Interactive RAG
1.0.0
Les agents révolutionnent la façon dont nous exploitons les modèles de langage pour la prise de décision et l’exécution des tâches. Les agents sont des systèmes qui utilisent des modèles de langage pour prendre des décisions et effectuer des tâches. Elles sont conçues pour gérer des scénarios complexes et offrent plus de flexibilité par rapport aux approches traditionnelles. Les agents peuvent être considérés comme des moteurs de raisonnement qui exploitent des modèles de langage pour traiter les informations, récupérer les données pertinentes, les ingérer (morceaux/intégrations) et générer des réponses.
À l’avenir, les agents joueront un rôle essentiel dans le traitement du texte, l’automatisation des tâches et l’amélioration des interactions homme-machine à mesure que les modèles linguistiques progressent.
Dans cet exemple, nous nous concentrerons spécifiquement sur l’exploitation des agents dans la génération dynamique de récupération augmentée (RAG). Grâce à ActionWeaver et MongoDB Atlas, vous aurez la possibilité de modifier votre stratégie RAG en temps réel grâce à des interactions conversationnelles. Qu'il s'agisse de sélectionner davantage de fragments, d'augmenter leur taille ou de modifier d'autres paramètres, vous pouvez affiner votre approche RAG pour obtenir la qualité et la précision de réponse souhaitées. Vous pouvez même ajouter/supprimer des sources à votre base de données vectorielles en utilisant le langage naturel !
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
Le texte fragmenté est une bonne chose, mais comment le stocker ?
Résumer permet d'économiser de l'espace et d'accélérer les choses, mais peut perdre des détails.
Le stockage des données brutes est précis, mais volumineux, plus lent et « bruyant ».
Avantages du résumé :
Inconvénients du résumé :
Qu'est-ce qui vous convient ? Cela dépend de vos besoins ! Considérer:
DÉMO 1
Créer un nouvel environnement Python
python3 -m venv envActiver le nouvel environnement Python
source env/bin/activateInstaller les exigences
pip3 install -r requirements.txtDéfinissez les paramètres dans params.py :
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Créez un index de recherche avec la définition suivante
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Définir l'environnement
export OPENAI_API_KEY=Pour exécuter l'application RAG
env/bin/streamlit run rag/app.pyLes informations du journal générées par l'application seront ajoutées à app.log.
Ce bot prend en charge les actions suivantes : répondre à une question, rechercher sur le Web, lire des URL, supprimer des sources, répertorier toutes les sources et réinitialiser les messages. Il prend également en charge une action appelée iRAG qui vous permet de contrôler dynamiquement la stratégie RAG de votre agent.
Ex : "définir la configuration RAG sur 3 sources et la taille du bloc 1 250 » => Nouvelle configuration RAG : {'num_sources' : 3, 'source_chunk_size' : 1250, 'min_rel_score' : 0, 'unique' : True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Si le robot n'est pas en mesure de fournir une réponse à la question à partir des données stockées dans le magasin Atlas Vector et de votre stratégie RAG (nombre de sources, taille du bloc, min_rel_score, etc.), il lancera une recherche sur le Web pour trouver des informations pertinentes. Vous pouvez ensuite demander au bot de lire et d’apprendre de ces résultats.
RAG, c'est cool et tout ça, mais trouver la bonne « stratégie RAG » est délicat. La taille des fragments et le nombre de sources uniques auront un impact direct sur la réponse générée par le LLM.
Dans le développement d'une stratégie RAG efficace, le processus d'ingestion des sources Web, le découpage, l'intégration, la taille des fragments et la quantité de sources utilisées jouent un rôle crucial. Le découpage décompose le texte saisi pour une meilleure compréhension, l'intégration capture le sens et le nombre de sources a un impact sur la diversité des réponses. Trouver le bon équilibre entre la taille des fragments et le nombre de sources est essentiel pour obtenir des réponses précises et pertinentes. L'expérimentation et la mise au point sont nécessaires pour déterminer les paramètres optimaux.
Avant de plonger dans la « Récupération », parlons d'abord du « Processus d'ingestion »
Pourquoi avoir un processus distinct pour « ingérer » votre contenu dans votre base de données vectorielles ? Grâce à la magie des agents, nous pouvons facilement ajouter du nouveau contenu à la base de données vectorielles.
Il existe de nombreux types de bases de données capables de stocker ces intégrations, chacune ayant ses propres utilisations particulières. Mais pour les tâches impliquant des applications GenAI, je recommande MongoDB.
Considérez MongoDB comme un gâteau que vous pouvez à la fois avoir et manger. Il vous donne la puissance de son langage pour faire des requêtes, Mongo Query Language. Il comprend également toutes les fonctionnalités intéressantes de MongoDB. En plus de cela, il vous permet de stocker ces éléments de base (intégrations vectorielles) et d'effectuer des opérations mathématiques sur eux, le tout au même endroit. Cela fait de MongoDB Atlas un guichet unique pour tous vos besoins d'intégration de vecteurs !
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
En utilisant ActionWeaver, un wrapper léger pour l'API d'appel de fonction, nous pouvons créer un agent proxy utilisateur qui récupère et ingère efficacement les informations pertinentes à l'aide de MongoDB Atlas.
Un agent proxy est un intermédiaire qui envoie des requêtes client à d'autres serveurs ou ressources, puis renvoie des réponses.
Cet agent présente les données à l'utilisateur de manière interactive et personnalisable, améliorant ainsi l'expérience utilisateur globale.
Le UserProxyAgent possède plusieurs paramètres RAG qui peuvent être personnalisés, tels que chunk_size (par exemple 1000), num_sources (par exemple 2), unique (par exemple True) et min_rel_score (par exemple 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
Voici quelques avantages clés qui ont influencé notre décision de choisir ActionWeaver :
Un agent est essentiellement un programme ou un système informatique conçu pour percevoir son environnement, prendre des décisions et atteindre des objectifs spécifiques.
Considérez un agent comme une entité logicielle qui affiche un certain degré d'autonomie et effectue des actions dans son environnement au nom de son utilisateur ou de son propriétaire, mais de manière relativement indépendante. Il prend des initiatives pour accomplir des actions par lui-même en délibérant sur ses options pour atteindre son ou ses objectifs. L'idée centrale des agents est d'utiliser un modèle de langage pour choisir une séquence d'actions à entreprendre. Contrairement aux chaînes, où une séquence d’actions est codée en dur dans le code, les agents utilisent un modèle de langage comme moteur de raisonnement pour déterminer quelles actions entreprendre et dans quel ordre.
Les actions sont des fonctions qu'un agent peut invoquer. Il existe deux considérations de conception importantes concernant les actions :
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Sans réfléchir aux deux, vous ne pourrez pas créer un agent fonctionnel. Si vous ne donnez pas à l'agent accès à un ensemble d'actions correct, il ne pourra jamais atteindre les objectifs que vous lui avez fixés. Si vous ne décrivez pas bien les actions, l’agent ne saura pas les utiliser correctement.
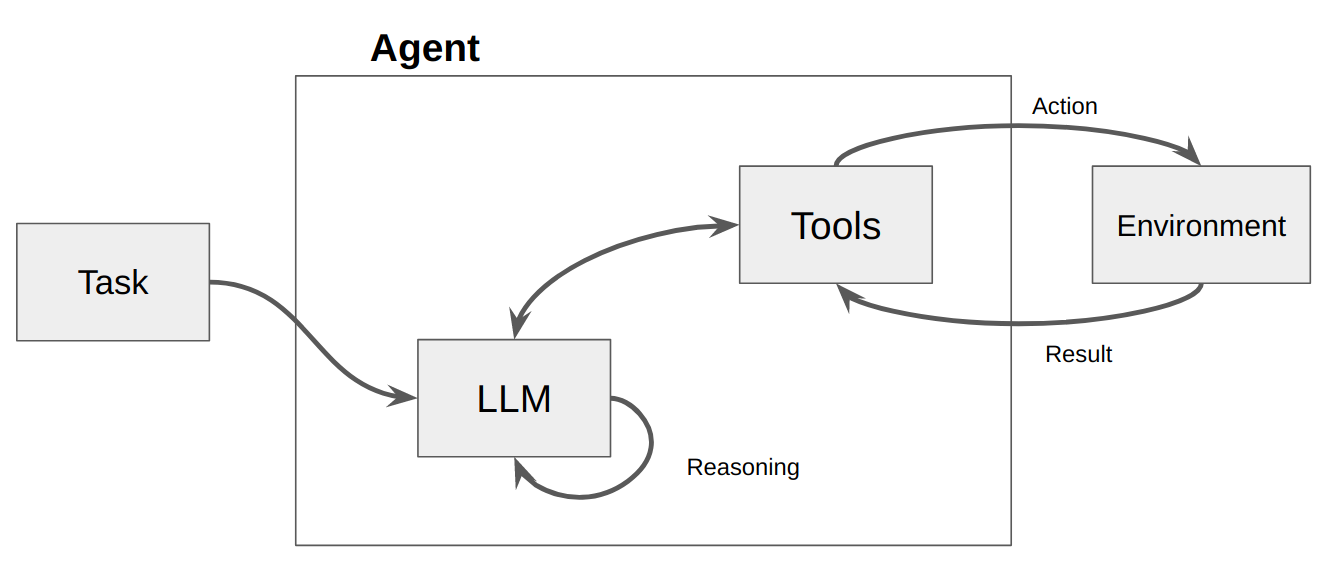
Un LLM est ensuite appelé, entraînant soit une réponse à l'utilisateur, soit une ou plusieurs actions à entreprendre. S'il est déterminé qu'une réponse est requise, elle est transmise à l'utilisateur et ce cycle est terminé. S'il est déterminé qu'une action est requise, cette action est alors entreprise et une observation (résultat de l'action) est effectuée. Cette action et l'observation correspondante sont rajoutées à l'invite (nous appelons cela un « bloc-notes d'agent »), et la boucle se réinitialise, c'est-à-dire. le LLM est à nouveau appelé (avec le bloc-notes de l'agent mis à jour).
Dans ActionWeaver, nous pouvons influencer la boucle en ajoutant stop=True|False à une action. Si stop=True , le LLM renverra immédiatement la sortie de la fonction. Cela empêchera également le LLM d'effectuer plusieurs appels de fonction. Dans cette démo, nous utiliserons uniquement stop=True
ActionWeaver prend également en charge un contrôle de boucle plus complexe en utilisant orch_expr(SelectOne[actions]) et orch_expr(RequireNext[actions]) , mais je laisserai cela pour la PARTIE II.
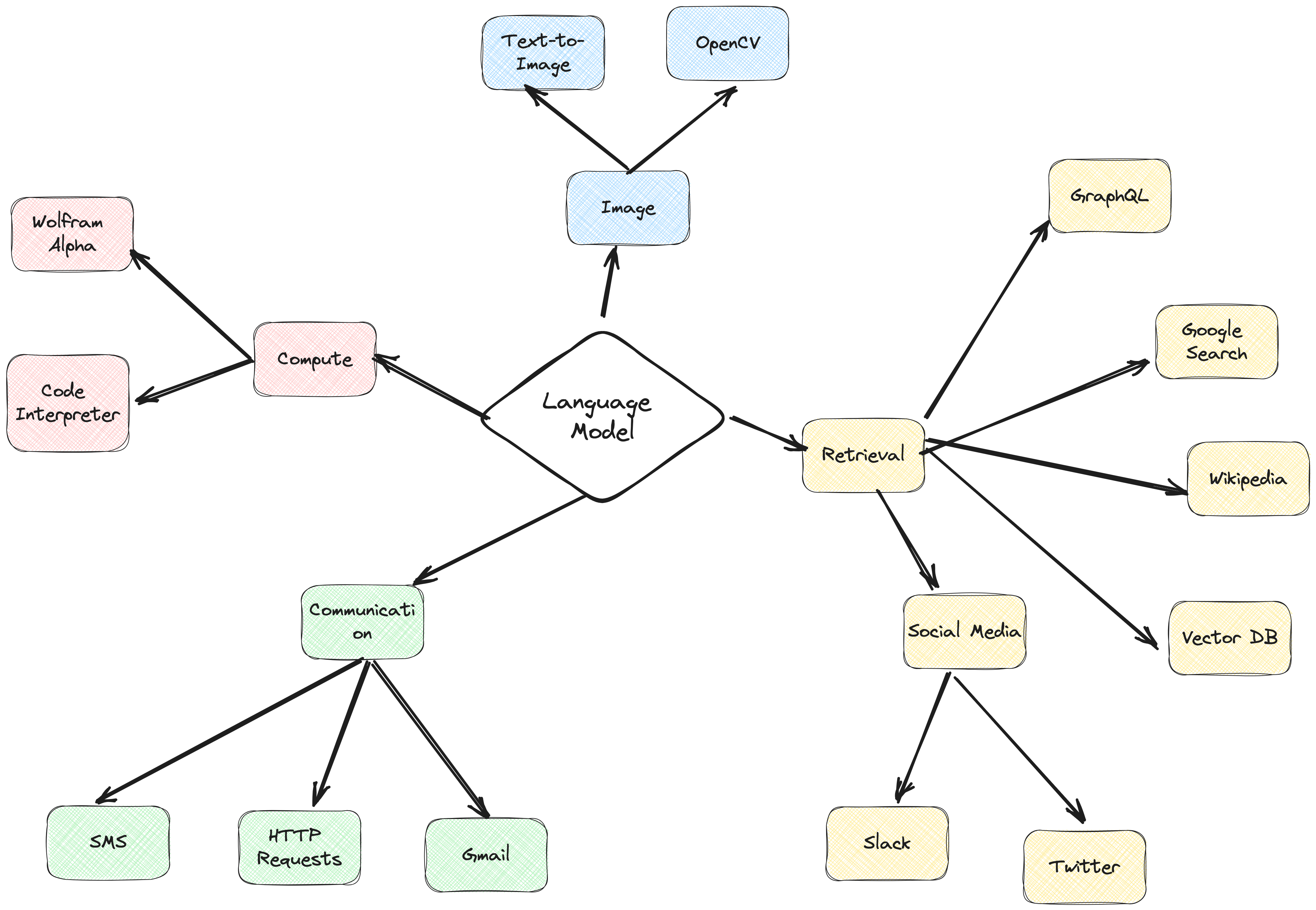
Le framework d'agent ActionWeaver est un framework d'application d'IA qui place l'appel de fonctions au cœur. Il est conçu pour permettre une fusion transparente des systèmes informatiques traditionnels avec les puissantes capacités de raisonnement des modèles de modèles de langage. ActionWeaver est construit autour du concept d'appel de fonction LLM, tandis que les frameworks populaires comme Langchain et Haystack sont construits autour du concept de pipelines.

Pour en savoir plus : https://thinhdanggroup.github.io/function-calling-openai/
Les développeurs peuvent attacher N'IMPORTE QUELLE fonction Python en tant qu'outil avec un simple décorateur. Dans l'exemple suivant, nous introduisons l'action get_sources_list, qui sera invoquée par l'API OpenAI.
ActionWeaver utilise la signature et la docstring de la méthode décorée comme description, les transmettant à l'API de fonction d'OpenAI.
ActionWeaver fournit un wrapper léger qui se charge de convertir les informations de la docstring/décorateur au format correct pour l'API OpenAI.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True lorsqu'il est ajouté à une action signifie que le LLM renverra immédiatement la sortie de la fonction, mais cela empêchera également le LLM d'effectuer plusieurs appels de fonction. Par exemple, si on l’interroge sur la météo à New York et à San Francisco, le modèle invoquerait deux fonctions distinctes séquentiellement pour chaque ville. Cependant, avec stop=True , ce processus est interrompu une fois que la première fonction renvoie des informations météorologiques pour New York ou San Francisco, selon la ville qu'elle interroge en premier.
Pour une compréhension plus approfondie du fonctionnement de ce bot, veuillez vous référer au fichier bot.py. De plus, vous pouvez explorer le référentiel ActionWeaver pour plus de détails.
La génération de traces de raisonnement permet au modèle d'induire, de suivre et de mettre à jour des plans d'action, et même de gérer les exceptions. Cet exemple utilise ReAct combiné avec une chaîne de pensée (CoT).
Chaîne de pensée
Raisonnement + Action
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
Les techniques d'incitation Chain of Thought (CoT) et ReAct entrent en jeu dans ces exemples. Voici comment procéder :
Invite de chaîne de pensée (CoT) :
Invite de réaction :
En résumé, CoT et ReAct jouent un rôle crucial dans ces exemples. CoT permet au modèle de raisonner étape par étape et de choisir les actions appropriées, tandis que ReAct étend cette fonctionnalité en permettant au modèle d'interagir avec son environnement et de mettre à jour ses plans en conséquence. Cette combinaison de raisonnement et d’action rend les grands modèles de langage plus flexibles et plus polyvalents, leur permettant de gérer un plus large éventail de tâches et de situations.
Commençons par poser une question à notre agent. Dans ce cas, « Qu'est-ce qu'une mangue ? » . La première chose qui se produira est qu'il essaiera de "rappeler" toute information pertinente en utilisant la similarité d'intégration vectorielle. Il formulera alors une réponse avec le contenu qu'il a « rappelé » ou effectuera une recherche sur le Web. Notre base de connaissances étant actuellement vide, nous devons ajouter quelques sources avant de pouvoir formuler une réponse.
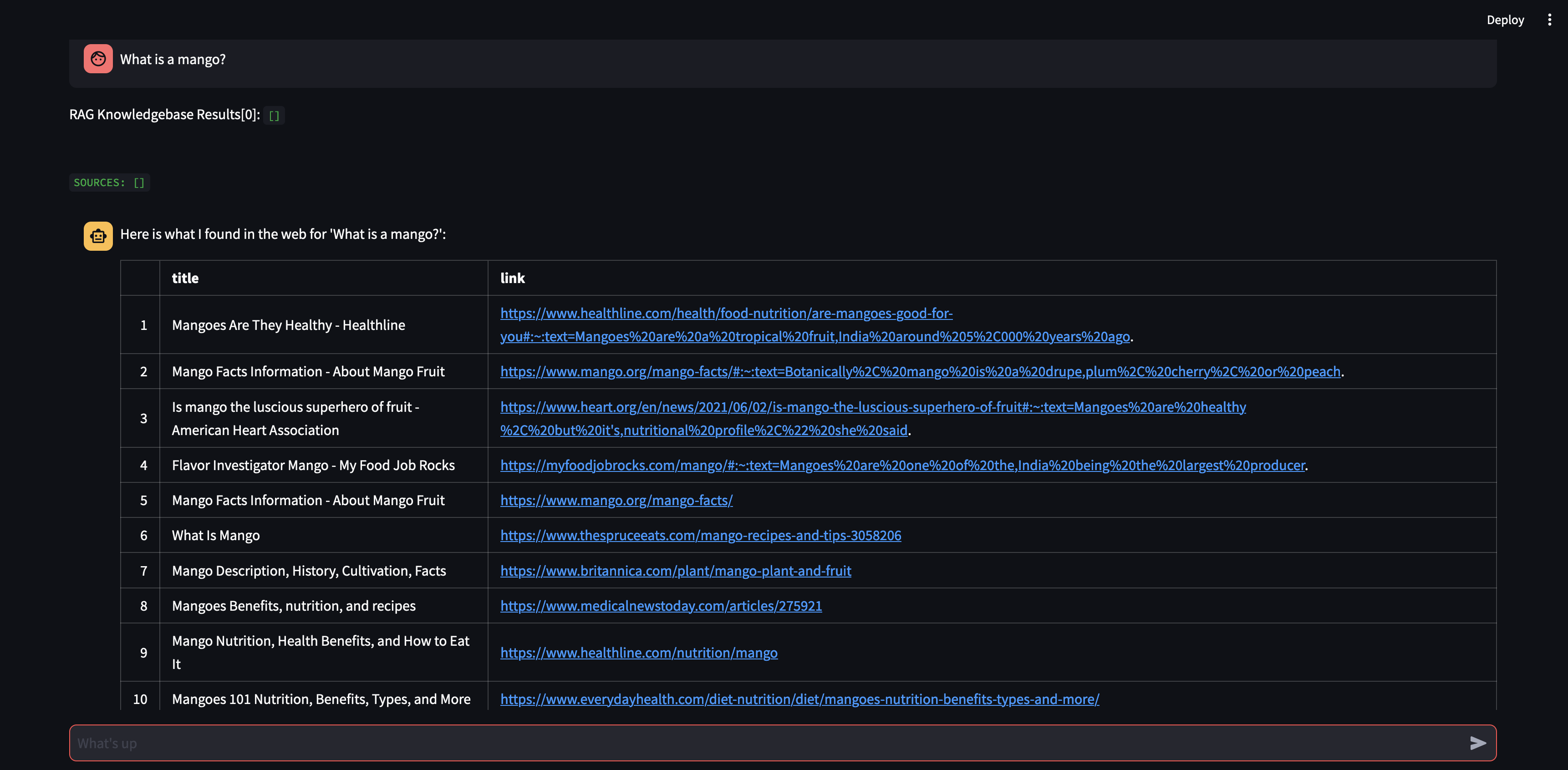
Étant donné que le robot n’est pas en mesure de fournir une réponse en utilisant le contenu de la base de données vectorielles, il a lancé une recherche sur Google pour trouver des informations pertinentes. Nous pouvons désormais lui dire quelles sources il doit « apprendre ». Dans ce cas, nous lui dirons d'apprendre les deux premières sources à partir des résultats de la recherche.
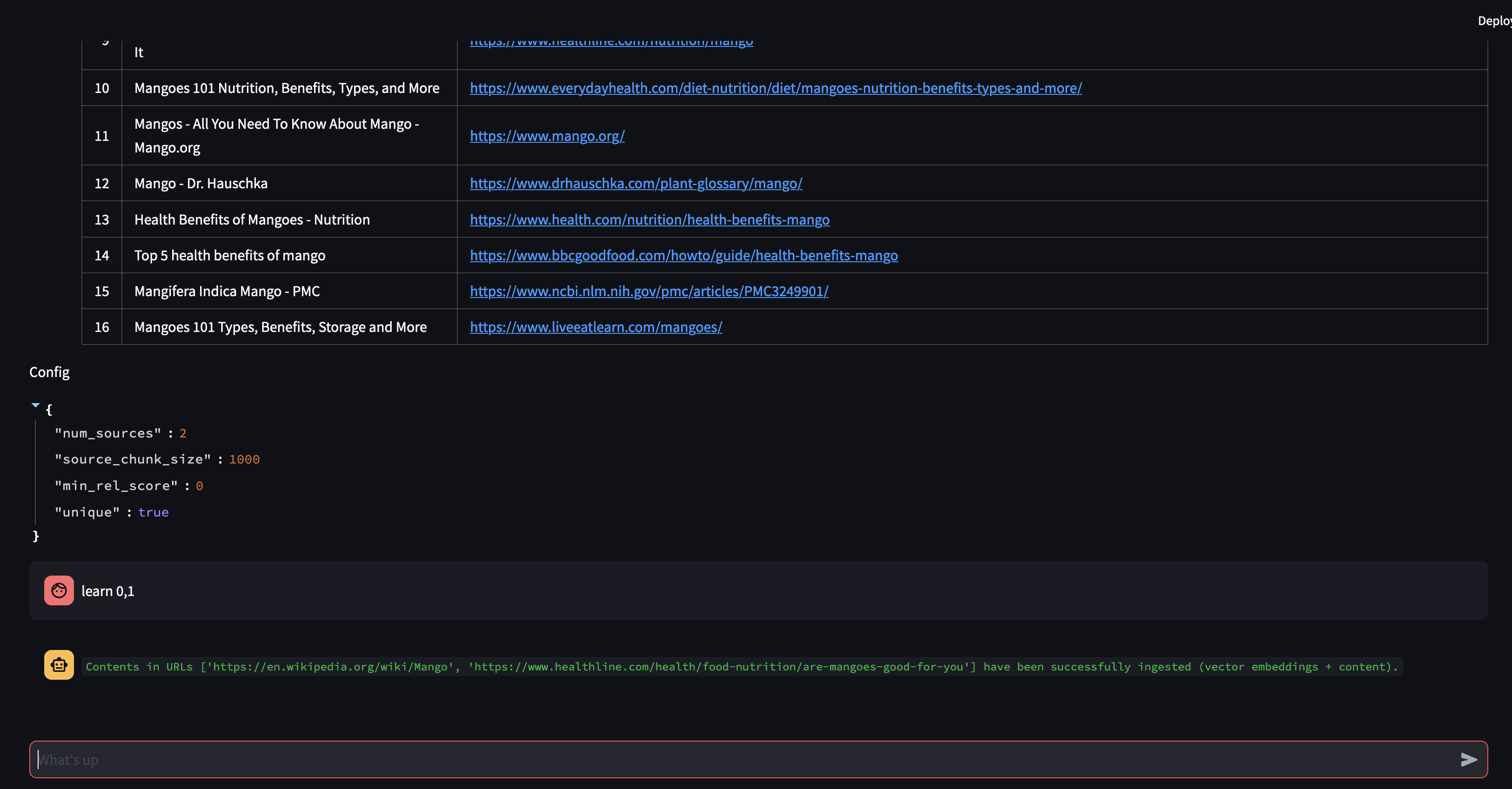
Ensuite, modifions la stratégie RAG ! Faisons en sorte qu'il n'utilise qu'une seule source et qu'il utilise un petit morceau de 500 caractères.
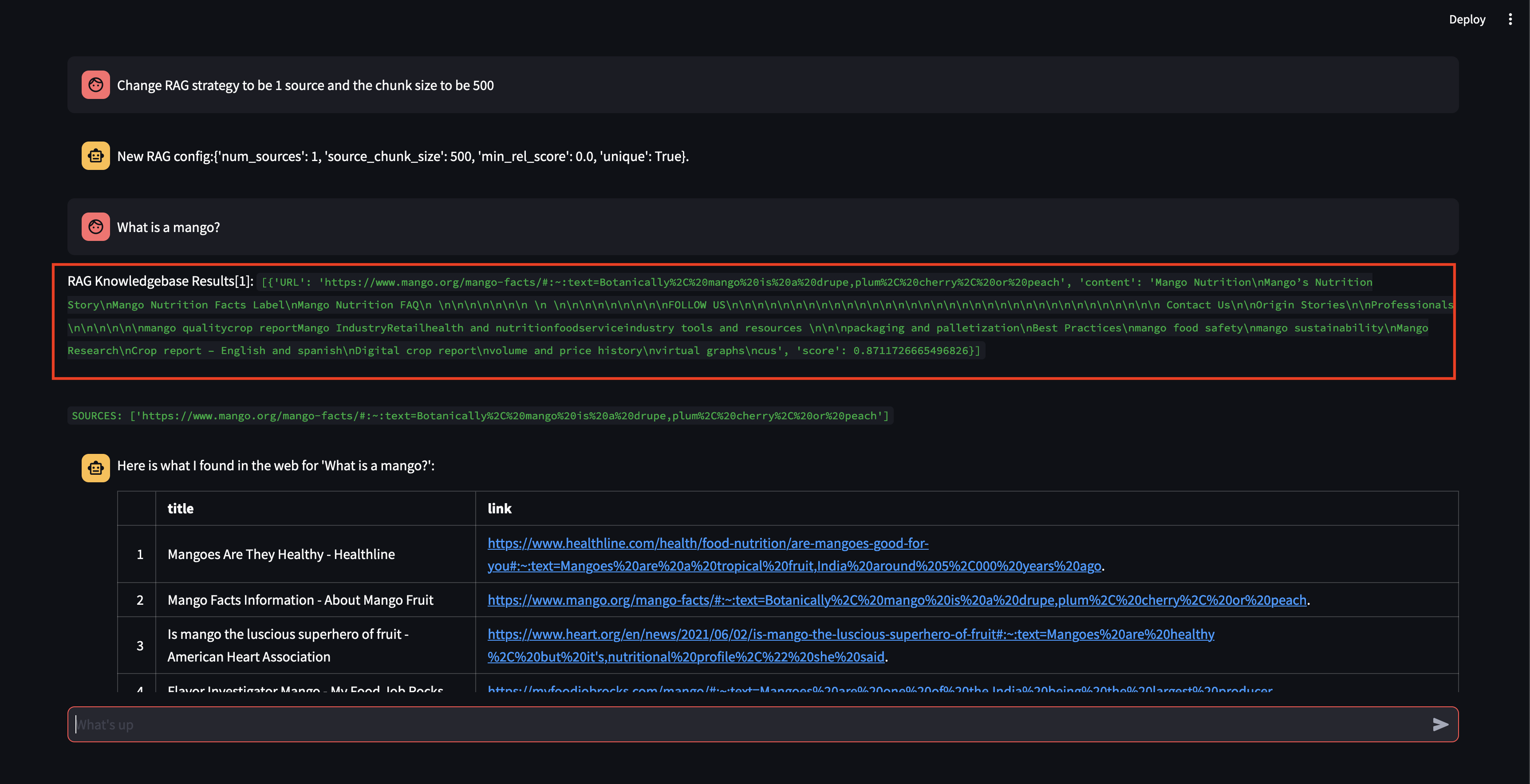
Notez que même s'il a pu récupérer un fragment, avec un score de pertinence assez élevé, il n'a pas pu générer de réponse car la taille du fragment était trop petite et le contenu du fragment n'était pas suffisamment pertinent pour formuler une réponse. Comme il ne pouvait pas générer de réponse avec ce petit morceau, il a effectué une recherche sur le Web au nom de l'utilisateur.
Voyons ce qui se passe si nous augmentons la taille du bloc à 3 000 caractères au lieu de 500.
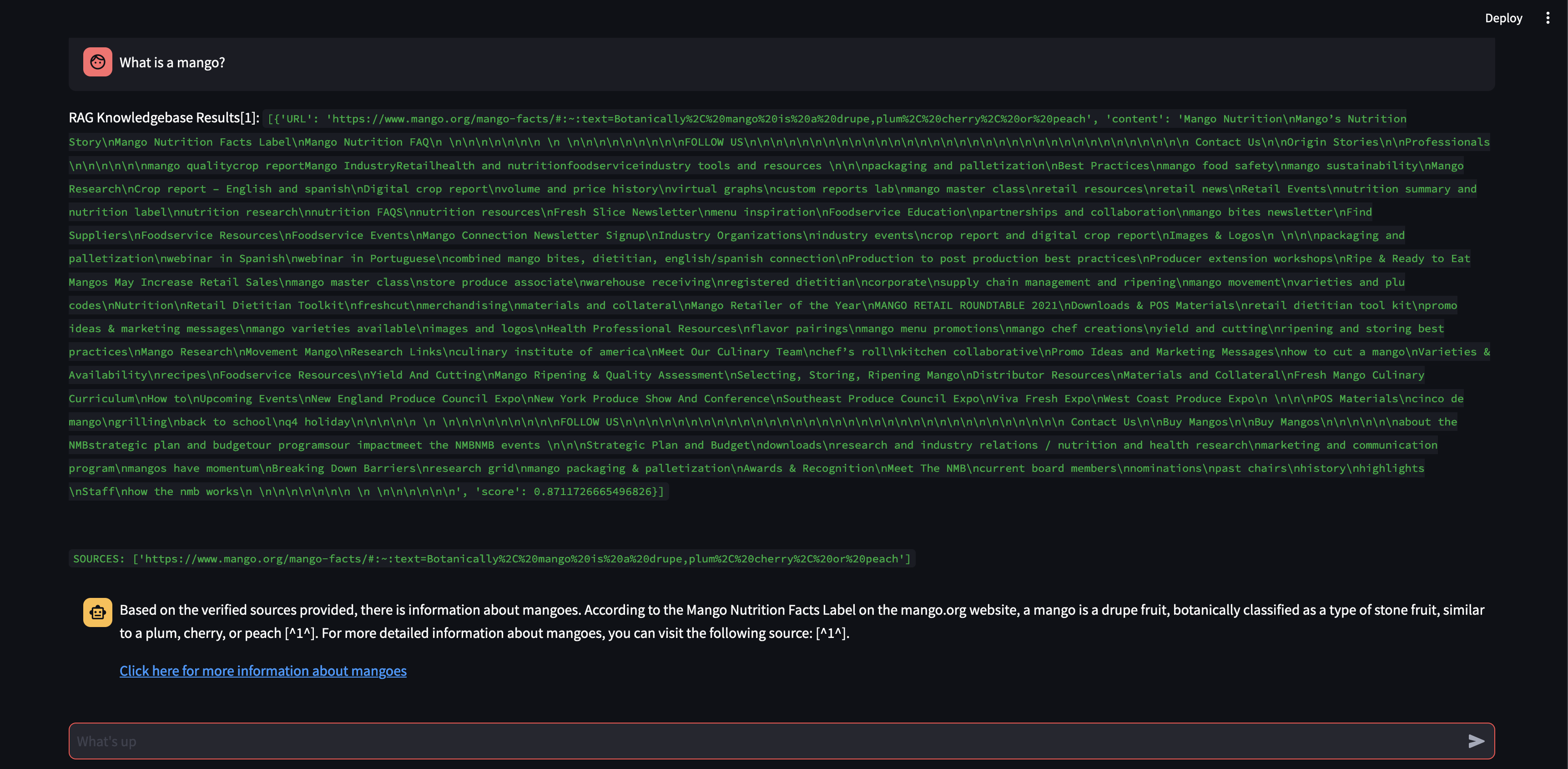
Désormais, avec une taille de fragment plus grande, il était capable de formuler avec précision la réponse en utilisant les connaissances de la base de données vectorielles !
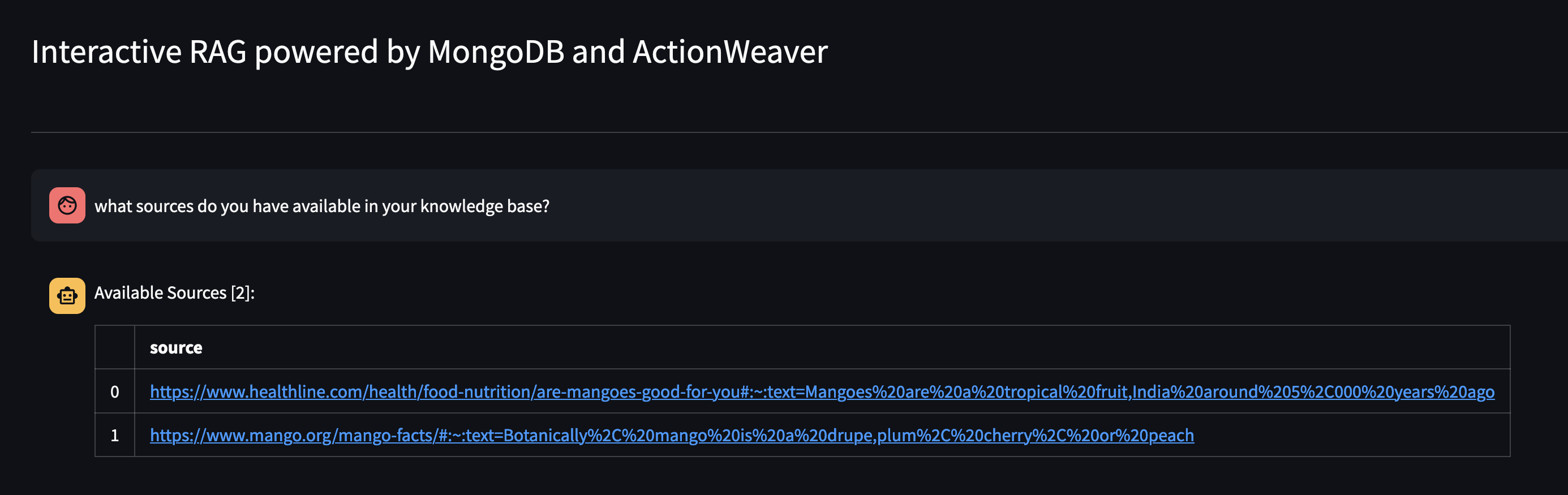
Voyons ce qui est disponible dans la base de connaissances de l'Agent en lui demandant : Quelles sources avez-vous dans votre base de connaissances ?
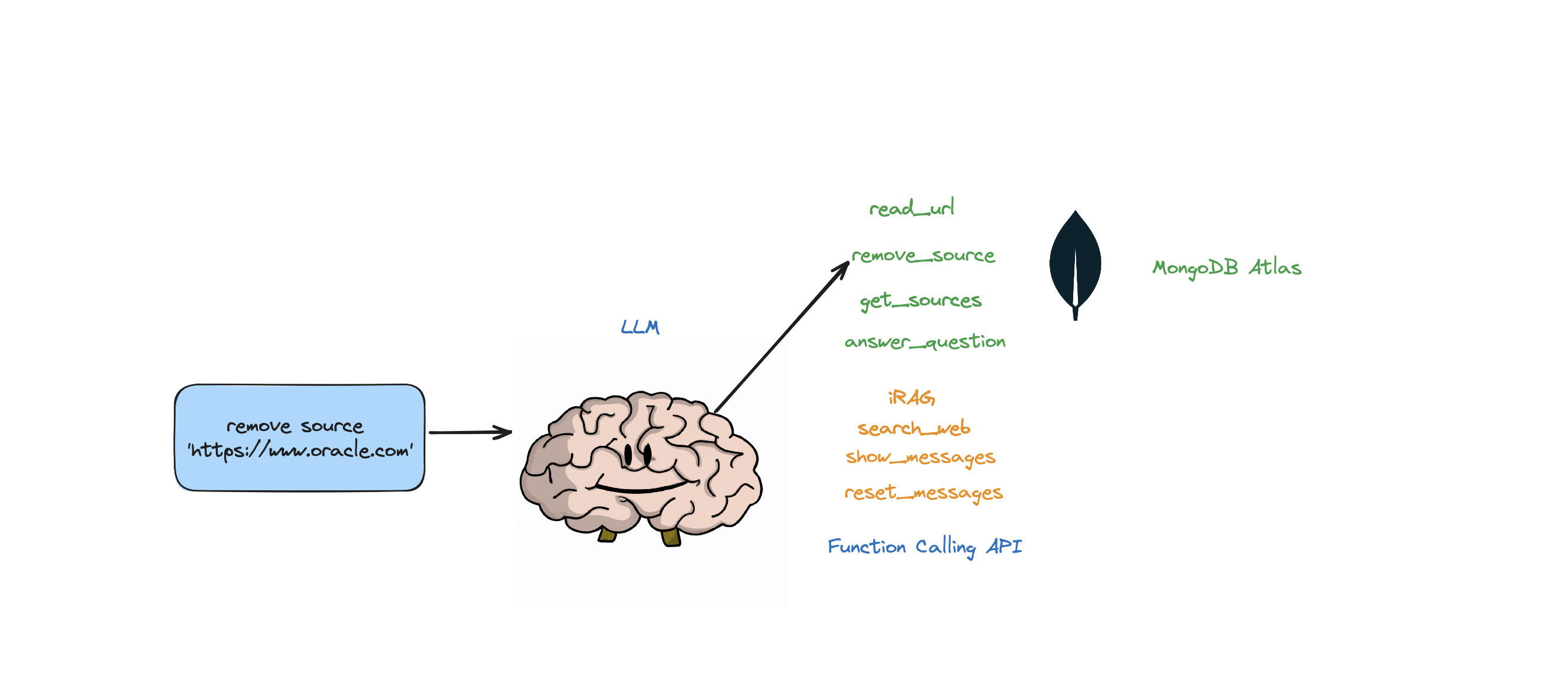
Si vous souhaitez supprimer une ressource spécifique, vous pouvez faire quelque chose comme :
USER: remove source 'https://www.oracle.com' from the knowledge base
Pour supprimer toutes les sources de la collection - Nous pourrions faire quelque chose comme :
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
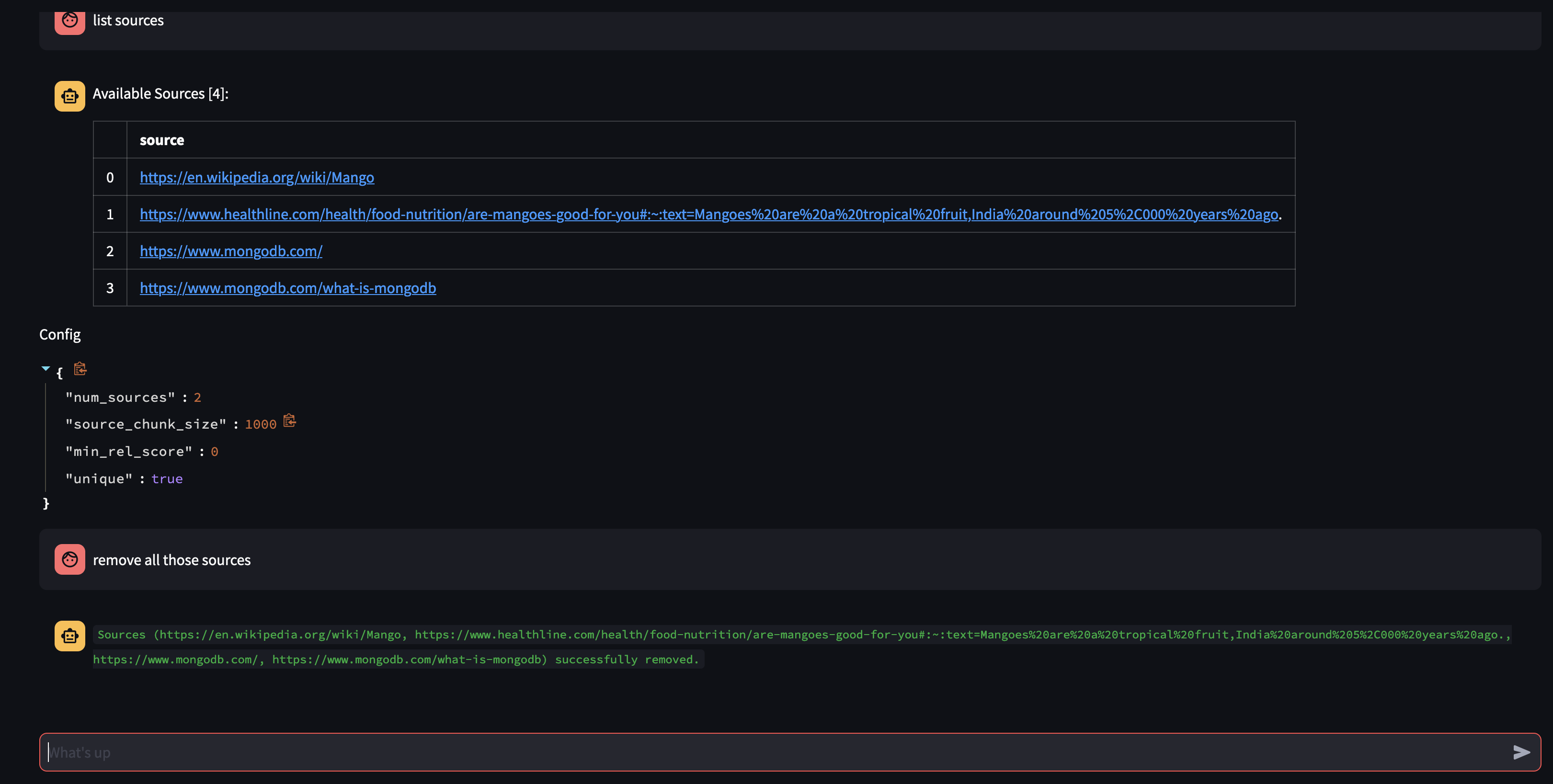
Cette démo a donné un aperçu du fonctionnement interne de notre agent IA, démontrant sa capacité à apprendre et à répondre aux requêtes des utilisateurs de manière interactive. Nous avons pu constater comment l'entreprise combine de manière transparente sa base de connaissances interne avec la recherche sur le Web en temps réel pour fournir des informations complètes et précises. Le potentiel de cette technologie est vaste, allant bien au-delà de la simple réponse aux questions. Rien de tout cela ne serait possible sans la magie de l' API Function Calling .
Ceci a été inspiré par https://github.com/TengHu/Interactive-RAG
Nous apprécions les contributions de la communauté open source.
Licence Apache 2.0


