similarity
1.1.6
similarité, calcule le score de similarité entre les chaînes de texte, écrit en Java.
Similarity, une boîte à outils de calcul de similarité, peut être utilisée pour le calcul de similarité de texte, l'analyse des sentiments, etc., écrite en Java.
Similarity est une version Java d'une boîte à outils de calcul de similarité composée d'une série d'algorithmes. L'objectif est de diffuser la méthode de calcul de similarité dans le traitement du langage naturel. La similarité présente les caractéristiques d'outils pratiques, de performances efficaces, d'une structure claire, d'un corpus à jour et d'une personnalisation.
La similarité fournit les fonctionnalités suivantes :
Calcul de similarité de mots
Calcul de similarité de phrases
Calcul de similarité de phrases
Calcul de similarité de paragraphe
CNKI Yiyuan
analyse des sentiments
Mots approximatifs
Tout en fournissant des fonctions riches, les modules internes de Similarity insistent sur un faible couplage, les modèles insistent sur un chargement paresseux et les dictionnaires insistent sur la publication en texte brut. Ils sont faciles à utiliser et aident les utilisateurs à former leurs propres corpus.
Présentation du package Jar
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Introduction du diplôme :
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Longueur du texte : granularité des mots
Il est recommandé d'utiliser la similarité Cilin : org.xm.Similarity.cilinSimilarity , qui est une méthode de calcul de similarité basée sur les synonymes Cilin
exemple : src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
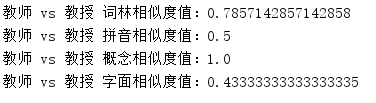
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Longueur du texte : granularité de la phrase
Il est recommandé d'utiliser la similarité de phrases : org.xm.Similarity.phraseSimilarity , qui est essentiellement une méthode de calcul de la similarité de deux phrases à travers les mêmes caractères et les positions des mêmes caractères.
exemple : src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Longueur du texte : granularité de la phrase
Il est recommandé d'utiliser la similarité de la forme des mots et de l'ordre des mots : org.xm.similarity.morphoSimilarity , une méthode de similarité qui considère non seulement le même texte comme un littéral de deux phrases, mais considère également l'ordre dans lequel le même texte apparaît.
exemple : src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Longueur du texte : granularité du paragraphe (un paragraphe, 25 caractères < longueur (texte) < 500 caractères)
Il est recommandé d'utiliser la similarité des phrases dans l'ordre des mots : org.xm.similarity.text.CosineSimilarity , une méthode qui considère le même texte dans deux paragraphes, le pondère via la segmentation des mots, la fréquence des mots et la pondération des parties du discours, et utilise le cosinus pour calculer la similarité.
exemple : src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875exemple : src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}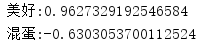
Cet exemple est une analyse granulaire de la polarité des sentiments basée sur des arbres de sémèmes. Concernant l'analyse des sentiments du texte, il existe pytextclassifier, qui utilise des modèles de réseaux neuronaux profonds et des algorithmes de classification SVM pour obtenir de meilleurs résultats.
exemple : src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

La formation de vecteurs de mots Word2vec est une version Java de l'outil de formation word2vec Word2VEC_java. Le corpus de formation est le roman Tian Long Ba Bu, et les synonymes sont obtenus grâce à l'implémentation de vecteurs de mots. Les utilisateurs peuvent former un corpus personnalisé ou utiliser Wikipédia chinois pour former des vecteurs de mots universels.
Mesure de similarité de texte

Le contrat de licence est The Apache License 2.0, qui est gratuit pour un usage commercial. Veuillez joindre un lien de similarité et un accord de licence à la description du produit.
Le code du projet est encore très approximatif. Si vous avez des améliorations au code, vous êtes invités à le soumettre à nouveau à ce projet. Avant de le soumettre, veuillez faire attention aux deux points suivants :
testVous pouvez ensuite soumettre un PR.


