files search guide
1.0.0
L'objectif de ce guide est de décrire les outils de recherche et de simplification de la recherche d'informations textuelles dans les fichiers et bases de données les plus courants.
Cela pourrait bénéficier aux enquêtes journalistiques, au travail avec de grands volumes de données telles que les fuites de documents et l'eDiscovery.
Le guide est applicable pour la recherche de violations de divers formats (archives gros fichiers texte, csv/sql), de documents (pdf, xls/x, doc/x) et dans des bases de données spécialisées (1C, Cronos, etc.).
Version anglaise | version russe
Datashare - une plateforme multi-OS d'ICIJ conçue pour partager de grands ensembles de données de documents, notamment entre chercheurs et journalistes.
Il vous permet de rechercher des fichiers PDF, des images, des textes, des feuilles de calcul, des diapositives et bien plus encore.
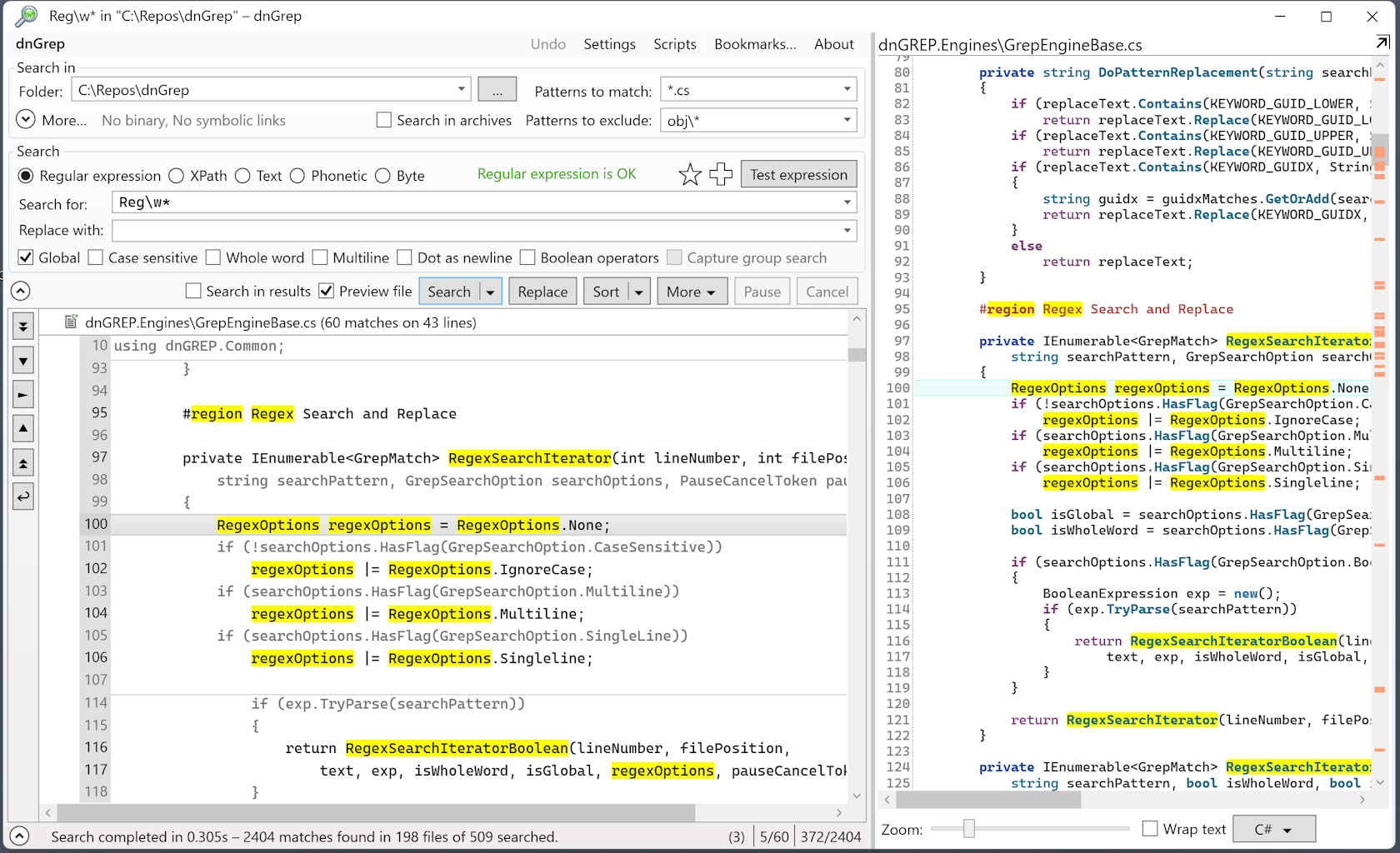
dnGrep - un outil avec une interface utilisateur graphique pour Windows, capable de rechercher dans des fichiers texte, des documents, des PDF et dans les formats d'archives les plus populaires. Les expressions régulières et les recherches récursives dans les répertoires sont prises en charge. Capacités supplémentaires : intégration de l'Explorateur Windows !
Malgré quelques problèmes de visualisation de la recherche et des échecs avec les grandes archives, dnGrep semble être l'outil le plus prometteur pour la recherche de masse dans les fichiers texte.
AstroGrep - un outil doté d'une interface utilisateur graphique pour Windows qui permet aux utilisateurs d'effectuer des recherches de texte dans plusieurs fichiers, ce qui le rend particulièrement utile pour ceux qui ont besoin de gérer de grands ensembles de documents. Il prend en charge différents formats de fichiers et offre une interface conviviale.
Les principaux avantages d'AstroGrep incluent sa capacité à fournir des résultats rapides à partir de recherches de texte dans une vaste gamme de fichiers. De plus, AstroGrep met en évidence les termes recherchés dans les fichiers, ce qui simplifie le processus d'examen des résultats de recherche. Il comprend également des fonctionnalités utiles telles que la correspondance d'expressions régulières, qui permettent des recherches plus complexes et précises.
Cependant, AstroGrep se concentre principalement sur les recherches de texte, son utilité est donc limitée aux données textuelles et ne s'étend pas aux recherches dans les documents Excel, les archives, les fichiers image ou audio.
Google Pinpoint - un outil Cloud conçu pour aider les journalistes à gérer de gros volumes d'informations. Il prend en charge différents types de fichiers, notamment les documents (convertit presque tout en PDF), les images et les fichiers audio, et s'intègre à Google Drive pour une gestion efficace des données. L'outil améliore l'efficacité de la recherche en permettant des recherches rapides dans de vastes ensembles de données.
Les avantages de Pinpoint incluent des capacités de recherche robustes qui permettent de gagner du temps en simplifiant le processus d'examen des données. Il prend également en charge le travail collaboratif, permettant à plusieurs utilisateurs de travailler simultanément sur le même projet.
Cependant, en tant qu’outil basé sur le cloud, il nécessite une connexion Internet stable.
L'outil Unix grep est le standard des chercheurs. Vous ne devez transmettre que deux paramètres : le modèle de recherche et le fichier, et l'outil recherche les lignes qui correspondent au modèle. Le modèle peut être une simple chaîne (par exemple, un numéro de téléphone ou une adresse e-mail).
grep est utilisé par d'autres utilitaires (ou simplement par sa syntaxe), considérons donc quelques arguments principaux :
-A number - imprime des lignes number de contexte après chaque correspondance
-B number - imprime les lignes number du contexte avant chaque correspondance
-C number - imprime les lignes number du contexte entourant chaque correspondance
-i - recherche insensible à la casse : la recherche sur la Target et les mots target seront trouvés TARGET
-R - recherche récursive : l'outil analysera tous les répertoires imbriqués (vous pouvez utiliser * comme nom de fichier)
-a - traite tous les fichiers comme des fichiers texte, à utiliser en cas d'erreur. Binary file (standard input) matches
Exemple d'utilisation grep :
grep -iR target dumps/* - recherche sur le mot target (insensible à la casse) dans tous les fichiers texte du répertoire dumps
Il sera préférable de convertir les fichiers XLSX en CSV et d'utiliser grep pour la recherche ou simplement d'utiliser l'outil xlsxgrep .
Exemple d'utilisation :
xlsxgrep target -H -N -r dumps/*
Il sera préférable d'utiliser zgrep pour effectuer une recherche dans les archives .gz et .tgz.
L'outil est un analogue direct de grep à l'exception des éléments suivants :
-R n'est pas supporté Exemple d'utilisation zgrep :
zgrep -ia target dumps/* - recherche sur le mot target (insensible à la casse) dans tous les fichiers texte et via les archives gz dans les dumps du répertoire
Il sera préférable d'utiliser l'outil de décompression 7zip avec grep pour rechercher dans les archives 7z :
Exemple d'utilisation :
7z x archive.7z -so | grep ...
7zip peut également fonctionner avec d'autres types d'archives.
Il sera préférable d'utiliser l'outil de décompression unrar avec grep pour effectuer une recherche dans les archives rar :
Exemple d'utilisation :
unrar p archive.rar | grep ...
Il existe un logiciel de base de données et un format de fichier Cronos populaires en Russie. Il sera préférable d'utiliser une version appropriée du client officiel (Cronos, CronosPlus, CronosPro) ou vous pouvez simplement convertir la base de données en fichier CSV avec l'outil cronodump :
git clone https://github.com/alephdata/cronodump && cd cronodump
python3 setup.py install
croconvert --csv cronos_db_directory/
# a new directory will be created
ls cronodump-2022-04-25-02-53-57-293000
БТК.csv Files-FL
grep ...
Il existe un logiciel populaire 1C en Russie. 1C utilise ses propres formats de fichiers : .1CD, .efd et autres. Vous pouvez utiliser onec_dtools pour écrire votre script personnalisé afin d'extraire toutes les données de la base de données 1C ou utiliser 1c-database-converter pour convertir la base de données en fichiers CSV.
./run.py 8-2-14.1CD
Target: 8-2-14.1CD
Results found: 1
1) Out Dir: 8-2-14.1CD_csv
File Type: 1CD
Status: Exported content of 1CD file
------------------------------
Total found: 1


