korpatbert
1.0.0
KorPatBERT (Korean Patent BERT) est un modèle de langage d'IA recherché et développé par le Service coréen d'information sur les brevets.
Afin de résoudre les problèmes de traitement du langage naturel coréen dans le domaine des brevets et de préparer une infrastructure d'information intelligente dans l'industrie des brevets, une formation préalable sur une grande quantité de documents de brevet nationaux (base : environ 4,06 millions de documents, grande : environ 5,06 millions de documents) est basé sur l'architecture du modèle de base Google BERT existant (pré-formation) et est fourni gratuitement.
Il s'agit d'un modèle linguistique pré-entraîné hautes performances spécialisé dans le domaine des brevets et pouvant être utilisé dans diverses tâches de traitement du langage naturel.
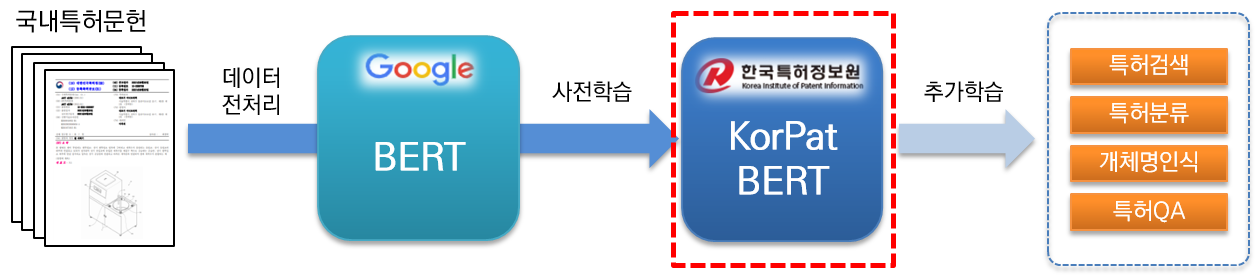
[Base KorPatBERT]
[KorPatBERT-large]
[Base KorPatBERT]
[KorPatBERT-large]
Environ 10 millions de noms majeurs et de noms composés ont été extraits des documents de brevet utilisés dans l'apprentissage des modèles de langage, et ceux-ci ont été ajoutés au dictionnaire utilisateur de l'analyseur de morphèmes coréen Mecab-ko, puis divisés en sous-mots via Google SentencePièce. Il s'agit d'un MSP spécialisé. tokeniseur (Mecab-ko Sentencepiece Patent Tokenizer).
| modèle | Haut@1(ACC) |
|---|---|
| GoogleBERT | 72.33 |
| KorBERT | 73.29 |
| KOBERT | 33,75 |
| KrBERT | 72.39 |
| Base KorPatBERT | 76.32 |
| KorPatBERT-grand | 77.06 |
| modèle | Haut@1(ACC) | Top@3(ACC) | Top@5(ACC) |
|---|---|---|---|
| Base KorPatBERT | 61,91 | 82.18 | 86,97 |
| KorPatBERT-grand | 62,89 | 82.18 | 87.26 |
| Nom du programme | version | Chemin du guide d’installation | Requis? |
|---|---|---|---|
| python | 3.6 et supérieur | https://www.python.org/ | Oui |
| anaconda | 4.6.8 et supérieur | https://www.anaconda.com/ | N |
| flux tensoriel | 2.2.0 et supérieur | https://www.tensorflow.org/install/pip?hl=ko | Oui |
| morceau de phrase | 0.1.96 ou supérieur | https://github.com/google/sentencepiece | N |
| Mecab-ko | 0.996-fr-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Oui |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Oui |
| mecab-python | 0.996-fr-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Oui |
| python-mecab-ko | 1.0.11 ou supérieur | https://pypi.org/project/python-mecab-ko/ | Oui |
| kéras | 2.4.3 et supérieur | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0.14.4 et supérieur | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 et supérieur | https://github.com/tqdm/tqdm | N |
| soynlp | 0.0.493 ou supérieur | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ C'est la même chose que la méthode d'apprentissage de base de Google BERT, et pour des exemples d'utilisation, veuillez vous référer à la section 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Nous diffusons le modèle linguistique de l'Institut coréen d'information sur les brevets, via certaines procédures, aux organisations, entreprises et chercheurs qui s'y intéressent. Veuillez remplir le formulaire de candidature et l'accord selon la procédure de candidature ci-dessous et soumettre la candidature par e-mail à la personne responsable.
| nom de fichier | explication |
|---|---|
| pat_all_mecab_dic.csv | Dictionnaire utilisateur des brevets Mecab |
| lm_test_data.tsv | Ensemble de données d'échantillon de classification |
| korpat_tokenizer.py | Programme de tokenisation KorPat |
| test_tokenize.py | Exemple d'utilisation du tokenizer |
| test_tokenize.ipynb | Exemple d'utilisation de Tokenizer (Jupiter) |
| test_lm.py | Exemple d'utilisation du modèle de langage |
| test_lm.ipynb | Exemple d'utilisation du modèle de langage (Jupyter) |
| korpat_bert_config.json | Fichier de configuration KorPatBERT |
| korpat_vocab.txt | Fichiers de vocabulaire KorPatBERT |
| modèle.ckpt-381250.meta | Fichier modèle KorPatBERT |
| modèle.ckpt-381250.index | Fichier modèle KorPatBERT |
| modèle.ckpt-381250.data-00000-of-00001 | Fichier modèle KorPatBERT |


