cherche
2.2.1
Recherche neuronale

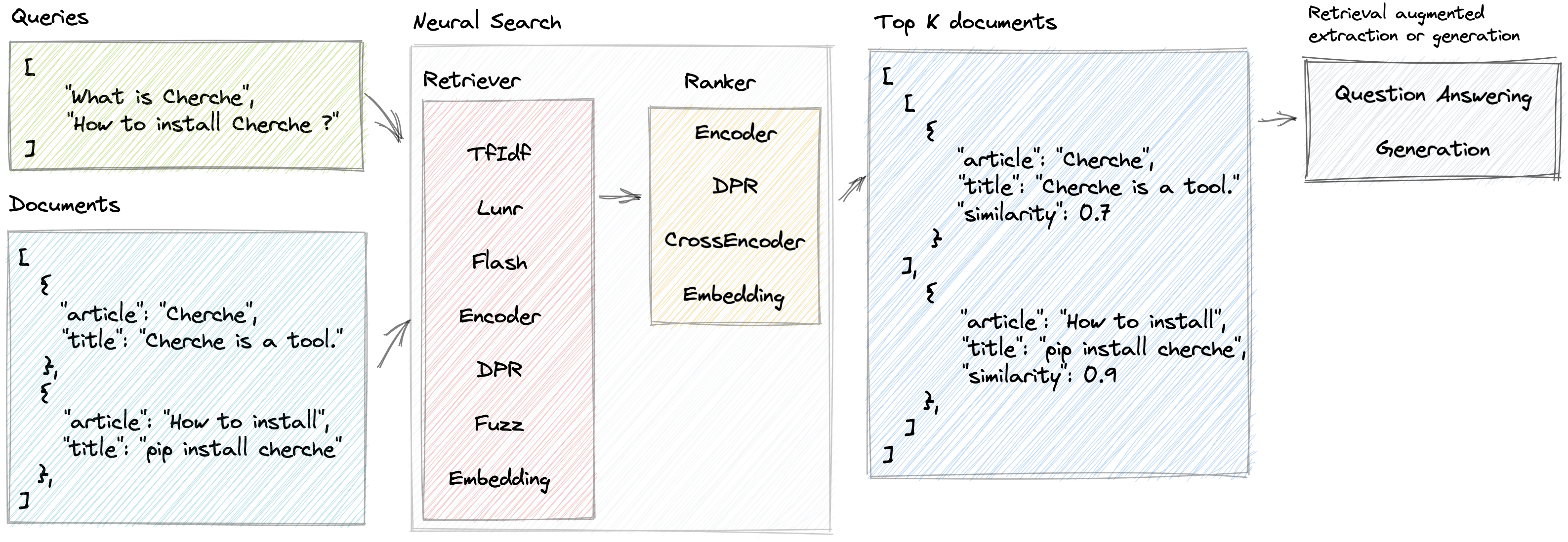
Cherche permet le développement d'un pipeline de recherche neuronale qui utilise des récupérateurs et des modèles linguistiques pré-entraînés à la fois comme récupérateurs et classeurs. Le premier atout du Cherche réside dans sa capacité à construire des pipelines de bout en bout. De plus, Cherche est bien adapté à la recherche sémantique hors ligne en raison de sa compatibilité avec le calcul par lots.
Voici quelques-unes des fonctionnalités offertes par Cherche :
Démo en direct d'un moteur de recherche PNL propulsé par Cherche
Pour installer Cherche afin de l'utiliser avec un simple récupérateur sur CPU, tel que TfIdf, Flash, Lunr, Fuzz, utilisez la commande suivante :
pip install cherchePour installer Cherche afin de l'utiliser avec n'importe quel récupérateur ou classement sémantique sur le processeur, utilisez la commande suivante :
pip install " cherche[cpu] "Enfin, si vous envisagez d'utiliser un outil de récupération sémantique ou un classement sur GPU, utilisez la commande suivante :
pip install " cherche[gpu] "En suivant ces instructions d'installation, vous pourrez utiliser Cherche avec les exigences appropriées à vos besoins.
La documentation est disponible ici. Il fournit des détails sur les récupérateurs, les classements, les pipelines et des exemples.
Cherche permet de retrouver le bon document au sein d'une liste d'objets. Voici un exemple de corpus.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]Voici un exemple de pipeline de recherche neuronale composé d'un TF-IDF qui récupère rapidement des documents, suivi d'un modèle de classement. Le modèle de classement trie les documents produits par le récupérateur en fonction de la similarité sémantique entre la requête et les documents. Nous pouvons appeler le pipeline en utilisant une liste de requêtes et obtenir les documents pertinents pour chaque requête.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Nous pouvons mapper l'index aux documents pour accéder à leur contenu à l'aide de pipelines :
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche fournit des récupérateurs qui filtrent les documents d'entrée en fonction d'une requête.
Cherche fournit des classements qui filtrent les documents dans la sortie des récupérateurs.
Les classements Cherche sont compatibles avec les modèles SentenceTransformers disponibles sur le hub Hugging Face.
Cherche propose des modules dédiés à la réponse aux questions. Ces modules sont compatibles avec les modèles pré-entraînés de Hugging Face et entièrement intégrés aux pipelines de recherche neuronale.
Cherche a été créé pour/par Renault et est désormais accessible à tous. Nous apprécions toutes les contributions.

Lunr retriever est un wrapper autour de Lunr.py. Flash retriever est un wrapper autour de FlashText. Les classements DPR, Encode et CrossEncoder sont des wrappers dédiés à l'utilisation des modèles pré-entraînés de SentenceTransformers dans un pipeline de recherche neuronale.
Si vous utilisez cherche pour produire des résultats pour votre publication scientifique, veuillez vous référer à notre article SIGIR :
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}L'équipe de développement de Cherche est composée de Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero, Jose G Moreno. ?


