stumpy
v1.13.0

STUMPY est une bibliothèque Python puissante et évolutive qui calcule efficacement ce qu'on appelle le profil matriciel, qui n'est qu'une façon académique de dire "pour chaque sous-séquence (verte) de votre série temporelle, identifiez automatiquement son voisin le plus proche (gris)" :
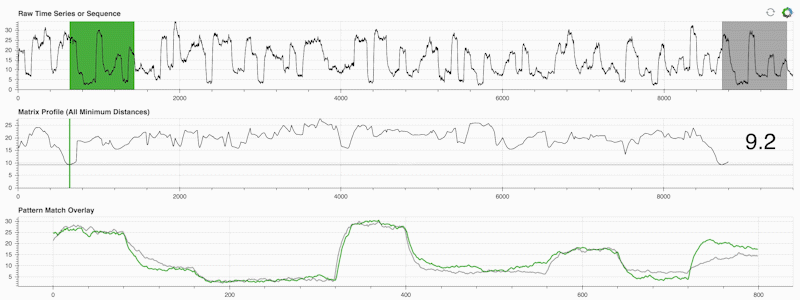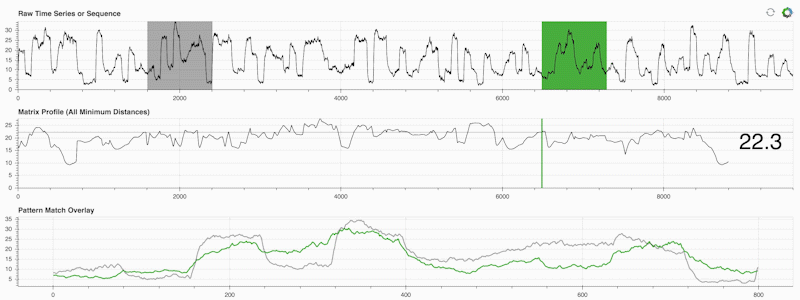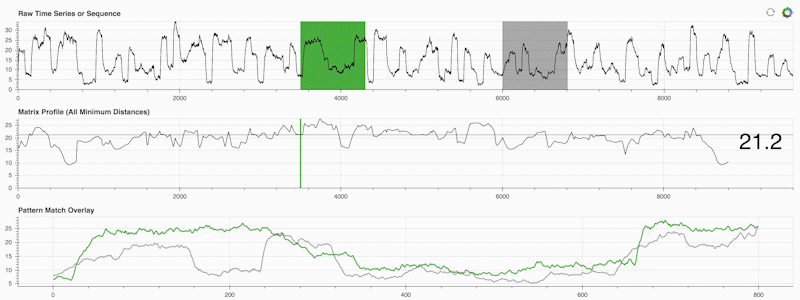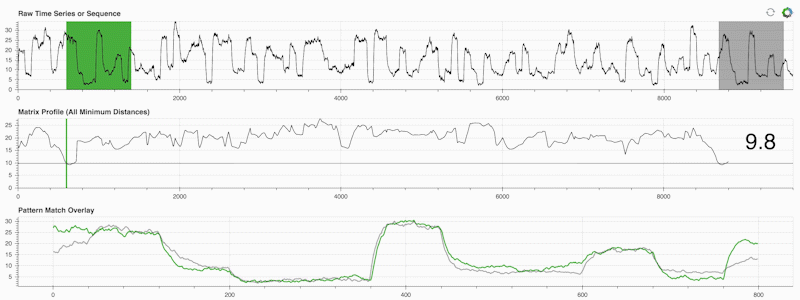
Ce qui est important, c'est qu'une fois que vous avez calculé votre profil matriciel (panneau du milieu ci-dessus), il peut ensuite être utilisé pour diverses tâches d'exploration de données de séries chronologiques telles que :
Que vous soyez un universitaire, un data scientist, un développeur de logiciels ou un passionné de séries chronologiques, STUMPY est simple à installer et notre objectif est de vous permettre d'accéder plus rapidement à vos informations sur les séries chronologiques. Voir la documentation pour plus d'informations.
Veuillez consulter notre documentation API pour une liste complète des fonctions disponibles et consulter nos didacticiels informatifs pour des exemples de cas d'utilisation plus complets. Ci-dessous, vous trouverez des extraits de code qui montrent rapidement comment utiliser STUMPY.
Utilisation typique (données de séries chronologiques unidimensionnelles) avec STUMP :
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )Utilisation distribuée pour les données de séries chronologiques unidimensionnelles avec Dask Distributed via STUMPED :
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )Utilisation du GPU pour les données de séries chronologiques unidimensionnelles avec GPU-STUMP :
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )Données de séries chronologiques multidimensionnelles avec MSTUMP :
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )Analyse de données de séries chronologiques multidimensionnelles distribuées avec Dask Distributed MSTUMPED :
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )Chaînes de séries chronologiques avec chaînes de séries chronologiques ancrées (ATSC) :
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )Segmentation sémantique avec segmentation sémantique unipotente rapide et peu coûteuse (FLUSS) :
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)Les versions Python et NumPy prises en charge sont déterminées conformément à la politique de dépréciation NEP 29.
Installation de Conda (de préférence) :
conda install -c conda-forge stumpyInstallation de PyPI, en supposant que numpy, scipy et numba soient installés :
python -m pip install stumpyPour installer Stumpy à partir des sources, consultez les instructions dans la documentation.
Afin de bien comprendre et apprécier les algorithmes et applications sous-jacents, il est impératif que vous lisiez les publications originales. Pour un exemple plus détaillé de la façon d'utiliser STUMPY, veuillez consulter la dernière documentation ou explorer nos didacticiels pratiques.
Nous avons testé les performances de calcul du profil matriciel exact à l'aide de la version compilée Numba JIT du code sur des données de séries chronologiques générées aléatoirement de différentes longueurs (c'est-à-dire np.random.rand(n) ) ainsi que différentes ressources matérielles CPU et GPU.
Les résultats bruts sont affichés dans le tableau ci-dessous sous la forme Heures:Minutes:Secondes.Millisecondes et avec une taille de fenêtre constante de m = 50. Notez que ces durées d'exécution signalées incluent le temps nécessaire pour déplacer les données de l'hôte vers tous les Périphérique(s) GPU. Vous devrez peut-être faire défiler vers la droite du tableau pour voir tous les environnements d'exécution.
| je | n = 2 je | GPU-STOMP | SOUCHE.2 | SOUCHE.16 | PERDU.128 | Perplexe.256 | GPU-STUMP.1 | GPU-STUMP.2 | GPU-STUMP.DGX1 | GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | NaN | NaN |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | NaN | NaN |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 512 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048 | NaN | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | NaN | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | NaN | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | NaN | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | NaN | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | NaN | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | NaN | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | NaN | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | NaN | NaN | NaN | 14:39:11,99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| NaN | 17729800 | 09:16:12.00 | NaN | NaN | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | NaN | NaN | NaN | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | NaN | NaN | NaN | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15,94 | 07:18:52.91 |
| NaN | 100000000 | 291:07:12.00 | NaN | NaN | NaN | 234:51:35.39 | NaN | NaN | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP : ces résultats sont reproduits à partir du document original Matrix Profile II - NVIDIA Tesla K80 (contient 2 GPU) et servent de référence de performances à comparer.
STUMP.2 : stumpy.stump exécuté avec 2 processeurs au total - 2x processeurs Intel(R) Xeon(R) E5-2650 v4 à 2,20 GHz parallélisés avec Numba sur un seul serveur sans Dask.
STUMP.16 : stumpy.stump exécuté avec 16 processeurs au total - 16x processeurs Intel(R) Xeon(R) E5-2650 v4 à 2,20 GHz parallélisés avec Numba sur un seul serveur sans Dask.
STUMPED.128 : stumpy.stumped exécuté avec 128 processeurs au total - 8x processeur Intel(R) Xeon(R) E5-2650 v4 à 2,20 GHz x 16 serveurs, parallélisés avec Numba et distribués avec Dask Distributed.
STUMPED.256 : stumpy.stumped exécuté avec 256 processeurs au total - 8x processeurs Intel(R) Xeon(R) E5-2650 v4 à 2,20 GHz x 32 serveurs, parallélisés avec Numba et distribués avec Dask Distributed.
GPU-STUMP.1 : stumpy.gpu_stump exécuté avec 1x GPU NVIDIA GeForce GTX 1080 Ti, 512 threads par bloc, limite de puissance de 200 W, compilé sur CUDA avec Numba et parallélisé avec le multitraitement Python
GPU-STUMP.2 : stumpy.gpu_stump exécuté avec 2x GPU NVIDIA GeForce GTX 1080 Ti, 512 threads par bloc, limite de puissance de 200 W, compilé sur CUDA avec Numba et parallélisé avec le multitraitement Python
GPU-STUMP.DGX1 : stumpy.gpu_stump exécuté avec 8x NVIDIA Tesla V100, 512 threads par bloc, compilé sur CUDA avec Numba et parallélisé avec le multitraitement Python
GPU-STUMP.DGX2 : stumpy.gpu_stump exécuté avec 16x NVIDIA Tesla V100, 512 threads par bloc, compilé sur CUDA avec Numba et parallélisé avec le multitraitement Python
Les tests sont écrits dans le répertoire tests et traités à l'aide de PyTest et nécessitent coverage.py pour l'analyse de la couverture du code. Les tests peuvent être exécutés avec :
./test.shSTUMPY prend en charge Python 3.9+ et, en raison de l'utilisation de noms/identifiants de variables Unicode, n'est pas compatible avec Python 2.x. Compte tenu des petites dépendances, STUMPY peut fonctionner sur les anciennes versions de Python mais cela dépasse la portée de notre support et nous vous recommandons fortement de passer à la version la plus récente de Python.
Tout d’abord, veuillez consulter les discussions et les problèmes sur Github pour voir si votre question y a déjà trouvé une réponse. Si aucune solution n'est disponible, n'hésitez pas à ouvrir une nouvelle discussion ou un nouveau problème et les auteurs tenteront d'y répondre dans un délai raisonnable.
Nous acceptons les contributions sous toutes leurs formes ! L'aide pour la documentation, en particulier les didacticiels d'extension, est toujours la bienvenue. Pour contribuer, veuillez créer le projet, apporter vos modifications et soumettre une pull request. Nous ferons de notre mieux pour résoudre tout problème avec vous et fusionner votre code dans la branche principale.
Si vous avez utilisé cette base de code dans une publication scientifique et souhaitez la citer, veuillez utiliser l'article du Journal of Open Source Software.
Loi SM, (2019). STUMPY : une bibliothèque Python puissante et évolutive pour l'exploration de données de séries chronologiques . Journal des logiciels open source, 4(39), 1504.
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}Ouais, Chin-Chia Michael, et al. (2016) Matrix Profile I : Toutes les paires de similarités se joignent pour les séries chronologiques : une vue unificatrice qui inclut les motifs, les discordes et les shapelets. ICDM : 1317-1322. Lien
Zhu, Yan et coll. (2016) Matrix Profile II : Exploiter un nouvel algorithme et des GPU pour briser la barrière des cent millions pour les motifs et les jointures de séries chronologiques. ICDM : 739-748. Lien
Ouais, Chin-Chia Michael, et al. (2017) Matrix Profile VI : Découverte significative de motifs multidimensionnels. ICDM : 565-574. Lien
Zhu, Yan et coll. (2017) Matrix Profile VII : Chaînes de séries chronologiques : une nouvelle primitive pour l'exploration de données de séries chronologiques. ICDM : 695-704. Lien
Gharghabi, Shaghayegh et al. (2017) Matrix Profile VIII : Segmentation sémantique en ligne indépendante du domaine à des niveaux de performance surhumains. ICDM : 117-126. Lien
Zhu, Yan et coll. (2017) Exploiter un nouvel algorithme et des GPU pour briser la barrière des dix quadrillions de comparaisons par paires pour les motifs et les jointures de séries chronologiques. KAIS : 203-236. Lien
Zhu, Yan et coll. (2018) Matrix Profile XI : SCRIMP++ : Découverte de motifs de séries temporelles à des vitesses interactives. ICDM : 837-846. Lien
Ouais, Chin-Chia Michael, et al. (2018) Jointures de séries chronologiques, motifs, discordes et shapelets : une vue unificatrice qui exploite le profil matriciel. Disque de connaissances minimum de données : 83-123. Lien
Gharghabi, Shaghayegh et al. (2018) « Matrix Profile XII : MPdist : une nouvelle mesure de distance de série chronologique pour permettre l'exploration de données dans des scénarios plus difficiles. » ICDM : 965-970. Lien
Zimmerman, Zachary et coll. (2019) Matrix Profile XIV : mise à l'échelle de la découverte de motifs de séries chronologiques avec des GPU pour briser un quintillion de comparaisons par paires par jour et au-delà. SoCC'19 : 74-86. Lien
Akbarinia, Reza et Betrand Cloez. (2019) Calcul efficace du profil matriciel utilisant différentes fonctions de distance. arXiv : 1901.05708. Lien
Kamgar, Kaveh et coll. (2019) Matrix Profile XV : Exploiter les motifs de consensus des séries chronologiques pour trouver la structure dans les ensembles de séries chronologiques. ICDM : 1156-1161. Lien


