genai knowledge capture
1.0.0
Cette solution de validation de principe explique une solution potentielle qui peut être utilisée pour capturer les connaissances tribales grâce à des enregistrements vocaux d'employés senior d'une entreprise. Il décrit les méthodologies permettant d'utiliser les services Amazon Transcribe et Amazon Bedrock pour la documentation et la vérification systématiques des données d'entrée. En fournissant une structure pour la formalisation de ces connaissances informelles, la solution garantit sa longévité et son applicabilité aux cohortes ultérieures d'employés d'une organisation. Cet effort garantit non seulement le maintien durable de l'excellence opérationnelle, mais améliore également l'efficacité des programmes de formation grâce à l'incorporation de connaissances pratiques acquises grâce à l'expérience directe.
Cette application de démonstration est une preuve de concept pour une application de génération de documents utilisant Amazon Transcribe et Amazon Bedrock.
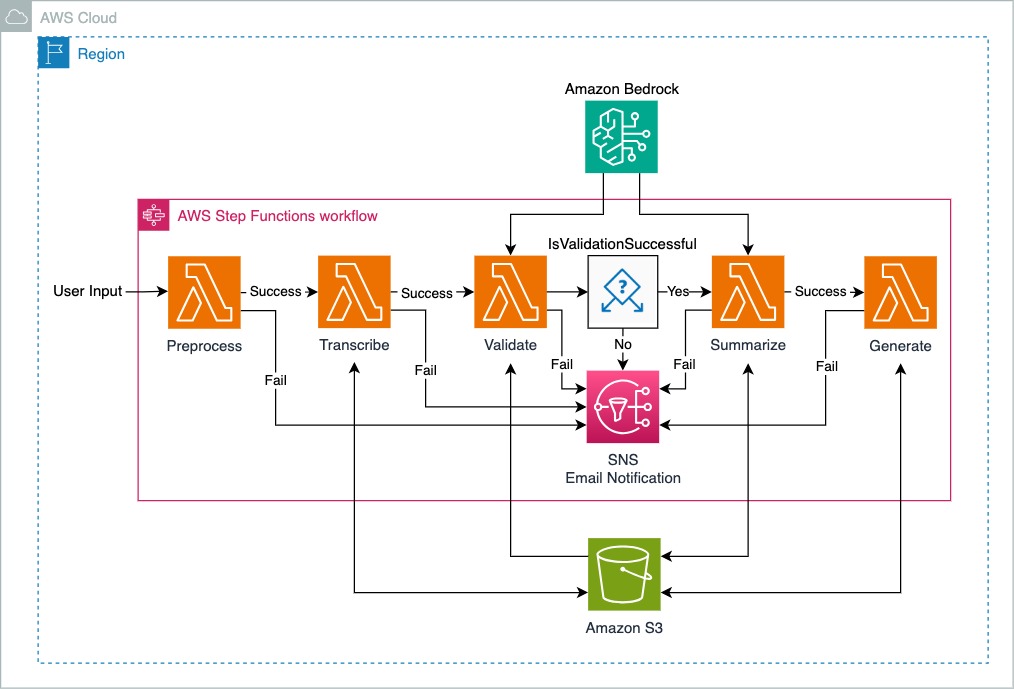
Le diagramme représente une architecture de solution pour un flux de travail orchestré par AWS Step Functions dans une région cloud AWS. Le flux de travail se compose de plusieurs étapes conçues pour traiter les entrées de l'utilisateur, avec des mécanismes de gestion des réussites et des échecs à chaque étape. Vous trouverez ci-dessous une description du flux de processus :
Entrée utilisateur : le flux de travail est lancé avec une entrée utilisateur pour déclencher la fonction Lambda preprocess .
Prétraitement : L'entrée est d'abord prétraitée. En cas de succès, il passe à l'étape transcribe ; en cas d'échec, Amazon SNS envoie des notifications.
Transcription : Cette étape reprend la sortie de l'étape précédente. Une transcription réussie passe à l'étape Valider et les résultats de la transcription sont stockés dans le compartiment Amazon S3.
Valider : Les données transcrites sont validées. En fonction du résultat de la validation, le workflow diverge :
Résumer : post-validation, si les données sont résumées avec succès, le texte résumé est stocké dans le compartiment Amazon S3. En cas d'échec, Amazon SNS envoie des notifications.
Amazon Bedrock est le service principal prenant en charge les fonctions Validate et Summarize Lambda.
Générer : Cette dernière étape génère le document final à partir du texte résumé. En cas d'échec, Amazon SNS envoie des notifications.
Chaque étape du processus est marquée par des chemins « Succès » ou « Échec », indiquant la capacité du flux de travail à gérer les erreurs à différentes étapes. En cas d'échec, Amazon SNS est utilisé pour envoyer des notifications à l'utilisateur.
Le flux de travail AWS Step Functions fonctionne comme un orchestrateur central, garantissant que chaque tâche est exécutée dans le bon ordre et gérant le succès ou l'échec de chaque étape de manière appropriée.
Le fichier cdk.json indique au CDK Toolkit comment exécuter votre application.
Ce projet est configuré comme un projet Python standard. Le processus d'initialisation crée également un virtualenv au sein de ce projet, stocké sous le répertoire .venv . Pour créer le virtualenv, cela suppose qu'il existe un exécutable python3 (ou python pour Windows) dans votre chemin avec accès au package venv . Si, pour une raison quelconque, la création automatique du virtualenv échoue, vous pouvez créer le virtualenv manuellement.
Pour créer manuellement un virtualenv sur MacOS et Linux :
$ python3 -m venv .venvUne fois le processus d'initialisation terminé et le virtualenv créé, vous pouvez utiliser l'étape suivante pour activer votre virtualenv.
$ source .venv/bin/activateSi vous êtes une plateforme Windows, vous activeriez le virtualenv comme ceci :
% .venvScripts activate.batUne fois le virtualenv activé, vous pouvez installer les dépendances requises.
$ pip install -r requirements.txt Pour ajouter des dépendances supplémentaires, par exemple d'autres bibliothèques CDK, ajoutez-les simplement à votre fichier setup.py et réexécutez la commande pip install -r requirements.txt .
À ce stade, vous pouvez désormais synthétiser le modèle CloudFormation pour ce code.
$ cdk synth Pour ajouter des dépendances supplémentaires, par exemple d'autres bibliothèques CDK, ajoutez-les simplement à votre fichier setup.py et réexécutez la commande pip install -r requirements.txt .
Vous devrez l'amorcer si c'est la première fois que vous exécutez cdk sur un compte et une région particuliers.
$ cdk bootstrap
Une fois démarré, vous pouvez procéder au déploiement de cdk.
$ cdk deploy
Si c'est la première fois que vous le déployez, le processus peut prendre environ 30 à 45 minutes pour créer plusieurs images Docker dans ECS (Amazon Elastic Container Service). Veuillez être patient jusqu'à ce qu'il soit terminé. Ensuite, il commencera à déployer la pile docgen, ce qui prend généralement environ 5 à 8 minutes.
Une fois le processus de déploiement terminé, vous verrez la sortie du cdk dans le terminal et vous pourrez également vérifier l'état dans votre console CloudFormation.
Pour supprimer le cdk une fois que vous avez fini de l'utiliser afin d'éviter des coûts futurs, vous pouvez soit le supprimer via la console, soit exécuter la commande suivante dans le terminal.
$ cdk destroyVous devrez peut-être également supprimer manuellement le compartiment S3 généré par le cdk. Veuillez vous assurer de supprimer toutes les ressources générées pour éviter d'engager des coûts.
cdk ls répertorie toutes les piles de l'applicationcdk synth émet le modèle CloudFormation synthétisécdk deploy déployez cette pile sur votre compte/région AWS par défautcdk diff compare la pile déployée avec l'état actuelcdk docs ouvre la documentation CDKcdk destroy détruit une ou plusieurs piles spécifiées code # Root folder for code for this solution
├── lambdas # Root folder for all lambda functions
│ ├── preprocess # Lambda function that processes user input, and outputs audio files uris for Amazon Transcribe
│ ├── transcribe # Lambda function that triggers Amazon Transcribe batch transcription
│ ├── validate # Lambda function that analyzes answers from Amazon Transcribe using LLMs from Amazon Bedrock
│ ├── summarize # Lambda function that summarizes on-topic texts from Amazon Transcribe using LLMs from Amazon Bedrock
│ └── generate # Lambda function that generates documents from the summary.
└── code_stack.py # Amazon CDK stack that deploys all AWS resources
Pour adapter l'application DocGen afin d'incorporer vos propres données, les étapes suivantes doivent être suivies :
Lors du déploiement, l'infrastructure AWS CDK facilitera le transfert automatique des fichiers audio vers le compartiment Amazon S3 désigné. Par la suite, l'exécution de la AWS Step Function peut être lancée pour commencer la phase de traitement.
Une fois la solution déployée, vous pouvez abonner votre email au sujet SNS pour recevoir des notifications.
Veuillez suivre les notifications par e-mail SNS.
Si une étape du flux de travail StepFunction échoue, vous recevrez une notification par e-mail.
Après le déploiement, vous pouvez déclencher la machine d'état AWS déployée à l'aide de la commande suivante :
aws stepfunctions start-execution
--state-machine-arn "arn:aws:states:<your aws region>:<your account id>:stateMachine:genai-knowledge-capture-stack-state-machine"
--input "{"documentName": "<your document name>", "audioFileFolderUri": "s3://<your s3 bucket>/assets/audio_samples/what is amazon bedrock/"}"
Voir CONTRIBUTION pour plus d'informations.
Cette bibliothèque est sous licence MIT-0. Voir le fichier LICENCE.


