php rag
v1.1.0
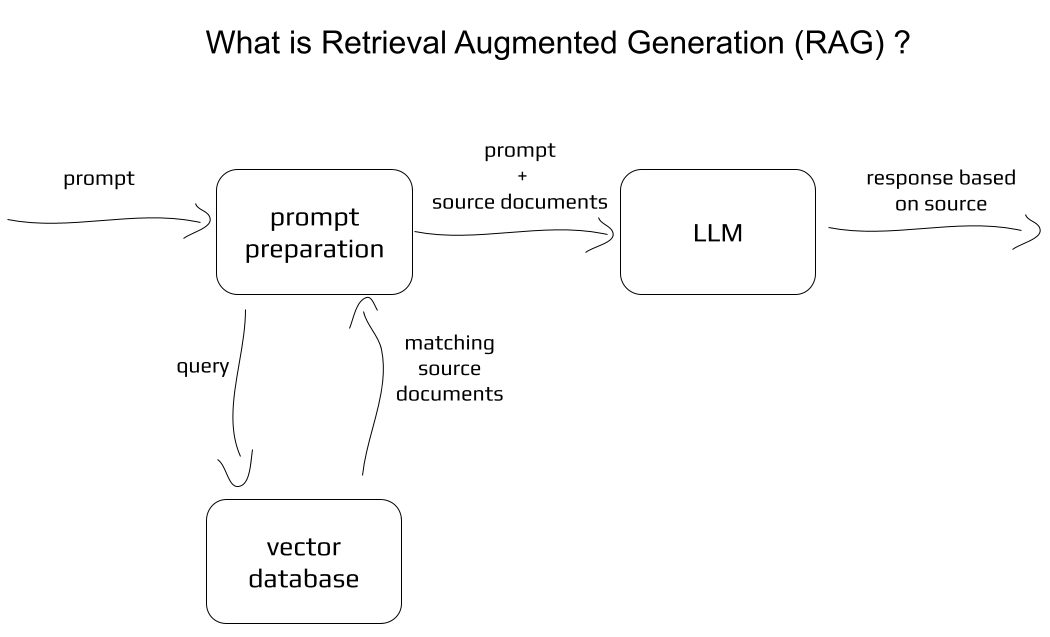
Cette application utilise LLM (Large Language Model) GPT-4o accessible via l'API OpenAI afin de générer du texte basé sur la saisie de l'utilisateur. L'entrée de l'utilisateur est utilisée pour récupérer les informations pertinentes de la base de données, puis les informations récupérées sont utilisées pour générer le texte. Cette approche combine puissance des transformateurs et accès aux documents sources.
Dans cette application particulière, la base de données de plus de 1000 sites Web est recherchée pour obtenir des informations relatives à une personne spécifique. Le véritable défi ici est que la personne recherchée "Michał Żarnecki" apparaît dans 2 contextes différents comme 2 personnes différentes portant le même nom. Le but est non seulement de trouver des informations spécifiques, mais également de comprendre le contexte et d'éviter des erreurs comme le mélange d'informations sur 2 personnes différentes portant le même nom.
J'ai décrit les concepts utilisés dans cette application avec plus de détails dans l'article sur medium.com https://medium.com/@michalzarnecki88/a-guide-to-using-llm-retrieval-augmented-Generation-with-php-3bff25ce6616
Pour la configuration, vous devez d'abord avoir installé Docker et Docker Compose https://docs.docker.com/compose/install/
Exécuter en CLI : cd app/src && composer install
Modèle de langage de configuration - choisissez parmi les options ci-dessous : option avec l'API OpenAI
"A" avec modèle gratuit via l'ollama API3 locale
"B" avec l'API OpenAI
L'option B est plus simple et nécessite moins de ressources CPU et RAM, mais vous avez besoin de la clé API OpenAI https://platform.openai.com/settings/profile?tab=api-keys L'option A nécessite plus de ressources CPU et RAM, mais vous pouvez exécuter localement en utilisant l'API ollama. Pour cette option, il est bon d'avoir un GPU.
Suivez les instructions pour l’option préférée A ou B ci-dessous :
Si vous souhaitez configurer ollama localement, veuillez utiliser les instructions au bas de ce fichier, mais en cas d'utilisation de Docker, cela ne sera pas nécessaire.
*Ollama fournit une API locale au service des LLM : « Soyez opérationnel avec de grands modèles de langage. » https://ollama.com/
docker-compose up
*ASTUCE : le script doit d'abord transformer les documents sources, ce qui peut prendre même 30 minutes. Si vous souhaitez gagner du temps, supprimez simplement une partie des documents de app/src/documents.
Attendez la fin de la configuration des conteneurs. Vous devriez voir dans les journaux de la console :
php-app | Loaded documents complete
php-app | Postgres is ready - executing command
php-app | [Sat Nov 02 11:32:28.365214 2024] [core:notice] [pid 1:tid 1] AH00094: Command line: 'apache2 -D FOREGROUND'
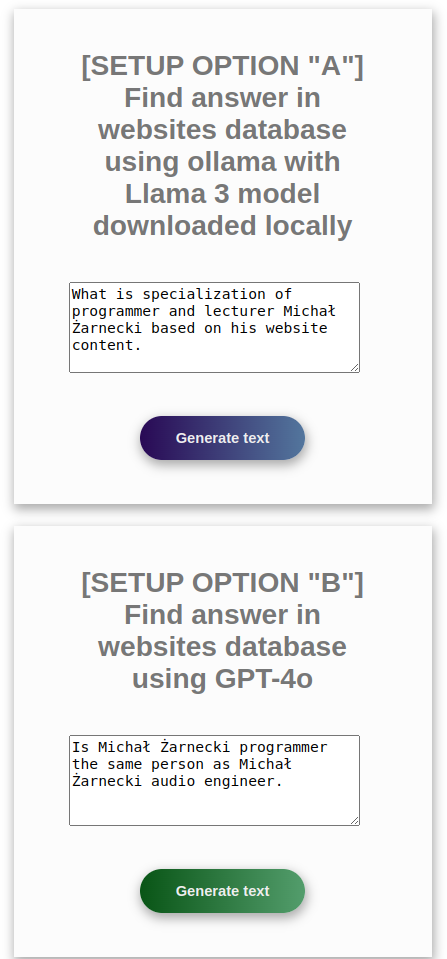
Vous pouvez utiliser l'application comme API en utilisant les requêtes ci-dessous :
Option A ollama :
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processOllama.php?api
Option B OpenAI GPT :
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processGpt.php?api
Exécutez Docker Interactive docker exec -it php-app sh
Exécuter en CLI : php minicli rag
Poser une question
##### INPUT:
What is the result of 2 + 2?
##### RESPONSE:
The result of 2 + 2 is 4.
##### INPUT:
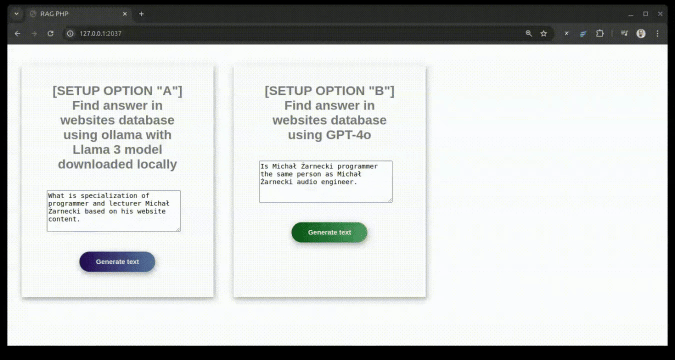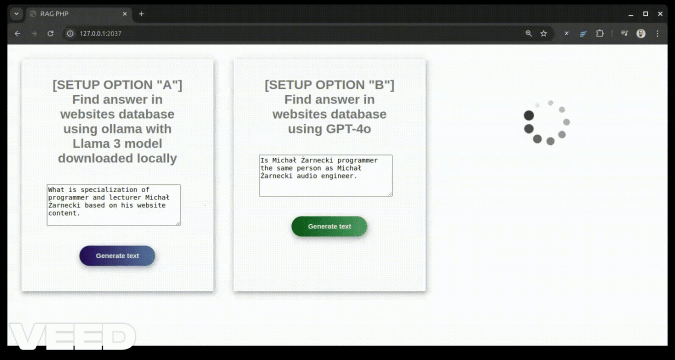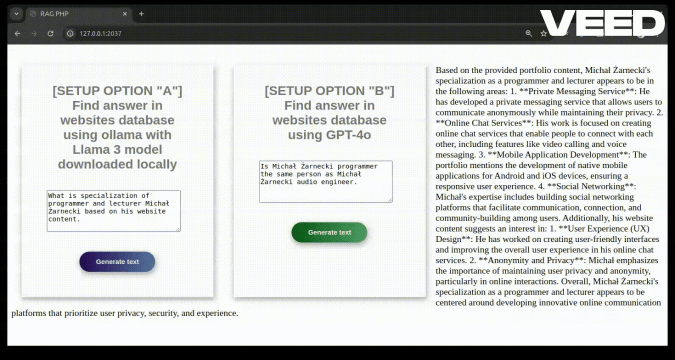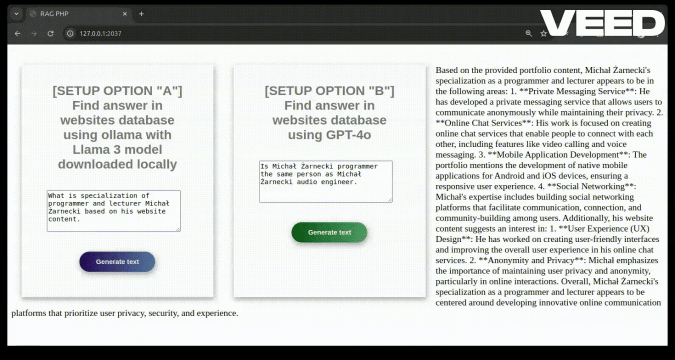
what is specialization of Michał Żarnecki based on his website content
##### RESPONSE:
Michał Żarnecki is a programmer and lecturer specializing in several key areas related to modern software development and data-driven technologies.
His expertise includes:
1. **Programming Languages**: Python, PHP, JavaScript.
2. **AI and Machine Learning**: Designing systems and solutions related to artificial intelligence and machine learning.
3. **Data Mining and Big Data**: Extracting valuable insights from large datasets.
4. **Natural Language Processing (NLP)**: Working on systems that understand and generate human language.
5. **Software Development Frameworks**: Utilizing various tools and frameworks such as Streamlit, TensorFlow, PyTorch, and langchain.
6. **Database Systems**: Implementing and working with databases like PostgreSQL, Elasticsearch, Neo4j, and others.
His portfolio highlights projects such as an AI chatbot for analyzing company documents and a self-driving vehicle based on TensorFlow and Raspberry Pi.
Additionally, he has contributed to conferences and created e-learning courses focused on machine learning, underscoring his dual role as a developer and educator.
##### INPUT:
Is Michał Żarnecki programmer the same person as Michał Żarnecki audio engineer?
##### RESPONSE:
Based on the information provided, it appears that Michał Żarnecki the programmer and Michał Żarnecki the audio engineer are not the same person.
Here’s why:
1. **Fields of Expertise**:
- Michał Żarnecki, the audio engineer, was a well-known operator and reżyser dźwięku (sound director) in Poland, with notable contributions to the Polish film industry, as mentioned in the Wikipedia excerpt.
- Michal Żarnecki, the programmer, has a portfolio focused on programming in Python, PHP, and JavaScript, with projects related to AI, machine learning, data mining, and software development.
2. **Lifespan**:
- Michał Żarnecki the audio engineer was born on November 12, 1946, and passed away on November 21, 2016.
- The projects listed in Michał Żarnecki the programmer’s portfolio date from 2014 to 2016, which would be conflicting if he had passed away in 2016 and was actively working in those years.
3. **Occupational Focus**:
- The audio engineer has a career documented in film sound engineering and education.
- The programmer’s career is centered around software development, mobile applications, ERP systems, and consulting in technology.
Given the distinct differences in their professional domains, timelines, and expertise, it is highly unlikely that they are the same individual
Notion de base :
Plus de détails pour les nerds :
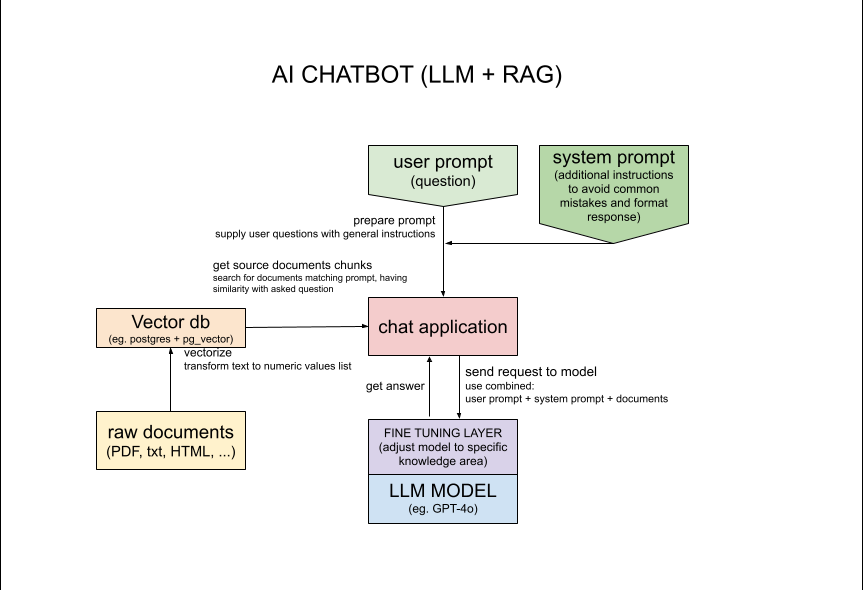
Pour accélérer le chargement des documents ou en utiliser davantage pour une meilleure récupération, manipulez la valeur $skipFirstN dans app/src/service/DocumentLoader.php:20
Après les modifications apportées aux scripts PHP, reconstruisez le docker avec les commandes :
docker-compose rm
docker rmi -f php-rag
docker-compose up
les sites Web utilisés pour remplir la base de données vectorielles proviennent de l'ensemble de données « Website Classification » sur Kaggle auteur : Hetul Mehta lien : https://www.kaggle.com/datasets/hetulmehta/website-classification?resource=download
articles/dépôts connexes :
https://medium.com/mlearning-ai/create-a-chatbot-in-python-with-langchain-and-rag-85bfba8c62d2
https://github.com/Krisseck/php-rag
https://ollama.com/downloadollama pull llama3:latestollama pull mxbai-embed-large ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 7 seconds ago
llama3:latest 365c0bd3c000 4.7 GB 17 seconds ago
ollama serveapp/src/loadDocuments.php (par défaut) S'il vous plaît laissez-moi savoir si vous trouvez des problèmes ou des choses à améliorer. Vous pouvez me contacter à l'adresse e-mail [email protected]. N'hésitez pas à signaler des bugs et à proposer des mises à niveau dans les pull request.


