ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
Introduction Youtube • Chat Discord • Documentation complète
L'installation d'UStore est un jeu d'enfant et son utilisation est à peu près aussi simple qu'un dict Python.
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' Nous venons de créer une base de données transactionnelle intégrée en mémoire et d'ajouter une entrée dans sa collection main . Préféreriez-vous ces données sur disque ? Changez une ligne.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )Préféreriez-vous vous connecter à un serveur UStore distant ? UStore est livré avec une interface Apache Arrow Flight RPC !
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) Stockez-vous MultiDiGraph de type NetworkX ? Ou DataFrame de type Pandas ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1Les appels de fonction peuvent sembler identiques, mais l'implémentation sous-jacente peut traiter des centaines de téraoctets de données placées quelque part dans la mémoire persistante d'une machine distante.
Est-ce que quelqu'un d'autre met à jour simultanément ces collections ? Regroupez vos opérations pour garantir la cohérence !
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )Jusqu'à présent, nous n'avons couvert que la pointe de l'UStore. Vous pouvez l'utiliser pour...
Mais UStore peut faire bien plus. Voici la carte :
## Utilisation de base
UStore n'est pas seulement conçu comme une base de données, mais aussi comme une boîte à outils « construire votre base de données » et un standard ouvert pour les bases de données potentiellement transactionnelles NoSQL, définissant des interfaces binaires sans copie pour les opérations « Créer, lire, mettre à jour, supprimer », ou CRUD en abrégé.
Quelques en-têtes C99 simples peuvent relier presque n'importe quel moteur de stockage sous-jacent à de nombreux pilotes de langage de haut niveau, étendant leur prise en charge des valeurs de chaîne binaire aux graphiques, aux documents à schéma flexible et à d'autres modalités, dans le but de remplacer MongoDB, Neo4J, Pinecone et ElasticSearch. avec un seul système transactionnel ACID.
Redis, par exemple, fournit RediSearch, RedisJSON et RedisGraph avec des objectifs similaires. UStore fait mieux, vous permettant d'ajouter vos magasins de valeurs clés (KVS) préférés, intégrés, autonomes ou fragmentés, tels que FoundationDB, multipliant ainsi ses fonctionnalités.
Les gros objets binaires peuvent être placés dans UStore. Les performances varient considérablement en fonction de la technologie sous-jacente utilisée. L'UCSet en mémoire sera le plus rapide, mais le moins adapté aux objets plus gros. L'UDisk persistant, lorsqu'il est correctement configuré, peut contourner entièrement le noyau Linux, y compris la couche du système de fichiers, en s'adressant directement aux périphériques bloc.
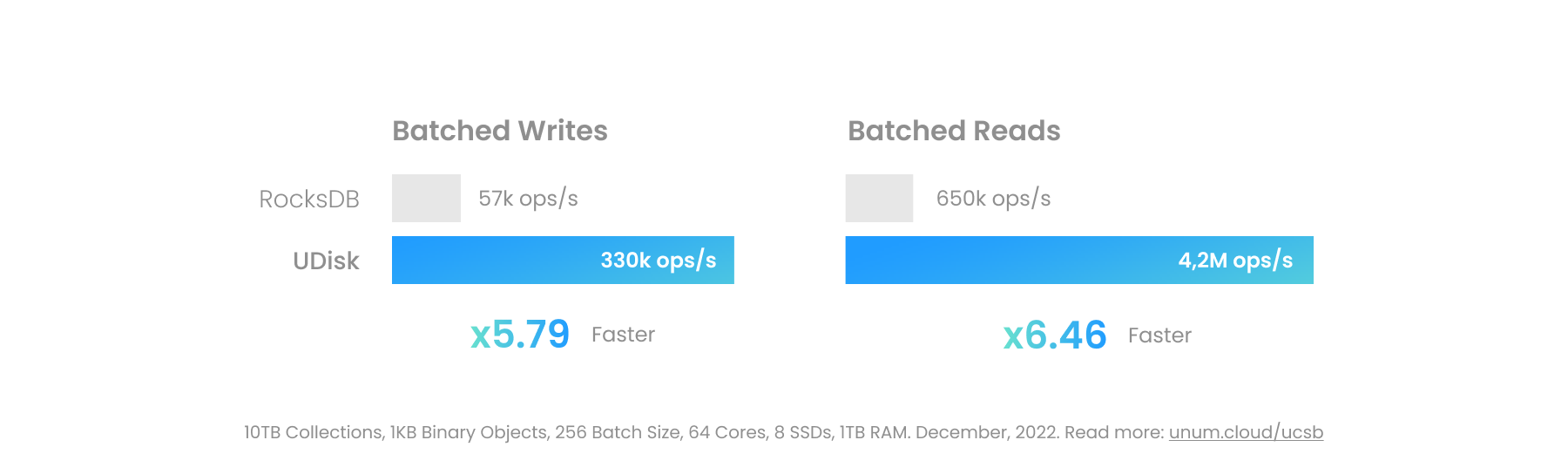
Les E/S persistantes modernes sur les serveurs haut de gamme peuvent dépasser 100 Go/s par socket lorsqu'elles sont construites sur des pilotes d'espace utilisateur tels que SPDK. Ceci est proche du débit réel de la RAM haut de gamme et ouvre de nouveaux cas d’utilisation peu courants dans les bases de données. On peut désormais placer un fichier vidéo de la taille d'un gigaoctet dans une base de données transactionnelle ACID, juste à côté de ses métadonnées, au lieu d'utiliser un magasin d'objets distinct, comme MinIO.
JSON est le format de document le plus couramment utilisé de nos jours. Les collections de documents UStore prennent en charge JSON, ainsi que MessagePack et BSON, utilisés par MongoDB.

UStore n'évolue pas encore horizontalement, mais offre des performances de nœud unique beaucoup plus élevées et offre une évolutivité verticale presque linéaire sur les systèmes multicœurs grâce aux bibliothèques open source simdjson et yyjson . De plus, pour interagir avec les données, vous n'avez pas besoin d'un langage de requête personnalisé comme MQL. Au lieu de cela, nous donnons la priorité aux normes RFC ouvertes pour véritablement éviter les blocages des fournisseurs :
Les bases de données Graph modernes, comme Neo4J, sont confrontées à des charges de travail importantes. Ils nécessitent trop de RAM et leurs algorithmes observent les données une entrée à la fois. Nous optimisons sur les deux fronts :
Les magasins de fonctionnalités et les bases de données vectorielles, comme Pinecone, Milvus et USearch, fournissent des index autonomes pour la recherche vectorielle. UStore l'implémente en tant que modalité distincte, à égalité avec les documents et les graphiques. Caractéristiques:
UStore pour Python et pour C++ sont très différents. Notre SDK Python imite d'autres bibliothèques Python - Pandas et NetworkX. De même, la bibliothèque C++ fournit l’interface attendue par les développeurs C++.
Comme nous le savons, les gens utilisent des langues différentes à des fins différentes. Certaines fonctionnalités de niveau C ne sont pas implémentées pour certains langages. Soit parce qu'il n'y avait pas de demande, soit parce que nous n'y sommes pas encore parvenus.
| Nom | Traiter | Collections | Lots | Documents | Graphiques | Copies |
|---|---|---|---|---|---|---|
| Norme C99 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK C++ | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| SDK Python | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| SDK GoLang | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| SDK Java | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| API de vol de flèche | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
Certaines interfaces ici sont entourées d’écosystèmes entiers ! L'API Apache Arrow Flight, par exemple, possède ses propres pilotes pour C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby et Rust.
Les moteurs suivants peuvent être utilisés de manière presque interchangeable. Historiquement, LevelDB était le premier. RocksDB a ensuite amélioré ses fonctionnalités et ses performances. Il sert désormais de base à la moitié des startups de SGBD.
| NiveauDB | RochesDB | Disque U | UCSet | |
|---|---|---|---|---|
| Vitesse | 1x | 2x | 10x | 30x |
| Persistant | ✓ | ✓ | ✓ | ✗ |
| Transactionnel | ✗ | ✓ | ✓ | ✓ |
| Bloquer la prise en charge des appareils | ✗ | ✗ | ✓ | ✗ |
| Cryptage | ✗ | ✗ | ✓ | ✗ |
| Montres | ✗ | ✓ | ✓ | ✓ |
| Instantanés | ✓ | ✓ | ✓ | ✗ |
| Échantillonnage aléatoire | ✗ | ✗ | ✓ | ✓ |
| Énumération groupée | ✗ | ✗ | ✓ | ✓ |
| Collections nommées | ✗ | ✓ | ✓ | ✓ |
| Open Source | ✓ | ✓ | ✗ | ✓ |
| Compatibilité | N'importe lequel | N'importe lequel | Linux | N'importe lequel |
| Mainteneur | Unum | Unum |
UCSet et UDisk sont tous deux conçus et maintenus par Unum. Les deux sont complets en fonctionnalités, mais la fonctionnalité la plus cruciale offerte par nos alternatives est la performance. Être rapide en mémoire est facile. La logique de base d'UCSet se trouve dans la bibliothèque ucset basée sur un modèle d'en-tête uniquement.
La conception d'UDisk a été une entreprise beaucoup plus difficile qui a duré 7 ans. Cela comprenait l'invention de nouvelles structures arborescentes, la mise en œuvre d'un contournement partiel du noyau avec io_uring , un contournement complet avec SPDK , l'accélération GPU CUDA et même un système de fichiers interne personnalisé. UDisk est le premier moteur conçu à partir de zéro avec des architectures parallèles et le contournement du noyau à l'esprit .
L'atomicité est toujours garantie. Même sur les écritures non transactionnelles, soit toutes les mises à jour réussissent, soit toutes échouent.
La cohérence est mise en œuvre sous la forme la plus stricte possible - « Sérialisabilité stricte », ce qui signifie que :
Le comportement par défaut peut toutefois être modifié au niveau d'opérations spécifiques. Pour cela, le ::ustore_option_transaction_dont_watch_k peut être transmis à ustore_transaction_init() ou à toute opération transactionnelle de lecture/écriture, pour contrôler les contrôles de cohérence lors de la préparation.
| Lit | Écrit | |
|---|---|---|
| Tête | Série stricte | Série stricte |
| Transactions sur instantanés | En série | Série stricte |
| Transactions sans instantanés | Série stricte | Série stricte |
| Transactions sans montres | Série stricte | Séquentiel |
Si ce sujet est nouveau pour vous, veuillez consulter le blog Jepsen.io sur la cohérence.
| Lit | Écrit | |
|---|---|---|
| Transactions sur instantanés | ✓ | ✓ |
| Transactions sans instantanés | ✗ | ✓ |
La durabilité ne s'applique pas aux systèmes en mémoire par définition. Dans les systèmes hybrides ou persistants, nous préférons le désactiver par défaut. Presque tous les SGBD basés sur KVS préfèrent implémenter leur propre mécanisme de durabilité. C'est encore plus vrai dans les bases de données distribuées, où trois journaux d'écriture anticipée distincts peuvent exister :
Si vous avez toujours besoin de durabilité, effacez les écritures sur les commits avec un indicateur facultatif. Dans le pilote C, vous appelleriez ustore_transaction_commit() avec l'indicateur ::ustore_option_write_flush_k .
L'ensemble du SGBD s'inscrit dans une image Docker inférieure à 100 Mo. Exécutez le script suivant pour extraire et exécuter le conteneur, exposant le serveur Apache Arrow Flight sur le port 38709 . Les SDK clients communiqueront également via ce même port, par défaut.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustoreLe fichier de configuration par défaut peut être récupéré avec :
cat /var/lib/ustore/config.jsonLe moyen le plus simple de se connecter et de tester serait la commande suivante :
python ...Les images UStore préemballées sont disponibles sur plusieurs plateformes :
N'hésitez pas à commercialiser et redistribuer UStore.
Le réglage des bases de données relève autant de l’art que de la science. Des projets comme RocksDB fournissent des dizaines de boutons pour optimiser le comportement. Nous autorisons le transfert de fichiers de configuration spécialisés vers le moteur sous-jacent.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}Nous disposons également d’une procédure plus simple, qui suffirait à 80 % des utilisateurs. Cela peut être étendu pour utiliser plusieurs appareils ou répertoires, ou pour transférer une configuration de moteur spécialisée.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}Les collections de bases de données peuvent également être configurées avec des fichiers JSON.
Depuis la version actuelle, des entiers signés 64 bits sont utilisés. Il autorise des clés uniques comprises entre [0, 2^63) . Des versions 128 bits avec UUID arrivent, mais les clés de longueur variable sont fortement déconseillées. Pourquoi ?
L'utilisation de clés de longueur variable impose de nombreuses limitations sur la conception d'un magasin de valeurs-clés. Premièrement, cela implique des comparaisons lentes entre les caractères – un tueur de performances sur les processeurs hyperscalaires modernes. Deuxièmement, il force la jointure des clés et des valeurs sur un disque afin de minimiser les métadonnées nécessaires à la navigation. Enfin, cela viole notre vision logique simple du KVS en tant qu'"allocateur de mémoire persistant", lui attribuant beaucoup plus de responsabilités.
L'approche recommandée pour gérer les clés de chaîne est la suivante :
Cela entraînera un point de conversion unique des représentations de chaîne en représentations entières et maintiendra la plupart du système vif et les interfaces de niveau C plus simples qu'elles n'auraient pu l'être.
Nous ne pouvons actuellement traiter que des valeurs de 4 Go ou moins. Pourquoi? Les magasins de valeurs clés sont généralement destinés aux opérations à haute fréquence. Fréquemment (des milliers de fois par seconde), l'accès et la modification de fichiers de 4 Go et plus sont impossibles sur le matériel moderne. Nous nous en tenons donc à des types de longueur plus petite, ce qui facilite légèrement l'utilisation de la représentation Apache Arrow et permet au KVS de mieux compresser les index.
Notre feuille de route de développement est publique et est hébergée dans le référentiel GitHub. Les tâches à venir incluent :
Lisez la feuille de route complète dans nos documents ici.


