmes différents, et avec les couches convolutives, il existe de nombreuses applications pour la reconnaissance et la génération d'images. Mais comme le spectrogramme Mel n'est pas seulement une image mais un graphique des fréquences du contenu sonore au fil du temps, je pense qu'une structure légèrement différente peut être mise en œuvre pour minimiser la perte lors de la reconstruction, tout en minimisant également l'incertitude créée par la convolution bidimensionnelle. couches.
Dans le modèle utilisé pour les résultats finaux du modèle, j'ai divisé l'encodeur en deux encodeurs distincts. Chaque encodeur utilise des couches convolutives unidimensionnelles pour compresser l'espace de l'image. Un encodeur s'entraîne sur X, tandis que l'autre s'entraîne sur la transposition X ou sur une version tournée à 90 degrés de l'entrée. De cette façon, un encodeur apprend les informations de l’axe temporel de l’image et l’autre apprend de l’axe des fréquences.
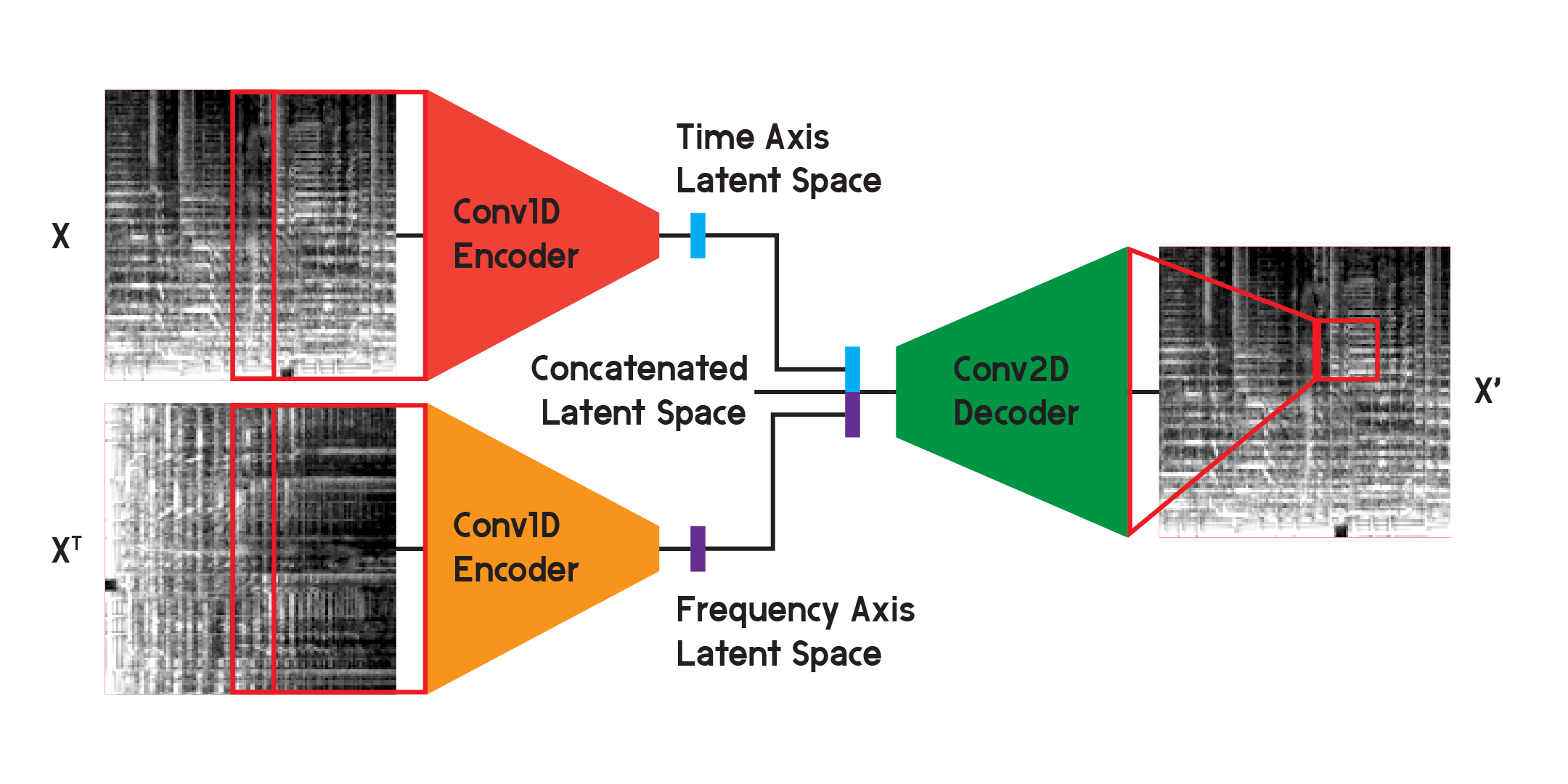
Une fois l'entrée parcourue par chaque codeur, les vecteurs codés résultants sont concaténés en un seul vecteur et entrés dans le décodeur convolutif bidimensionnel comme illustré précédemment. Les sorties sont entraînées pour minimiser la perte entre les entrées comme auparavant.
Au final, la perte dans le modèle final était bien inférieure à celle de la structure de base, atteignant une erreur quadratique moyenne de 0,0037 (entraînement) et 0,0037 (validation) après 20 époques, avec 125 440 images dans l'ensemble d'apprentissage et 2 560 dans l'ensemble d'apprentissage. ensemble de validation.
Nous allons construire le modèle ici à des fins de démonstration uniquement, car j'ai formé le modèle dans un autre cahier et je chargerai les poids du modèle formé une fois qu'il sera construit.
En utilisant une classe personnalisée pour exécuter l'inférence via le réseau et enregistrer les résultats, nous pouvons construire l'espace latent pour chaque spectrogramme mel dont nous disposons. Nous pouvons le faire en exécutant les données uniquement via l'encodeur et en recevant un vecteur de la taille avec laquelle nous avons initialisé le modèle avec, dans ce cas, 256 dimensions.
Pour explorer le paysage abstrait créé par l'espace latent des données à travers le modèle, nous pouvons utiliser la réduction de dimensionnalité. UMAP, comme T-SNE, peut réduire un espace multidimensionnel en 2 dimensions pour le visualiser dans un tracé.
La classe LatentSpace personnalisée recherchera des recommandations en utilisant la similarité cosinus pour chaque vecteur.
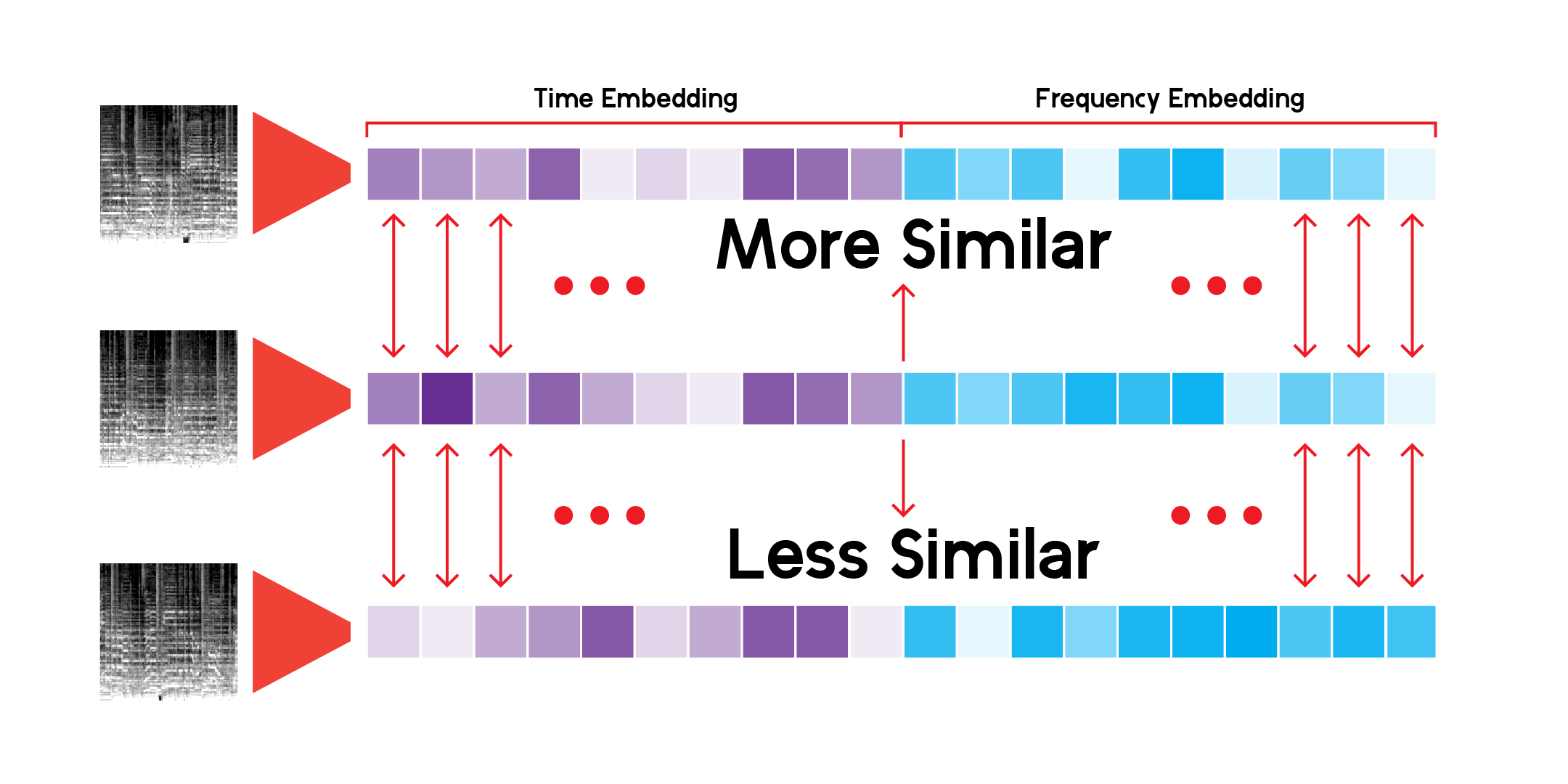
J'ai parcouru sans cesse ce système de recommandation et je suis convaincu que le modèle peut détecter des connexions très intéressantes entre des sons musicaux différents mais également similaires. Voici quelques-unes de mes conclusions :
Ce que je veux dire par là, c'est que le modèle fait des recommandations basées sur le contenu sonore de chaque chanson, mais il n'écoute pas la chanson. Il crée un spectrogramme Mel et effectue une comparaison mathématique.
Parfois, le système recommande une chanson en fonction de son âge. Si une chanson a été enregistrée il y a longtemps, ces fréquences particulières du matériel ou de l'équipement d'enregistrement seront captées par le modèle et afficheront les résultats.
De plus, le modèle est très efficace pour capter la voix ou des instruments particuliers. Pour cette raison, si une chanson contient beaucoup de paroles ou de chants-parlés, elle peut recommander uniquement des pistes de créations orales. De plus, s’il y a beaucoup de distorsion dans une chanson, cela peut suggérer des sons de pluie ou des chants d’oiseaux.
Certains aperçus de pistes ne sont pas disponibles dans l'API Spotify, comme indiqué dans mon EDA initial. Par conséquent, leur contribution au modèle est également manquante et ne constituera pas une recommandation alors qu'elle pourrait parfaitement convenir à un tel modèle. Par exemple, il n’y a aucune chanson de James Brown, des Beatles ou de Prince. A besoin de plus de données.
Le système utilise plus de 278 000 aperçus pour formuler des recommandations, et ce n’est toujours pas suffisant. En regardant la projection UMAP pour toutes les pistes, il y a une grande continuité dans les données, mais il y a quelques trous. Idéalement, le système pourrait utiliser beaucoup plus de données.
Ce qui rend un système/des services de recommandation comme Spotify si efficaces pour faire des recommandations, c'est qu'ils combinent de nombreux types différents de systèmes de recommandation et de fonctionnalités comme celui-ci pour fournir des recommandations. Du suivi de ce que vous écoutez régulièrement à l'utilisation du filtrage collaboratif pour trouver des recommandations basées sur une utilisation similaire par les utilisateurs, Spotify peut faire des prédictions beaucoup plus équilibrées sur ce que quelqu'un aimera et écoutera. Je trouve ce modèle intéressant pour faire des prédictions, mais il peut être amélioré en ajoutant plus de fonctionnalités telles que des genres similaires, des années de sortie et des données utilisateur similaires pour faire de meilleures prédictions.
Dans l’ensemble, outre les prédictions et les recommandations, je pense que la véritable importance de ce modèle réside dans l’explication de la continuité et du spectre du langage musical et du son. Les genres sont des étiquettes que les gens apposent sur un artiste ou un son, mais les genres se mélangent et chaque son existe dans cet espace continu, du moins mathématiquement.
De plus, la musique n’a pas de barrières. La plupart du temps, lorsque vous interrogez une chanson dans le système de recommandation, les résultats proviendront de toutes les époques et de tous les endroits. Puisqu’aucune des métadonnées d’une chanson n’est une entrée pour l’auto-encodeur, les résultats sont basés sur leur similarité sonore, et rien de plus.


