nlp lt
1.0.0
L'objectif principal de cette recherche est d'étudier et d'apprendre les principes du traitement du langage naturel (NLP) pour la langue lituanienne. Il est intéressant d'analyser les méthodes classiques de PNL et de voir comment elles fonctionnent. Dans ce travail, j'ai donc implémenté la classification de texte, l'extraction de sujets, les requêtes de recherche et les idées de regroupement. Les détails de mise en œuvre et d'autres informations sont stockés sur paper/paper.pdf
L'analyse des données ne peut pas être établie sans données textuelles, c'est pourquoi mon travail a commencé en obtenant des données brutes du site d'information le plus populaire www.delfi.lt. J'ai décidé d'explorer des articles de 5 catégories (Criminels[227 articles], Musique[120 articles], Films[167 articles], Sports[136 articles], Science[204 articles]).
Les performances de classification sont mesurées à l'aide d'une matrice de confusion où les lignes correspondent à la vraie catégorie et les colonnes à la catégorie prédite. De plus, une telle approche atteint plus de 90 % de rappel et 90 % de précision.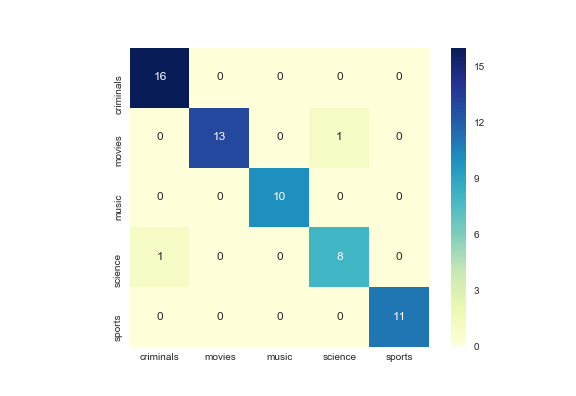
La figure montre 6 composants avec 10 jetons pour chaque composant. À partir de ces résultats, nous pouvons détecter les mots les plus importants et deviner intuitivement le sujet de chaque composant principal. Par exemple, 4 composants principaux stockent des informations sur le sport et la musique, tandis que 6 composants principaux stockent des informations sur les criminels.
Les principaux résultats sont présentés ci-dessous :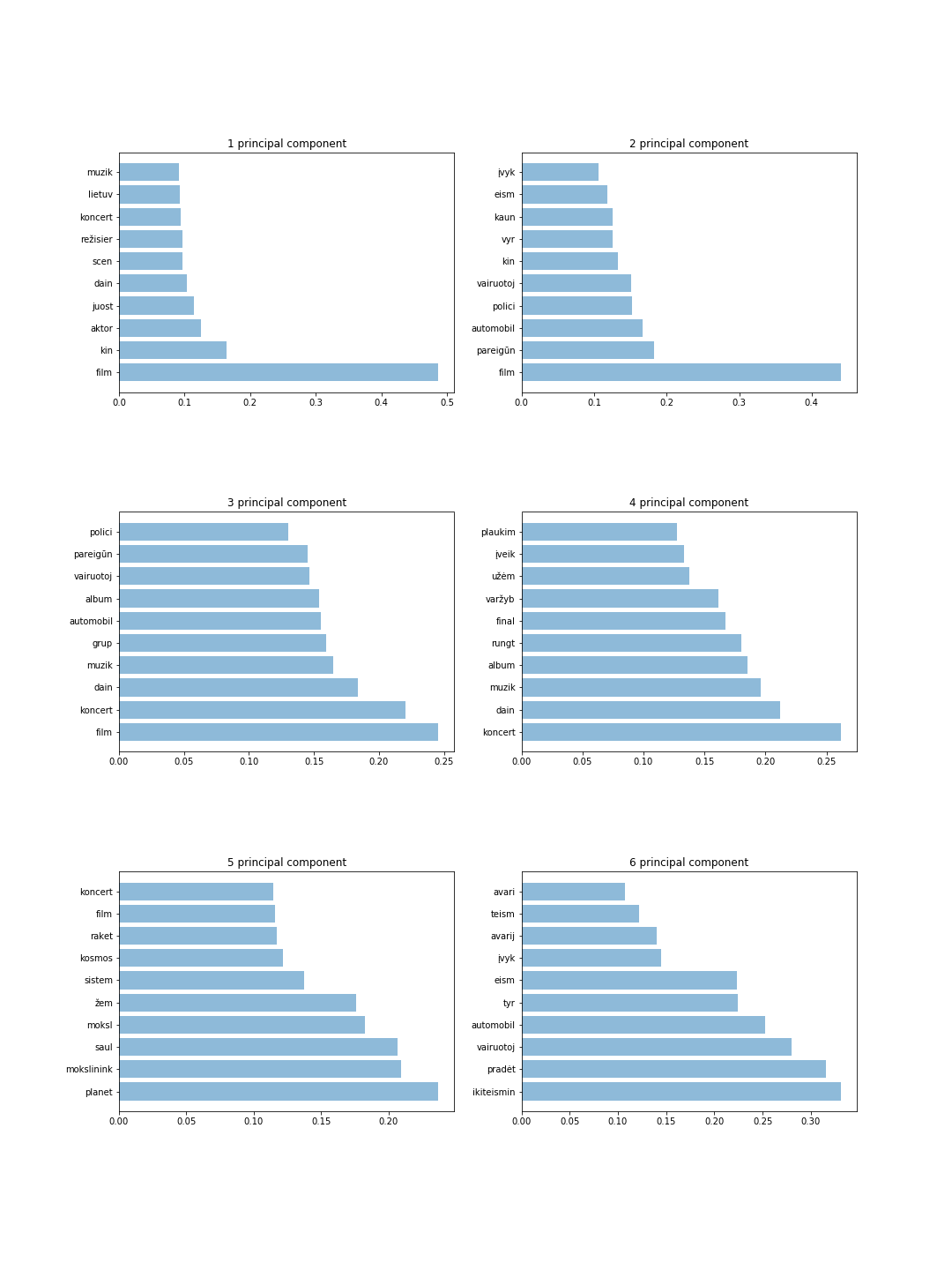
La recherche est basée sur l'article http://webhome.cs.uvic.ca/~thomo/svd.pdf, où lsa est appliqué pour trouver des documents associés en utilisant non seulement des similitudes de requête exactes, mais aussi des relations plus profondes entre les documents.
Requête = "švietim apdovanojam"
Résultat:
En cours


