qwen2 in a lambda
1.0.0
Mis à jour le 11/09/2024
(Marquer la date en raison de la rapidité avec laquelle les API LLM dans Python évoluent et peut introduire des modifications importantes au moment où quelqu'un d'autre lira ceci !)
Il s'agit d'une recherche mineure sur la façon dont nous pouvons placer les fichiers de modèle Qwen GGUF dans AWS Lambda à l'aide de Docker et de SAM CLI.
Adapté de https://makit.net/blog/llm-in-a-lambda-function/
Je voulais savoir si je pouvais réduire mes dépenses AWS en tirant uniquement parti des capacités de Lambda et non de Lambda + Bedrock, car les deux services entraîneraient des coûts plus élevés à long terme.
L'idée était d'adapter un petit modèle de langage qui ne serait pas aussi gourmand en ressources et, espérons-le, de recevoir une latence inférieure à une seconde sur une configuration de mémoire de 128 à 256 Mo.
Je voulais également utiliser les modèles GGUF pour utiliser différents niveaux de quantification afin de déterminer quelle est la meilleure performance/taille de fichier à charger en mémoire.
qwen2-1_5b-instruct-q5_k_m.gguf dans qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (de préférence dans un environnement venv/conda)sam build / sam validatesam local start-api pour tester localementcurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate pour inviter le LLMsam deploy --guided pour déployer sur AWS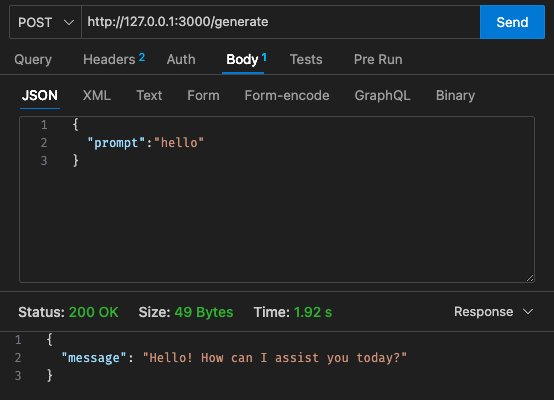
AWS
Configuration initiale - 128 Mo, délai d'attente de 30 s
Configuration n° 1 - 512 Mo, délai d'attente de 30 s
Configuration ajustée n°2 - 512 Mo, délai d'attente de 30 s
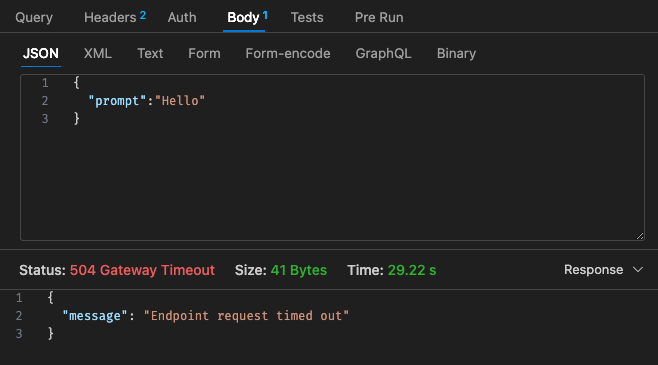
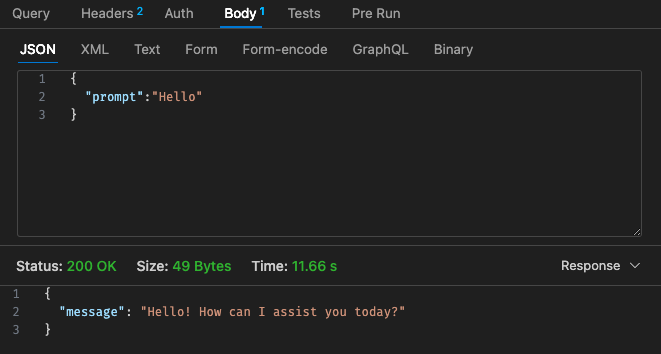
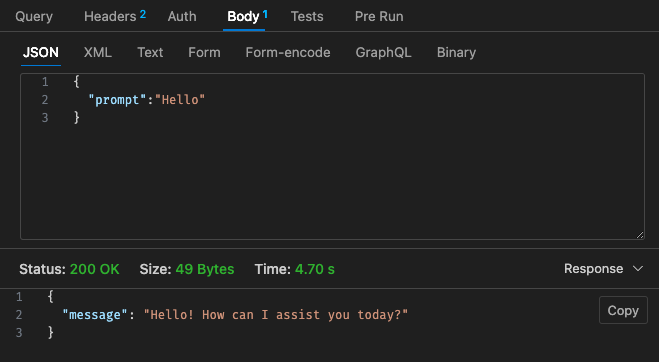
En revenant à la structure tarifaire de Lambda,
Il peut être moins cher d'utiliser simplement un LLM hébergé utilisant AWS Bedrock, etc. sur le cloud, car la structure tarifaire de Lambda avec Qwen ne semble pas plus compétitive par rapport à Claude 3 Haiku.
De plus, le délai d'expiration de la passerelle API n'est pas facilement configurable au-delà du délai d'attente de 30 secondes, selon votre cas d'utilisation, cela peut ne pas être très idéal.
Les résultats via local dépendent des spécifications de votre machine !! et peut fausser considérablement votre perception, vos attentes par rapport à la réalité
En fonction également de votre cas d'utilisation, la latence par invocation et réponses lambda peut entraîner une mauvaise expérience utilisateur.
Dans l’ensemble, je pense que c’était une petite expérience amusante même si elle n’a pas vraiment répondu aux exigences de budget et de latence via Qwen 1.5b pour mon projet parallèle. Merci encore à @makit pour le guide !


