aiwhispr
version 0.941
AIWhispr est un outil sans/low code pour automatiser les pipelines d'intégration de vecteurs pour la recherche sémantique. Une configuration simple pilote le pipeline pour lire les fichiers, extraire le texte, créer des intégrations vectorielles et les stocker dans une base de données vectorielles.
AIWhispr

AIWhispr dispose de connecteurs pour les bases de données vectorielles suivantes
1 Qrant
2 Milvus
3 Tisser
4 Sens de la typographie
5MongoDB
6 Postgres - PGVector
Veuillez vous assurer que vous avez installé et démarré votre base de données vectorielles.
La variable d'environnement AIWHISPR_HOME_DIR doit être le chemin complet du répertoire aiwhispr.
La variable d'environnement AIWHISPR_LOG_LEVEL peut être définie sur DEBUG/INFO/AVERTISSEMENT/ERREUR.
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
N'oubliez pas d'ajouter les variables d'environnement dans votre script de connexion shell
Exécutez la commande ci-dessous
$AIWHISPR_HOME/shell/install_python_packages.sh
Si l'installation d'uwsgi échoue, assurez-vous que gcc, python-dev et python3-dev sont installés.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr est livré avec une application simplifiée pour vous aider à démarrer.
Exécutez l'application simplifiée
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
Cela devrait démarrer une application simplifiée sur le port par défaut 8501 et démarrer une session sur votre navigateur Web.
Il y a 3 étapes pour configurer le pipeline d'indexation de votre contenu pour la recherche sémantique.
1. Configurer pour lire les fichiers à partir d'un emplacement de stockage
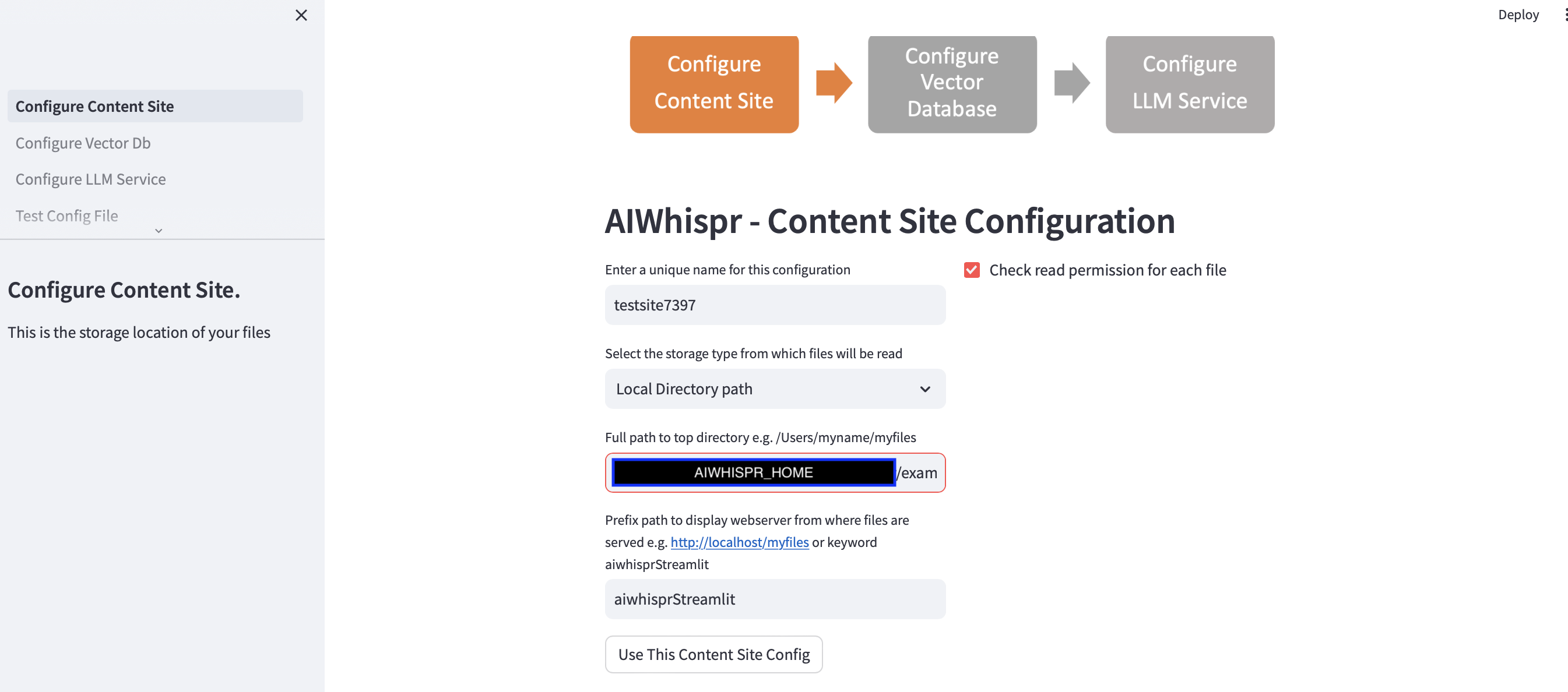
Vous pouvez continuer avec la configuration par défaut en cliquant sur le bouton "Utiliser cette configuration de site de contenu"
et passez à l'étape suivante pour configurer la connexion à la base de données vectorielle.
L'exemple par défaut indexera les actualités de la BBC pour la recherche sémantique.
L'application simplifiée suppose que vous démarrez une nouvelle configuration et attribuera un nom de configuration aléatoire. Vous pouvez l'écraser pour lui donner un nom plus significatif. Le nom de la configuration doit être unique ; il ne peut pas contenir d'espaces ou de caractères spéciaux.
La configuration par défaut lira le contenu du chemin du répertoire local $AIWHISPR_HOME/examples/http/bbc
Celui-ci contient plus de 2 000 actualités de la BBC qui sont indexées pour la recherche sémantique.
Vous pouvez choisir de lire le contenu stocké sur AWS S3, Azure Blob, Google Cloud Storage.
La configuration du chemin du préfixe est utilisée pour créer les liens Web href pour les résultats de la recherche. Vous pouvez continuer avec le mot clé par défaut "aiwhisprStreamlit"
Cliquez sur le bouton "Utiliser cette configuration de site de contenu" et passez à l'étape suivante pour configurer la connexion à la base de données vectorielle en cliquant sur "Configurer la base de données vectorielle" dans la barre latérale gauche.
2. Configurer la base de données vectorielle
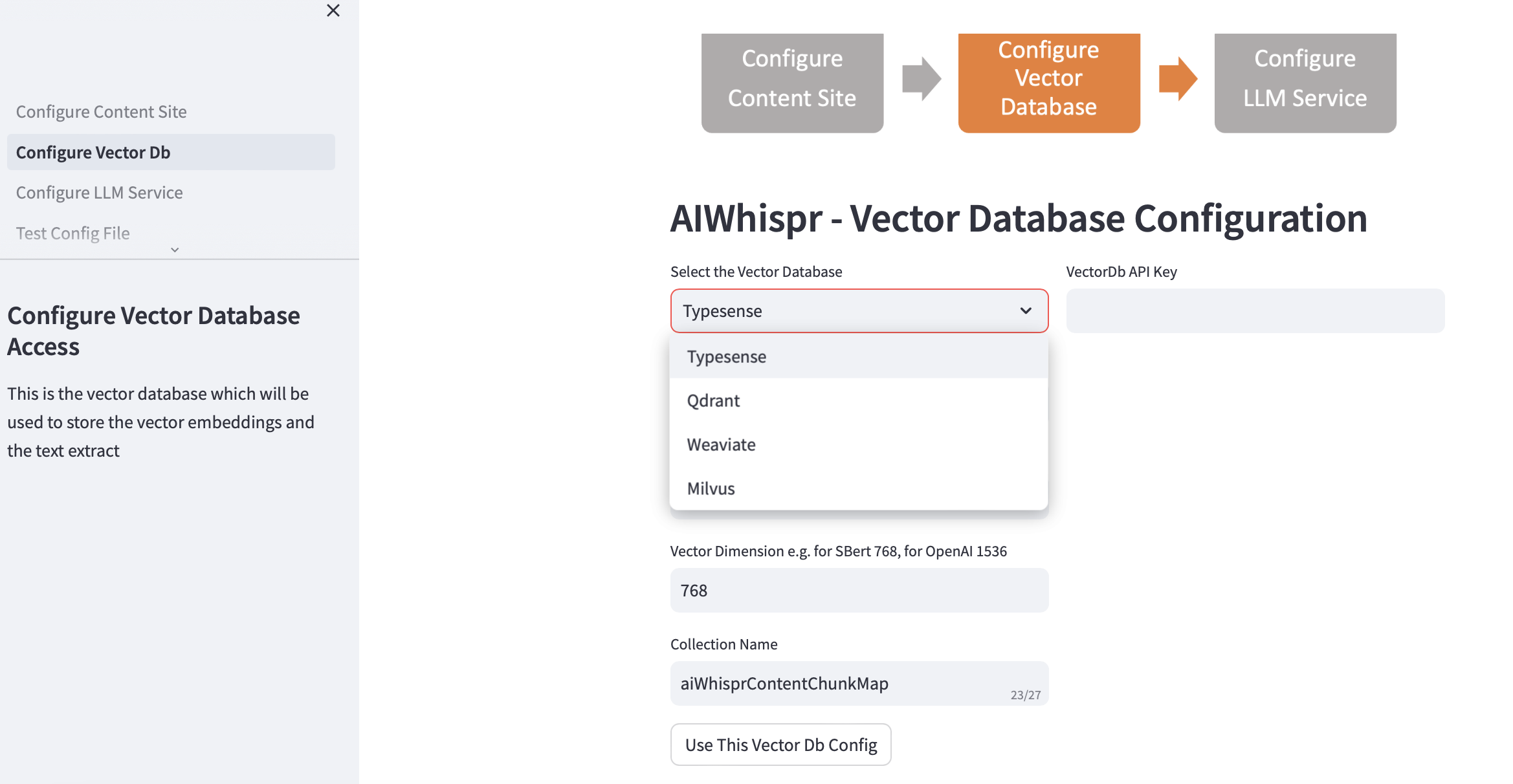
Choisissez votre vectordb et fournissez les détails de connexion.
Lorsque vous choisissez la base de données vectorielle, l'adresse IP et les numéros de port de Vector Db sont renseignés en fonction des installations par défaut. Vous pouvez modifier cela en fonction de votre configuration.
Votre base de données vectorielles doit être configurée pour l'authentification. Dans le cas de Qdrant, Weaviate, Typesense, une clé API est requise. Pour Milvus, une combinaison d'identifiant utilisateur et de mot de passe doit être configurée.
La taille de la dimension vectorielle doit être spécifiée en fonction du LLM que vous prévoyez d'utiliser pour encoder le texte sous forme d'incorporations vectorielles. Exemple : pour Open AI "text-embedding-ada-002", cela doit être configuré sur 1536, qui est la taille du vecteur renvoyé par le service d'intégration OpenAI.
Le nom de collection par défaut créé dans la base de données vectorielles est aiwhisprContentChunkMap. Vous pouvez spécifier votre propre nom de collection.
Cliquez sur le bouton « Utiliser cette configuration de base de données vectorielle », puis passez à l'étape suivante en cliquant sur « Configurer le service LLM » dans la barre latérale gauche.
3. Configurer le service LLM
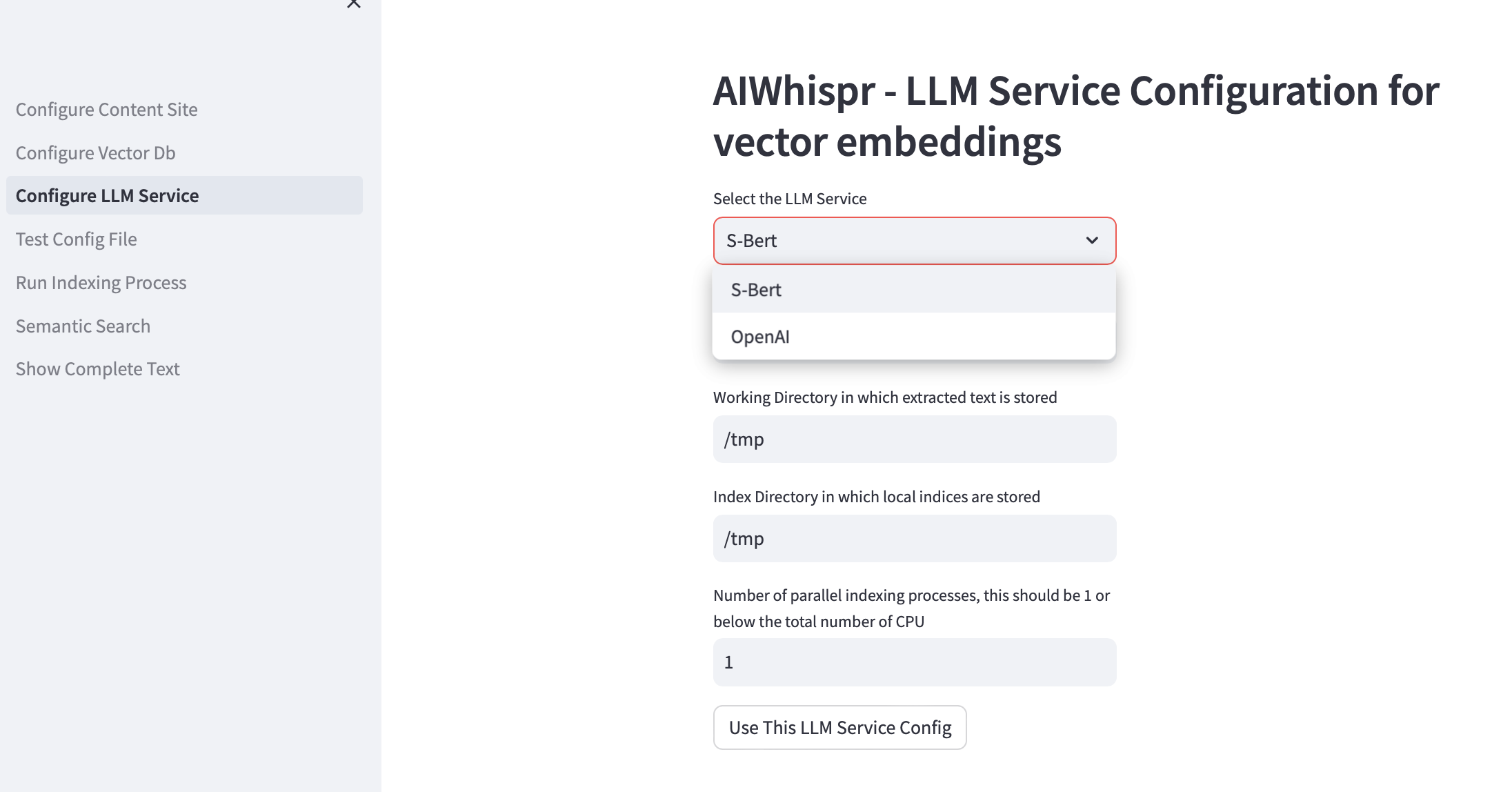
Vous pouvez choisir de créer des intégrations vectorielles à l'aide de modèles pré-entraînés Sbert exécutés localement ou d'utiliser l'API OpenAI.
Pour la famille de modèles SBert, le modèle par défaut utilisé est all-mpnet-base-v2. Vous pouvez spécifier un autre modèle SBert.
Pour OpenAI, le modèle d'intégration par défaut est text-embedding-ada-002
Le répertoire de travail par défaut est /tmp
Le répertoire de travail est l'emplacement sur la machine locale qui sera utilisé comme répertoire de travail pour traiter les fichiers lus/téléchargés depuis votre emplacement de stockage. Le texte extrait de vos documents est ensuite découpé en morceaux plus petits, généralement 700 mots, qui sont ensuite codés sous forme d'intégrations vectorielles. Le répertoire de travail est utilisé pour stocker les morceaux de texte.
Le répertoire d'indexation local par défaut est /tmp
Vous pouvez spécifier un chemin de répertoire local persistant pour le répertoire de travail et d'index.
Le répertoire index est utilisé pour stocker la liste d'indexation des fichiers de contenu qui doivent être lus. AIWhispr prend en charge plusieurs processus d'indexation, chaque processus utilisera sa propre liste d'indexation, vous permettant ainsi d'exploiter plusieurs processeurs sur votre machine.
Si vous souhaitez exploiter plusieurs processeurs pour l'indexation (lecture de contenu, création d'intégration vectorielle, stockage dans une base de données vectorielle), spécifiez-le dans la zone de test pour le nombre de processus parallèles. Notre recommandation est que cela soit 1 ou maximum (nombre de processeurs/2). Exemple sur une machine à 8 processeurs, cela doit être défini sur 4. AIWhispr utilise le multitraitement pour contourner les limitations de Python GIL.
Cliquez sur « Utiliser cette configuration de service LLM » pour créer la version finale de votre fichier de configuration de pipeline d'intégration de vecteurs.
Le contenu du fichier de configuration et son emplacement sur votre machine seront affichés.
Vous pouvez tester cette configuration en cliquant sur "Test Config File" dans la barre latérale gauche.
4. Configuration des tests
Vous devriez maintenant voir un message indiquant l'emplacement de votre fichier de configuration de pipeline d'intégration vectorielle et un bouton "Test Configfile".
Cliquer sur le bouton lancera le processus qui testera la configuration du pipeline pour
Vous devriez voir le message « NO ERRORS » à la fin des journaux qui vous informe que cette configuration de pipeline peut être utilisée.
Cliquez sur « Exécuter le processus d'indexation » dans la barre latérale gauche pour démarrer le pipeline.
5. Exécuter le processus d'indexation
Vous devriez voir un bouton "Démarrer l'indexation".
Cliquez sur ce bouton pour démarrer le pipeline. Les journaux sont mis à jour toutes les 15 secondes.
L'exemple par défaut indexe plus de 2 000 reportages de la BBC, ce qui prend environ 20 minutes.
Ne quittez pas cette page pendant que le processus d'indexation est en cours, c'est-à-dire lorsque le statut Streamlit « En cours d'exécution » est affiché en haut à droite.
Vous pouvez également vérifier si le processus d'indexation est en cours d'exécution à l'aide de grep sur votre machine.
ps -ef | grep python3 | grep index_content_site.py
6. Recherche sémantique
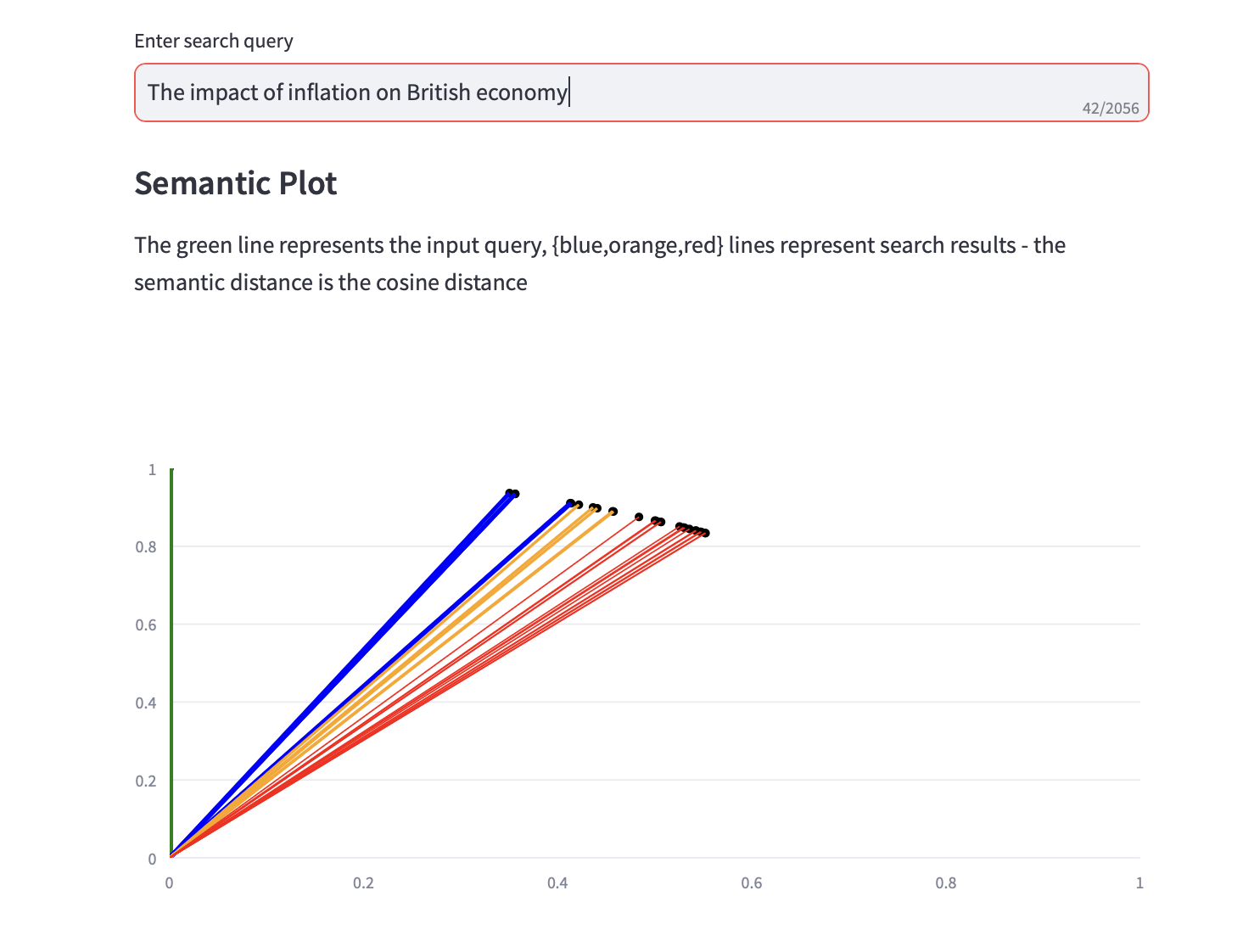
Vous pouvez désormais exécuter des requêtes de recherche sémantique.
Un tracé sémantique qui affiche la distance cosinus et une analyse des 3 principales analyses PCA pour les résultats de la recherche est également affiché avec les résultats de la recherche de texte.