memray
v1.15.0
Memray est un profileur de mémoire pour Python. Il peut suivre les allocations de mémoire dans le code Python, dans les modules d'extension natifs et dans l'interpréteur Python lui-même. Il peut générer plusieurs types de rapports différents pour vous aider à analyser les données capturées sur l'utilisation de la mémoire. Bien qu'il soit couramment utilisé comme outil CLI, il peut également être utilisé comme bibliothèque pour effectuer des tâches de profilage plus fines.
Caractéristiques notables :
Memray peut vous aider à résoudre les problèmes suivants :
Remarque Memray ne fonctionne que sous Linux et MacOS et ne peut pas être installé sur d'autres plates-formes.
Nous recherchons constamment les commentaires de notre formidable communauté ❤️. Si vous avez utilisé Memray pour résoudre un problème, profiler une application, trouver une fuite de mémoire ou toute autre chose, faites-le nous savoir ! Nous serions ravis de connaître votre expérience et comment Memray vous a aidé.
S'il vous plaît, envisagez d'écrire votre histoire sur la page de discussion Histoires de réussite.
Cela fait vraiment une différence !
Memray nécessite Python 3.7+ et peut être facilement installé à l'aide des outils de packaging Python les plus courants. Nous vous recommandons d'installer la dernière version stable de PyPI avec pip :
python3 -m pip install memrayNotez que Memray contient une extension C, donc les versions sont distribuées sous forme de roues binaires ainsi que le code source. Si une roue binaire n'est pas disponible pour votre système (Linux x86/x64 ou macOS), vous devrez vous assurer que toutes les dépendances sont satisfaites sur le système sur lequel vous effectuez l'installation.
Si vous souhaitez construire Memray à partir des sources, vous avez besoin des dépendances binaires suivantes dans votre système :
Vérifiez votre gestionnaire de paquets pour savoir comment installer ces dépendances (par exemple apt-get install build-essential python3-dev libdebuginfod-dev libunwind-dev liblz4-dev dans les systèmes basés sur Debian ou brew install lz4 sous MacOS). Notez que vous devrez peut-être apprendre au compilateur où trouver les fichiers d'en-tête et de bibliothèque des dépendances. Par exemple, sous MacOS avec brew vous devrez peut-être exécuter :
export CFLAGS= " -I $( brew --prefix lz4 ) /include " LDFLAGS= " -L $( brew --prefix lz4 ) /lib -Wl,-rpath, $( brew --prefix lz4 ) /lib " avant d'installer memray . Consultez la documentation de votre gestionnaire de packages pour connaître l'emplacement des fichiers d'en-tête et de bibliothèque pour des informations plus détaillées.
Si vous construisez sur MacOS, vous devrez également définir la cible de déploiement.
export MACOSX_DEPLOYMENT_TARGET=10.14Une fois les dépendances binaires installées, vous pouvez cloner le référentiel et suivre le processus de construction normal :
git clone [email protected]:bloomberg/memray.git memray
cd memray
python3 -m venv ../memray-env/ # just an example, put this wherever you want
source ../memray-env/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install -e . -r requirements-test.txt -r requirements-extra.txt Cela installera Memray dans l'environnement virtuel en mode développement (le -e de la dernière commande pip install ).
Si vous envisagez de contribuer en retour, vous devez installer les hooks de pré-commit :
pre-commit installCela garantira que votre contribution passe nos contrôles de peluchage.
Vous pouvez trouver la dernière documentation disponible ici.
Il existe de nombreuses façons d'utiliser Memray. Le moyen le plus simple consiste à l'utiliser comme outil de ligne de commande pour exécuter votre script, votre application ou votre bibliothèque.
usage: memray [-h] [-v] {run,flamegraph,table,live,tree,parse,summary,stats} ...
Memory profiler for Python applications
Run `memray run` to generate a memory profile report, then use a reporter command
such as `memray flamegraph` or `memray table` to convert the results into HTML.
Example:
$ python3 -m memray run -o output.bin my_script.py
$ python3 -m memray flamegraph output.bin
positional arguments:
{run,flamegraph,table,live,tree,parse,summary,stats}
Mode of operation
run Run the specified application and track memory usage
flamegraph Generate an HTML flame graph for peak memory usage
table Generate an HTML table with all records in the peak memory usage
live Remotely monitor allocations in a text-based interface
tree Generate a tree view in the terminal for peak memory usage
parse Debug a results file by parsing and printing each record in it
summary Generate a terminal-based summary report of the functions that allocate most memory
stats Generate high level stats of the memory usage in the terminal
optional arguments:
-h, --help Show this help message and exit
-v, --verbose Increase verbosity. Option is additive and can be specified up to 3 times
-V, --version Displays the current version of Memray
Please submit feedback, ideas, and bug reports by filing a new issue at https://github.com/bloomberg/memray/issues
Pour utiliser Memray sur un script ou un seul fichier python, vous pouvez utiliser :
python3 -m memray run my_script.py Si vous exécutez normalement votre application avec python3 -m my_module , vous pouvez utiliser l'indicateur -m avec memray run :
python3 -m memray run -m my_module Vous pouvez également appeler Memray en tant qu'outil de ligne de commande sans avoir à utiliser -m pour l'invoquer en tant que module :
memray run my_script.py
memray run -m my_module La sortie sera un fichier binaire (comme memray-my_script.2369.bin ) que vous pourrez analyser de différentes manières. Une solution consiste à utiliser la commande memray flamegraph pour générer un graphique de flamme :
memray flamegraph my_script.2369.binCela produira un fichier HTML avec un graphique en flamme de l'utilisation de la mémoire que vous pourrez inspecter avec votre navigateur préféré. Il existe plusieurs autres rapporteurs que vous pouvez utiliser pour générer d'autres types de rapports, certains générant une sortie basée sur un terminal et d'autres générant des fichiers HTML. Voici un exemple de flamegraph Memray :
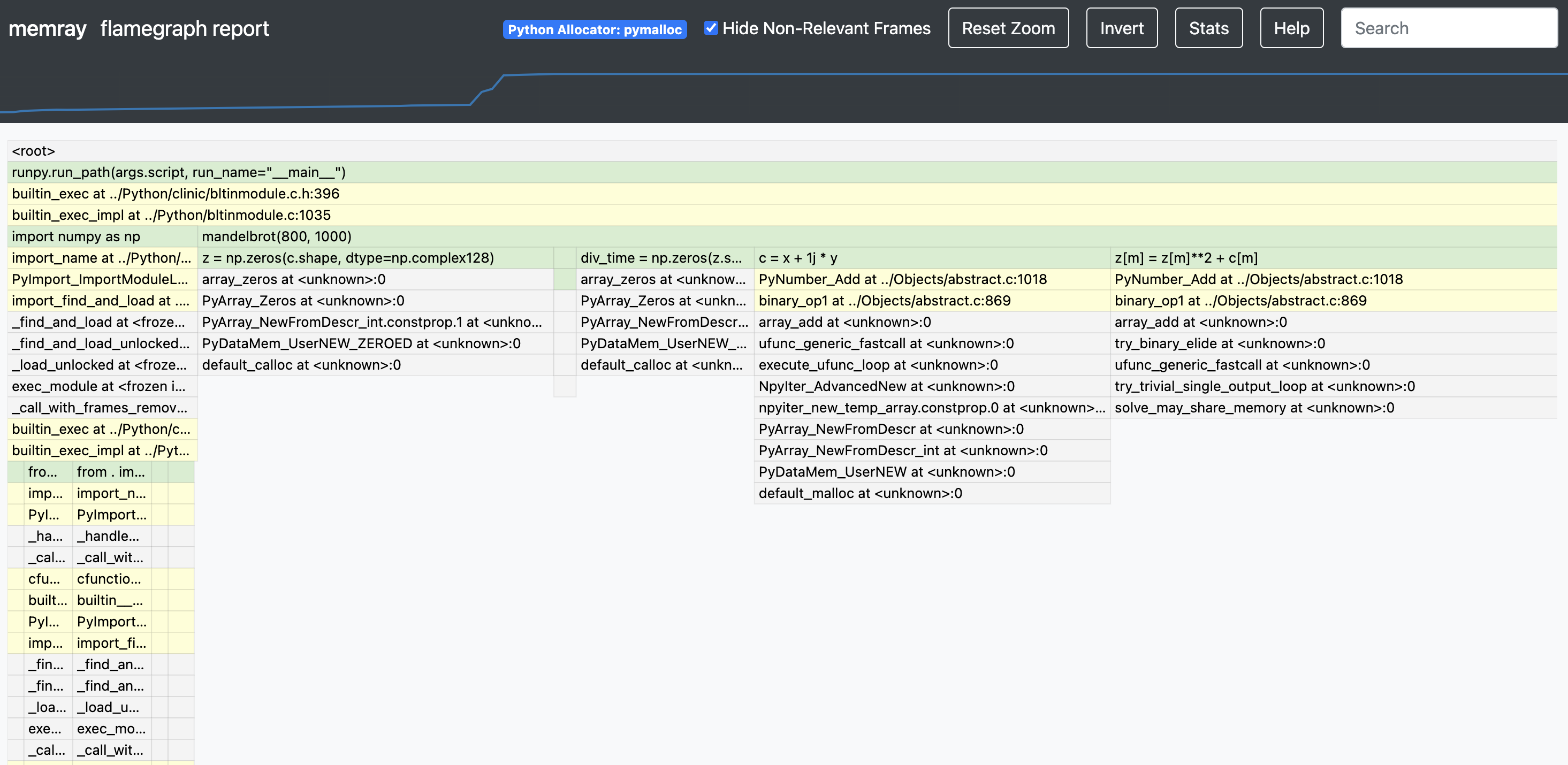
Si vous souhaitez un moyen simple et pratique d'utiliser memray dans votre suite de tests, vous pouvez envisager d'utiliser pytest-memray. Une fois installé, ce plugin pytest vous permet d'ajouter simplement --memray à l'invocation de la ligne de commande :
pytest --memray tests/Et obtiendra automatiquement un rapport comme celui-ci :
python3 -m pytest tests --memray
=============================================================================================================================== test session starts ================================================================================================================================
platform linux -- Python 3.8.10, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: /mypackage, configfile: pytest.ini
plugins: cov-2.12.0, memray-0.1.0
collected 21 items
tests/test_package.py ..................... [100%]
================================================================================================================================= MEMRAY REPORT ==================================================================================================================================
Allocations results for tests/test_package.py::some_test_that_allocates
? Total memory allocated: 24.4MiB
? Total allocations: 33929
Histogram of allocation sizes: |▂ █ |
? Biggest allocating functions:
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 3.0MiB
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 2.3MiB
- _visit:/opt/bb/lib/python3.8/site-packages/astroid/transforms.py:62 -> 576.0KiB
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 517.6KiB
- __init__:/opt/bb/lib/python3.8/site-packages/astroid/node_classes.py:1353 -> 512.0KiB
Vous pouvez également utiliser certains des marqueurs inclus pour faire échouer les tests si l'exécution dudit test alloue plus de mémoire que ce qui est autorisé :
@ pytest . mark . limit_memory ( "24 MB" )
def test_foobar ():
# do some stuff that allocates memoryPour en savoir plus sur la façon dont le plugin peut être utilisé et configuré, consultez la documentation du plugin.
Memray prend en charge le suivi des fonctions natives C/C++ ainsi que des fonctions Python. Cela peut être particulièrement utile lors du profilage d'applications dotées d'extensions C (telles que numpy ou pandas ), car cela donne une vision globale de la quantité de mémoire allouée par l'extension et de la quantité allouée par Python lui-même.
Pour activer le suivi natif, vous devez fournir l'argument --native lors de l'utilisation de la sous-commande run :
memray run --native my_script.pyCela ajoutera automatiquement des informations natives au fichier de résultats et elles seront automatiquement utilisées par tout rapporteur (tel que le flamegraph ou les rapporteurs de table). Cela signifie qu'au lieu de voir cela dans les flamegraphs :
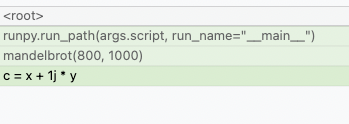
Vous pourrez maintenant voir ce qui se passe dans les appels Python :

Les journalistes affichent les frames natifs dans une couleur différente de celle des frames Python. Ils peuvent également être distingués en regardant l'emplacement du fichier dans un cadre (les cadres Python seront généralement générés à partir de fichiers avec une extension .py tandis que les cadres natifs seront générés à partir de fichiers avec des extensions comme .c, .cpp ou .h).
Le mode direct de Memray exécute un script ou un module dans une interface basée sur un terminal qui vous permet d'inspecter de manière interactive son utilisation de la mémoire pendant son exécution. Ceci est utile pour déboguer des scripts ou des modules dont l'exécution prend beaucoup de temps ou qui présentent plusieurs modèles de mémoire complexes. Vous pouvez utiliser l'option --live pour exécuter le script ou le module en mode live :
memray run --live my_script.pyou si vous souhaitez exécuter un module :
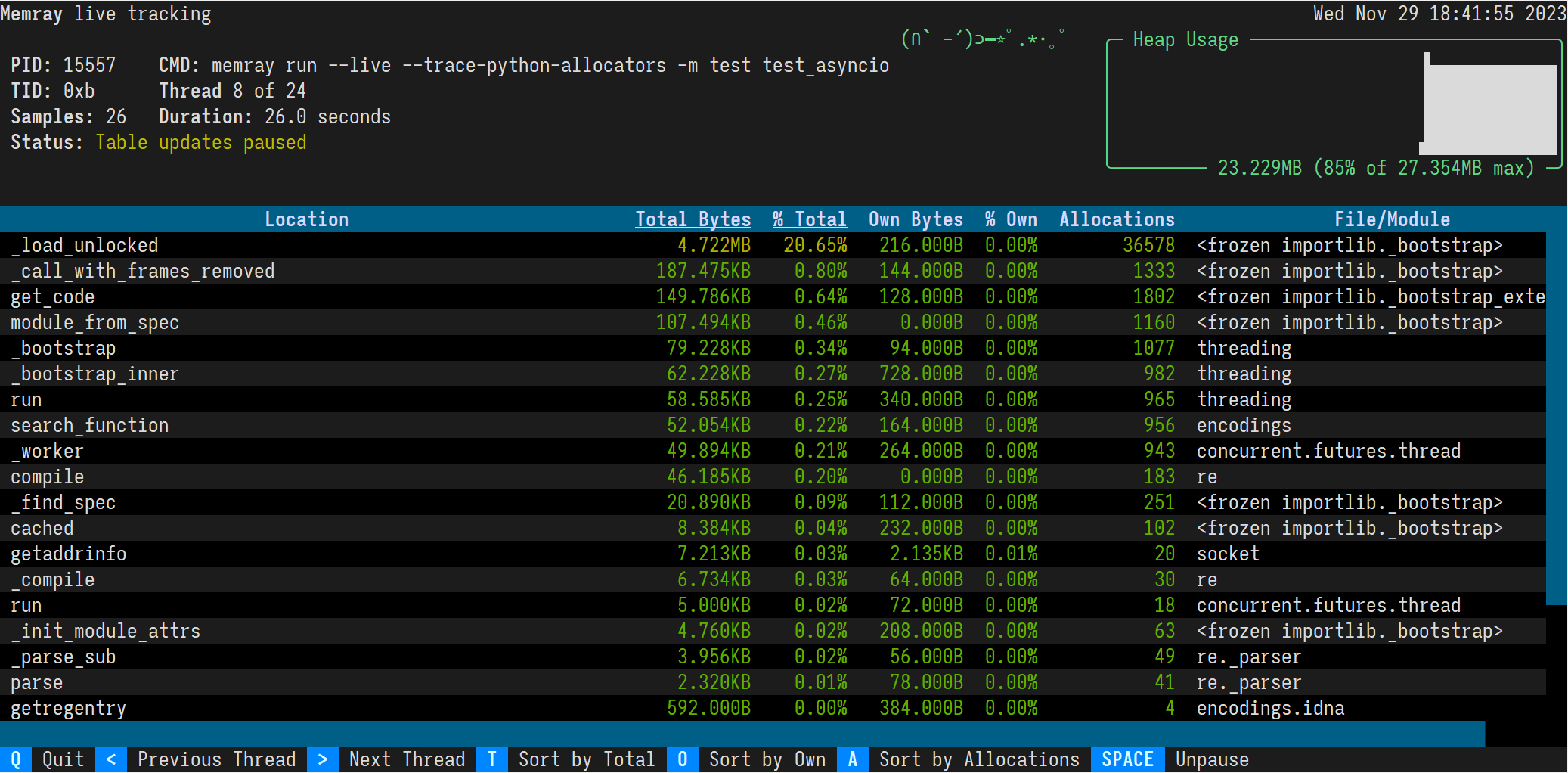
memray run --live -m my_moduleCela affichera l'interface TUI suivante dans votre terminal :
Les résultats sont affichés par ordre décroissant de la mémoire totale allouée par une fonction et des sous-fonctions appelées par celle-ci. Vous pouvez modifier l'ordre avec les raccourcis clavier suivants :
t (par défaut) : Trier par mémoire totale
o : Trier par propre mémoire
a : Trier par nombre d'allocations
Dans la plupart des terminaux, vous pouvez également cliquer sur les boutons « Trier par total », « Trier par propre » et « Trier par allocations » dans le pied de page.
L'en-tête de la colonne triée est souligné.
Par défaut, la commande live présentera le thread principal du programme. Vous pouvez consulter différents threads du programme en appuyant sur les touches supérieur à et inférieur à, < et > . Dans la plupart des terminaux, vous pouvez également cliquer sur les boutons « Sujet précédent » et « Sujet suivant » en pied de page.
En plus du suivi des processus Python à partir d'une CLI à l'aide memray run , il est également possible d'activer par programme le suivi dans un programme Python en cours d'exécution.
import memray
with memray . Tracker ( "output_file.bin" ):
print ( "Allocations will be tracked until the with block ends" )Pour plus de détails, consultez la documentation de l'API.
Memray est sous licence Apache-2.0, comme indiqué dans le fichier LICENSE.
Ce projet a adopté un code de conduite. Si vous avez des préoccupations concernant le Code ou le comportement que vous avez constaté dans le projet, veuillez nous contacter à [email protected].
Si vous pensez avoir identifié une vulnérabilité de sécurité dans ce projet, veuillez envoyer un e-mail à l'équipe du projet à [email protected], détaillant le problème suspecté et toutes les méthodes que vous avez trouvées pour le reproduire.
Veuillez NE PAS ouvrir de problème dans le référentiel GitHub, car nous préférons garder les rapports de vulnérabilité privés jusqu'à ce que nous ayons eu l'occasion de les examiner et de les résoudre.
Nous apprécions vos contributions pour nous aider à améliorer et à prolonger ce projet !
Vous trouverez ci-dessous quelques étapes de base requises pour pouvoir contribuer au projet. Si vous avez des questions sur ce processus ou sur tout autre aspect de la contribution à un projet open source Bloomberg, n'hésitez pas à envoyer un e-mail à [email protected] et nous répondrons à vos questions le plus rapidement possible.
Étant donné que ce projet est distribué selon les termes d'une licence open source, les contributions que vous apportez sont sous licence selon les mêmes conditions. Afin que nous puissions accepter vos contributions, nous aurons besoin d'une confirmation explicite de votre part que vous êtes capable et disposé à les fournir dans le cadre de ces conditions, et le mécanisme que nous utilisons pour ce faire est appelé certificat d'origine du développeur (DCO). . Ceci est très similaire au processus utilisé par le noyau Linux, Samba et de nombreux autres projets open source majeurs.
Pour participer selon ces conditions, tout ce que vous devez faire est d'inclure une ligne comme celle-ci comme dernière ligne du message de validation pour chaque validation de votre contribution :
Signed-Off-By: Random J. Developer <[email protected]>
Le moyen le plus simple d'y parvenir est d'ajouter -s ou --signoff à votre commande git commit .
Vous devez utiliser votre vrai nom (désolé, pas de pseudonymes et pas de contributions anonymes).


