system design primer
1.0.0
Anglais ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Ajouter une traduction
Aidez-nous à traduire ce guide !
Apprenez à concevoir des systèmes à grande échelle.
Préparez-vous à l’entretien de conception du système.
Apprendre à concevoir des systèmes évolutifs vous aidera à devenir un meilleur ingénieur.
La conception de systèmes est un vaste sujet. Il existe une grande quantité de ressources dispersées sur le Web sur les principes de conception de systèmes.
Ce référentiel est une collection organisée de ressources pour vous aider à apprendre à créer des systèmes à grande échelle.
Il s'agit d'un projet open source continuellement mis à jour.
Les contributions sont les bienvenues !
En plus des entretiens de codage, la conception du système est un élément obligatoire du processus d’entretien technique dans de nombreuses entreprises technologiques.
Pratiquez des questions d'entretien courantes sur la conception de systèmes et comparez vos résultats avec des exemples de solutions : discussions, code et diagrammes.
Sujets supplémentaires pour la préparation aux entretiens :
Les jeux de cartes mémoire Anki fournis utilisent une répétition espacée pour vous aider à conserver les concepts clés de conception du système.
Idéal pour une utilisation en déplacement.
Vous recherchez des ressources pour vous aider à préparer l’ entretien de codage ?
Découvrez le dépôt sœur Interactive Coding Challenges , qui contient un deck Anki supplémentaire :
Apprenez de la communauté.
N'hésitez pas à soumettre des demandes de tirage pour vous aider :
Le contenu qui a besoin d’être peaufiné est en cours de développement.
Consultez les directives de contribution.
Résumés de divers sujets de conception de systèmes, y compris les avantages et les inconvénients. Tout est un compromis .
Chaque section contient des liens vers des ressources plus approfondies.
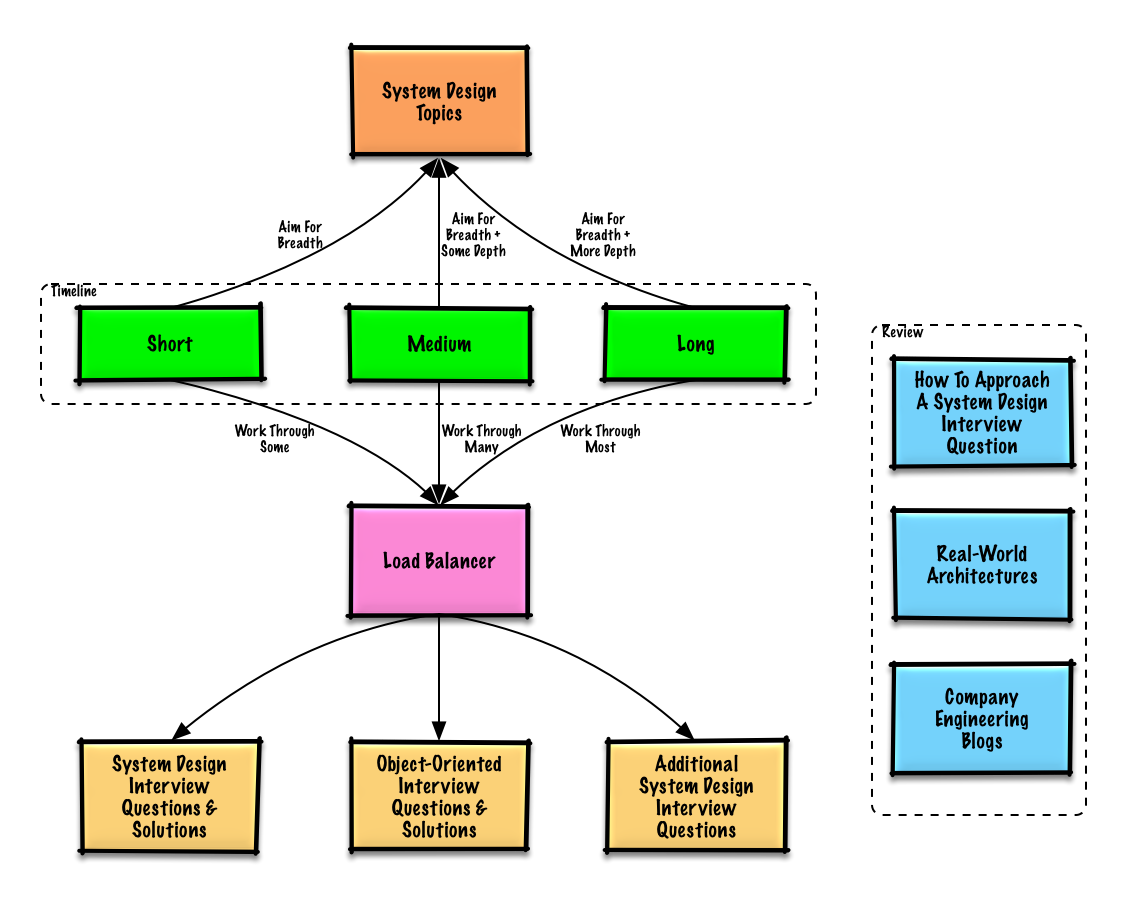
Suggestions de sujets à examiner en fonction du calendrier de votre entretien (court, moyen, long).
Q : Pour les entretiens, dois-je tout savoir ici ?
R : Non, vous n'avez pas besoin de tout savoir ici pour vous préparer à l'entretien .
Ce qui vous est demandé lors d'un entretien dépend de variables telles que :
On s’attend généralement à ce que les candidats plus expérimentés en sachent davantage sur la conception de systèmes. On peut s’attendre à ce que les architectes ou les chefs d’équipe en sachent plus que les contributeurs individuels. Les entreprises de haute technologie sont susceptibles de passer un ou plusieurs entretiens de conception.
Commencez large et approfondissez quelques domaines. Il est utile d’en savoir un peu plus sur divers sujets clés de conception de systèmes. Ajustez le guide suivant en fonction de votre calendrier, de votre expérience, des postes pour lesquels vous passez un entretien et des entreprises avec lesquelles vous passez un entretien.
| Court | Moyen | Long | |
|---|---|---|---|
| Lisez les rubriques sur la conception de systèmes pour avoir une compréhension globale du fonctionnement des systèmes. | ? | ? | ? |
| Lisez quelques articles dans les blogs d'ingénierie de l'entreprise pour les entreprises avec lesquelles vous interviewez | ? | ? | ? |
| Lisez quelques architectures du monde réel | ? | ? | ? |
| Comment aborder une question d'entretien de conception de système | ? | ? | ? |
| Répondre aux questions d'entretien de conception de système avec des solutions | Quelques | Beaucoup | La plupart |
| Travailler sur des questions d'entretien de conception orientée objet avec des solutions | Quelques | Beaucoup | La plupart |
| Examiner les questions supplémentaires d'entretien sur la conception du système | Quelques | Beaucoup | La plupart |
Comment aborder une question d'entretien de conception de système.
L'entretien de conception du système est une conversation ouverte . Vous êtes censé le diriger.
Vous pouvez utiliser les étapes suivantes pour guider la discussion. Pour aider à solidifier ce processus, parcourez la section Questions d'entretien sur la conception du système avec solutions en suivant les étapes suivantes.
Rassemblez les exigences et définissez le problème. Posez des questions pour clarifier les cas d’utilisation et les contraintes. Discutez des hypothèses.
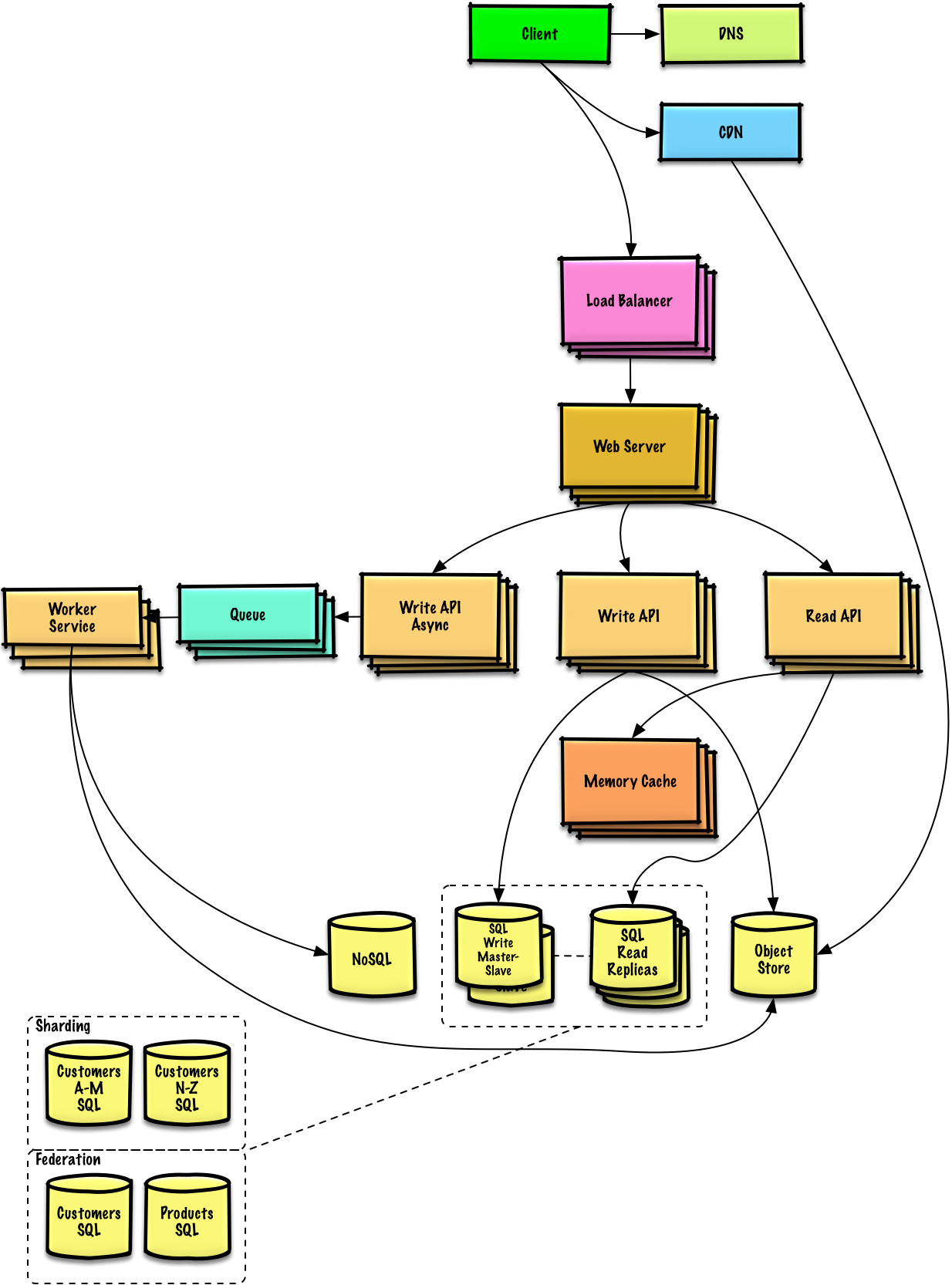
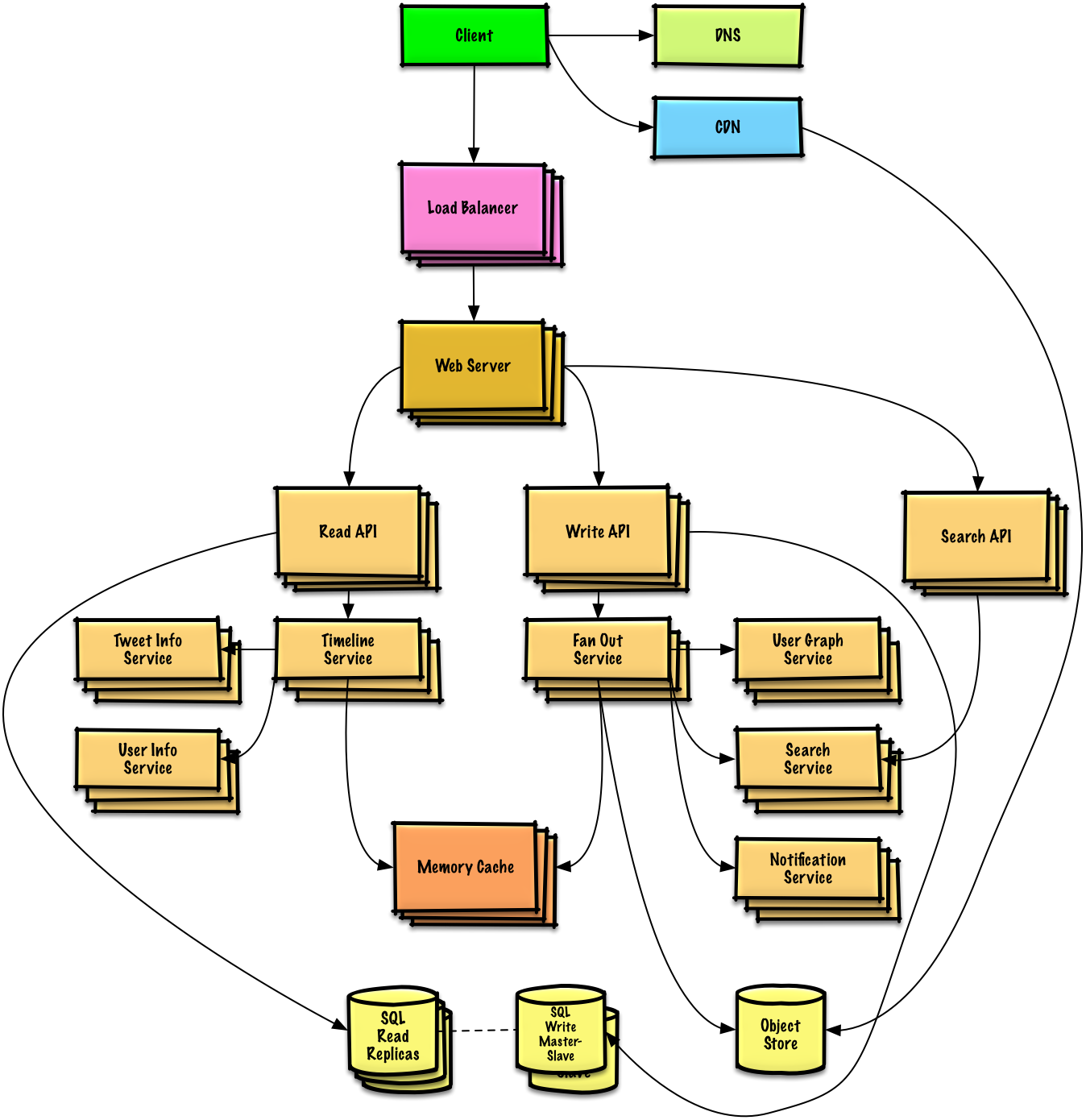
Décrivez une conception de haut niveau avec tous les composants importants.
Plongez dans les détails de chaque composant principal. Par exemple, si on vous demandait de concevoir un service de raccourcissement d’URL, discutez :
Identifiez et résolvez les goulots d’étranglement, compte tenu des contraintes. Par exemple, avez-vous besoin des éléments suivants pour résoudre les problèmes d’évolutivité ?
Discutez des solutions potentielles et des compromis. Tout est un compromis. Résolvez les goulots d’étranglement en utilisant les principes de conception de systèmes évolutifs.
On vous demandera peut-être de faire certaines estimations à la main. Reportez-vous à l'annexe pour les ressources suivantes :
Consultez les liens suivants pour avoir une meilleure idée de ce à quoi vous attendre :
Questions d'entretien communes sur la conception de systèmes avec des exemples de discussions, de code et de diagrammes.
Solutions liées au contenu du dossier
solutions/.
| Question | |
|---|---|
| Concevoir Pastebin.com (ou Bit.ly) | Solution |
| Concevoir la chronologie et la recherche Twitter (ou le flux et la recherche Facebook) | Solution |
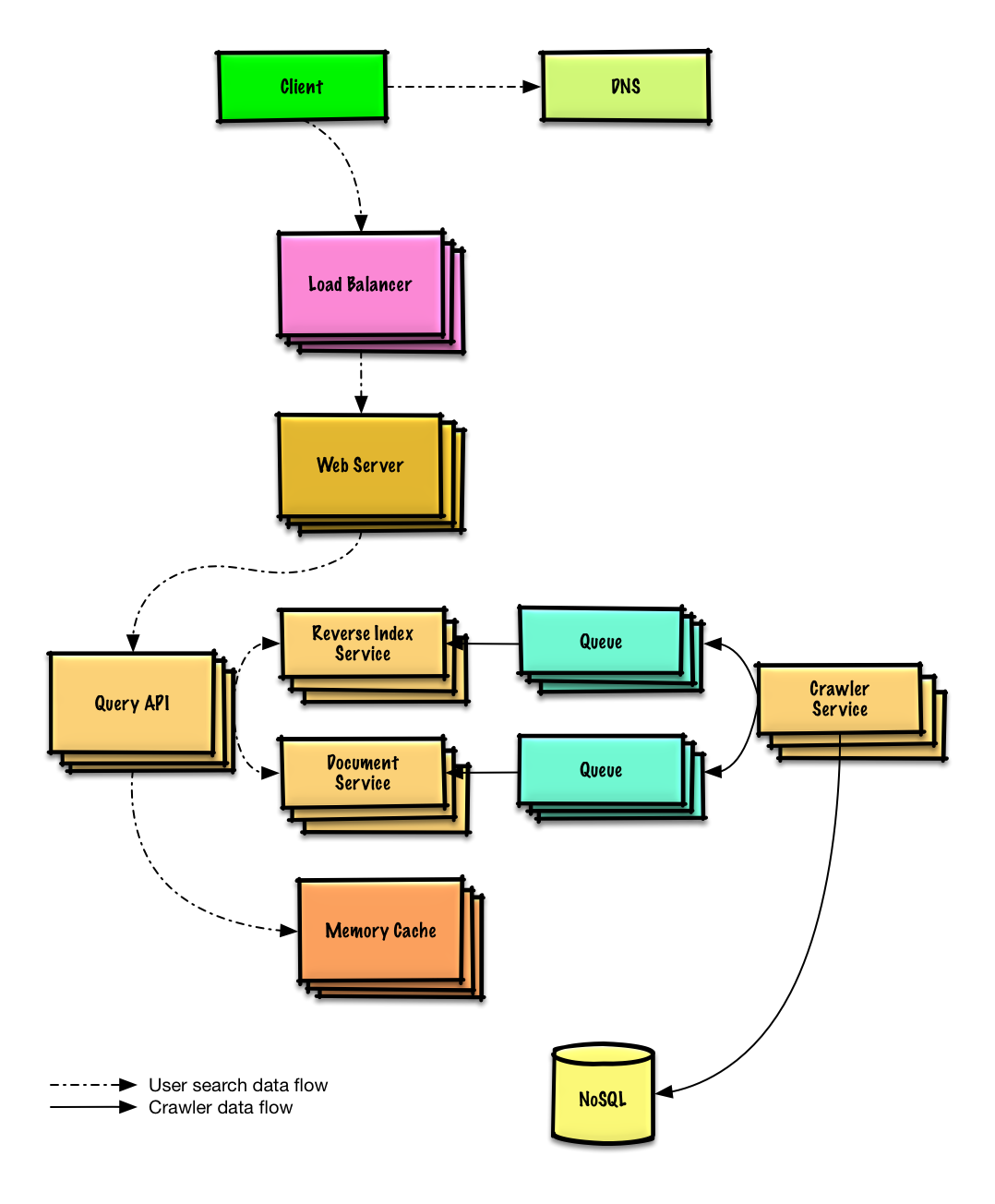
| Concevoir un robot d'exploration Web | Solution |
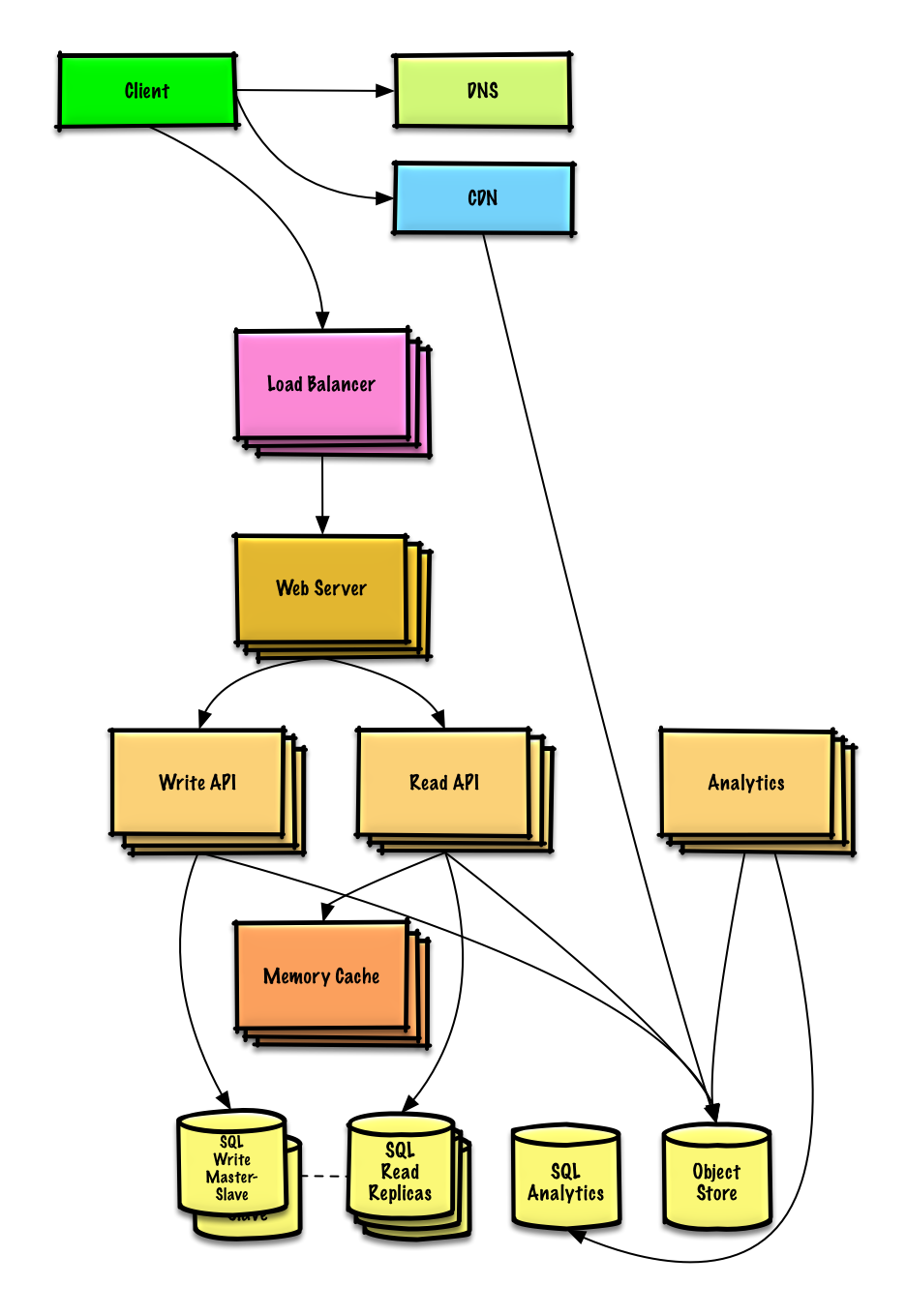
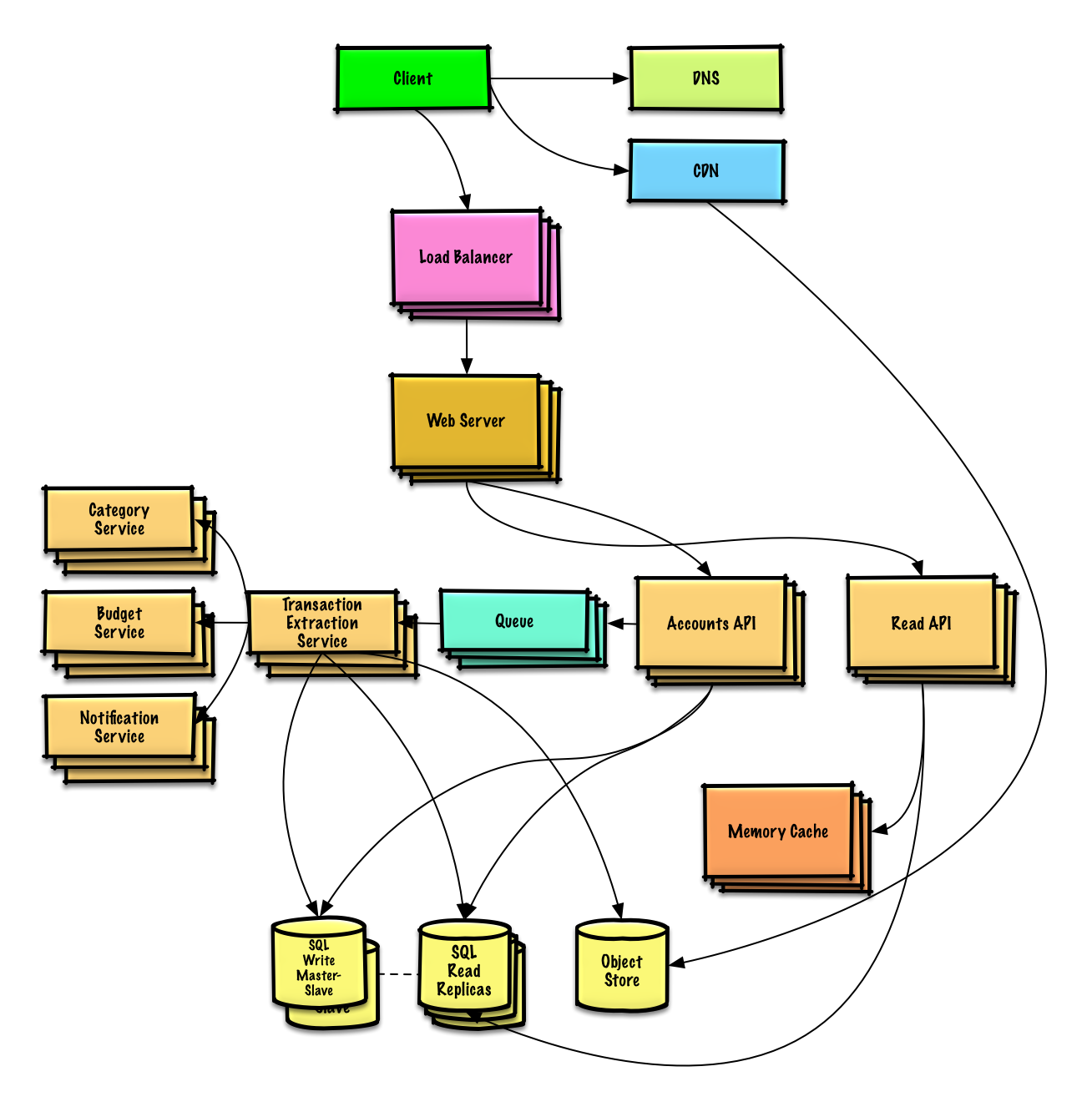
| Conception Mint.com | Solution |
| Concevoir les structures de données pour un réseau social | Solution |
| Concevoir un magasin clé-valeur pour un moteur de recherche | Solution |
| Concevoir le classement des ventes d'Amazon par catégorie | Solution |
| Concevoir un système qui s'adapte à des millions d'utilisateurs sur AWS | Solution |
| Ajouter une question de conception de système | Contribuer |
Voir l'exercice et la solution
Voir l'exercice et la solution
Voir l'exercice et la solution
Voir l'exercice et la solution
Voir l'exercice et la solution
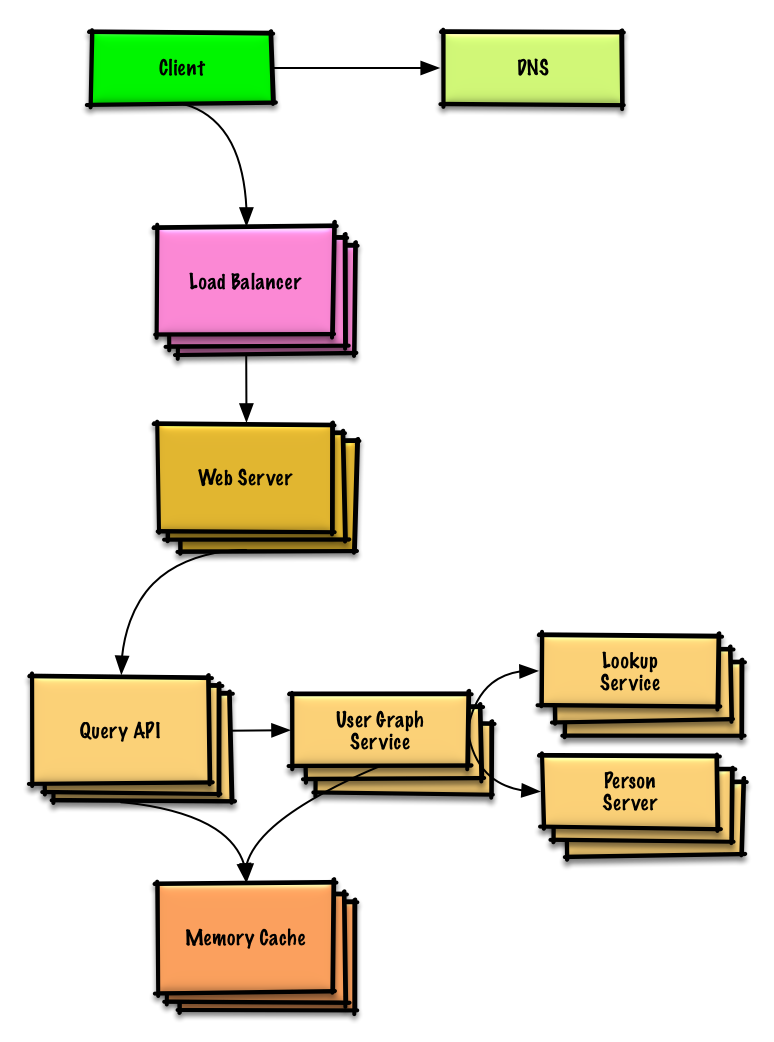
Voir l'exercice et la solution
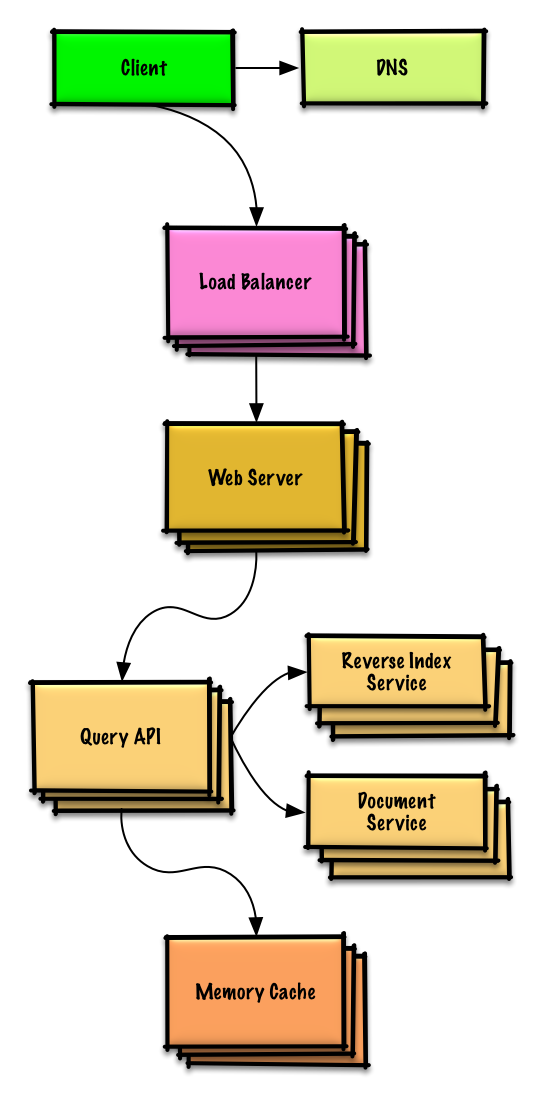
Voir l'exercice et la solution
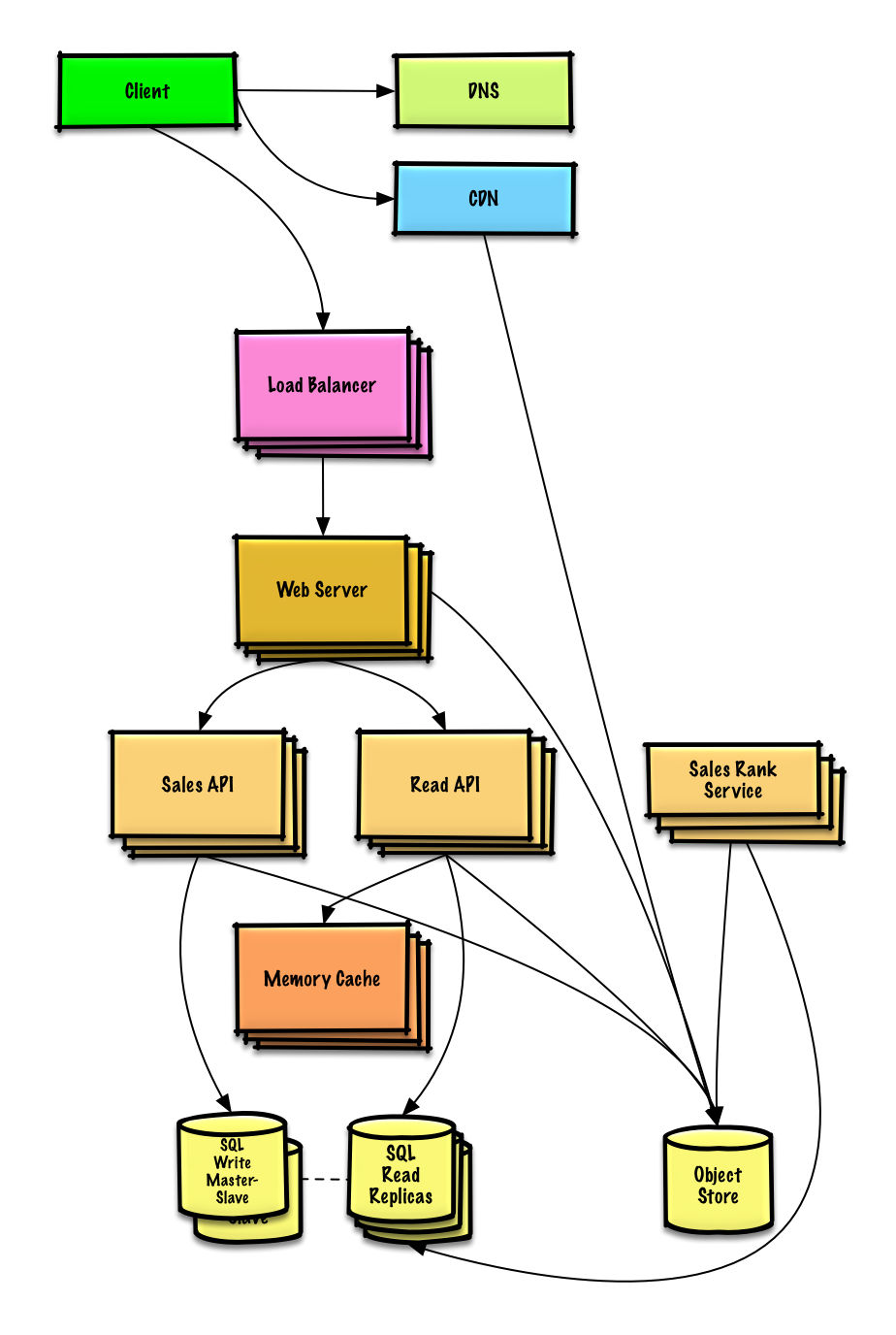
Voir l'exercice et la solution
Questions d'entretien courantes sur la conception orientée objet avec des exemples de discussions, de code et de diagrammes.
Solutions liées au contenu du dossier
solutions/.
Remarque : Cette section est en cours de développement
| Question | |
|---|---|
| Concevoir une carte de hachage | Solution |
| Concevoir un cache le moins récemment utilisé | Solution |
| Concevoir un centre d'appel | Solution |
| Concevoir un jeu de cartes | Solution |
| Concevoir un parking | Solution |
| Concevoir un serveur de chat | Solution |
| Concevoir un réseau circulaire | Contribuer |
| Ajouter une question de conception orientée objet | Contribuer |
Vous débutez dans la conception de systèmes ?
Tout d’abord, vous aurez besoin d’une compréhension de base des principes communs, d’apprendre ce qu’ils sont, comment ils sont utilisés, ainsi que leurs avantages et inconvénients.
Conférence sur l'évolutivité à Harvard
Évolutivité
Ensuite, nous examinerons les compromis de haut niveau :
Gardez à l’esprit que tout est un compromis .
Nous aborderons ensuite des sujets plus spécifiques tels que le DNS, les CDN et les équilibreurs de charge.
Un service est évolutif s’il entraîne une augmentation des performances proportionnelle aux ressources ajoutées. En règle générale, augmenter les performances signifie servir davantage d'unités de travail, mais cela peut également signifier gérer des unités de travail plus importantes, par exemple lorsque les ensembles de données augmentent. 1
Une autre façon d’envisager les performances par rapport à l’évolutivité :
La latence est le temps nécessaire pour effectuer une action ou produire un résultat.
Le débit est le nombre de ces actions ou résultats par unité de temps.
En règle générale, vous devez viser un débit maximal avec une latence acceptable .
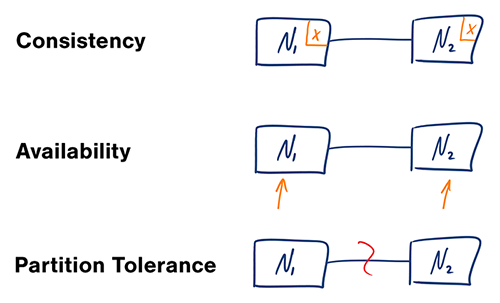
Source : Théorème CAP revisité
Dans un système informatique distribué, vous ne pouvez prendre en charge que deux des garanties suivantes :
Les réseaux ne sont pas fiables, vous devrez donc prendre en charge la tolérance de partition. Vous devrez faire un compromis logiciel entre cohérence et disponibilité.
L'attente d'une réponse du nœud partitionné peut entraîner une erreur de délai d'attente. CP est un bon choix si les besoins de votre entreprise nécessitent des lectures et des écritures atomiques.
Les réponses renvoient la version la plus facilement disponible des données disponibles sur n'importe quel nœud, qui peut ne pas être la dernière. Les écritures peuvent prendre un certain temps pour se propager une fois la partition résolue.
AP est un bon choix si l'entreprise doit permettre une cohérence éventuelle ou lorsque le système doit continuer à fonctionner malgré des erreurs externes.
Avec plusieurs copies des mêmes données, nous sommes confrontés à des options sur la façon de les synchroniser afin que les clients aient une vue cohérente des données. Rappelez-vous la définition de la cohérence du théorème CAP - Chaque lecture reçoit l'écriture la plus récente ou une erreur.
Après une écriture, les lectures peuvent ou non le voir. Une approche de « meilleur effort » est adoptée.
Cette approche est visible dans des systèmes tels que Memcached. Une faible cohérence fonctionne bien dans les cas d'utilisation en temps réel tels que la VoIP, le chat vidéo et les jeux multijoueurs en temps réel. Par exemple, si vous êtes en communication téléphonique et perdez la réception pendant quelques secondes, lorsque vous rétablissez la connexion, vous n'entendez pas ce qui a été dit lors de la perte de connexion.
Après une écriture, les lectures finiront par le voir (généralement en quelques millisecondes). Les données sont répliquées de manière asynchrone.
Cette approche est visible dans des systèmes tels que le DNS et la messagerie électronique. La cohérence finale fonctionne bien dans les systèmes hautement disponibles.
Après une écriture, les lectures le verront. Les données sont répliquées de manière synchrone.
Cette approche est visible dans les systèmes de fichiers et les SGBDR. Une cohérence forte fonctionne bien dans les systèmes nécessitant des transactions.
Il existe deux modèles complémentaires pour prendre en charge la haute disponibilité : le basculement et la réplication .
Avec le basculement actif-passif, des battements de cœur sont envoyés entre le serveur actif et le serveur passif en veille. Si le battement de cœur est interrompu, le serveur passif reprend l'adresse IP de l'actif et reprend le service.
La durée du temps d'arrêt est déterminée par le fait que le serveur passif fonctionne déjà en veille « à chaud » ou s'il doit démarrer à partir d'une veille « à froid ». Seul le serveur actif gère le trafic.
Le basculement actif-passif peut également être appelé basculement maître-esclave.
En mode actif-actif, les deux serveurs gèrent le trafic, répartissant la charge entre eux.
Si les serveurs sont publics, le DNS devra connaître les adresses IP publiques des deux serveurs. Si les serveurs sont internes, la logique de l’application devra connaître les deux serveurs.
Le basculement actif-actif peut également être appelé basculement maître-maître.
Ce sujet est abordé plus en détail dans la section Base de données :
La disponibilité est souvent quantifiée par le temps de disponibilité (ou le temps d'arrêt) en pourcentage de la durée pendant laquelle le service est disponible. La disponibilité est généralement mesurée en nombre de 9 : un service avec une disponibilité de 99,99 % est décrit comme ayant quatre 9.
| Durée | Temps d'arrêt acceptable |
|---|---|
| Temps d'arrêt par an | 8h 45min 57s |
| Temps d'arrêt par mois | 43 min 49,7 s |
| Temps d'arrêt par semaine | 10 minutes 4,8 secondes |
| Temps d'arrêt par jour | 1 min 26,4 s |
| Durée | Temps d'arrêt acceptable |
|---|---|
| Temps d'arrêt par an | 52min 35,7s |
| Temps d'arrêt par mois | 4 min 23 s |
| Temps d'arrêt par semaine | 1 min 5 s |
| Temps d'arrêt par jour | 8,6 s |
Si un service est constitué de plusieurs composants sujets aux pannes, la disponibilité globale du service dépend du fait que les composants soient en séquence ou en parallèle.
La disponibilité globale diminue lorsque deux composants avec une disponibilité < 100 % sont en séquence :
Availability (Total) = Availability (Foo) * Availability (Bar)
Si Foo et Bar avaient chacun une disponibilité de 99,9 %, leur disponibilité totale en séquence serait de 99,8 %.
La disponibilité globale augmente lorsque deux composants avec une disponibilité < 100 % sont en parallèle :
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Si Foo et Bar avaient chacun une disponibilité de 99,9 %, leur disponibilité totale en parallèle serait de 99,9999 %.
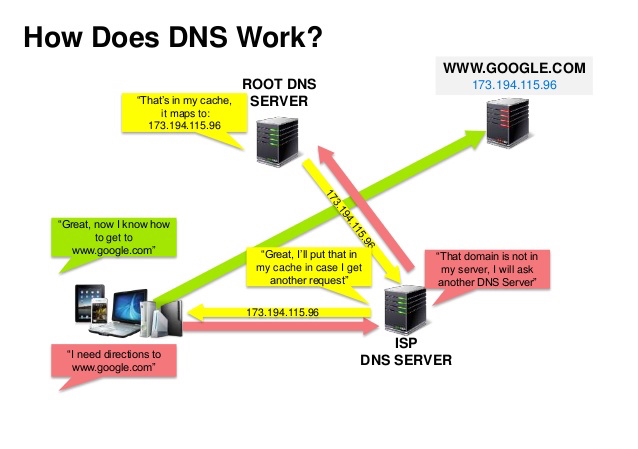
Source : présentation sur la sécurité DNS
Un système de noms de domaine (DNS) traduit un nom de domaine tel que www.example.com en une adresse IP.
Le DNS est hiérarchique, avec quelques serveurs faisant autorité au niveau supérieur. Votre routeur ou FAI fournit des informations sur le(s) serveur(s) DNS à contacter lors d'une recherche. Les mappages de cache des serveurs DNS de niveau inférieur, qui pourraient devenir obsolètes en raison des retards de propagation DNS. Les résultats DNS peuvent également être mis en cache par votre navigateur ou votre système d'exploitation pendant une certaine période, déterminée par la durée de vie (TTL).
CNAME (example.com vers www.example.com) ou vers un enregistrement ADes services tels que CloudFlare et Route 53 fournissent des services DNS gérés. Certains services DNS peuvent acheminer le trafic via différentes méthodes :
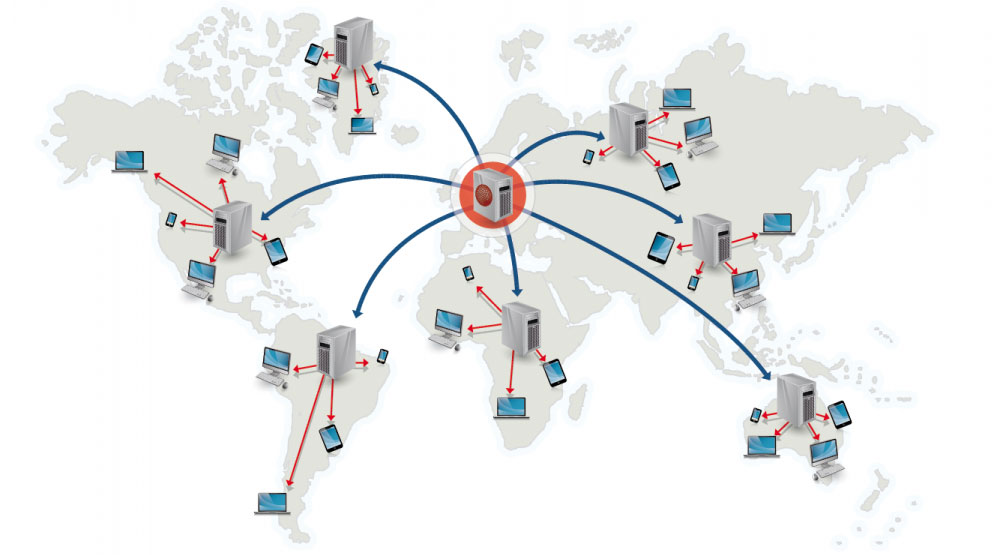
Source : Pourquoi utiliser un CDN
Un réseau de diffusion de contenu (CDN) est un réseau distribué à l'échelle mondiale de serveurs proxy, diffusant du contenu à partir d'emplacements plus proches de l'utilisateur. Généralement, les fichiers statiques tels que HTML/CSS/JS, les photos et les vidéos sont servis à partir du CDN, bien que certains CDN tels que CloudFront d'Amazon prennent en charge le contenu dynamique. La résolution DNS du site indiquera aux clients quel serveur contacter.
La diffusion de contenu à partir de CDN peut améliorer considérablement les performances de deux manières :
Les CDN Push reçoivent du nouveau contenu chaque fois que des changements se produisent sur votre serveur. Vous assumez l'entière responsabilité de fournir le contenu, de le télécharger directement sur le CDN et de réécrire les URL pour qu'elles pointent vers le CDN. Vous pouvez configurer quand le contenu expire et quand il est mis à jour. Le contenu est téléchargé uniquement lorsqu'il est nouveau ou modifié, ce qui minimise le trafic mais maximise le stockage.
Les sites avec un faible trafic ou les sites dont le contenu n'est pas souvent mis à jour fonctionnent bien avec les CDN push. Le contenu est placé sur les CDN une seule fois, au lieu d'être réextrait à intervalles réguliers.
Les Pull CDN récupèrent le nouveau contenu de votre serveur lorsque le premier utilisateur demande le contenu. Vous laissez le contenu sur votre serveur et réécrivez les URL pour pointer vers le CDN. Cela entraîne une requête plus lente jusqu'à ce que le contenu soit mis en cache sur le CDN.
Une durée de vie (TTL) détermine la durée pendant laquelle le contenu est mis en cache. Les CDN Pull minimisent l'espace de stockage sur le CDN, mais peuvent créer un trafic redondant si les fichiers expirent et sont extraits avant d'avoir réellement été modifiés.
Les sites à fort trafic fonctionnent bien avec les CDN pull, car le trafic est réparti plus uniformément et seul le contenu récemment demandé reste sur le CDN.
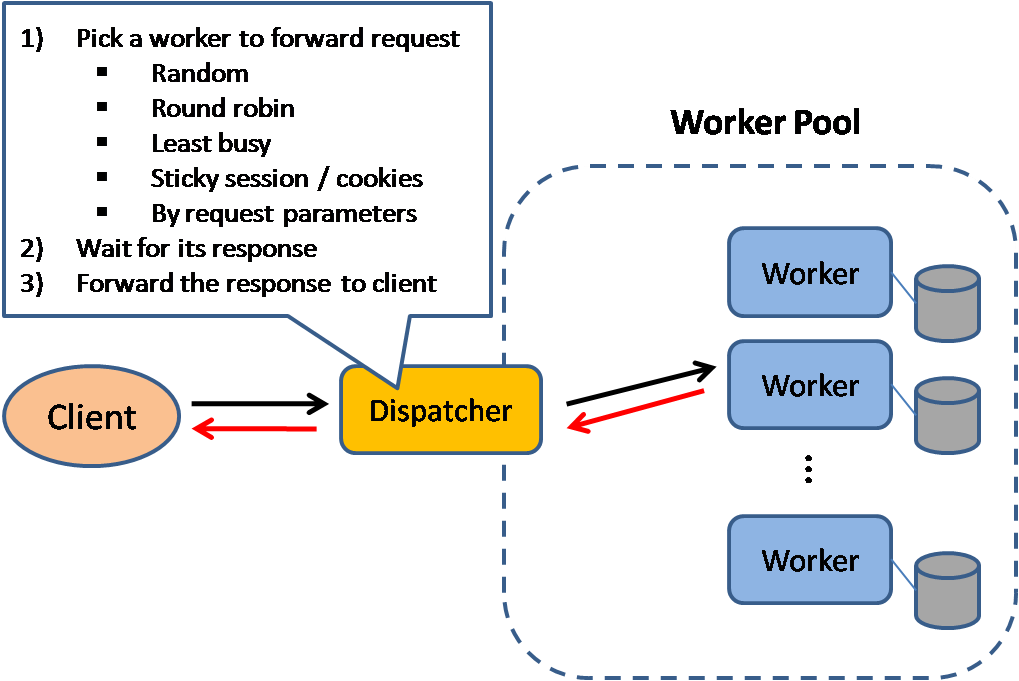
Source : Modèles de conception de systèmes évolutifs
Les équilibreurs de charge distribuent les requêtes client entrantes aux ressources informatiques telles que les serveurs d'applications et les bases de données. Dans chaque cas, l'équilibreur de charge renvoie la réponse de la ressource informatique au client approprié. Les équilibreurs de charge sont efficaces pour :
Les équilibreurs de charge peuvent être implémentés avec du matériel (coûteux) ou avec des logiciels tels que HAProxy.
Les avantages supplémentaires incluent :
Pour se protéger contre les pannes, il est courant de configurer plusieurs équilibreurs de charge, soit en mode actif-passif, soit en mode actif-actif.
Les équilibreurs de charge peuvent acheminer le trafic en fonction de diverses mesures, notamment :
Les équilibreurs de charge de couche 4 examinent les informations au niveau de la couche de transport pour décider comment distribuer les requêtes. Généralement, cela implique les adresses IP source, de destination et les ports dans l'en-tête, mais pas le contenu du paquet. Les équilibreurs de charge de couche 4 transfèrent les paquets réseau vers et depuis le serveur en amont, effectuant une traduction d'adresses réseau (NAT).
Les équilibreurs de charge de couche 7 examinent la couche application pour décider comment distribuer les requêtes. Cela peut impliquer le contenu de l'en-tête, du message et des cookies. Les équilibreurs de charge de couche 7 mettent fin au trafic réseau, lisent le message, prennent une décision d'équilibrage de charge, puis ouvrent une connexion au serveur sélectionné. Par exemple, un équilibreur de charge de couche 7 peut diriger le trafic vidéo vers des serveurs qui hébergent des vidéos tout en dirigeant le trafic de facturation des utilisateurs plus sensibles vers des serveurs dont la sécurité est renforcée.
Au détriment de la flexibilité, l'équilibrage de charge de couche 4 nécessite moins de temps et de ressources informatiques que la couche 7, bien que l'impact sur les performances puisse être minime sur le matériel de base moderne.
Les équilibreurs de charge peuvent également contribuer à la mise à l'échelle horizontale, améliorant ainsi les performances et la disponibilité. La mise à l'échelle à l'aide de machines standard est plus rentable et entraîne une disponibilité plus élevée que la mise à l'échelle d'un seul serveur sur du matériel plus coûteux, appelée mise à l'échelle verticale . Il est également plus facile d’embaucher des talents travaillant sur du matériel de base que sur des systèmes d’entreprise spécialisés.
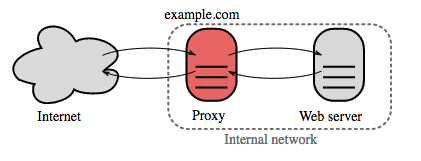
Source : Wikipédia
Un proxy inverse est un serveur Web qui centralise les services internes et fournit des interfaces unifiées au public. Les demandes des clients sont transmises à un serveur qui peut y répondre avant que le proxy inverse ne renvoie la réponse du serveur au client.
Les avantages supplémentaires incluent :
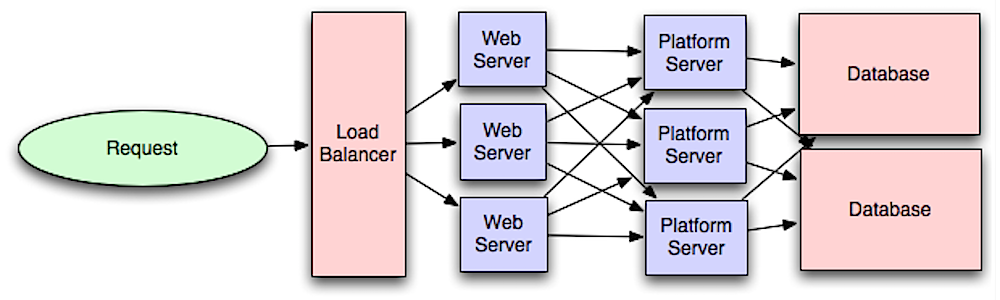
Source : Introduction à l'architecture des systèmes à grande échelle
Séparer la couche Web de la couche application (également appelée couche plate-forme) vous permet de faire évoluer et de configurer les deux couches indépendamment. L'ajout d'une nouvelle API entraîne l'ajout de serveurs d'applications sans nécessairement ajouter de serveurs Web supplémentaires. Le principe de responsabilité unique préconise des services petits et autonomes qui travaillent ensemble. Les petites équipes dotées de petits services peuvent planifier de manière plus agressive une croissance rapide.
Les travailleurs de la couche application contribuent également à activer l’asynchronisme.
Les microservices sont liés à cette discussion, qui peuvent être décrits comme une suite de petits services modulaires déployables indépendamment. Chaque service exécute un processus unique et communique via un mécanisme léger et bien défini pour servir un objectif commercial. 1
Pinterest, par exemple, pourrait disposer des microservices suivants : profil utilisateur, follower, flux, recherche, téléchargement de photos, etc.
Des systèmes tels que Consul, Etcd et Zookeeper peuvent aider les services à se retrouver en gardant une trace des noms, adresses et ports enregistrés. Les vérifications de l'état aident à vérifier l'intégrité du service et sont souvent effectuées à l'aide d'un point de terminaison HTTP. Consul et Etcd disposent tous deux d'un magasin clé-valeur intégré qui peut être utile pour stocker les valeurs de configuration et d'autres données partagées.
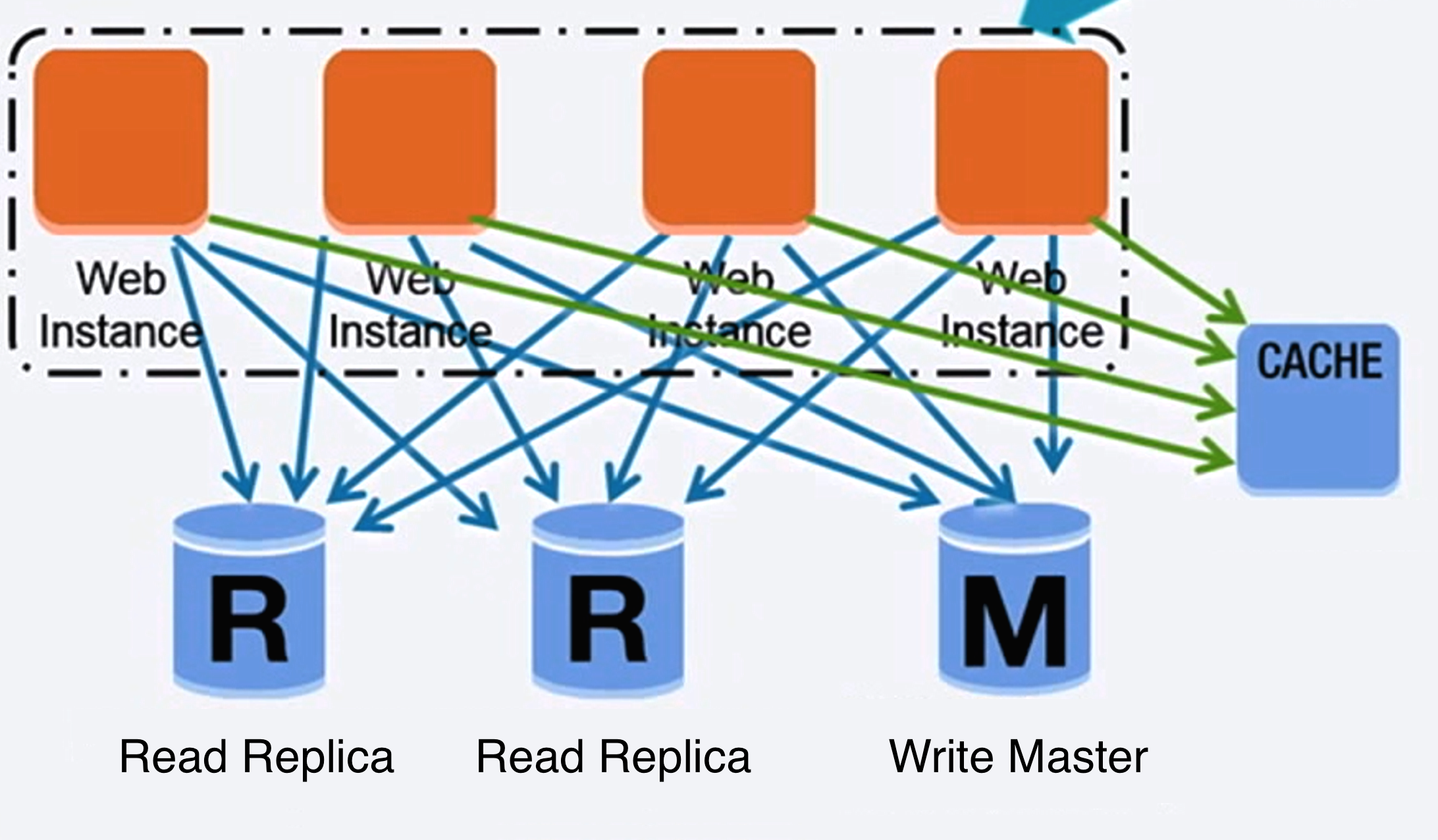
Source : Passer à l'échelle de vos 10 premiers millions d'utilisateurs
Une base de données relationnelle comme SQL est une collection d'éléments de données organisés en tables.
ACID est un ensemble de propriétés de transactions de bases de données relationnelles.
Il existe de nombreuses techniques pour faire évoluer une base de données relationnelle : la réplication maître-esclave , la réplication maître-maître , la fédération , le partitionnement , la dénormalisation et le réglage SQL .
Le maître assure les lectures et les écritures, répliquant les écritures sur un ou plusieurs esclaves, qui servent uniquement aux lectures. Les esclaves peuvent également se répliquer sur d'autres esclaves sous la forme d'une arborescence. Si le maître se déconnecte, le système peut continuer à fonctionner en mode lecture seule jusqu'à ce qu'un esclave soit promu maître ou qu'un nouveau maître soit provisionné.
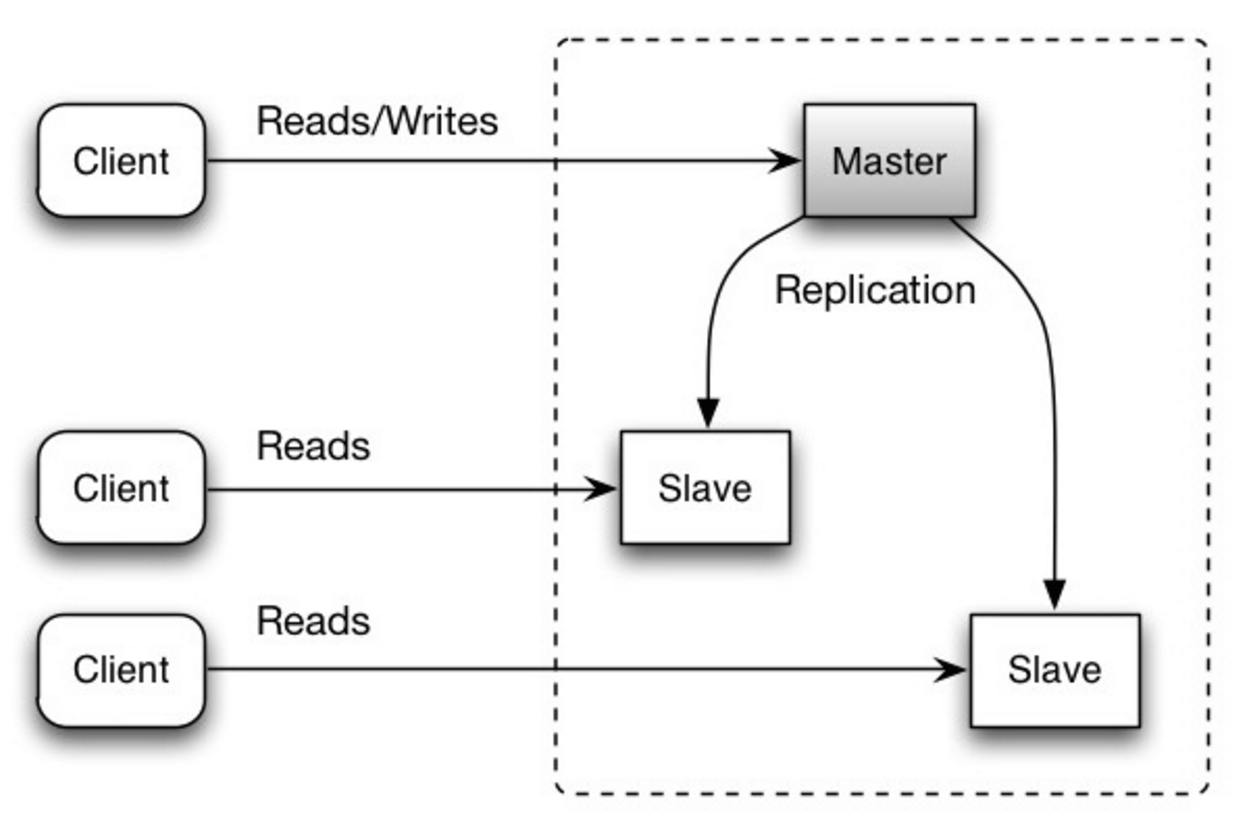
Source : évolutivité, disponibilité, stabilité, modèles
Les deux maîtres assurent les lectures et les écritures et se coordonnent les uns avec les autres lors des écritures. Si l'un des maîtres tombe en panne, le système peut continuer à fonctionner en lecture et en écriture.
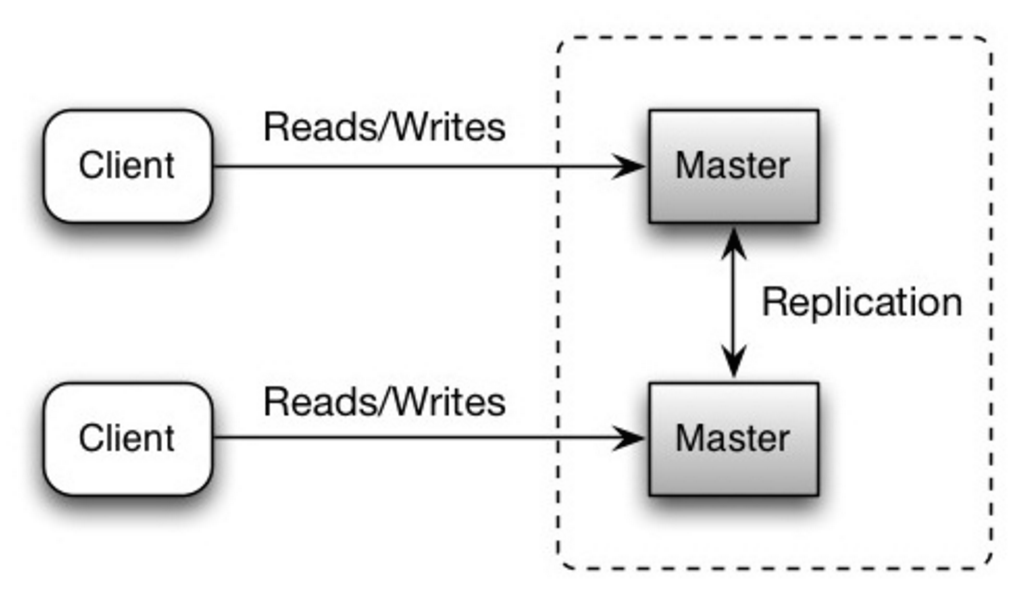
Source : évolutivité, disponibilité, stabilité, modèles
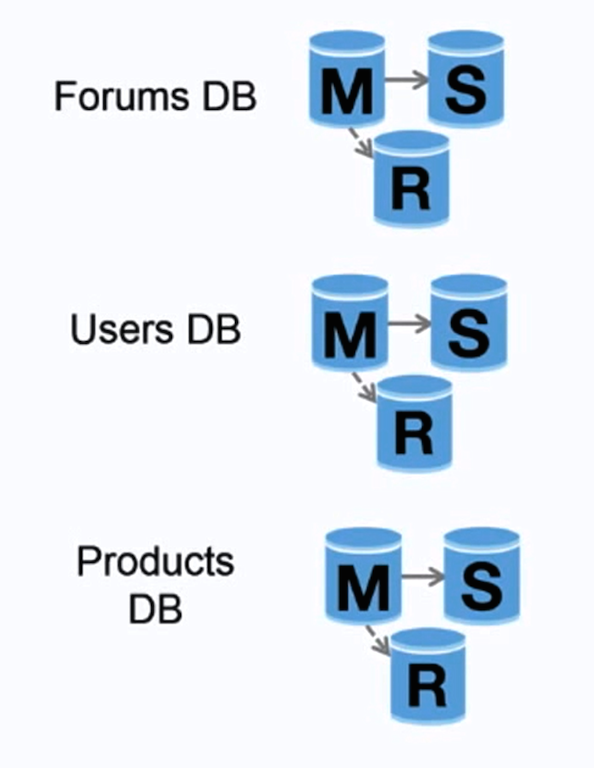
Source : Passer à l'échelle de vos 10 premiers millions d'utilisateurs
La fédération (ou partitionnement fonctionnel) divise les bases de données par fonction. Par exemple, au lieu d'une base de données unique et monolithique, vous pourriez avoir trois bases de données : forums , users et products , ce qui entraînerait moins de trafic de lecture et d'écriture vers chaque base de données et donc moins de retard de réplication. Des bases de données plus petites génèrent davantage de données pouvant tenir en mémoire, ce qui entraîne à son tour davantage d'accès au cache en raison d'une meilleure localisation du cache. En l’absence d’écritures de sérialisation principales centrales, vous pouvez écrire en parallèle, augmentant ainsi le débit.
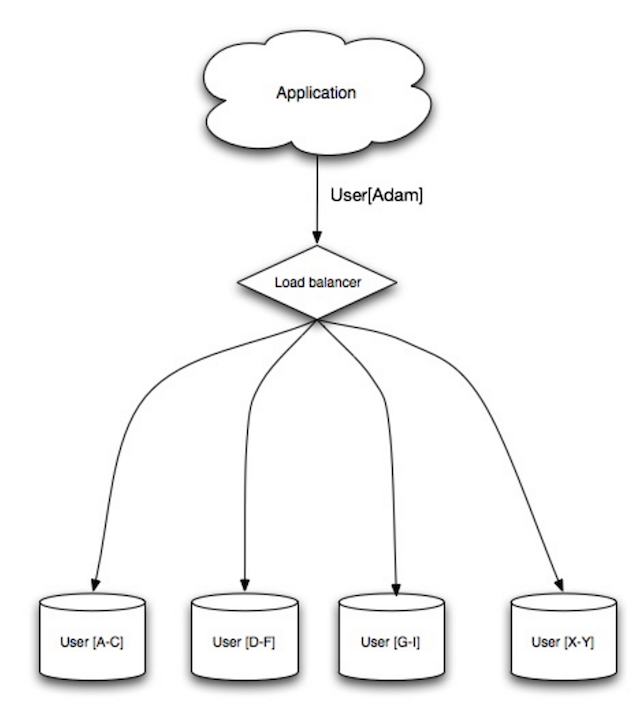
Source : évolutivité, disponibilité, stabilité, modèles
Le partage distribue les données entre différentes bases de données de telle sorte que chaque base de données ne peut gérer qu'un sous-ensemble de données. En prenant une base de données d'utilisateurs comme exemple, à mesure que le nombre d'utilisateurs augmente, davantage de fragments sont ajoutés au cluster.
Semblable aux avantages de la fédération, le partitionnement entraîne moins de trafic de lecture et d’écriture, moins de réplication et plus d’accès au cache. La taille de l'index est également réduite, ce qui améliore généralement les performances avec des requêtes plus rapides. Si une partition tombe en panne, les autres partitions sont toujours opérationnelles, même si vous souhaiterez ajouter une forme de réplication pour éviter la perte de données. Comme pour la fédération, il n’existe pas de maître central unique sérialisant les écritures, ce qui vous permet d’écrire en parallèle avec un débit accru.
Les méthodes courantes pour partager une table d'utilisateurs consistent soit à utiliser l'initiale du nom de famille de l'utilisateur, soit à utiliser l'emplacement géographique de l'utilisateur.
La dénormalisation tente d'améliorer les performances de lecture au détriment de certaines performances d'écriture. Des copies redondantes des données sont écrites en plusieurs tableaux pour éviter les jointures coûteuses. Certains SGBDR tels que PostgreSQL et Oracle prennent en charge les vues matérialisées qui gèrent le travail de stockage des informations redondantes et de maintenir des copies redondantes cohérentes.
Une fois que les données sont distribuées avec des techniques telles que la fédération et le fragment, la gestion des jointures entre les centres de données augmente encore la complexité. La dénormalisation pourrait contourner la nécessité de telles jointures complexes.
Dans la plupart des systèmes, les lectures peuvent être fortement plus nombreuses que les écritures de 100: 1 ou même 1000: 1. Une lecture entraînant une jointure de base de données complexe peut être très coûteuse, passant un temps important en opérations de disque.
SQL Tuning est un sujet large et de nombreux livres ont été écrits comme référence.
Il est important de comparer et de profil pour simuler et découvrir les goulots d'étranglement.
L'analyse comparative et le profilage peuvent vous orienter vers les optimisations suivantes.
CHAR au lieu de VARCHAR pour les champs de longueur fixe.CHAR permet efficacement un accès rapide et aléatoire, tandis qu'avec VARCHAR , vous devez trouver la fin d'une chaîne avant de passer à la suivante.TEXT pour de grands blocs de texte tels que les articles de blog. TEXT permet également des recherches booléennes. L'utilisation d'un champ TEXT entraîne le stockage d'un pointeur sur le disque utilisé pour localiser le bloc de texte.INT pour des nombres plus importants jusqu'à 2 ^ 32 ou 4 milliards.DECIMAL pour la monnaie pour éviter les erreurs de représentation des points flottants.BLOBS , stockez l'emplacement de l'endroit où obtenir l'objet à la place.VARCHAR(255) est le plus grand nombre de caractères qui peuvent être comptés dans un nombre de 8 bits, maximisant souvent l'utilisation d'un octet dans certains SGBDR.NOT NULL le cas échéant le cas échéant pour améliorer les performances de recherche. SELECT , GROUP BY , ORDER BY , JOIN ) pourraient être plus rapides avec les indices.NoSQL est une collection d'éléments de données représentés dans une boutique de valeurs de clé , un magasin de documents , une boutique de colonnes larges ou une base de données de graphiques . Les données sont dénormalisées et les jointures sont généralement effectuées dans le code d'application. La plupart des magasins NoSQL manquent de véritables transactions acides et favorisent une cohérence éventuelle.
La base est souvent utilisée pour décrire les propriétés des bases de données NOSQL. En comparaison avec le théorème de CAP, la base choisit la disponibilité plutôt que la cohérence.
En plus de choisir entre SQL ou NOSQL, il est utile de comprendre quel type de base de données NOSQL correspond le mieux à vos cas d'utilisation. Nous examinerons les magasins de valeurs clés , les magasins de documents , les magasins de colonnes larges et les bases de données de graphiques dans la section suivante.
Abstraction: table de hachage
Un magasin de valeurs clés permet généralement O (1) lit et écrit et est souvent soutenu par la mémoire ou le SSD. Les magasins de données peuvent maintenir des clés dans l'ordre lexicographique, permettant une récupération efficace des plages de clés. Les magasins de valeurs clés peuvent permettre le stockage de métadonnées avec une valeur.
Les magasins de valeurs clés offrent des performances élevées et sont souvent utilisées pour des modèles de données simples ou pour des données en changement rapide, telles qu'une couche de cache en mémoire. Puisqu'ils n'offrent qu'un ensemble d'opérations limité, la complexité est déplacée vers la couche d'application si des opérations supplémentaires sont nécessaires.
Un magasin de valeurs clés est la base de systèmes plus complexes tels qu'un magasin de documents et, dans certains cas, une base de données de graphiques.
Abstraction: magasin de valeurs de clé avec des documents stockés comme valeurs
Un magasin de documents est centré sur des documents (XML, JSON, binaire, etc.), où un document stocke toutes les informations pour un objet donné. Les magasins de documents fournissent des API ou un langage de requête à requête en fonction de la structure interne du document lui-même. Remarque, de nombreux magasins de valeurs clés incluent des fonctionnalités pour travailler avec les métadonnées d'une valeur, brouillant les lignes entre ces deux types de stockage.
Sur la base de l'implémentation sous-jacente, les documents sont organisés par collections, balises, métadonnées ou répertoires. Bien que les documents puissent être organisés ou regroupés, les documents peuvent avoir des champs qui sont complètement différents les uns des autres.
Certains magasins de documents comme MongoDB et CouchDB fournissent également un langage de type SQL pour effectuer des requêtes complexes. DynamoDB prend en charge les valeurs clés et les documents.
Les magasins de documents offrent une grande flexibilité et sont souvent utilisés pour travailler avec des données modifiées occasionnellement.
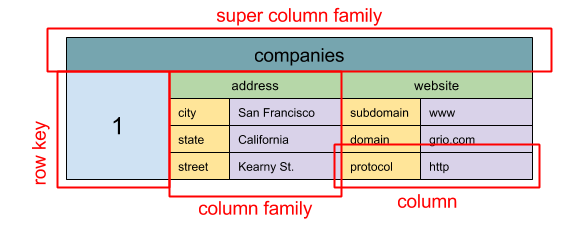
Source: SQL & NOSQL, une brève histoire
Abstraction:
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
L'unité de base des données d'une colonne large est une colonne (paire de noms / valeur). Une colonne peut être regroupée dans des familles de colonnes (analogues à une table SQL). Familles de super colonnes autres familles de colonnes de groupe. Vous pouvez accéder à chaque colonne indépendamment avec une touche de ligne et des colonnes avec la même ligne de touche de ligne a une ligne. Chaque valeur contient un horodatage pour le versioning et pour la résolution des conflits.
Google a présenté BigTable comme le premier magasin de colonnes larges, qui a influencé l'Open-source Hbase souvent utilisée dans l'écosystème Hadoop, et Cassandra de Facebook. Des magasins tels que BigTable, HBASE et Cassandra maintiennent des clés dans l'ordre lexicographique, permettant une récupération efficace des gammes de clés sélectives.
Les magasins de colonnes larges offrent une haute disponibilité et une éleve. Ils sont souvent utilisés pour de très grands ensembles de données.
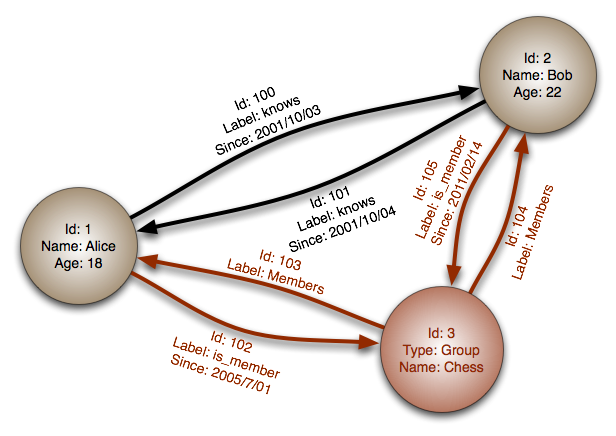
Source: Base de données de graphiques
Abstraction: graphique
Dans une base de données de graphiques, chaque nœud est un enregistrement et chaque arc est une relation entre deux nœuds. Les bases de données de graphiques sont optimisées pour représenter des relations complexes avec de nombreuses clés étrangères ou des relations plusieurs à plusieurs.
Les bases de données de graphiques offrent des performances élevées pour les modèles de données avec des relations complexes, comme un réseau social. Ils sont relativement nouveaux et ne sont pas encore largement utilisés; Il pourrait être plus difficile de trouver des outils et des ressources de développement. De nombreux graphiques ne sont accessibles qu'avec des API REST.
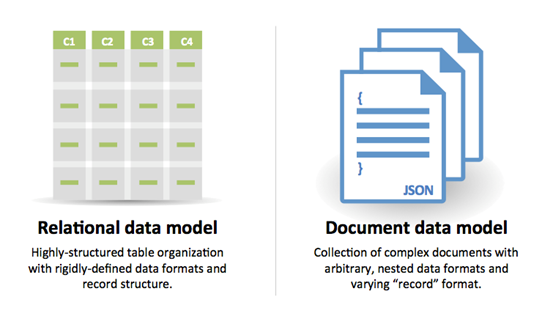
Source: Transition des SGBDR à Nosql
Raisons de SQL :
Raisons de nosql :
Exemples de données bien adaptées à nosql:
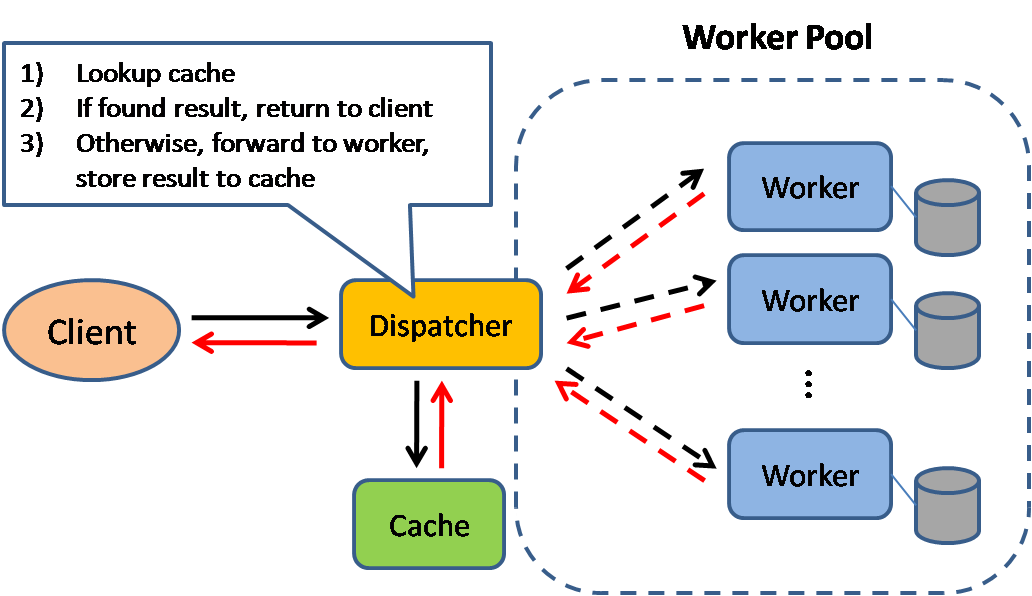
Source: modèles de conception du système évolutif
La mise en cache améliore les temps de chargement des pages et peut réduire la charge sur vos serveurs et bases de données. Dans ce modèle, le répartiteur recherchera d'abord si la demande a été faite auparavant et essayez de trouver le résultat précédent pour revenir, afin de sauvegarder l'exécution réelle.
Les bases de données bénéficient souvent d'une distribution uniforme des lectures et des écritures à travers ses partitions. Les articles populaires peuvent fausser la distribution, provoquant des goulots d'étranglement. Mettre un cache devant une base de données peut aider à absorber les charges et les pointes inégaux dans le trafic.
Les caches peuvent être situées du côté client (OS ou navigateur), côté serveur ou dans une couche de cache distincte.
Les CDN sont considérés comme un type de cache.
Les procurations inverses et les caches telles que le vernis peuvent servir directement un contenu statique et dynamique. Les serveurs Web peuvent également mettre en cache les demandes, le retour des réponses sans avoir à contacter les serveurs d'application.
Votre base de données comprend généralement un certain niveau de mise en cache dans une configuration par défaut, optimisée pour un cas d'utilisation générique. Ajuster ces paramètres pour des modèles d'utilisation spécifiques peut augmenter davantage les performances.
Les caches en mémoire telles que Memcached et Redis sont des magasins de valeurs clés entre votre application et votre stockage de données. Étant donné que les données sont maintenues en RAM, elles sont beaucoup plus rapides que les bases de données typiques où les données sont stockées sur le disque. La RAM est plus limitée que le disque, donc les algorithmes d'invalidation du cache tels que le moins récemment utilisé (LRU) peuvent aider à invalider les entrées «froides» et à garder les données «chaudes» dans RAM.
Redis a les fonctionnalités supplémentaires suivantes:
Il y a plusieurs niveaux que vous pouvez mettre en cache qui entrent dans deux catégories générales: les requêtes et objets de base de données:
Généralement, vous devriez essayer d'éviter la mise en cache basée sur les fichiers, car cela rend le clonage et la mise à l'échelle automatique plus difficile.
Chaque fois que vous interrogez la base de données, hachez la requête comme clé et stockez le résultat au cache. Cette approche souffre de problèmes d'expiration:
Consultez vos données comme un objet, similaire à ce que vous faites avec votre code d'application. Demandez à votre application d'assembler l'ensemble de données à partir de la base de données dans une instance de classe ou une ou des structures de données:
Suggestions de quoi mettre en cache:
Étant donné que vous ne pouvez stocker qu'une quantité limitée de données en cache, vous devrez déterminer la stratégie de mise à jour du cache qui fonctionne le mieux pour votre cas d'utilisation.
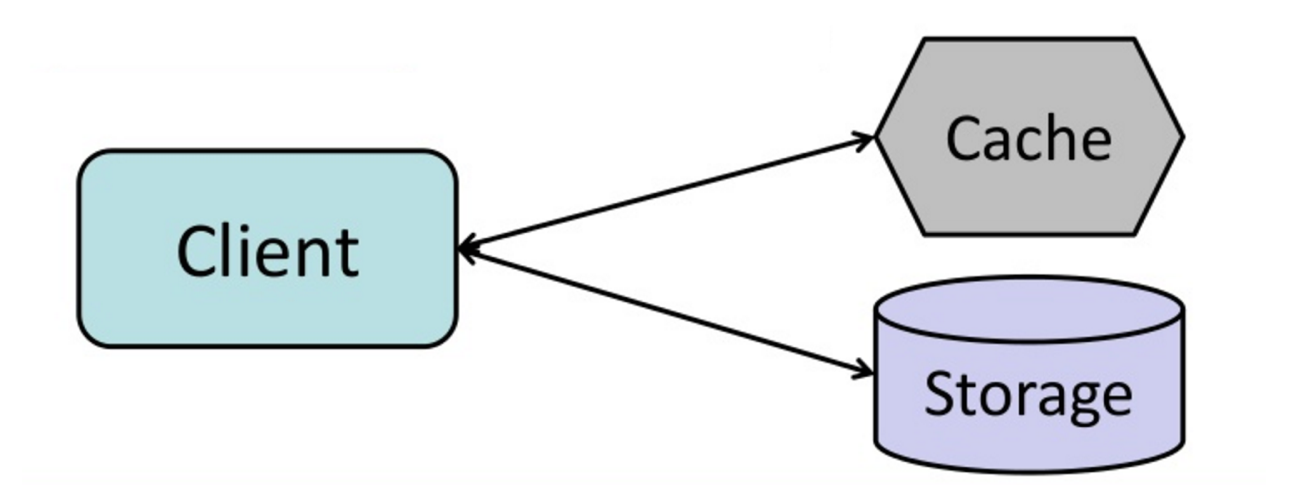
Source: du cache à la grille de données en mémoire
L'application est responsable de la lecture et de l'écriture du stockage. Le cache n'interagit pas directement avec le stockage. L'application fait ce qui suit:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userMemcached est généralement utilisé de cette manière.
Les lectures ultérieures des données ajoutées au cache sont rapides. Le cache-aside est également appelé chargement paresseux. Seules les données demandées sont mises en cache, ce qui évite de remplir le cache avec des données qui ne sont pas demandées.
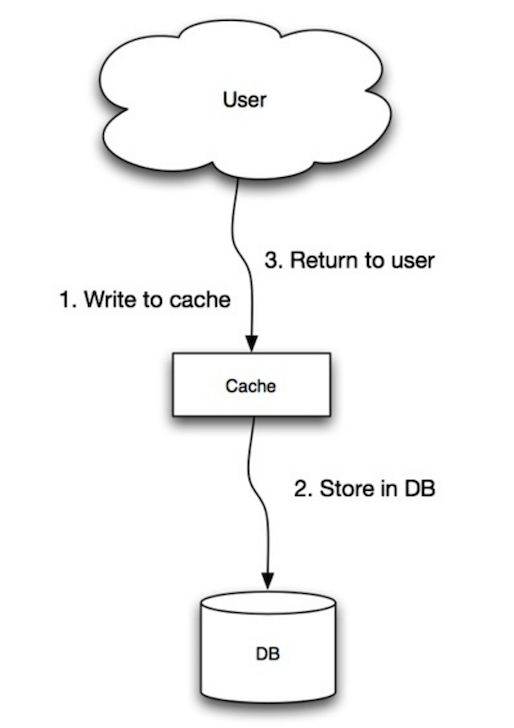
Source: évolutivité, disponibilité, stabilité, modèles
L'application utilise le cache comme magasin de données principal, en lisant et en écrivant des données, tandis que le cache est responsable de la lecture et de l'écriture dans la base de données:
Code d'application:
set_user ( 12345 , { "foo" : "bar" })Code de cache:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )L'écriture est une opération globale lente en raison de l'opération d'écriture, mais les lectures ultérieures des données simplement écrites sont rapides. Les utilisateurs sont généralement plus tolérants à la latence lors de la mise à jour des données que la lecture des données. Les données dans le cache ne sont pas périmées.
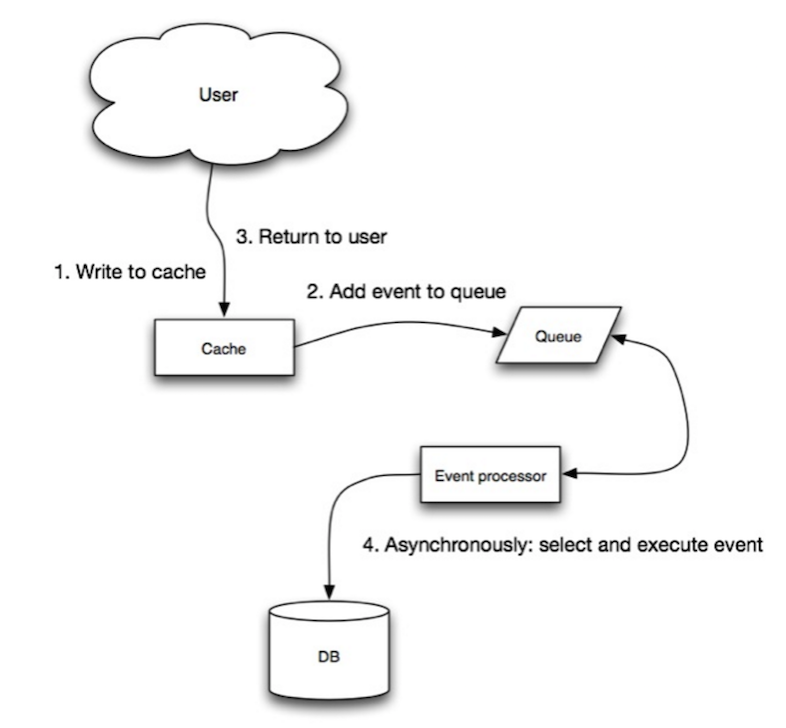
Source: évolutivité, disponibilité, stabilité, modèles
En écriture, l'application fait ce qui suit:
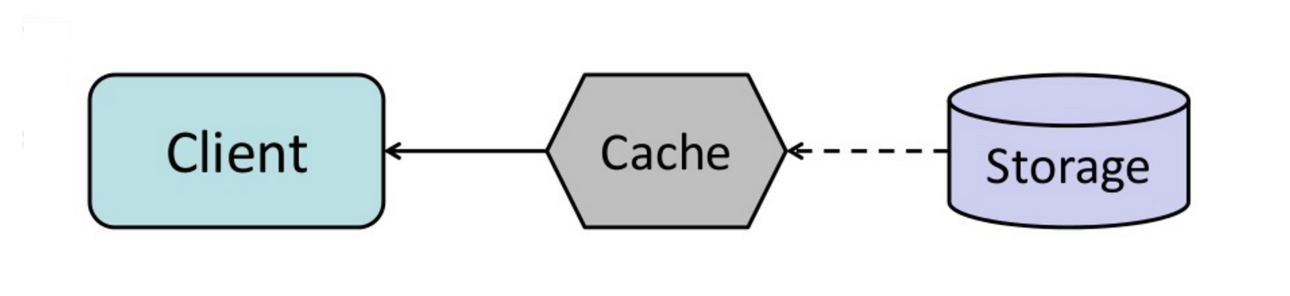
Source: du cache à la grille de données en mémoire
Vous pouvez configurer le cache pour actualiser automatiquement toute entrée de cache récemment consultée avant son expiration.
Le rafraîchissement peut entraîner une latence réduite par rapport à la lecture si le cache peut prédire avec précision quels éléments sont susceptibles d'être nécessaires à l'avenir.
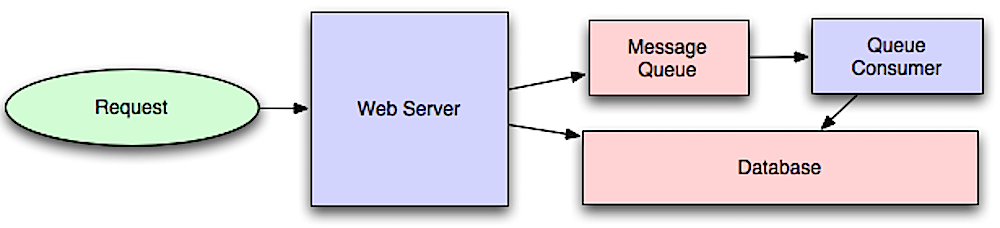
Source: introduction aux systèmes d'architecture pour l'échelle
Les flux de travail asynchrones aident à réduire les délais de demande pour des opérations coûteuses qui seraient autrement effectuées en ligne. Ils peuvent également aider à effectuer des travaux longs à l'avance, comme l'agrégation périodique des données.
Les files d'attente de messages reçoivent, maintiennent et livrent des messages. Si une opération est trop lente pour effectuer en ligne, vous pouvez utiliser une file d'attente de messages avec le flux de travail suivant:
L'utilisateur n'est pas bloqué et le travail est traité en arrière-plan. Pendant ce temps, le client pourrait éventuellement effectuer une petite quantité de traitement pour donner l'impression que la tâche s'est terminée. Par exemple, si vous publiez un tweet, le tweet pourrait être instantanément affiché dans votre calendrier, mais cela pourrait prendre un certain temps avant que votre tweet ne soit réellement livré à tous vos abonnés.
Redis est utile en tant que courtier de messages simple, mais les messages peuvent être perdus.
RabbitMQ est populaire mais vous oblige à vous adapter au protocole «AMQP» et à gérer vos propres nœuds.
Amazon SQS est hébergé mais peut avoir une latence élevée et a la possibilité que les messages soient livrés deux fois.
Les files d'attente de tâches reçoivent des tâches et leurs données connexes, les exécute, puis fournissent leurs résultats. Ils peuvent prendre en charge la planification et peuvent être utilisés pour exécuter des travaux à forte intensité de calcul en arrière-plan.
Le céleri prend en charge la planification et a principalement une prise en charge de Python.
Si les files d'attente commencent à croître considérablement, la taille de la file d'attente peut devenir plus grande que la mémoire, ce qui entraîne des manquements de cache, des lectures de disque et des performances encore plus lentes. La pression du dos peut aider en limitant la taille de la file d'attente, maintenant ainsi un taux de débit élevé et de bons temps de réponse pour les emplois déjà dans la file d'attente. Une fois que la file d'attente se remplit, les clients obtiennent un serveur occupé ou code d'état HTTP 503 pour réessayer plus tard. Les clients peuvent réessayer la demande ultérieurement, peut-être avec un backoff exponentiel.
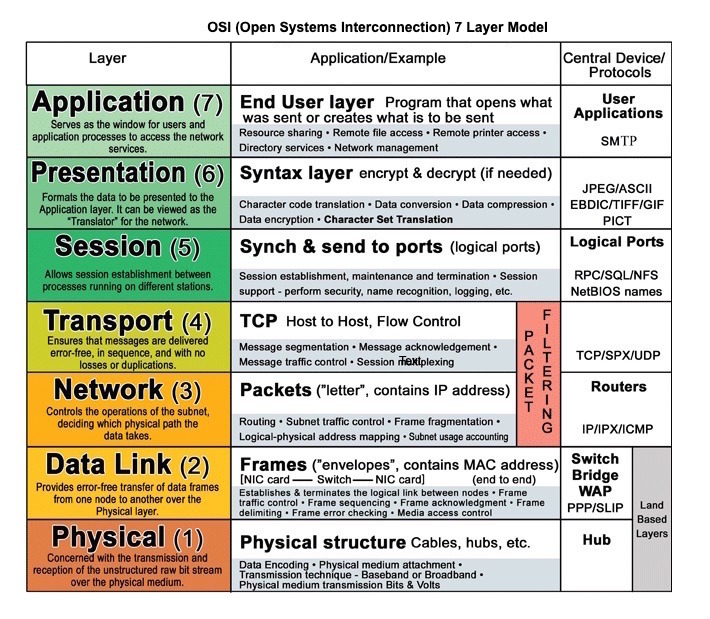
Source: modèle de couche OSI 7
HTTP est une méthode d'encodage et de transport de données entre un client et un serveur. Il s'agit d'un protocole de demande / réponse: les clients émettent des demandes et des serveurs émettent des réponses avec des informations pertinentes sur le contenu et l'état d'achèvement sur la demande. HTTP est autonome, permettant aux demandes et aux réponses de circuler à travers de nombreux routeurs et serveurs intermédiaires qui effectuent un équilibrage de charge, une mise en cache, un chiffrement et une compression.
Une demande HTTP de base se compose d'un verbe (méthode) et d'une ressource (point de terminaison). Voici les verbes HTTP courants:
| Verbe | Description | Idempotent * | Sûr | Mise en cache |
|---|---|---|---|---|
| OBTENIR | Lit une ressource | Oui | Oui | Oui |
| POSTE | Crée une ressource ou déclenche un processus qui gère les données | Non | Non | Oui si la réponse contient des informations de fraîcheur |
| METTRE | Crée ou remplacer une ressource | Oui | Non | Non |
| CORRECTIF | Met partiellement à jour une ressource | Non | Non | Oui si la réponse contient des informations de fraîcheur |
| SUPPRIMER | Supprime une ressource | Oui | Non | Non |
* Peut être appelé plusieurs fois sans résultats différents.
HTTP est un protocole de couche d'application reposant sur des protocoles de niveau inférieur tels que TCP et UDP .
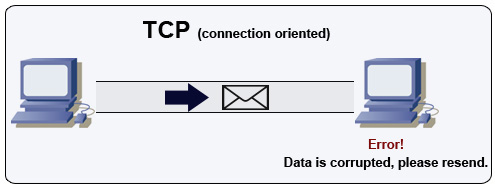
Source: comment faire un jeu multijoueur
TCP est un protocole axé sur la connexion sur un réseau IP. La connexion est établie et terminée à l'aide d'une poignée de main. Tous les paquets envoyés sont garantis pour atteindre la destination dans l'ordre d'origine et sans corruption:
Si l'expéditeur ne reçoit pas de réponse correcte, il renverra les paquets. S'il y a plusieurs délais d'expiration, la connexion est supprimée. TCP met également en œuvre le contrôle du débit et le contrôle de la congestion. Ces garanties provoquent des retards et entraînent généralement une transmission moins efficace que l'UDP.
Pour garantir un débit élevé, les serveurs Web peuvent garder un grand nombre de connexions TCP ouvertes, ce qui entraîne une utilisation élevée de la mémoire. Il peut être coûteux d'avoir un grand nombre de connexions ouvertes entre les threads de serveur Web et de dire un serveur memcached. Le regroupement de connexion peut aider en plus de passer à UDP, le cas échéant.
Le TCP est utile pour les applications qui nécessitent une fiabilité élevée mais qui sont moins critiques. Certains exemples incluent les serveurs Web, les informations de base de données, SMTP, FTP et SSH.
Utilisez TCP sur UDP lorsque:
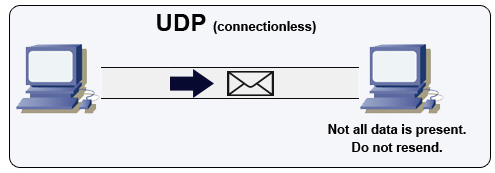
Source: comment faire un jeu multijoueur
UDP est sans connexion. Les datagrammes (analogues aux paquets) ne sont garantis qu'au niveau du datagramme. Les datagrammes peuvent atteindre leur destination hors service ou pas du tout. L'UDP ne soutient pas le contrôle de la congestion. Sans les garanties que le TCP prend en charge, UDP est généralement plus efficace.
UDP peut diffuser, envoyer des datagrammes à tous les appareils du sous-réseau. Ceci est utile avec DHCP car le client n'a pas encore reçu d'adresse IP, empêchant ainsi un moyen pour TCP de diffuser sans l'adresse IP.
L'UDP est moins fiable mais fonctionne bien dans les cas d'utilisation en temps réel tels que VoIP, le chat vidéo, le streaming et les jeux multijoueurs en temps réel.
Utilisez UDP sur TCP lorsque:
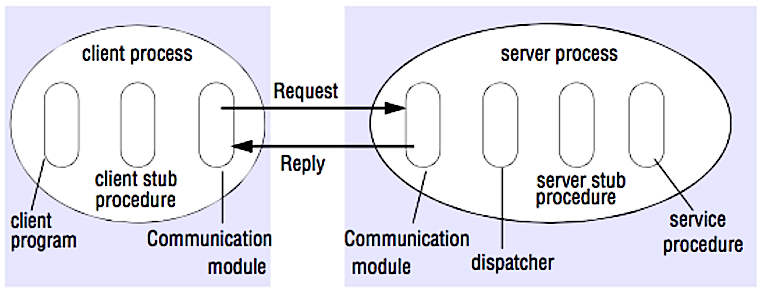
Source: Crack l'interview de conception du système
Dans un RPC, un client fait s'exécuter d'une procédure sur un autre espace d'adressage, généralement un serveur distant. La procédure est codée comme s'il s'agissait d'un appel de procédure local, abstractant les détails de la façon de communiquer avec le serveur du programme client. Les appels distants sont généralement plus lents et moins fiables que les appels locaux, il est donc utile de distinguer les appels RPC des appels locaux. Les cadres RPC populaires incluent Protobuf, Thrift et Avro.
RPC est un protocole de demande de réponse:
Exemple d'appels RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC se concentre sur l'exposition des comportements. Les RPC sont souvent utilisés pour des raisons de performance avec des communications internes, car vous pouvez les appels natifs à main pour mieux s'adapter à vos cas d'utilisation.
Choisissez une bibliothèque native (aka sdk) lorsque:
Les API HTTP suivant le repos ont tendance à être utilisées plus souvent pour les API publiques.
REST est un style architectural appliquant un modèle client / serveur où le client agit sur un ensemble de ressources gérées par le serveur. Le serveur fournit une représentation des ressources et des actions qui peuvent manipuler ou obtenir une nouvelle représentation des ressources. Toutes les communications doivent être apatrides et cachables.
Il y a quatre qualités d'une interface reposante:
Exemple d'appels de repos:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
Le repos est axé sur l'exposition des données. Il minimise le couplage entre le client / serveur et est souvent utilisé pour les API HTTP publiques. REST utilise une méthode plus générique et uniforme pour exposer les ressources via les URI, la représentation via des en-têtes et les actions via des verbes tels que Get, Post, Put, Supprimer et Patch. Étant apatride, le repos est idéal pour la mise à l'échelle et le partitionnement horizontales.
| Opération | RPC | REPOS |
|---|---|---|
| S'inscrire | Post / inscription | Poste / personnes |
| Démissionner | Poster / démissionner { "Personmid": "1234" } | Supprimer / personnes / 1234 |
| Lire une personne | Get / ReadSerson? PersonID = 1234 | Get / Persons / 1234 |
| Lire la liste des éléments d'une personne | Get / readUserSitemsList? PersonId = 1234 | Get / Persons / 1234 / Articles |
| Ajoutez un article aux articles d'une personne | Post / additemTousseSitemslist { "Personid": "1234"; "itemid": "456" } | Post / Personnes / 1234 / Articles { "itemid": "456" } |
| Mettre à jour un article | Post / modificationItem { "itemId": "456"; "clé": "valeur" } | Mettre / articles / 456 { "clé": "valeur" } |
| Supprimer un article | Poster / Supprimer { "itemid": "456" } | Supprimer / éléments / 456 |
Source: Savez-vous vraiment pourquoi vous préférez le repos au RPC
Cette section pourrait utiliser certaines mises à jour. Pensez à contribuer!
La sécurité est un sujet large. À moins que vous n'ayez une expérience considérable, une formation en sécurité ou que vous postulez pour un poste qui nécessite une connaissance de la sécurité, vous n'aurez probablement pas besoin d'en savoir plus que les bases:
Vous serez parfois invité à faire des estimations «à l'arrière-plan». Par exemple, vous devrez peut-être déterminer combien de temps il faudra pour générer 100 miniatures d'image à partir du disque ou la quantité de mémoire qu'une structure de données prendra. Les pouvoirs de deux numéros de table et de latence que chaque programmeur devraient connaître sont des références pratiques.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Mesures pratiques basées sur les nombres ci-dessus:
Questions d'entrevue de conception du système commun, avec des liens vers des ressources sur la façon de résoudre chacun.
| Question | Référence (s) |
|---|---|
| Concevoir un service de synchronisation de fichiers comme Dropbox | youtube.com |
| Concevoir un moteur de recherche comme Google | queue.acm.org stackexchange.com ardendertat.com Stanford.edu |
| Concevoir un robot Web évolutif comme Google | quora.com |
| Concevoir Google Docs | code.google.com neil.fraser.name |
| Concevoir un magasin de valeurs clés comme Redis | SlideShare.net |
| Concevoir un système de cache comme Memcached | SlideShare.net |
| Concevoir un système de recommandation comme Amazon | hulu.com ijcai13.org |
| Concevoir un système Tinyurl comme Bitly | n00tc0d3r.blogspot.com |
| Concevoir une application de chat comme WhatsApp | HighScalability.com |
| Concevoir un système de partage d'images comme Instagram | HighScalability.com HighScalability.com |
| Concevoir la fonction Facebook News Feed | quora.com quora.com SlideShare.net |
| Concevoir la fonction de chronologie Facebook | facebook.com HighScalability.com |
| Concevoir la fonction de chat Facebook | erlang-factory.com facebook.com |
| Concevoir une fonction de recherche de graphiques comme Facebook | facebook.com facebook.com facebook.com |
| Concevoir un réseau de livraison de contenu comme CloudFlare | fighare.com |
| Concevoir un système de sujet à tendance comme Twitter | Michael-noll.com snikolov .wordpress.com |
| Concevoir un système de génération d'ID aléatoire | blog.twitter.com github.com |
| Renvoie les K supérieures à un intervalle de temps | cs.ucsb.edu wpi.edu |
| Concevoir un système qui sert les données de plusieurs centres de données | HighScalability.com |
| Concevoir un jeu de cartes multijoueur en ligne | indieflashblog.com buildnewgames.com |
| Concevoir un système de collecte des ordures | StuffWithStuff.com Washington.edu |
| Concevoir un limiteur de taux d'API | https://stripe.com/blog/ |
| Concevoir une bourse (comme le nasdaq ou la binance) | Jane Street Implémentation de Golang Implémentation GO |
| Ajouter une question de conception du système | Contribuer |
Articles sur la conception des systèmes du monde réel.
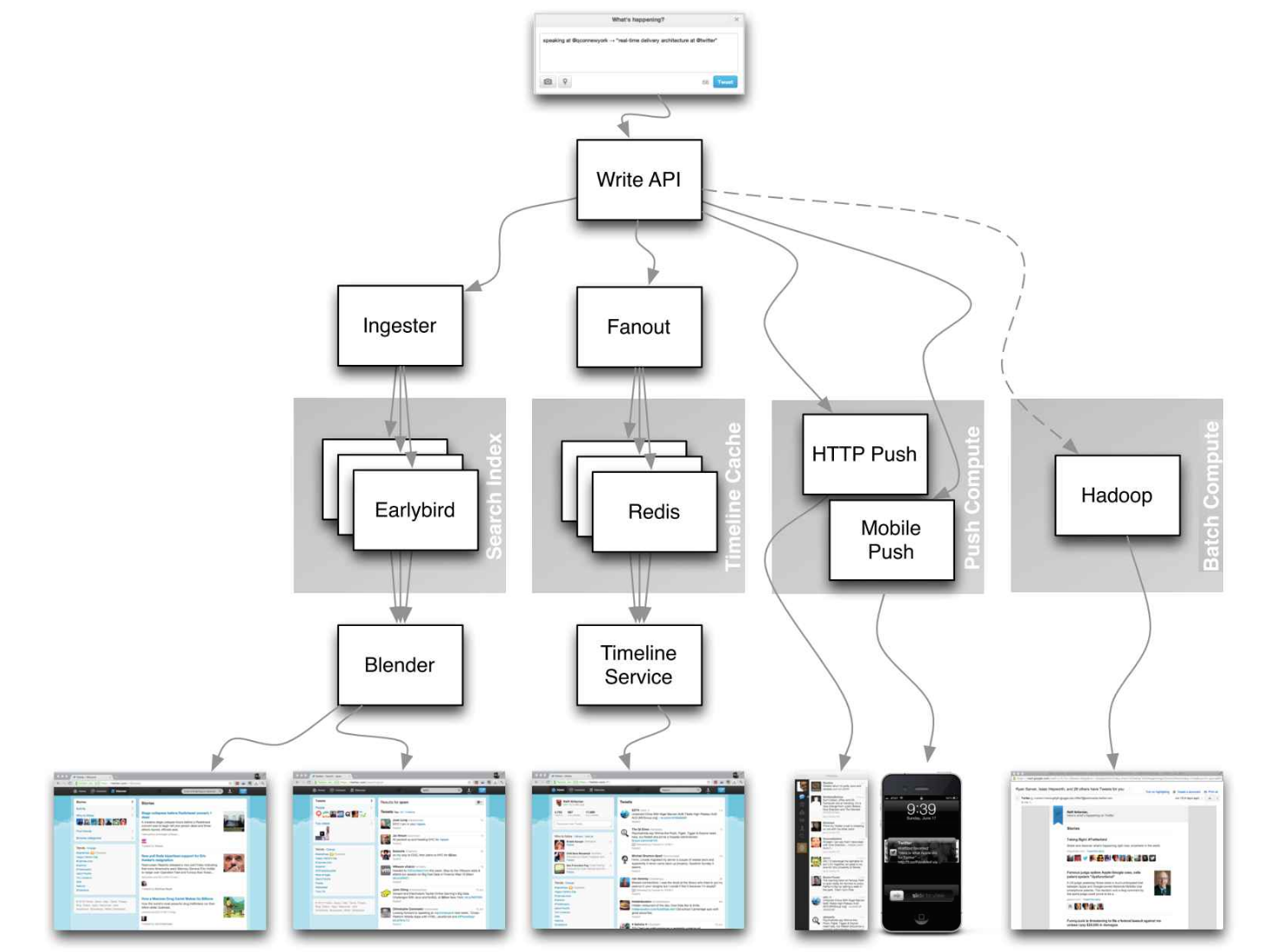
Source: Twitter Timelines à grande échelle
Ne vous concentrez pas sur les détails de Nitty pour les articles suivants, à la place:
| Taper | Système | Référence (s) |
|---|---|---|
| Informatique | MapReduce - Traitement des données distribué à partir de Google | Research.google.com |
| Informatique | Spark - Traitement des données distribué à partir de databricks | slideshare.net |
| Informatique | Storm - Traitement des données distribué de Twitter | slideshare.net |
| Magasin de données | BigTable - Base de données axée sur la colonne distribuée de Google | Harvard.edu |
| Magasin de données | HBASE - Implémentation open source de BigTable | slideshare.net |
| Magasin de données | Cassandra - Base de données axée sur la colonne distribuée de Facebook | slideshare.net |
| Magasin de données | DynamoDB - base de données orientée document d'Amazon | Harvard.edu |
| Magasin de données | MongoDB - base de données axée sur le document | SlideShare.net |
| Magasin de données | Spanner - base de données distribuée à l'échelle mondiale de Google | Research.google.com |
| Magasin de données | Memcached - Système de mise en cache de mémoire distribué | slideshare.net |
| Magasin de données | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Misc | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Misc | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Misc | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Misc | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribuer |
| Entreprise | Reference(s) |
|---|---|
| Amazone | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| Boîte de dépôt | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| 14 million users, terabytes of photos What powers Instagram | |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers | |
| Flickr | Flickr architecture |
| Boîte aux lettres | From 0 to one million users in 6 weeks |
| Netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees | |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| Force de vente | How they handle 1.3 billion transactions a day |
| Stack Overflow | Stack Overflow architecture |
| TripAdvisor | 40M visitors, 200M dynamic page views, 30TB data |
| Tumblr | 15 billion page views a month |
| Gazouillement | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| Uber | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| The WhatsApp architecture Facebook bought for $19 billion | |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? Contribuer!
Credits and sources are provided throughout this repo.
Un merci spécial à :
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


