
Ce dépôt contient des questions et des exercices sur divers sujets techniques, parfois liés au DevOps et au SRE
Il y a actuellement 2624 exercices et questions
️ Vous pouvez les utiliser pour préparer un entretien, mais la plupart des questions et exercices ne représentent pas un véritable entretien. Veuillez lire la page FAQ pour plus de détails
? Si vous êtes intéressé à poursuivre une carrière d'ingénieur DevOps, l'apprentissage de certains des concepts mentionnés ici serait utile, mais sachez qu'il ne s'agit pas d'apprendre tous les sujets et technologies mentionnés dans ce référentiel.
Vous pouvez ajouter plus d'exercices en soumettant des demandes de tirage :) Découvrez les directives de contribution ici

DevOps | 
Git | 
Réseau | 
Matériel | 
Kubernetes |

Développement de logiciels | 
Python | 
Aller | 
Perl | 
Expression régulière |

Nuage | 
AWS | 
Azuré | 
Plateforme Google Cloud | 
OpenStack |

Système opérateur | 
Linux | 
Virtualisation | 
DNS | 
Scripts Shell |

Bases de données | 
SQL | 
Mongo | 
Essai | 
Mégadonnées |

CI/CD | 
Certificats | 
Conteneurs | 
OuvrirShift | 
Stockage |

Terraforme | 
Fantoche | 
Distribué | 
Questions que vous pouvez poser | 
Ansible |

Observabilité | 
Prométhée | 
Encerclez CI | 
| 
Grafana |

Argo | 
Compétences générales | 
Sécurité | 
Conception du système |

Ingénierie du chaos | 
Divers | 
Élastique | 
Kafka | 
NoeudJs |
Réseau
En général, de quoi avez-vous besoin pour communiquer ?
- Un langage commun (pour que les deux extrémités puissent comprendre)
- Une façon de s'adresser à qui vous souhaitez communiquer
- Une connexion (afin que le contenu de la communication puisse atteindre les destinataires)
Qu'est-ce que TCP/IP ?
Ensemble de protocoles qui définissent la manière dont deux appareils ou plus peuvent communiquer entre eux.
Pour en savoir plus sur TCP/IP, lisez ici
Qu’est-ce qu’Ethernet ?
Ethernet fait simplement référence au type de réseau local (LAN) le plus couramment utilisé aujourd'hui. Un LAN, contrairement à un WAN (Wide Area Network), qui s'étend sur une zone géographique plus vaste, est un réseau d'ordinateurs connectés dans une petite zone, comme votre bureau, votre campus universitaire ou même votre maison.
Qu'est-ce qu'une adresse MAC ? A quoi sert-il ?
Une adresse MAC est un numéro ou un code d'identification unique utilisé pour identifier les appareils individuels sur le réseau.
Les paquets envoyés sur Ethernet proviennent toujours d'une adresse MAC et sont envoyés à une adresse MAC. Si une carte réseau reçoit un paquet, elle compare l'adresse MAC de destination du paquet à la propre adresse MAC de la carte.
Quand cette adresse MAC est-elle utilisée ? : ff:ff:ff:ff:ff:ff
Lorsqu'un appareil envoie un paquet à l'adresse MAC de diffusion (FF:FF:FF:FF:FF:FF), il est transmis à toutes les stations du réseau local. Les diffusions Ethernet sont utilisées pour résoudre les adresses IP en adresses MAC (par ARP) au niveau de la couche liaison de données.
Qu'est-ce qu'une adresse IP ?
Une adresse de protocole Internet (adresse IP) est une étiquette numérique attribuée à chaque appareil connecté à un réseau informatique qui utilise le protocole Internet pour la communication. Une adresse IP remplit deux fonctions principales : l'identification de l'hôte ou de l'interface réseau et l'adressage de localisation.
Expliquez le masque de sous-réseau et donnez un exemple
Un masque de sous-réseau est un nombre de 32 bits qui masque une adresse IP et divise les adresses IP en adresses réseau et adresses d'hôte. Le masque de sous-réseau est créé en définissant les bits du réseau sur tous les « 1 » et en définissant les bits de l'hôte sur tous les « 0 ». Au sein d'un réseau donné, sur le total des adresses d'hôtes utilisables, deux sont toujours réservées à des fins spécifiques et ne peuvent être attribuées à aucun hôte. Il s'agit de la première adresse, qui est réservée comme adresse réseau (alias ID réseau), et de la dernière adresse utilisée pour la diffusion réseau.
Exemple
Qu'est-ce qu'une adresse IP privée ? Dans quels scénarios/conceptions de systèmes faut-il l'utiliser ?
Des adresses IP privées sont attribuées aux hôtes du même réseau pour communiquer entre eux. Comme le nom « privé » l’indique, les appareils auxquels sont attribuées les adresses IP privées ne peuvent être atteints par les appareils d’aucun réseau externe. Par exemple, si je vis dans une auberge et que je souhaite que mes camarades de l'auberge rejoignent le serveur de jeu que j'ai hébergé, je leur demanderai de le rejoindre via l'adresse IP privée de mon serveur, puisque le réseau est local à l'auberge. Qu'est-ce qu'une adresse IP publique ? Dans quels scénarios/conceptions de systèmes faut-il l'utiliser ?
Une adresse IP publique est une adresse IP publique. Dans le cas où vous hébergez un serveur de jeu que vous souhaitez que vos amis rejoignent, vous donnerez à vos amis votre adresse IP publique pour permettre à leurs ordinateurs d'identifier et de localiser votre réseau et votre serveur afin que la connexion ait lieu. Une fois que vous n'auriez pas besoin d'utiliser une adresse IP publique, c'est si vous jouiez avec des amis connectés au même réseau que vous, dans ce cas, vous utiliseriez une adresse IP privée. Pour que quelqu'un puisse se connecter à votre serveur situé en interne, vous devrez configurer une redirection de port pour indiquer à votre routeur d'autoriser le trafic du domaine public vers votre réseau et vice versa. Expliquez le modèle OSI. Quelles couches y a-t-il ? De quoi chaque couche est-elle responsable ?
- Application : utilisateur final (HTTP est ici)
- Présentation : établit le contexte entre les entités de la couche application (le cryptage est ici)
- Session : établit, gère et termine les connexions
- Transport : transfère des séquences de données de longueur variable d'une source vers un hôte de destination (TCP & UDP sont ici)
- Réseau : transfère les datagrammes d'un réseau à un autre (IP est ici)
- Liaison de données : fournit un lien entre deux nœuds directement connectés (MAC est ici)
- Physique : les spécifications électriques et physiques de la connexion de données (les bits sont ici )
Vous pouvez en savoir plus sur le modèle OSI sur penguintutor.com
Pour chacun des éléments suivants, détermine à quelle couche OSI il appartient :- Correction d'erreur
- Routage des paquets
- Câbles et signaux électriques
- Adresse MAC
- Adresse IP
- Terminer les connexions
- poignée de main à 3
Correction d'erreurs - Routage des paquets de liaison de données - Câbles réseau et signaux électriques - Adresse MAC physique - Adresse IP de la liaison de données - Réseau Terminer les connexions - Session Poignée de main à 3 - Transports Quels schémas de livraison connaissez-vous ?
Unicast : communication individuelle où il y a un expéditeur et un récepteur.
Diffusion : envoi d'un message à tous les utilisateurs du réseau. L'adresse ff:ff:ff:ff:ff:ff est utilisée pour la diffusion. Deux protocoles courants utilisant la diffusion sont ARP et DHCP.
Multicast : envoi d'un message à un groupe d'abonnés. Il peut s'agir d'un à plusieurs ou de plusieurs à plusieurs.
Qu’est-ce que CSMA/CD ? Est-il utilisé dans les réseaux Ethernet modernes ?
CSMA/CD signifie Carrier Sense Multiple Access/Collision Detection. Son objectif principal est de gérer l'accès à un support/bus partagé où un seul hôte peut transmettre à un moment donné.
Algorithme CSMA/CD :
Avant d'envoyer une trame, il vérifie si un autre hôte transmet déjà une trame.- Si personne ne transmet, il commence à transmettre la trame.
- Si deux hôtes transmettent en même temps, nous avons une collision.
- Les deux hôtes arrêtent d'envoyer la trame et envoient à tout le monde un « signal de brouillage » informant tout le monde qu'une collision s'est produite.
- Ils attendent une heure aléatoire avant de l'envoyer à nouveau
- Une fois que chaque hôte a attendu un temps aléatoire, il essaie à nouveau d'envoyer la trame et le cycle recommence.
Décrivez les périphériques réseau suivants et la différence entre eux :
Un routeur, un commutateur et un hub sont tous des périphériques réseau utilisés pour connecter des appareils dans un réseau local (LAN). Cependant, chaque appareil fonctionne différemment et a ses cas d’utilisation spécifiques. Voici une brève description de chaque appareil et des différences entre eux :
Routeur : périphérique réseau qui connecte plusieurs segments de réseau entre eux. Il fonctionne au niveau de la couche réseau (couche 3) du modèle OSI et utilise des protocoles de routage pour diriger les données entre les réseaux. Les routeurs utilisent des adresses IP pour identifier les appareils et acheminer les paquets de données vers la bonne destination.- Switch : un périphérique réseau qui connecte plusieurs appareils sur un réseau local. Il fonctionne au niveau de la couche liaison de données (couche 2) du modèle OSI et utilise les adresses MAC pour identifier les appareils et diriger les paquets de données vers la bonne destination. Les commutateurs permettent aux appareils sur le même réseau de communiquer entre eux plus efficacement et peuvent empêcher les collisions de données qui peuvent survenir lorsque plusieurs appareils envoient des données simultanément.
- Hub : un périphérique réseau qui connecte plusieurs appareils via un seul câble et est utilisé pour connecter plusieurs appareils sans segmenter un réseau. Cependant, contrairement à un commutateur, il fonctionne au niveau de la couche physique (couche 1) du modèle OSI et diffuse simplement des paquets de données à tous les appareils qui y sont connectés, que l'appareil soit ou non le destinataire prévu. Cela signifie que des collisions de données peuvent se produire et que l'efficacité du réseau peut en souffrir. Les hubs ne sont généralement pas utilisés dans les configurations réseau modernes, car les commutateurs sont plus efficaces et offrent de meilleures performances réseau.
Qu'est-ce qu'un « domaine de collision » ?
Un domaine de collision est un segment de réseau dans lequel les appareils peuvent potentiellement interférer les uns avec les autres en tentant de transmettre des données en même temps. Lorsque deux appareils transmettent des données en même temps, cela peut provoquer une collision entraînant une perte ou une corruption des données. Dans un domaine de collision, tous les appareils partagent la même bande passante et n'importe quel appareil peut potentiellement interférer avec la transmission de données par d'autres appareils. Qu'est-ce qu'un « domaine de diffusion » ?
Un domaine de diffusion est un segment de réseau dans lequel tous les appareils peuvent communiquer entre eux en envoyant des messages de diffusion. Un message diffusé est un message envoyé à tous les appareils d'un réseau plutôt qu'à un appareil spécifique. Dans un domaine de diffusion, tous les appareils peuvent recevoir et traiter des messages diffusés, que le message leur soit destiné ou non. trois ordinateurs connectés à un commutateur. Combien y a-t-il de domaines de collision ? Combien de domaines de diffusion ?
Trois domaines de collision et un domaine de diffusion
Comment fonctionne un routeur ?
Un routeur est un appareil physique ou virtuel qui transmet des informations entre deux ou plusieurs réseaux informatiques à commutation de paquets. Un routeur inspecte l'adresse de protocole Internet (adresse IP) de destination d'un paquet de données donné, calcule le meilleur moyen pour qu'il atteigne sa destination, puis le transmet en conséquence.
Qu’est-ce que le NAT ?
La traduction d'adresses réseau (NAT) est un processus dans lequel une ou plusieurs adresses IP locales sont traduites en une ou plusieurs adresses IP globales et vice versa afin de fournir un accès Internet aux hôtes locaux.
Qu'est-ce qu'un proxy ? Comment ça marche ? Pourquoi en avons-nous besoin ?
Un serveur proxy agit comme une passerelle entre vous et Internet. Il s'agit d'un serveur intermédiaire séparant les utilisateurs finaux des sites Web qu'ils parcourent.
Si vous utilisez un serveur proxy, le trafic Internet transite par le serveur proxy pour arriver à l'adresse que vous avez demandée. La demande revient ensuite via ce même serveur proxy (il existe des exceptions à cette règle), puis le serveur proxy vous transmet les données reçues du site Web.
Les serveurs proxy offrent différents niveaux de fonctionnalités, de sécurité et de confidentialité en fonction de votre cas d'utilisation, de vos besoins ou de la politique de votre entreprise.
Qu’est-ce que TCP ? Comment ça marche ? Qu'est-ce que la poignée de main à trois ?
La prise de contact TCP à 3 voies ou prise de contact à trois voies est un processus utilisé dans un réseau TCP/IP pour établir une connexion entre le serveur et le client.
Une négociation à trois voies est principalement utilisée pour créer une connexion socket TCP. Cela fonctionne quand :
Un nœud client envoie un paquet de données SYN sur un réseau IP à un serveur sur le même réseau ou sur un réseau externe. L'objectif de ce paquet est de demander/déduire si le serveur est ouvert à de nouvelles connexions.- Le serveur cible doit disposer de ports ouverts capables d'accepter et d'initier de nouvelles connexions. Lorsque le serveur reçoit le paquet SYN du nœud client, il répond et renvoie un accusé de réception – le paquet ACK ou le paquet SYN/ACK.
- Le nœud client reçoit le SYN/ACK du serveur et répond avec un paquet ACK.
Qu'est-ce que le délai aller-retour ou le temps aller-retour ?
De Wikipédia : "le temps nécessaire pour qu'un signal soit envoyé plus le temps nécessaire pour qu'un accusé de réception de ce signal soit reçu"
Question bonus : quel est le RTT du LAN ?
Comment fonctionne une négociation SSL ?
La prise de contact SSL est un processus qui établit une connexion sécurisée entre un client et un serveur. Le client envoie un message Client Hello au serveur, qui comprend la version client du protocole SSL/TLS, une liste des algorithmes cryptographiques pris en charge par le client et une valeur aléatoire.- Le serveur répond avec un message Server Hello, qui inclut la version du serveur du protocole SSL/TLS, une valeur aléatoire et un ID de session.
- Le serveur envoie un message de certificat contenant le certificat du serveur.
- Le serveur envoie un message Server Hello Done, qui indique que le serveur a fini d'envoyer des messages pour la phase Server Hello.
- Le client envoie un message Client Key Exchange, qui contient la clé publique du client.
- Le client envoie un message Modifier la spécification de chiffrement, qui informe le serveur que le client est sur le point d'envoyer un message chiffré avec la nouvelle spécification de chiffrement.
- Le client envoie un message de prise de contact chiffré, qui contient le secret pré-maître chiffré avec la clé publique du serveur.
- Le serveur envoie un message Change Cipher Spec, qui informe le client que le serveur est sur le point d'envoyer un message chiffré avec la nouvelle spécification de chiffrement.
- Le serveur envoie un message de prise de contact chiffré, qui contient le secret pré-maître chiffré avec la clé publique du client.
- Le client et le serveur peuvent désormais échanger des données d'application.
Quelle est la différence entre TCP et UDP ?
TCP établit une connexion entre le client et le serveur pour garantir l'ordre des packages, tandis que UDP n'établit pas de connexion entre le client et le serveur et ne gère pas les commandes de packages. Cela rend UDP plus léger que TCP et un candidat idéal pour des services comme le streaming.
Penguintutor.com fournit une bonne explication.
Quels protocoles TCP/IP connaissez-vous ?
Expliquer la "passerelle par défaut"
Une passerelle par défaut sert de point d'accès ou de routeur IP qu'un ordinateur en réseau utilise pour envoyer des informations à un ordinateur d'un autre réseau ou sur Internet.
Qu’est-ce que l’ARP ? Comment ça marche ?
ARP signifie Protocole de résolution d'adresse. Lorsque vous essayez d'envoyer une requête ping à une adresse IP sur votre réseau local, par exemple 192.168.1.1, votre système doit transformer l'adresse IP 192.168.1.1 en adresse MAC. Cela implique d'utiliser ARP pour résoudre l'adresse, d'où son nom.
Les systèmes conservent une table de recherche ARP dans laquelle ils stockent des informations sur les adresses IP associées à quelles adresses MAC. Lorsqu'il tente d'envoyer un paquet vers une adresse IP, le système consultera d'abord ce tableau pour voir s'il connaît déjà l'adresse MAC. S'il y a une valeur en cache, ARP n'est pas utilisé.
Qu’est-ce que le TTL ? Qu’est-ce que cela aide à prévenir ?
TTL (Time to Live) est une valeur dans un paquet IP (Internet Protocol) qui détermine le nombre de sauts ou de routeurs qu'un paquet peut parcourir avant d'être rejeté. Chaque fois qu'un paquet est transmis par un routeur, la valeur TTL est diminuée de un. Lorsque la valeur TTL atteint zéro, le paquet est abandonné et un message ICMP (Internet Control Message Protocol) est renvoyé à l'expéditeur indiquant que le paquet a expiré.- TTL est utilisé pour empêcher les paquets de circuler indéfiniment dans le réseau, ce qui peut provoquer une congestion et dégrader les performances du réseau.
- Cela permet également d'éviter que les paquets ne soient piégés dans des boucles de routage, où les paquets voyagent continuellement entre le même ensemble de routeurs sans jamais atteindre leur destination.
- De plus, TTL peut être utilisé pour aider à détecter et à prévenir les attaques d'usurpation d'adresse IP, lorsqu'un attaquant tente d'usurper l'identité d'un autre appareil sur le réseau en utilisant une adresse IP fausse ou fausse. En limitant le nombre de sauts qu'un paquet peut parcourir, le TTL peut aider à empêcher les paquets d'être acheminés vers des destinations qui ne sont pas légitimes.
Qu’est-ce que DHCP ? Comment ça marche ?
Il signifie Dynamic Host Configuration Protocol et attribue des adresses IP, des masques de sous-réseau et des passerelles aux hôtes. Voici comment cela fonctionne :
- Un hôte en entrant dans un réseau diffuse un message à la recherche d'un serveur DHCP (DHCP DISCOVER)
- Un message d'offre est renvoyé par le serveur DHCP sous forme de paquet contenant la durée du bail, le masque de sous-réseau, les adresses IP, etc. (DHCP OFFER)
- En fonction de l'offre acceptée, le client renvoie une réponse diffusée informant tous les serveurs DHCP (DHCP REQUEST)
- Le serveur envoie un accusé de réception (DHCP ACK)
Lire la suite ici
Peut-on avoir deux serveurs DHCP sur le même réseau ? Comment ça marche ?
Il est possible d'avoir deux serveurs DHCP sur le même réseau, cependant, cela n'est pas recommandé et il est important de les configurer soigneusement pour éviter les conflits et les problèmes de configuration.
Lorsque deux serveurs DHCP sont configurés sur le même réseau, il existe un risque que les deux serveurs attribuent des adresses IP et d'autres paramètres de configuration réseau au même périphérique, ce qui peut provoquer des conflits et des problèmes de connectivité. De plus, si les serveurs DHCP sont configurés avec des paramètres ou des options réseau différents, les périphériques du réseau peuvent recevoir des paramètres de configuration contradictoires ou incohérents.- Cependant, dans certains cas, il peut être nécessaire d'avoir deux serveurs DHCP sur le même réseau, comme dans les grands réseaux où un seul serveur DHCP peut ne pas être en mesure de gérer toutes les requêtes. Dans de tels cas, les serveurs DHCP peuvent être configurés pour servir différentes plages d'adresses IP ou différents sous-réseaux, afin qu'ils n'interfèrent pas les uns avec les autres.
Qu’est-ce que le tunneling SSL ? Comment ça marche ?
- Le tunneling SSL (Secure Sockets Layer) est une technique utilisée pour établir une connexion sécurisée et cryptée entre deux points de terminaison sur un réseau non sécurisé, tel qu'Internet. Le tunnel SSL est créé en encapsulant le trafic dans une connexion SSL, qui assure la confidentialité, l'intégrité et l'authentification.
Voici comment fonctionne le tunneling SSL :
Un client initie une connexion SSL à un serveur, ce qui implique un processus d'établissement de liaison pour établir la session SSL.- Une fois la session SSL établie, le client et le serveur négocient les paramètres de chiffrement, tels que l'algorithme de chiffrement et la longueur de la clé, puis échangent des certificats numériques pour s'authentifier mutuellement.
- Le client envoie ensuite le trafic via le tunnel SSL au serveur, qui décrypte le trafic et le transmet vers sa destination.
- Le serveur renvoie le trafic via le tunnel SSL au client, qui déchiffre le trafic et le transmet à l'application.
Qu'est-ce qu'une prise ? Où pouvez-vous voir la liste des sockets de votre système ?
Un socket est un point de terminaison logiciel qui permet une communication bidirectionnelle entre les processus sur un réseau. Les sockets fournissent une interface standardisée pour la communication réseau, permettant aux applications d'envoyer et de recevoir des données sur un réseau. Pour afficher la liste des sockets ouverts sur un système Linux : netstat -an- Cette commande affiche une liste de tous les sockets ouverts, ainsi que leur protocole, leur adresse locale, leur adresse étrangère et leur état.
Qu’est-ce qu’IPv6 ? Pourquoi devrions-nous envisager de l’utiliser si nous avons IPv4 ?
- IPv6 (Internet Protocol version 6) est la dernière version du protocole Internet (IP), utilisé pour identifier et communiquer avec les appareils sur un réseau. Les adresses IPv6 sont des adresses de 128 bits et sont exprimées en notation hexadécimale, telle que 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
Il y a plusieurs raisons pour lesquelles nous devrions envisager d'utiliser IPv6 plutôt que IPv4 :
Espace d'adressage : IPv4 dispose d'un espace d'adressage limité, qui a été épuisé dans de nombreuses régions du monde. IPv6 fournit un espace d'adressage beaucoup plus grand, permettant des milliards d'adresses IP uniques.- Sécurité : IPv6 inclut la prise en charge intégrée d'IPsec, qui fournit un cryptage et une authentification de bout en bout pour le trafic réseau.
- Performances : IPv6 inclut des fonctionnalités qui peuvent contribuer à améliorer les performances du réseau, telles que le routage multicast, qui permet d'envoyer un seul paquet vers plusieurs destinations simultanément.
- Configuration réseau simplifiée : IPv6 inclut des fonctionnalités qui peuvent simplifier la configuration réseau, telles que la configuration automatique sans état, qui permet aux appareils de configurer automatiquement leurs propres adresses IPv6 sans avoir besoin d'un serveur DHCP.
- Meilleure prise en charge de la mobilité : IPv6 inclut des fonctionnalités qui peuvent améliorer la prise en charge de la mobilité, telles que Mobile IPv6, qui permet aux appareils de conserver leurs adresses IPv6 lorsqu'ils se déplacent entre différents réseaux.
Qu’est-ce qu’un VLAN ?
- Un VLAN (Virtual Local Area Network) est un réseau logique qui regroupe un ensemble d'appareils sur un réseau physique, quel que soit leur emplacement physique. Les VLAN sont créés en configurant des commutateurs réseau pour attribuer un ID de VLAN spécifique aux trames envoyées par les appareils connectés à un port ou à un groupe de ports spécifique sur le commutateur.
Qu’est-ce que le MTU ?
MTU signifie Unité de transmission maximale. Il s'agit de la taille de la plus grande PDU (protocol Data Unit) pouvant être envoyée en une seule transaction.
Que se passe-t-il si vous envoyez un paquet dont la taille dépasse la MTU ?
Avec le protocole IPv4, le routeur peut fragmenter la PDU puis envoyer toutes les PDU fragmentées via la transaction.
Avec le protocole IPv6, il génère une erreur sur l'ordinateur de l'utilisateur.
Vrai ou faux ? Ping utilise UDP car il ne se soucie pas d'une connexion fiable
FAUX. Ping utilise en fait ICMP (Internet Control Message Protocol), un protocole réseau utilisé pour envoyer des messages de diagnostic et des messages de contrôle liés à la communication réseau.
Qu’est-ce que le SDN ?
SDN signifie Software-Defined Networking. Il s'agit d'une approche de la gestion de réseau qui met l'accent sur la centralisation du contrôle du réseau, permettant aux administrateurs de gérer le comportement du réseau via une abstraction logicielle.- Dans un réseau traditionnel, les périphériques réseau tels que les routeurs, les commutateurs et les pare-feu sont configurés et gérés individuellement, à l'aide de logiciels spécialisés ou d'interfaces de ligne de commande. En revanche, SDN sépare le plan de contrôle du réseau du plan de données, permettant aux administrateurs de gérer le comportement du réseau via un contrôleur logiciel centralisé.
Qu’est-ce qu’ICMP ? A quoi sert-il ?
- ICMP signifie Internet Control Message Protocol. Il s'agit d'un protocole utilisé à des fins de diagnostic et de contrôle dans les réseaux IP. Il fait partie de la suite de protocoles Internet, fonctionnant au niveau de la couche réseau.
Les messages ICMP sont utilisés à diverses fins, notamment :
Rapport d'erreurs : les messages ICMP sont utilisés pour signaler les erreurs qui se produisent sur le réseau, comme un paquet qui n'a pas pu être livré à sa destination.- Ping : ICMP est utilisé pour envoyer des messages ping, qui sont utilisés pour tester si un hôte ou un réseau est accessible et pour mesurer le temps d'aller-retour des paquets.
- Découverte de la MTU du chemin : ICMP est utilisé pour découvrir l'unité de transmission maximale (MTU) d'un chemin, qui est la plus grande taille de paquet pouvant être transmise sans fragmentation.
- Traceroute : ICMP est utilisé par l'utilitaire traceroute pour tracer le chemin emprunté par les paquets à travers le réseau.
- Découverte de routeurs : ICMP est utilisé pour découvrir les routeurs d'un réseau.
Qu’est-ce que le NAT ? Comment ça marche ?
NAT signifie Traduction d'adresses réseau. C'est un moyen de mapper plusieurs adresses privées locales sur une adresse publique avant de transférer les informations. Les organisations qui souhaitent que plusieurs appareils utilisent une seule adresse IP utilisent NAT, comme le font la plupart des routeurs domestiques. Par exemple, l'adresse IP privée de votre ordinateur pourrait être 192.168.1.100, mais votre routeur mappe le trafic sur son adresse IP publique (par exemple 1.1.1.1). N'importe quel appareil sur Internet verrait le trafic provenant de votre IP publique (1.1.1.1) au lieu de votre IP privée (192.168.1.100).
Quel numéro de port est utilisé dans chacun des protocoles suivants ? :- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- FTP
- SFTP
SSH-22- SMTP-25
- HTTP-80
- DNS-53
- HTTPS-443
- FTP-21
- SFTP-22
Quels facteurs affectent les performances du réseau ?
Plusieurs facteurs peuvent affecter les performances du réseau, notamment :
Bande passante : la bande passante disponible d'une connexion réseau peut avoir un impact significatif sur ses performances. Les réseaux avec une bande passante limitée peuvent connaître des taux de transfert de données lents, une latence élevée et une mauvaise réactivité.- Latence : la latence fait référence au délai qui se produit lorsque les données sont transmises d'un point d'un réseau à un autre. Une latence élevée peut entraîner un ralentissement des performances du réseau, en particulier pour les applications en temps réel telles que la vidéoconférence et les jeux en ligne.
- Congestion du réseau : lorsque trop d'appareils utilisent un réseau en même temps, une congestion du réseau peut se produire, entraînant des taux de transfert de données lents et de mauvaises performances du réseau.
- Perte de paquets : la perte de paquets se produit lorsque des paquets de données sont abandonnés pendant la transmission. Cela peut entraîner des vitesses de réseau plus lentes et une baisse des performances globales du réseau.
- Topologie du réseau : la disposition physique d'un réseau, y compris l'emplacement des commutateurs, des routeurs et d'autres périphériques réseau, peut avoir un impact sur les performances du réseau.
- Protocole réseau : différents protocoles réseau ont des caractéristiques de performances différentes, ce qui peut avoir un impact sur les performances du réseau. Par exemple, TCP est un protocole fiable qui peut garantir la livraison des données, mais il peut également entraîner un ralentissement des performances en raison de la surcharge requise pour la vérification des erreurs et la retransmission.
- Sécurité du réseau : les mesures de sécurité telles que les pare-feu et le cryptage peuvent avoir un impact sur les performances du réseau, en particulier si elles nécessitent une puissance de traitement importante ou introduisent une latence supplémentaire.
- Distance : la distance physique entre les appareils d'un réseau peut avoir un impact sur les performances du réseau, en particulier pour les réseaux sans fil où la force du signal et les interférences peuvent affecter la connectivité et les taux de transfert de données.
Qu’est-ce qu’APIPA ?
APIPA est un ensemble d'adresses IP attribuées aux appareils lorsque le serveur DHCP principal n'est pas accessible
Quelle plage IP l’APIPA utilise-t-elle ?
APIPA utilise la plage IP : 169.254.0.1 - 169.254.255.254.
Plan de contrôle et plan de données
À quoi fait référence le « plan de contrôle » ?
Le plan de contrôle fait partie du réseau qui décide comment acheminer et transférer les paquets vers un emplacement différent.
À quoi fait référence le « plan de données » ?
Le plan de données fait partie du réseau qui transmet réellement les données/paquets.
À quoi fait référence le « plan de gestion » ?
Il fait référence aux fonctions de suivi et de gestion.
A quel plan (données, contrôle, ...) appartient la création des tables de routage ?
Plan de contrôle.
Expliquer le protocole Spanning Tree (STP).
Qu’est-ce que l’agrégation de liens ? Pourquoi est-il utilisé ?
Qu’est-ce que le routage asymétrique ? Comment y faire face ?
Quels protocoles de superposition (tunnel) connaissez-vous ?
Qu’est-ce que le GRE ? Comment ça marche ?
Qu’est-ce que VXLAN ? Comment ça marche ?
Qu’est-ce que le SNAT ?
Expliquez OSPF.
OSPF (Open Shortest Path First) est un protocole de routage qui peut être implémenté sur différents types de routeurs. En général, OSPF est pris en charge sur la plupart des routeurs modernes, y compris ceux de fournisseurs tels que Cisco, Juniper et Huawei. Le protocole est conçu pour fonctionner avec les réseaux IP, notamment IPv4 et IPv6. En outre, il utilise une conception de réseau hiérarchique, dans laquelle les routeurs sont regroupés en zones, chaque zone ayant sa propre carte topologique et sa propre table de routage. Cette conception permet de réduire la quantité d'informations de routage qui doivent être échangées entre les routeurs et d'améliorer l'évolutivité du réseau.
Les 4 types de routeurs OSPF sont :
- Routeur interne
- Routeurs frontaliers de zone
- Routeurs périphériques pour systèmes autonomes
- Routeurs de base
En savoir plus sur les types de routeurs OSPF : https://www.educba.com/ospf-router-types/
Qu’est-ce que la latence ?
La latence est le temps nécessaire à l'information pour atteindre sa destination depuis la source.
Qu’est-ce que la bande passante ?
La bande passante est la capacité d'un canal de communication à mesurer la quantité de données que ce dernier peut traiter sur une période de temps déterminée. Plus de bande passante impliquerait plus de traitement du trafic et donc plus de transfert de données.
Qu’est-ce que le débit ?
Le débit fait référence à la mesure de la quantité réelle de données transférées sur une certaine période de temps sur n'importe quel canal de transmission.
Lors de l’exécution d’une requête de recherche, qu’est-ce qui est le plus important : la latence ou le débit ? Et comment garantir que nous gérons les infrastructures mondiales ?
Latence. Pour avoir une bonne latence, une requête de recherche doit être transmise au centre de données le plus proche.
Lors du téléchargement d’une vidéo, qu’est-ce qui est le plus important : la latence ou le débit ? Et comment garantir cela ?
Débit. Pour avoir un bon débit, le flux de téléchargement doit être acheminé vers un lien sous-utilisé.
Quelles autres considérations (à l'exception de la latence et du débit) sont à prendre en compte lors du transfert des requêtes ?
- Gardez les caches à jour (ce qui signifie que la demande pourrait ne pas être transmise au centre de données le plus proche)
Expliquer la colonne vertébrale et la feuille
« Spine & Leaf » est une topologie de réseau couramment utilisée dans les environnements de centres de données pour connecter plusieurs commutateurs et gérer efficacement le trafic réseau. Elle est également connue sous le nom d'architecture « colonne vertébrale-feuille » ou de topologie « feuille-colonne vertébrale ». Cette conception offre une bande passante élevée, une faible latence et une évolutivité, ce qui la rend idéale pour les centres de données modernes gérant de gros volumes de données et de trafic. Au sein d'un réseau Spine & Leaf, il existe deux types principaux de commutateurs :
- Commutateurs spine : les commutateurs spine sont des commutateurs hautes performances disposés dans une couche spine. Ces commutateurs constituent le cœur du réseau et sont généralement interconnectés avec chaque commutateur feuille. Chaque commutateur spine est connecté à tous les commutateurs feuilles du centre de données.
- Commutateurs Leaf : les commutateurs Leaf sont connectés à des périphériques finaux tels que des serveurs, des baies de stockage et d'autres équipements réseau. Chaque commutateur feuille est connecté à chaque commutateur spine du centre de données. Cela crée une connectivité non bloquante et entièrement maillée entre les commutateurs feuille et spine, garantissant que n'importe quel commutateur feuille peut communiquer avec n'importe quel autre commutateur feuille avec un débit maximal.
L'architecture Spine & Leaf est devenue de plus en plus populaire dans les centres de données en raison de sa capacité à répondre aux exigences des applications modernes de cloud computing, de virtualisation et de Big Data, en fournissant une infrastructure réseau évolutive, hautes performances et fiable.
Qu’est-ce que la congestion du réseau ? Qu'est-ce qui peut le provoquer ?
La congestion du réseau se produit lorsqu'il y a trop de données à transmettre sur un réseau et que celui-ci n'a pas suffisamment de capacité pour gérer la demande.
Cela peut entraîner une latence accrue et une perte de paquets. Les causes peuvent être multiples, telles qu'une utilisation élevée du réseau, des transferts de fichiers volumineux, des logiciels malveillants, des problèmes matériels ou des problèmes de conception du réseau.
Pour éviter la congestion du réseau, il est important de surveiller votre utilisation du réseau et de mettre en œuvre des stratégies pour limiter ou gérer la demande.
Que pouvez-vous me dire sur le format des paquets UDP ? Qu'en est-il du format des paquets TCP ? En quoi est-ce différent ?
Qu'est-ce que l'algorithme d'intervalle exponentiel ? Où est-il utilisé ?
En utilisant le code de Hamming, quel serait le mot de code pour le mot de données suivant 100111010001101 ?
00110011110100011101
Donner des exemples de protocoles trouvés dans la couche application
Hypertext Transfer Protocol (HTTP) - utilisé pour les pages Web sur Internet- Simple Mail Transfer Protocol (SMTP) - transmission d'e-mails
- Réseau de télécommunications - (TELNET) - émulation de terminal pour permettre à un client d'accéder à un serveur telnet
- File Transfer Protocol (FTP) - facilite le transfert de fichiers entre deux machines quelconques
- Système de noms de domaine (DNS) - traduction de noms de domaine
- Dynamic Host Configuration Protocol (DHCP) : alloue des adresses IP, des masques de sous-réseau et des passerelles aux hôtes
- Simple Network Management Protocol (SNMP) : collecte des données sur les appareils du réseau
Donnez des exemples de protocoles trouvés dans la couche réseau
Protocole Internet (IP) - aide au routage des paquets d'une machine à une autre- Internet Control Message Protocol (ICMP) - permet de savoir ce qui se passe, comme les messages d'erreur et les informations de débogage
Qu’est-ce que le HSTS ?
HTTP Strict Transport Security est une directive de serveur Web qui informe les agents utilisateurs et les navigateurs Web comment gérer leur connexion via un en-tête de réponse envoyé au tout début et renvoyé au navigateur. Cela force les connexions via le cryptage HTTPS, sans tenir compte de l'appel de tout script pour charger n'importe quelle ressource de ce domaine via HTTP. En savoir plus [ici](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS et%20retour%20à%20le%20navigateur.)
Réseau - Divers
Qu’est-ce qu’Internet ? Est-ce la même chose que le World Wide Web ?
Internet fait référence à un réseau de réseaux transférant d'énormes quantités de données à travers le monde.
Le World Wide Web est une application fonctionnant sur des millions de serveurs, au-dessus d'Internet, accessible via ce que l'on appelle le navigateur Web.
Qu'est-ce que le FAI ?
ISP (Internet Service Provider) est le fournisseur d'accès Internet local.
Système opérateur
Exercices sur le système d'exploitation
| Nom | Sujet | Objectif et instructions | Solution | Commentaires |
|---|
| Fourche 101 | Fourchette | Lien | Lien | |
| Fourche 102 | Fourchette | Lien | Lien | |
Système d'exploitation - auto-évaluation
Qu'est-ce qu'un système d'exploitation?
Du livre "Systèmes d'exploitation: trois pièces faciles":
"Responsable de faciliter l'exécution de programmes (même vous permettant d'apporter beaucoup de nombreuses personnes en même temps), permettant aux programmes de partager de la mémoire, permettant aux programmes d'interagir avec les appareils et d'autres trucs amusants comme ça".
Système d'exploitation - Processus
Pouvez-vous expliquer ce qu'est un processus?
Un processus est un programme en cours d'exécution. Un programme est une ou plusieurs instructions et le programme (ou le processus) est exécuté par le système d'exploitation.
Si vous deviez concevoir une API pour les processus dans un système d'exploitation, à quoi ressemblerait cette API?
Il soutiendrait ce qui suit:
Créer - Autoriser à créer de nouveaux processus- Supprimer - Laisser supprimer / détruire les processus
- État - Autoriser à vérifier l'état du processus, qu'il soit en cours d'exécution, s'arrêtait, attend, etc.
- Arrêtez - Laisser arrêter un processus de course
Comment un processus est-il créé?
Le code OS est le code du programme et toutes les données pertinentes supplémentaires- Le code du programme est chargé dans la mémoire ou plus spécifiquement, dans l'espace d'adressage du processus.
- La mémoire est allouée à la pile du programme (AKA Run-Time Stack). La pile a également initialisé par le système d'exploitation avec des données comme Argv, Argc et Paramètres à Main ()
- La mémoire est allouée pour le tas du programme qui est requis pour les données allouées dynamiquement comme les listes de données et les tables de hachage des structures de données
- Les tâches d'initialisation d'E / S sont effectuées, comme dans les systèmes basés sur UNIX / Linux, où chaque processus a 3 descripteurs de fichiers (entrée, sortie et erreur)
- Le système d'exploitation exécute le programme, à partir de main ()
Vrai ou faux ? Le chargement du programme dans la mémoire est fait avec impatience (tout à la fois)
FAUX. C'était vrai dans le passé, mais les systèmes d'exploitation d'aujourd'hui effectuent un chargement paresseux, ce qui signifie que seuls les pièces pertinentes requises pour que le processus s'exécute est chargé en premier.
Quels sont les différents états d'un processus?
Exécution - il s'agit d'instructions- Prêt - il est prêt à courir, mais pour différentes raisons, il est en attente
- Bloqué - il attend que certaines opérations se terminent, par exemple une demande de disque d'E / S
Quelles sont les raisons pour lesquelles un processus est bloqué?
Opérations d'E / S (par exemple, la lecture d'un disque)- En attente d'un paquet d'un réseau
Qu'est-ce que la communication inter-processus (IPC)?
La communication inter-processus (IPC) fait référence aux mécanismes fournis par un système d'exploitation qui permettent aux processus pour gérer les données partagées.
Qu'est-ce que le «partage du temps»?
Même lorsque vous utilisez un système avec un CPU physique, il est possible de permettre à plusieurs utilisateurs de travailler dessus et d'exécuter des programmes. Cela est possible avec le partage de temps, où les ressources informatiques sont partagées d'une manière qu'il semble à l'utilisateur, le système a plusieurs CPU, mais en fait, c'est simplement un processeur partagé en appliquant le multiprogrammation et le multitâche.
Qu'est-ce que le «partage de l'espace»?
Un peu l'opposé du partage de temps. Pendant que le partage de temps, une ressource est utilisé pendant un certain temps par une entité, puis la même ressource peut être utilisée par une autre ressource, dans le partage d'espace, l'espace est partagé par plusieurs entités, mais d'une manière où il n'est pas transféré entre eux.
Il est utilisé par une entité, jusqu'à ce que cette entité décide de s'en débarrasser. Prenons par exemple le stockage. En stockage, un fichier est le vôtre, jusqu'à ce que vous décidiez de le supprimer.
Quel composant détermine quel processus s'exécute à un moment donné?
Planificateur du processeur
Système d'exploitation - Mémoire
Qu'est-ce que la «mémoire virtuelle» et à quoi sert-il?
La mémoire virtuelle combine la RAM de votre ordinateur avec un espace temporaire sur votre disque dur. Lorsque RAM s'exécute bas, la mémoire virtuelle aide à déplacer les données de RAM vers un espace appelé fichier de pagination. Le déménagement des données vers le fichier de pagination peut libérer le RAM, afin que votre ordinateur puisse terminer son travail. En général, plus votre ordinateur a de RAM, plus les programmes fonctionnent rapidement. https://www.minitool.com/lib/virtual-memory.html
Qu'est-ce que la demande de demande?
La pagination de la demande est une technique de gestion de la mémoire où les pages sont chargées dans la mémoire physique uniquement lorsqu'ils sont accessibles par un processus. Il optimise l'utilisation de la mémoire en chargeant des pages à la demande, en réduisant la latence de démarrage et les frais généraux d'espace. Cependant, il introduit une certaine latence lors de l'accès aux pages pour la première fois. Dans l'ensemble, il s'agit d'une approche rentable pour gérer les ressources de la mémoire dans les systèmes d'exploitation.
Qu'est-ce que la copie-écriture?
Copy-on-Write (Cow) est un concept de gestion des ressources, dans le but de réduire la copie inutile des informations. Il s'agit d'un concept, qui est implémenté par exemple dans le Syscall POSIX Fork, qui crée un processus en double du processus d'appel. L'idée:
Si les ressources sont partagées entre 2 entités ou plus (par exemple des segments de mémoire partagés entre 2 processus), les ressources n'ont pas besoin d'être copiées pour chaque entité, mais que chaque entité a une autorisation d'accès à l'opération de lecture sur la ressource partagée. (Les segments partagés sont marqués en lecture seule) (Pensez à chaque entité ayant un pointeur vers l'emplacement de la ressource partagée, qui peut être déréférencée pour lire sa valeur)- Si une entité effectuerait une opération d'écriture sur une ressource partagée, un problème se posait, car la ressource serait également modifiée en permanence pour toutes les autres entités le partageant. (Pensez à un processus modifiant certaines variables sur la pile, ou en allouant certaines données dynamiquement sur le tas, ces modifications de la ressource partagée s'appliqueraient également à tous les autres processus, c'est certainement un comportement indésirable)
- En tant que solution uniquement, si une opération d'écriture est sur le point d'être effectuée sur une ressource partagée, cette ressource est copiée en premier, puis les modifications sont appliquées.
Qu'est-ce qu'un noyau, et que fait-il?
Le noyau fait partie du système d'exploitation et est responsable de tâches comme:
Allocation de la mémoire- Planifier les processus
- Contrôler le processeur
Vrai ou faux ? Certains éléments du code dans le noyau sont chargés dans des zones protégées de la mémoire afin que les applications ne puissent pas les écraser.
Vrai
Qu'est-ce que POSIX?
POSIX (Interface du système d'exploitation portable) est un ensemble de normes qui définissent l'interface entre un système d'exploitation de type UNIX et des programmes d'application.
Expliquez ce qu'est le sémaphore et quel est son rôle dans les systèmes d'exploitation.
Un sémaphore est une primitive de synchronisation utilisée dans les systèmes d'exploitation et la programmation simultanée pour contrôler l'accès aux ressources partagées. Il s'agit d'un type de données variable ou abstrait qui agit comme un compteur ou un mécanisme de signalisation pour gérer l'accès aux ressources par plusieurs processus ou threads.
Qu'est-ce que le cache? Qu'est-ce que le tampon?
Cache: le cache est généralement utilisé lorsque les processus lisent et écrivent sur le disque pour rendre le processus plus rapidement, en créant des données similaires utilisées par différents programmes facilement accessibles. Tampon: place réservée dans RAM, qui est utilisée pour contenir des données à des fins temporaires.
Virtualisation
Qu'est-ce que la virtualisation?
La virtualisation utilise un logiciel pour créer une couche d'abstraction sur le matériel informatique, qui permet aux éléments matériels d'un seul ordinateur - processeurs, mémoire, stockage et plus - d'être divisé en plusieurs ordinateurs virtuels, communément appelés machines virtuelles (machines virtuelles).
Qu'est-ce qu'un hyperviseur?
Red Hat: "Un hyperviseur est un logiciel qui crée et exécute des machines virtuelles (VM). Un hyperviseur, parfois appelé moniteur de machine virtuelle (VMM), isole le système d'exploitation hyperviseur et les ressources à partir des machines virtuelles et permet la création et la gestion de ceux VMS. "
Lire la suite ici
Quels types d'hyperviseurs y a-t-il?
Hyperviseurs hébergés et hyperviseurs à métal nu.
Quels sont les avantages et les inconvénients de l'hyperviseur à métal nu sur un hyperviseur hébergé?
En raison d'avoir ses propres pilotes et un accès direct aux composants matériels, un hyperviseur de baremetal aura souvent de meilleures performances ainsi que la stabilité et l'évolutivité.
D'un autre côté, il y aura probablement une limitation concernant le chargement (n'importe quel) conducteurs, donc un hyperviseur hébergé bénéficiera généralement d'une meilleure compatibilité matérielle.
Quels types de virtualisation existe-t-il?
Le réseau de virtualisation du système d'exploitation fonctionne de virtualisation de la virtualisation de bureau
La contenerisation est-elle un type de virtualisation?
Oui, c'est une virtualisation au niveau du système opérationnel, où le noyau est partagé et permet d'utiliser plusieurs instances d'espaces utilisateur isolés.
Comment l'introduction des machines virtuelles a changé l'industrie et la façon dont les applications ont été déployées?
L'introduction de machines virtuelles a permis aux entreprises de déployer plusieurs applications commerciales sur le même matériel, tandis que chaque application est séparée les unes des autres de manière sécurisée, où chacune fonctionne sur son propre système d'exploitation séparé.
Machines virtuelles
Avons-nous besoin de machines virtuelles à l'ère des conteneurs? Sont-ils toujours pertinents?
Oui, les machines virtuelles sont toujours pertinentes même à l'ère des conteneurs. Bien que les conteneurs fournissent une alternative légère et portable aux machines virtuelles, ils ont certaines limites. Les machines virtuelles comptent toujours car elles offrent l'isolement et la sécurité, peuvent exécuter différents systèmes d'exploitation et sont bons pour les applications héritées. Les limitations des conteneurs, par exemple, partagent le noyau hôte.
Prométhée
Qu'est-ce que Prométhée? Quelles sont certaines des principales caractéristiques de Prometheus?
Prométhée est une boîte à outils de surveillance et d'alerte des systèmes open source populaire, développée à l'origine sur SoundCloud. Il est conçu pour collecter et stocker les données de séries chronologiques et permettre l'interrogation et l'analyse de ces données à l'aide d'un langage de requête puissant appelé PromQL. Prométhée est fréquemment utilisée pour surveiller les applications, les microservices et les autres infrastructures modernes.
Certaines des principales caractéristiques de Prometheus comprennent:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
Dans l'ensemble, Prometheus est un outil puissant et flexible pour surveiller et analyser les systèmes et applications, et est largement utilisé dans l'industrie pour la surveillance et l'observabilité du cloud-natif.
Dans quels scénarios pourraient-ils être mieux de ne pas utiliser Prometheus?
De la documentation de Prometheus: "Si vous avez besoin d'une précision à 100%, comme pour la facturation par la demande".
Décrire l'architecture et les composants de Prometheus
L'architecture Prométhée se compose de quatre composantes majeures:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
Dans l'ensemble, l'architecture Prometheus est conçue pour être très évolutive et résiliente. Les bibliothèques du serveur et des clients peuvent être déployées de manière distribuée pour prendre en charge la surveillance dans des environnements à grande échelle et très dynamiques
Pouvez-vous comparer Prometheus à d'autres solutions comme InfluxDB par exemple?
Par rapport à d'autres solutions de surveillance, telles que InfluxDB, Prométhée est connue pour ses performances et son évolutivité élevées. Il peut gérer de grands volumes de données et peut facilement être intégré à d'autres outils dans l'écosystème de surveillance. InfluxDB, en revanche, est connu pour sa facilité d'utilisation et sa simplicité. Il dispose d'une interface conviviale et fournit des API faciles à utiliser pour la collecte et l'interrogation de données.
Une autre solution populaire, Nagios, est un système de surveillance plus traditionnel qui s'appuie sur un modèle basé sur la poussée pour collecter des données. Nagios existe depuis longtemps et est connu pour sa stabilité et sa fiabilité. Cependant, par rapport à Prometheus, Nagios n'a pas certaines des fonctionnalités les plus avancées, telles que le modèle de données multidimensionnel et le langage de requête puissant.
Dans l'ensemble, le choix d'une solution de surveillance dépend des besoins et des exigences spécifiques de l'organisation. Bien que Prometheus soit un excellent choix pour la surveillance et l'alerte à grande échelle, l'affluxDB peut être mieux adapté aux petits environnements qui nécessitent une facilité d'utilisation et une simplicité. Nagios reste un choix solide pour les organisations qui priorisent la stabilité et la fiabilité par rapport aux fonctionnalités avancées.
Qu'est-ce qu'une alerte?
Dans Prométhée, une alerte est une notification déclenchée lorsqu'une condition ou seuil spécifique est rempli. Les alertes peuvent être configurées pour déclencher lorsque certaines mesures traversent un certain seuil ou lorsque des événements spécifiques se produisent. Une fois qu'une alerte est déclenchée, elle peut être acheminée vers divers canaux, tels que le courrier électronique, le téléavertisseur ou le chat, pour informer les équipes ou les individus concernés pour prendre les mesures appropriées. Les alertes sont un élément essentiel de tout système de surveillance, car ils permettent aux équipes de détecter et de répondre de manière proactive aux problèmes avant d'avoir un impact sur les utilisateurs ou provoquer des temps d'arrêt du système. Qu'est-ce qu'une instance? Qu'est-ce qu'un travail?
Dans Prométhée, une instance fait référence à une seule cible qui est surveillée. Par exemple, un seul serveur ou service. Un travail est un ensemble d'instances qui remplissent la même fonction, comme un ensemble de serveurs Web servant la même application. Les emplois vous permettent de définir et de gérer un groupe de cibles ensemble.
Essentiellement, un exemple est une cible individuelle dont Prométhée recueille des mesures, tandis qu'un travail est une collection d'instances similaires qui peuvent être gérées en tant que groupe.
Quels types de métriques de base soutient Prométhée?
Prométhée prend en charge plusieurs types de mesures, notamment: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prométhée prend également en charge diverses fonctions et opérateurs pour l'agrégation et la manipulation de mesures, telles que Sum, Max, Min et Rate. Ces fonctionnalités en font un outil puissant pour surveiller et alerter les mesures système.
Qu'est-ce qu'un exportateur? A quoi sert-il ?
L'exportateur sert de pont entre le système ou l'application tiers et Prometheus, ce qui permet à Prometheus de surveiller et de collecter des données à partir de ce système ou application. L'exportateur agit comme un serveur, écoutant sur un port réseau spécifique pour les demandes de Prometheus pour gratter les mesures. Il collecte des mesures à partir du système ou de l'application tiers et les transforme en un format qui peut être compris par Prometheus. L'exportateur expose ensuite ces mesures à Prometheus via un point de terminaison HTTP, ce qui les rend disponibles pour la collecte et l'analyse.
Les exportateurs sont couramment utilisés pour surveiller divers types de composants d'infrastructure tels que les bases de données, les serveurs Web et les systèmes de stockage. Par exemple, des exportateurs sont disponibles pour surveiller les bases de données populaires telles que MySQL et PostgreSQL, ainsi que des serveurs Web comme Apache et Nginx.
Dans l'ensemble, les exportateurs sont un élément essentiel de l'écosystème de Prometheus, permettant la surveillance d'un large éventail de systèmes et d'applications, et offrant un degré élevé de flexibilité et d'extensibilité à la plate-forme.
Quelles meilleures pratiques de Prometheus?
Voici trois d'entre eux: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
Comment obtenir des demandes totales dans une période donnée?
Pour obtenir les demandes totales dans une période donnée à l'aide de Prometheus, vous pouvez utiliser la fonction * SUM * avec la fonction * Rate *. Voici un exemple de requête qui vous donnera le nombre total de demandes au cours de la dernière heure: sum(rate(http_requests_total[1h]))
Dans cette requête, http_requests_total est le nom de la métrique qui suit le nombre total de demandes HTTP, et la fonction de taux calcule le taux de demandes par seconde au cours de la dernière heure. La fonction SUM additionne ensuite toutes les demandes pour vous donner le nombre total de demandes au cours de la dernière heure.
Vous pouvez ajuster la plage de temps en modifiant la durée de la fonction de vitesse . Par exemple, si vous vouliez obtenir le nombre total de demandes le dernier jour, vous pouvez modifier la fonction en évaluer (http_requests_total [1d]) .
Qu'est-ce que Ha in Prometheus signifie?
HA signifie haute disponibilité. Cela signifie que le système est conçu pour être très fiable et toujours disponible, même face aux échecs ou à d'autres problèmes. En pratique, cela implique généralement de configurer plusieurs instances de Prometheus et de s'assurer qu'ils sont tous synchronisés et capables de travailler ensemble de manière transparente. Cela peut être réalisé grâce à une variété de techniques, telles que l'équilibrage de la charge, la réplication et les mécanismes de basculement. En mettant en œuvre HA dans Prometheus, les utilisateurs peuvent s'assurer que leurs données de surveillance sont toujours disponibles et à jour, même face aux défaillances matérielles ou logicielles, aux problèmes de réseau ou à d'autres problèmes qui pourraient autrement entraîner des temps d'arrêt ou une perte de données.
Comment rejoignez-vous deux mesures?
Dans Prométhée, l'adhésion à deux mesures peut être réalisée en utilisant la fonction * join () *. La fonction * join () * combine deux séries chronologiques ou plus en fonction de leurs valeurs d'étiquette. Il faut deux arguments obligatoires: * ON * et * TABLE *. L'argument ON spécifie les étiquettes pour rejoindre * ON * et l'argument * Table * Spécifie la série temporelle à rejoindre. Voici un exemple de la façon de rejoindre deux mesures à l'aide de la fonction join () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
Dans cet exemple, la fonction join () combine la série temporelle request_count_total and error_count_total basée sur leurs valeurs de service et d'étiquette d'instance . La fonction sum_series () calcule ensuite la somme de la série chronologique résultante
Comment rédiger une requête qui renvoie la valeur d'une étiquette?
Pour écrire une requête qui renvoie la valeur d'une étiquette dans Prometheus, vous pouvez utiliser la fonction * Label_values *. La fonction * Label_Values * prend deux arguments: le nom de l'étiquette et le nom de la métrique. Par exemple, si vous avez une métrique appelée http_requests_total avec une étiquette appelée méthode , et que vous souhaitez renvoyer toutes les valeurs de l'étiquette de la méthode , vous pouvez utiliser la requête suivante:
label_values(http_requests_total, method)
Cela renverra une liste de toutes les valeurs de l'étiquette de méthode dans la métrique http_requests_total . Vous pouvez ensuite utiliser cette liste dans d'autres requêtes ou pour filtrer vos données.
Comment convertir CPU_USER_SECONDS en utilisation du processeur en pourcentage?
Pour convertir * cpu_user_seconds * en utilisation du processeur en pourcentage, vous devez le diviser par le temps total écoulé et le nombre de cœurs de CPU, puis se multiplier par 100. La formule est la suivante: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
Ici, est le nom du travail que vous souhaitez interroger, est la plage de temps que vous souhaitez interroger (par exemple 5m , 1h ), et est le nombre de cœurs CPU sur la machine que vous interrogez.
Par exemple, pour obtenir l'utilisation du CPU en pourcentage pour les 5 dernières minutes pour un travail nommé My-Job fonctionnant sur une machine avec 4 cœurs CPU, vous pouvez utiliser la requête suivante:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
Aller
Quelles sont les caractéristiques du langage de programmation Go?
- Typage solide et statique - Le type de variables ne peut pas être modifié au fil du temps et ils doivent être définis au moment de la compilation
- Simplicité
- Fast
- Compile Times
- intégrés Concurrence
- Platform collecté
- Platform Indépendamment
- sera compilé en un seul binaire. Très utile pour la gestion des versions dans l'exécution.
Go a également une bonne communauté.
Quelle est la différence entre var x int = 2 et x := 2 ?
Le résultat est le même, une variable avec la valeur 2.
Avec var x int = 2 nous définissons le type de variable sur entier tandis qu'avec x := 2 nous laissons aller à lui-même le type.
Vrai ou faux ? En Go, nous pouvons redémarrer les variables et une fois déclaré, nous devons l'utiliser.
FAUX. Nous ne pouvons pas redémarrer les variables mais oui, nous devons utiliser les variables déclarées.
Quelles bibliothèques de Go avez-vous utilisées?
Cela devrait être répondu en fonction de votre utilisation, mais certains exemples sont:
Quel est le problème avec le bloc de code suivant? Comment y remédier ? func main() {
var x float32 = 13.5
var y int
y = x
}
Le bloc de code suivant essaie de convertir l'entier 101 en une chaîne mais à la place, nous obtenons "E". Pourquoi donc? Comment y remédier ? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Il semble quelle valeur Unicode est définie à 101 et l'utilise pour convertir l'entier en une chaîne. Si vous souhaitez obtenir "101", vous devez utiliser le package "strConv" et remplacer y = string(x) par y = strconv.Itoa(x)
Quel est le problème avec le code suivant ?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Les constantes dans GO ne peuvent être déclarées qu'en utilisant des expressions constantes. Mais x , y et leur somme sont variables.
const initializer x + y is not a constant
Quelle sera la sortie du bloc de code suivant ?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
L'identificateur IOTA de Go est utilisé dans les déclarations const pour simplifier les définitions des nombres incréments. Parce qu'il peut être utilisé dans les expressions, il fournit une généralité au-delà de celle des énumérations simples.
x et y dans le premier groupe Iota, z dans le second.
Page iota dans Go Wiki
À quoi est utilisé dans Go?
Il évite d'avoir à déclarer toutes les variables pour les valeurs de retour. Il s'appelle l'identifiant vierge.
Réponse dans SO
Quelle sera la sortie du bloc de code suivant ?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
Étant donné que le premier IOTA est déclaré avec la valeur 3 ( + 3 ), le suivant a la valeur 4
Quelle sera la sortie du bloc de code suivant ?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
Sortie: 2 1 3
Aritcle sur Sync / WaitGroup
Synchronisation du package Golang
Quelle sera la sortie du bloc de code suivant ?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
Sortir:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
Dans mod1 a est un lien, et lorsque nous utilisons a[i] , nous changeons la valeur s1 . Mais dans mod2 , append crée une nouvelle tranche, et nous ne changeons a valeur, pas s2 .
Aritcle sur les tableaux, article de blog sur append
Quelle sera la sortie du bloc de code suivant ?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
Sortie : 3
Package de conteneur / tas Golang
Mongo
Quels sont les avantages de MongoDB? Ou en d'autres termes, pourquoi choisir MongoDB et non d'autres implémentations de Nosql?
Les avantages MongoDB sont les suivants:
- Schémas
- Facile à évoluer
- Pas de jointures complexes
- La structure d'un seul objet est claire
Quelle est la différence entre SQL et NOSQL?
La principale différence est que les bases de données SQL sont structurées (les données sont stockées sous la forme de tables avec des lignes et des colonnes - comme une table de feuille de calcul Excel) tandis que le NOSQL n'est pas structuré, et le stockage de données peut varier en fonction de la configuration de la base de données noSQL, comme la paire de valeurs clés, les documents, etc.
Dans quels scénarios préférez-vous utiliser Nosql / Mongo sur SQL?
Données hétérogènes qui changent souvent- La cohérence et l'intégrité des données ne sont pas prioritaires
- Meilleur si la base de données doit évoluer rapidement
Qu'est-ce qu'un document? Qu'est-ce qu'une collection?
Un document est un enregistrement dans MongoDB, qui est stocké au format BSON (JSON binaire) et est l'unité de base des données dans MongoDB.- Une collection est un groupe de documents connexes stockés dans une seule base de données dans MongoDB.
Qu'est-ce qu'un agrégateur?
- Un agrégateur est un cadre de MongoDB qui effectue des opérations sur un ensemble de données pour renvoyer un seul résultat calculé.
Quoi de mieux ? Documents intégrés ou référencés?
- Il n'y a pas de réponse définitive à laquelle est mieux, cela dépend du cas d'utilisation et des exigences spécifiques. Certaines explications: les documents intégrés fournissent des mises à jour atomiques, tandis que les documents référencés permettent une meilleure normalisation.
Avez-vous effectué des optimisations de récupération de données à Mongo? Sinon, pouvez-vous réfléchir aux moyens d'optimiser une récupération lente des données?
- Certaines façons d'optimiser la récupération des données dans MongoDB sont les suivantes: indexation, conception de schéma appropriée, optimisation des requêtes et équilibrage de la charge de base de données.
Requêtes
Expliquez cette requête: db.books.find({"name": /abc/})
Expliquez cette requête: db.books.find().sort({x:1})
Quelle est la différence entre trouver () et find_one ()?
find() renvoie tous les documents qui correspondent aux conditions de requête.- find_one () Renvoie un seul document qui correspond aux conditions de requête (ou null si aucune correspondance n'est trouvée).
Comment pouvez-vous exporter des données de Mongo DB?
Mongoexport- langages de programmation
SQL
Exercices SQL
| Nom | Sujet | Objectif et instructions | Solution | Commentaires |
|---|
| Fonctions vs comparaisons | Améliorations de requête | Exercice | Solution | |
Auto-évaluation SQL
Qu'est-ce que SQL?
SQL (Language de requête structuré) est un langage standard pour les bases de données relationnelles (comme MySQL, MariaDB, ...).
Il est utilisé pour la lecture, la mise à jour, la suppression et la création de données dans une base de données relationnelle.
En quoi SQL est-il différent de nosql
La principale différence est que les bases de données SQL sont structurées (les données sont stockées sous la forme de tables avec des lignes et des colonnes - comme une table de feuille de calcul Excel) tandis que le NOSQL n'est pas structuré, et le stockage de données peut varier en fonction de la configuration de la base de données noSQL, comme la paire de valeurs clés, les documents, etc.
Quand est-il préférable d'utiliser SQL? NoSQL?
SQL - Mieux utilisé lorsque l'intégrité des données est cruciale. SQL est généralement mis en œuvre avec de nombreuses entreprises et zones dans le domaine des finances en raison de sa conformité acide.
NoSQL - Génial si vous avez besoin de mettre à l'échelle les choses rapidement. NoSQL a été conçu avec des applications Web à l'esprit, donc cela fonctionne très bien si vous avez besoin de diffuser rapidement les mêmes informations sur plusieurs serveurs
De plus, comme le NOSQL n'adhère pas à la table stricte avec des colonnes et des lignes de structure que les bases de données relationnelles nécessitent, vous pouvez stocker différents types de données ensemble.
SQL pratique - bases
Pour ces questions, nous utiliserons les tables des clients et des commandes illustrés ci-dessous:
Clients
| Client_id | Customer_name | Items_in_cart | Cash_Spent_To_Date |
|---|
| 100204 | John Smith | 0 | 20h00 |
| 100205 | Jeanne Smith | 3 | 40h00 |
| 100206 | Bobby Frank | 1 | 100.20 |
ORDRES
| Client_id | Order_id | Article | Prix | Date_sold |
|---|
| 100206 | A123 | Canard en caoutchouc | 2.20 | 2019-09-18 |
| 100206 | A123 | Bain moussant | 8h00 | 2019-09-18 |
| 100206 | Q987 | TP de 80 packs | 90.00 | 2019-09-20 |
| 100205 | Z001 | Nourriture pour chats - Poisson de thon | 10h00 | 2019-08-05 |
| 100205 | Z001 | Nourriture pour chats - poulet | 10h00 | 2019-08-05 |
| 100205 | Z001 | Nourriture pour chats - bœuf | 10h00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Kitty Quesadilla | 10h00 | 2019-08-05 |
| 100204 | X202 | Café | 20h00 | 2019-04-29 |
Comment pourrais-je sélectionner tous les champs de ce tableau?
Sélectionner *
Des clients;
Combien d'articles y a-t-il dans le panier de John?
Sélectionnez des éléments_in_cart
Des clients
Où client_name = "John Smith";
Quelle est la somme de tout l'argent dépensé à tous les clients?
Sélectionnez SUM (Cash_Spent_To_Date) comme sum_cash
Des clients;
Combien de personnes ont des articles dans leur panier?
Sélectionnez Count (1) comme numéro_of_people_w_items
Des clients
où items_in_cart> 0;
Comment rejoigneriez-vous le tableau des clients à la table de commandes?
Vous les rejoindrez sur la clé unique. Dans ce cas, la clé unique est Customer_ID dans la table des clients et la table des commandes
Comment montreriez-vous quel client a commandé quels articles?
Sélectionnez C.Customer_name, O.Item
Des clients c
Gauche jointer les ordres o
Sur c.Customer_id = o.customer_id;
En utilisant une déclaration avec une déclaration, comment montreriez-vous qui a commandé de la nourriture pour chats et le montant total dépensé?
avec cat_food comme (
Sélectionnez Customer_ID, SUM (Prix) As Total_price
Des commandes
Où des articles comme "% de nourriture pour chats%"
Groupe par client_id
)
Sélectionnez Customer_name, Total_price
Des clients c
Inner Join Cat_food F
Sur c.Customer_id = f.Customer_id
où C.Customer_ID IN (sélectionnez Customer_ID FROM CAT_FOOD);
Bien qu'il s'agisse d'une déclaration simple, la clause "avec" brille vraiment lorsqu'une requête complexe doit être exécutée sur une table avant de se joindre à une autre. Avec les déclarations sont sympas, car vous créez une pseudo tempor lors de l'exécution de votre requête, au lieu de créer une toute nouvelle table.
La somme de tous les achats de nourriture pour chats n'était pas facilement disponible, nous avons donc utilisé une déclaration avec une déclaration pour créer la pseudo-table pour récupérer la somme des prix dépensés par chaque client, puis rejoindre la table normalement.
Laquelle des requêtes suivantes utiliseriez-vous? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
Lorsque vous utilisez une fonction ( YEAR(purchased_at) ), elle doit scanner toute la base de données plutôt que l'utilisation d'index et essentiellement la colonne telle qu'elle est, dans son état naturel.
OpenStack
Quels composants / projets d'OpenStack connaissez-vous?
Pouvez-vous me dire de quoi chacun des services / projets suivants est responsable ?:- Nova
- Neutron
- Cendre
- Coup d'oeil
- Clé de voûte
Nova - Gérer les instances virtuelles- Neutron - Gérer le réseautage en fournissant un réseau en tant que service (NAAS)
- Cinder - Block Storage
- Glance - Gérer les images pour les machines virtuelles et les conteneurs (recherche, obtenez et inscrivez-vous)
- Keystone - Service d'authentification à travers le cloud
Identifiez le service / projet utilisé pour chacun des éléments suivants:- Copier ou instance d'instantané
- GUI pour la visualisation et la modification des ressources
- Blocage de blocage
- Gérer les instances virtuelles
Glance - Service d'images. Également utilisé pour la copie ou les instances d'instantané- Horizon - GUI pour la visualisation et la modification des ressources
- Cinder - Block Storage
- Nova - Gérer les instances virtuelles
Qu'est-ce qu'un locataire / projet?
Déterminer vrai ou faux:- OpenStack est gratuit
- Le service responsable du réseautage est un coup d'œil
- Le but du locataire / du projet est de partager des ressources entre différents projets et les utilisateurs d'OpenStack
Décrivez en détail comment vous apportez une instance avec une adresse IP flottante
Vous recevez un appel d'un client disant: "Je peux ping mon instance mais je ne peux pas le connecter (SSH)". Quel pourrait être le problème?
Quels types de réseaux prennent en charge OpenStack?
Comment déboguez-vous les problèmes de stockage d'OpenStack? (Outils, journaux, ...)
Comment déboguez-vous les problèmes de calcul OpenStack? (Outils, journaux, ...)
OpenStack Deployment & Tripleo
Avez-vous déployé OpenStack dans le passé? Si oui, pouvez-vous décrire comment vous l'avez fait?
Connaissez-vous Tripleo? En quoi est-ce différent de DevStack ou Packstack?
Vous pouvez lire sur Tripleo ici
Calcul OpenStack
Pouvez-vous décrire Nova en détail?
Utilisé pour provisionner et gérer les instances virtuelles- Il prend en charge la multi-tension à différents niveaux - journalisation, contrôle de l'utilisateur final, audit, etc.
- Très évolutif
- L'authentification peut être effectuée en utilisant un système interne ou un LDAP
- Prend en charge plusieurs types de stockage de blocs
- Essaie d'être du matériel et de l'hyperviseur Agnostice
Que savez-vous de l'architecture et des composants Nova?
Nova-API - Le serveur qui sert les métadonnées et calcule les API- Les différents composants Nova communiquent en utilisant une file d'attente (Rabbitmq généralement) et une base de données
- Une demande de création d'une instance est inspectée par Nova-Scheduler qui détermine où l'instance sera créée et en cours d'exécution
- Nova-Compute est le composant responsable de la communication avec l'hyperviseur pour créer l'instance et gérer son cycle de vie
OpenStack Networking (Neutron)
Expliquez le neutron en détail
L'un des composants principaux d'OpenStack et un projet autonome- Neutron s'est concentré sur la livraison de réseautage en tant que service
- Avec Neutron, les utilisateurs peuvent configurer des réseaux dans le cloud et configurer et gérer une variété de services réseau
- Le neutron interagit avec:
Keystone - Autoriser les appels d'API
- Nova - Nova communique avec les neutrons pour brancher le NICS sur un réseau
- Horizon - prend en charge les entités de réseautage dans le tableau de bord et fournit également une vue de topologie qui comprend les détails de réseautage
Expliquez chacun des composants suivants:- neutron-dhcp-agent
- neutron-l3-agent
- agent de création à neutrons
- neutron - * - agtent
- serveur à neutrons
Neutron-L3-Agent - L3 / NAT Forwarding (fournit un accès au réseau externe pour les machines virtuelles par exemple)- Neutron-DHCP-Agent - Services DHCP
- Neutron-Metering-Agent - L3 Metting Traffic Metering
- Neutron - * - Agtent - gère la configuration de vSwitch locale sur chaque calcul (basé sur le plugin choisi)
- Neutron-Server - expose l'API de mise en réseau et transmet les demandes à d'autres plugins si nécessaire
Expliquez ces types de réseau:- Réseau de gestion
- Réseau d'invité
- Réseau API
- Réseau externe
Réseau de gestion - Utilisé pour la communication interne entre les composants OpenStack. Toute adresse IP dans ce réseau est accessible uniquement dans le datacetner- Réseau invité - Utilisé pour la communication entre les instances / VM
- Réseau API - Utilisé pour les services Communication API. Toute adresse IP dans ce réseau est accessible au public
- Réseau externe - Utilisé pour la communication publique. Toute adresse IP dans ce réseau est accessible par quiconque sur Internet
Dans quel ordre devez-vous supprimer les entités suivantes:- Réseau
- Port
- Routeur
- Sous-réseau
- Réseau
- de routeurs
- de sous-réseau
- port
Il y a de nombreuses raisons à cela. Un par exemple: vous ne pouvez pas supprimer le routeur s'il y a des ports actifs qui lui sont affectés.
Qu'est-ce qu'un réseau de prestataires?
Quels composants et services existent pour L2 et L3?
Quel est le plug-in ML2? Expliquez son architecture
Qu'est-ce que l'agent L2? Comment cela fonctionne-t-il et de quoi est-il responsable?
Qu'est-ce que l'agent L3? Comment cela fonctionne-t-il et de quoi est-il responsable?
Expliquez ce que l'agent de métadonnées est responsable
Quelle est la prise en charge des neutrons de réseautage?
Comment déboguez-vous les problèmes de réseautage OpenStack? (Outils, journaux, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
Vrai ou faux ? there can be two objects with the same name in the same container but not in two different containers
FAUX. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- Rôle
- Tenant/Project
- Service
- Point de terminaison
- Jeton
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
En utilisant:
Nom- Numéro d'identification
- Taper
- Description
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- Rapide
- Sahara
- Ironique
- Trove
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- PAM
- Memcached
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Fantoche
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
Élastique
What is the Elastic Stack?
The Elastic Stack consists of:
- Recherche élastique
- Kibana
- Logstash
- Battements
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Recherche élastique
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. Qu'est-ce que ça veut dire? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
Vrai ou faux ? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
FAUX. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
_indice- _identifiant
- _taper
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". Qu'est-ce que ça veut dire?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? À quoi l’utiliseriez-vous ?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Kibana
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". Qu'est-ce que ça veut dire?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Lire ici
Vrai ou faux ? a single harvester harvest multiple files, according to the limits set in filebeat.yml
FAUX. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Elastic Stack
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Distribué
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Réseau- Processeur
- Mémoire
- Disque
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
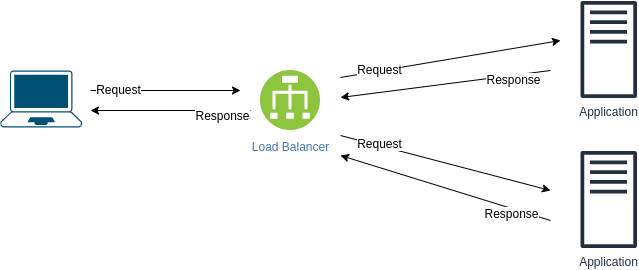
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage , mémoire, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Misc
| Nom | Sujet | Objective & Instructions | Solution | Commentaires |
|---|
| Highly Available "Hello World" | Exercice | Solution | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
Vrai ou faux ? API Definition is the same as API Specification
FAUX. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
Avantages :
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
Autorisation- Enregistrement
- Authentification
- Ordering
- L'extrémité avant
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Lequel utiliseriez-vous ? Pourquoi?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
Vrai ou faux ? Any valid JSON file is also a valid YAML file
Vrai. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
Micrologiciel
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
Cassandre
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
Qu'est-ce que HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- Réponse HTTP
Vrai ou faux ? HTTP is stateful
FAUX. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
OBTENIR- POSTE
- TÊTE
- METTRE
- SUPPRIMER
- CONNECTER
- OPTIONS
- TRACER
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. Qu'est-ce que ça veut dire?
The server didn't receive a response from another server it communicates with in a timely manner.
Qu'est-ce qu'un proxy ?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Tournoi à la ronde- Tournoi à la ronde pondéré
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
Inconvénients :
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Cookies. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Tournoi à la ronde
- Tournoi à la ronde pondéré
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Licences
Are you familiar with "Creative Commons"? Qu'en savez-vous ?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Aléatoire
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. Source
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
Stockage
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
Avantages :
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
Avantages :
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Essai
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
Extrait
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
Remplacer
Replace tabs with four spaces
Replace 'red' with 'green'
Conception du système
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Évolutivité
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
Jetez un oeil ici
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Matériel
Qu'est-ce qu'un processeur ?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
Externe- Machine check
- I/O
- Programme
- Redémarrage
- Supervisor call (SVC)
Mégadonnées
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Céph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. Vrai ou faux ? Ceph favor consistency and correctness over performances
Vrai Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
Moniteur- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Directeur
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? Comment ça marche ?
Emballeur
What is Packer? A quoi sert-il ?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Libérer
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Certificats
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Bonne chance :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
Azuré
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




Crédits
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
Licence


