homemade machine learning
1.0.0
?? L'UKRAINE EST ATTAQUÉE PAR L'ARMÉE RUSSE. DES CIVILS SONT TUÉS. LES ZONES RÉSIDENTIELLES SONT BOMBÉES.
- Aidez l’Ukraine via :
- Fondation caritative Serhiy Prytula
- Fondation caritative Come Back Alive
- Banque nationale d'Ukraine
- Plus d’informations sur war.ukraine.ua et le ministère des Affaires étrangères d’Ukraine
Lisez ceci dans d'autres langues : Español
Vous pourriez être intéressé par :
- GPT fait maison • JS
- Expériences interactives d'apprentissage automatique
Pour la version Octave/MatLab de ce référentiel, veuillez consulter le projet machine-learning-octave.
Ce référentiel contient des exemples d'algorithmes d'apprentissage automatique populaires implémentés en Python , les mathématiques sous-jacentes étant expliquées. Chaque algorithme dispose d'une démo interactive Jupyter Notebook qui vous permet de jouer avec les données d'entraînement, les configurations des algorithmes et de voir immédiatement les résultats, les graphiques et les prédictions directement dans votre navigateur . Dans la plupart des cas, les explications sont basées sur cet excellent cours d'apprentissage automatique d'Andrew Ng.
Le but de ce référentiel n'est pas d'implémenter des algorithmes d'apprentissage automatique en utilisant des bibliothèques tierces , mais plutôt de s'entraîner à implémenter ces algorithmes à partir de zéro et de mieux comprendre les mathématiques derrière chaque algorithme. C'est pourquoi toutes les implémentations d'algorithmes sont dites « faites maison » et ne sont pas destinées à être utilisées en production.
Dans l'apprentissage supervisé, nous avons un ensemble de données d'entraînement comme entrée et un ensemble d'étiquettes ou de « réponses correctes » pour chaque ensemble d'entraînement comme sortie. Ensuite, nous entraînons notre modèle (paramètres de l'algorithme d'apprentissage automatique) pour mapper correctement l'entrée à la sortie (pour effectuer une prédiction correcte). Le but ultime est de trouver de tels paramètres de modèle qui permettront de continuer avec succès le mappage entrée → sortie (prédictions) correct, même pour de nouveaux exemples d'entrée.
Dans les problèmes de régression, nous effectuons des prédictions de valeurs réelles. Fondamentalement, nous essayons de dessiner une ligne/un plan/un plan à n dimensions le long des exemples de formation.
Exemples d'utilisation : prévision du cours des actions, analyse des ventes, dépendance d'un nombre quelconque, etc.
country happiness en fonction economy GDPcountry happiness en fonction du economy GDP et freedom indexDans les problèmes de classification, nous divisons les exemples d'entrée selon certaines caractéristiques.
Exemples d'utilisation : filtres anti-spam, détection de langue, recherche de documents similaires, reconnaissance de lettres manuscrites, etc.
class de fleurs d'iris en fonction de petal_length et petal_widthvalidity de la micropuce en fonction de param_1 et param_228x28 pixels28x28 pixels L'apprentissage non supervisé est une branche de l'apprentissage automatique qui apprend à partir de données de test qui n'ont pas été étiquetées, classées ou catégorisées. Au lieu de répondre aux commentaires, l'apprentissage non supervisé identifie les points communs dans les données et réagit en fonction de la présence ou de l'absence de ces points communs dans chaque nouvel élément de données.
Dans les problèmes de clustering, nous divisons les exemples de formation selon des caractéristiques inconnues. L'algorithme lui-même décide quelle caractéristique utiliser pour le fractionnement.
Exemples d'utilisation : segmentation de marché, analyse des réseaux sociaux, organisation de clusters informatiques, analyse de données astronomiques, compression d'images, etc.
petal_length et petal_widthLa détection d'anomalies (également la détection de valeurs aberrantes) est l'identification d'éléments, d'événements ou d'observations rares qui éveillent des soupçons en différant considérablement de la majorité des données.
Exemples d'utilisation : détection d'intrusion, détection de fraude, surveillance de l'état du système, suppression des données anormales de l'ensemble de données, etc.
latency et threshold Le réseau neuronal en lui-même n'est pas un algorithme, mais plutôt un cadre permettant à de nombreux algorithmes d'apprentissage automatique différents de travailler ensemble et de traiter des entrées de données complexes.
Exemples d'utilisation : en remplacement de tous les autres algorithmes en général, reconnaissance d'images, reconnaissance vocale, traitement d'images (en appliquant un style spécifique), traduction linguistique, etc.
28x28 pixels28x28 pixels 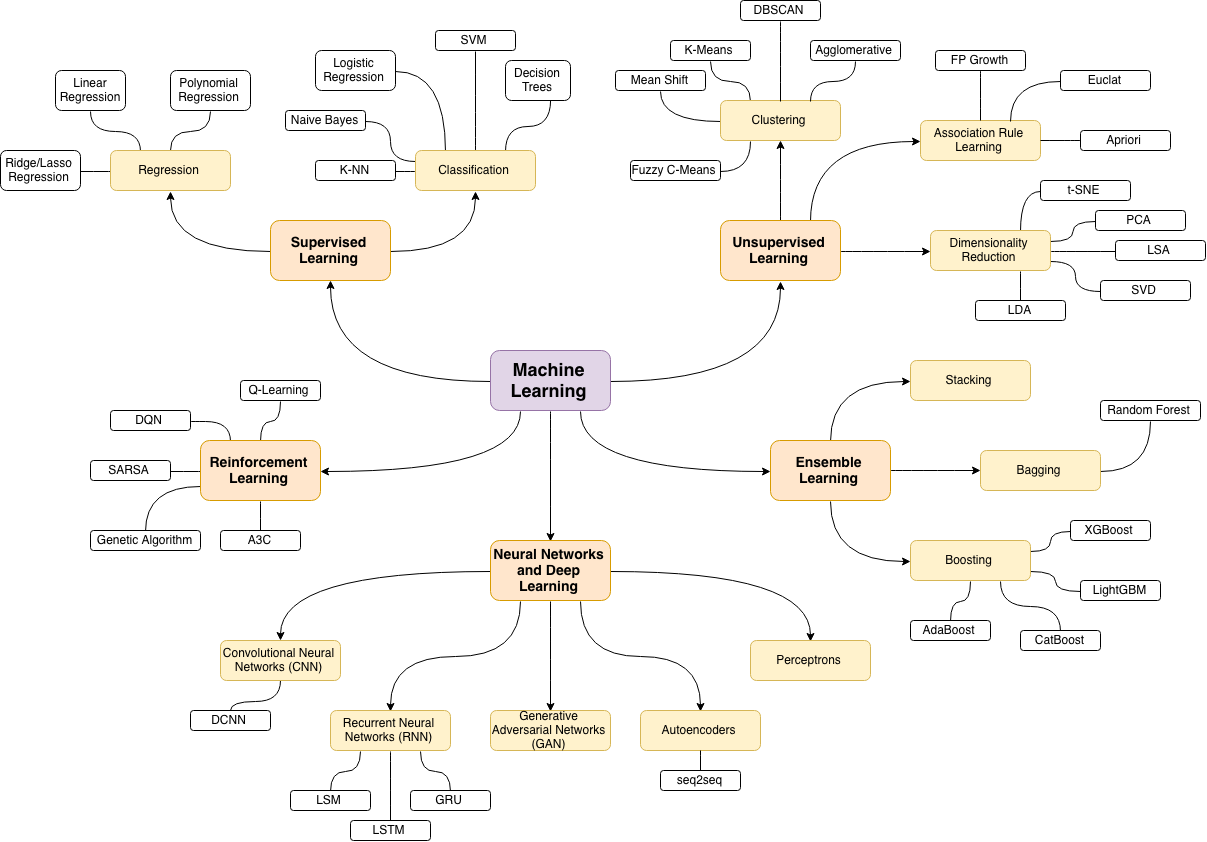
La source de la carte suivante des sujets d'apprentissage automatique est ce merveilleux article de blog
Assurez-vous que Python est installé sur votre ordinateur.
Vous souhaiterez peut-être utiliser la bibliothèque Python standard venv pour créer des environnements virtuels et installer et servir Python, pip et tous les packages dépendants à partir du répertoire de projet local afin d'éviter de jouer avec les packages à l'échelle du système et leurs versions.
Installez toutes les dépendances requises pour le projet en exécutant :
pip install -r requirements.txtToutes les démos du projet peuvent être exécutées directement dans votre navigateur sans installer Jupyter localement. Mais si vous souhaitez lancer Jupyter Notebook localement, vous pouvez le faire en exécutant la commande suivante à partir du dossier racine du projet :
jupyter notebook Après cela, Jupyter Notebook sera accessible par http://localhost:8888 .
Chaque section d'algorithme contient des liens de démonstration vers Jupyter NBViewer. Il s'agit d'un aperçu en ligne rapide pour les blocs-notes Jupyter où vous pouvez voir le code de démonstration, les graphiques et les données directement dans votre navigateur sans rien installer localement. Si vous souhaitez modifier le code et expérimenter le bloc-notes de démonstration, vous devez lancer le bloc-notes dans Binder. Vous pouvez le faire en cliquant simplement sur le lien « Exécuter sur le classeur » dans le coin supérieur droit de NBViewer.
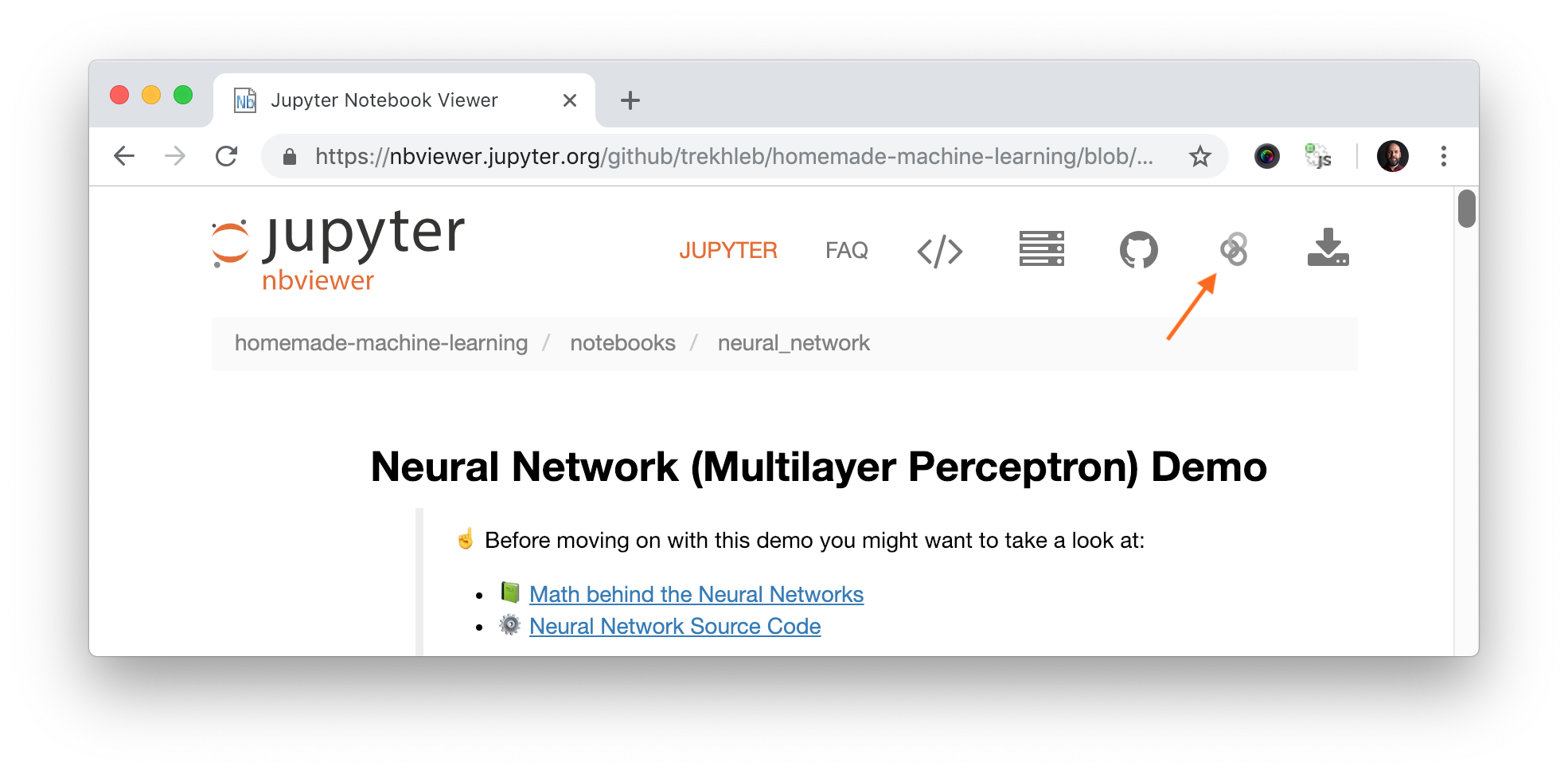
La liste des ensembles de données utilisés pour les démos Jupyter Notebook se trouve dans le dossier de données.
Vous pouvez soutenir ce projet via ❤️️ GitHub ou ❤️️ Patreon.


