SeekStorm
v0.11.0

SeekStorm est une bibliothèque de recherche en texte intégral open source inférieure à la milliseconde et un serveur multi-tenant implémenté dans Rust .
Développement commencé en 2015, en production depuis 2020, port Rust en 2023, open source en 2024, travail en cours.
SeekStorm est open source sous licence Apache License 2.0
Articles de blog : SeekStorm est désormais Open Source et SeekStorm obtient la recherche à facettes, la recherche de proximité géographique et le tri des résultats.
Types de requêtes
Types de résultats
Performance
Latence plus faible, débit plus élevé, coût et consommation d'énergie réduits, en particulier. pour les requêtes multi-champs et simultanées.
De faibles latences de queue garantissent une expérience utilisateur fluide et évitent la perte de clients et de revenus.
Alors que certains s'appuient sur des accélérateurs matériels propriétaires (FPGA/ASIC) ou des clusters pour améliorer les performances,
SeekStorm obtient une amélioration similaire de manière algorithmique sur un seul serveur de base.
Cohérence
Aucune latence de requête imprévisible pendant et après l'indexation de gros volumes, car SeekStorm ne nécessite pas de fusions de segments gourmandes en ressources.
Latences stables : pas de coûts de démarrage à froid dus à une compilation juste à temps, pas de retards imprévisibles dans le garbage collection.
Mise à l'échelle
Maintient une faible latence, un débit élevé et une faible consommation de RAM, même pour les index à l'échelle d'un milliard.
Numéro de champ, longueur de champ et taille d'index illimités.
Pertinence
Le classement de proximité des termes fournit des résultats plus pertinents que le BM25.
En temps réel
Véritable recherche en temps réel, par opposition à NRT : chaque document indexé est immédiatement consultable, même avant et pendant la validation.
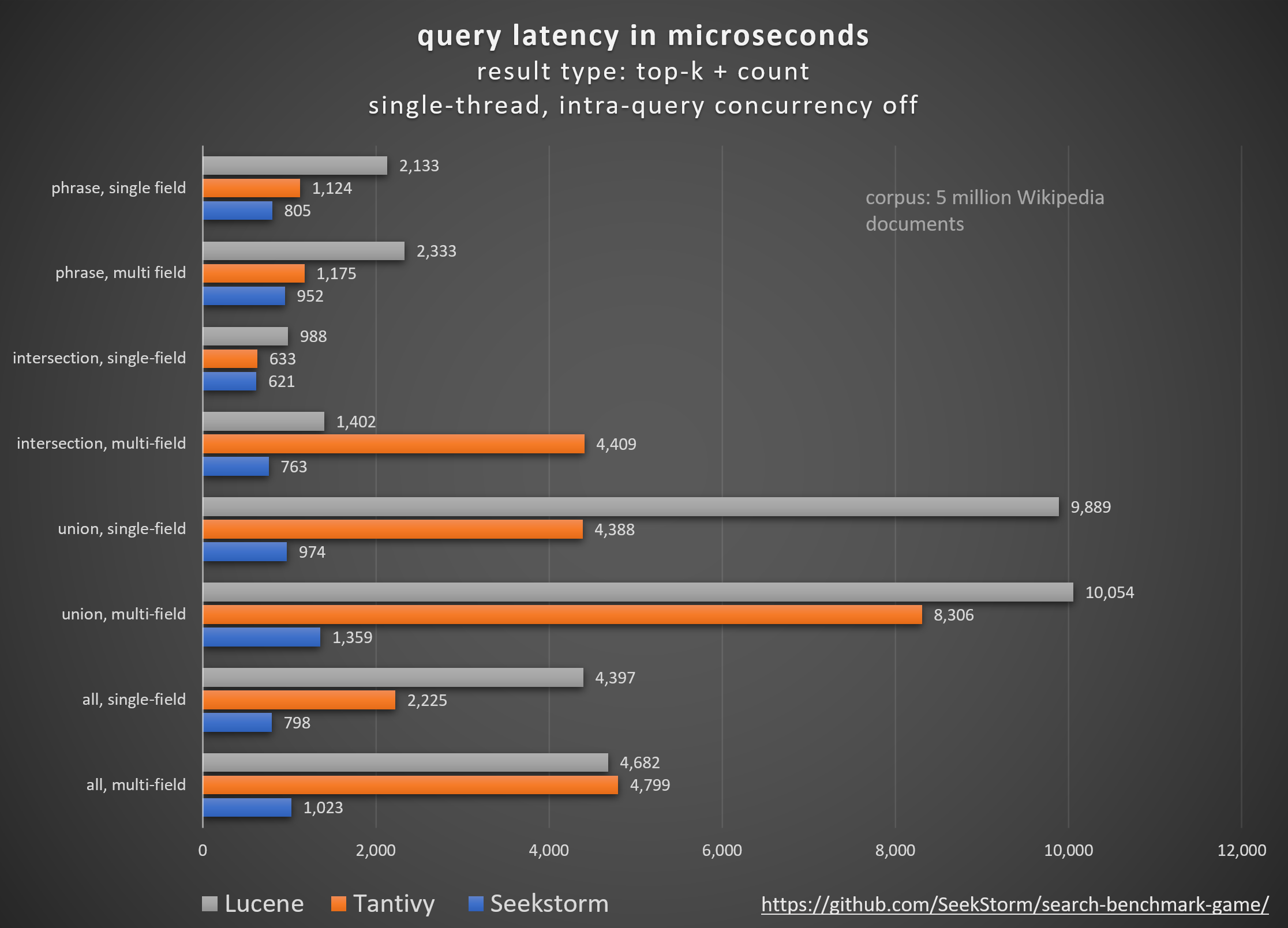
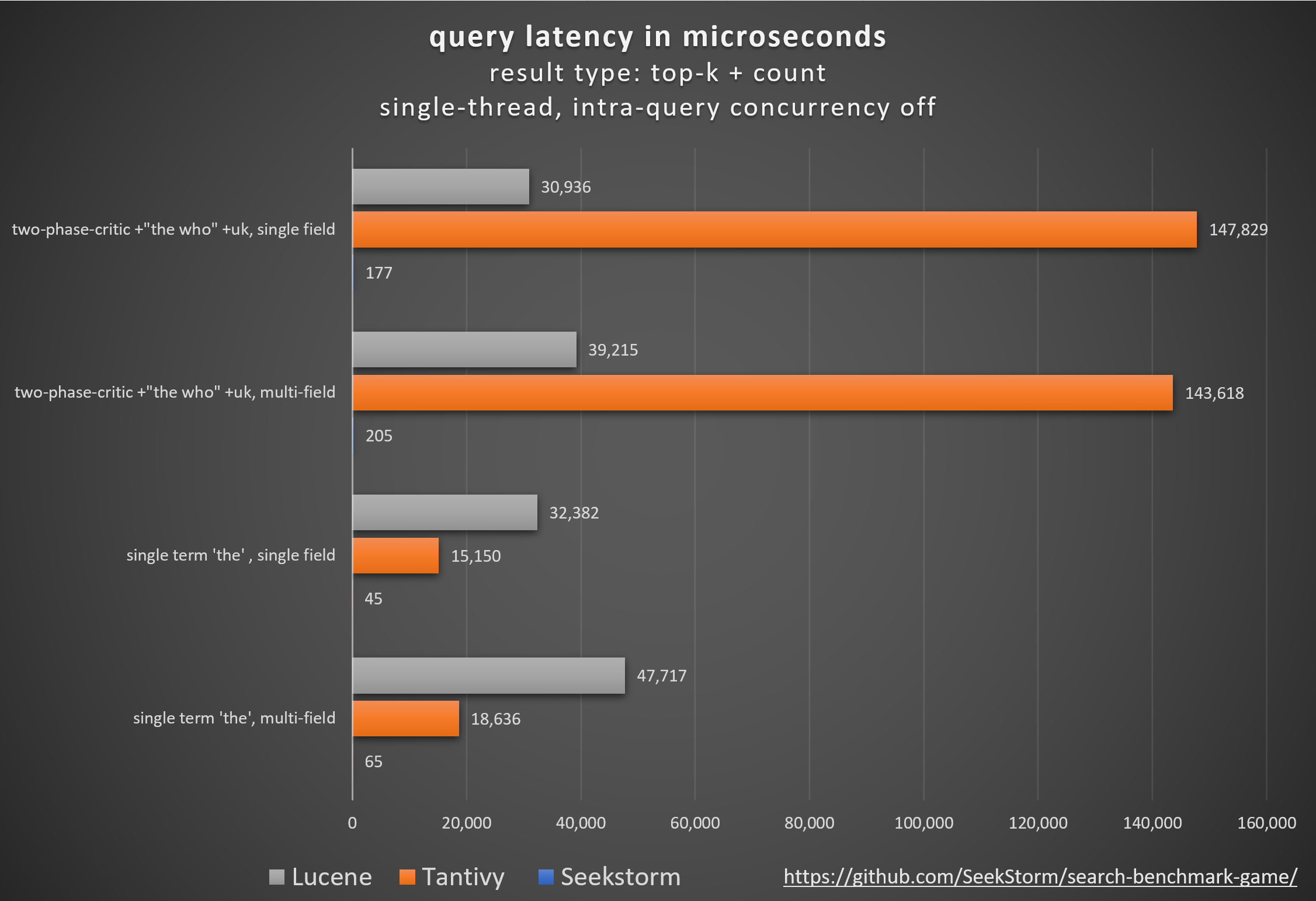
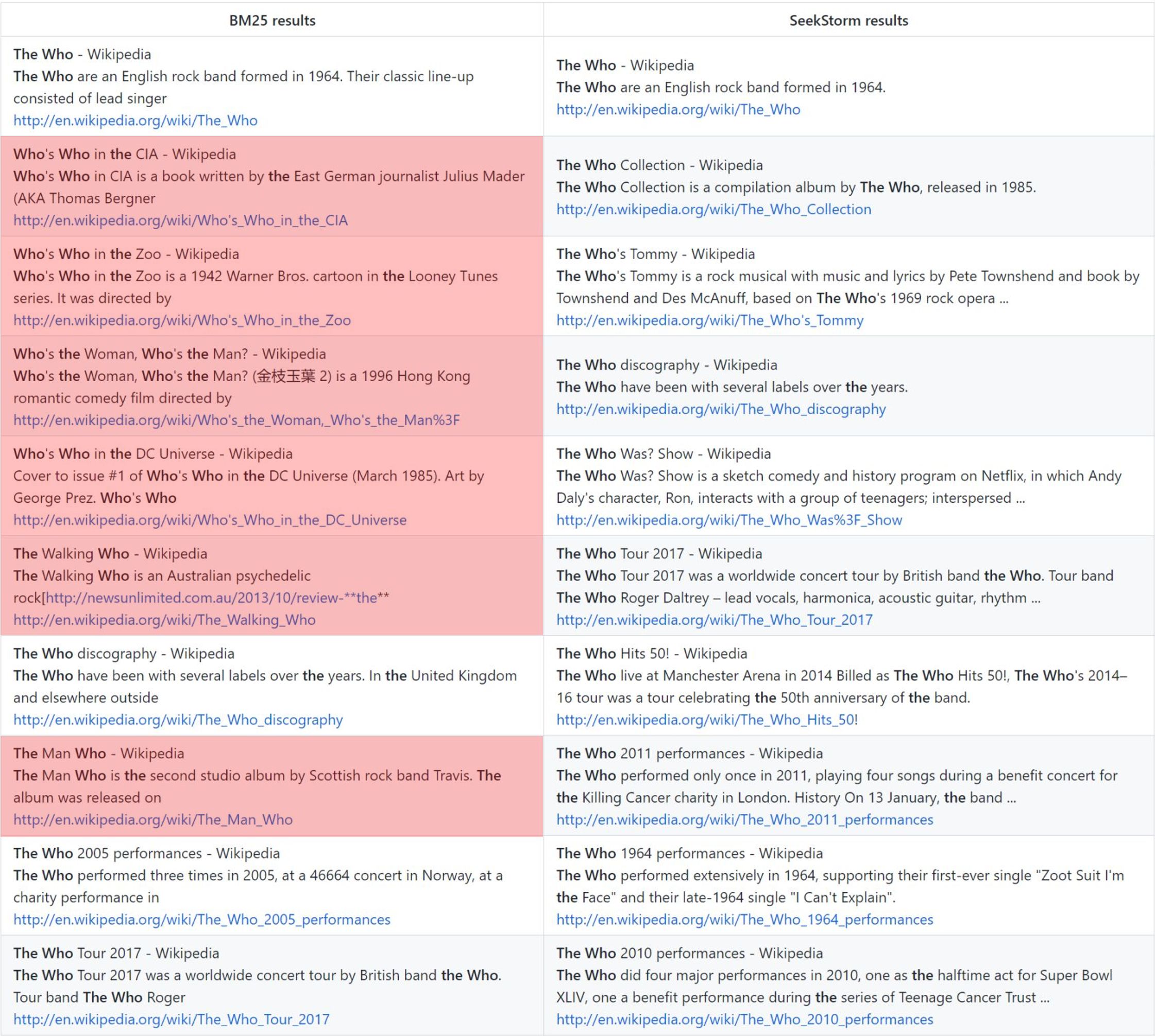
le qui : classement vanille BM25 vs classement de proximité SeekStorm
Méthodologie
Comparaison de différentes bibliothèques de moteurs de recherche open source (recherche lexicale BM25) à l'aide du search_benchmark_game open-source développé par Tantivy et Jason Wolfe.
Avantages
Résultats de référence détaillés https://seekstorm.github.io/search-benchmark-game/
Référentiel de code de référence https://github.com/SeekStorm/search-benchmark-game/
Consultez nos articles de blog pour des informations plus détaillées : SeekStorm est désormais Open Source et SeekStorm obtient la recherche à facettes, la recherche de proximité géographique et le tri des résultats.
Malgré ce que les cycles de battage médiatique https://www.bitecode.dev/p/hype-cycles veulent vous faire croire, la recherche par mot clé n'est pas morte, car NoSQL n'était pas la mort de SQL.
Vous devez conserver une boîte à outils et choisir le meilleur outil pour votre tâche à accomplir. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
La recherche par mot-clé n'est qu'un filtre pour un ensemble de documents, renvoyant ceux dans lesquels certains mots-clés apparaissent, généralement combinés avec une métrique de classement telle que BM25. Une fonctionnalité très basique et essentielle, très difficile à mettre en œuvre à grande échelle avec une faible latence. La fonctionnalité étant si basique, il existe un nombre illimité de champs d’application. C'est un composant à utiliser avec d'autres composants. Il existe des cas d'utilisation qui peuvent être mieux résolus aujourd'hui avec la recherche vectorielle et les LLM, mais pour beaucoup d'autres, la recherche par mot clé reste la meilleure solution. La recherche par mot clé est exacte, sans perte et très rapide, avec une meilleure mise à l'échelle, une meilleure latence, un coût et une consommation d'énergie réduits. La recherche de vecteurs fonctionne avec une similarité sémantique, renvoyant des résultats avec une proximité et une probabilité données.
Si vous recherchez des résultats exacts comme des noms propres, des numéros, des plaques d'immatriculation, des noms de domaine et des expressions (par exemple, détection de plagiat), alors la recherche par mot clé est votre amie. La recherche de vecteurs, en revanche, enterrera le résultat exact que vous recherchez parmi une myriade de résultats qui ne sont que d'une manière ou d'une autre liés sémantiquement. Dans le même temps, si vous ne connaissez pas les termes exacts ou si vous êtes intéressé par un sujet, une signification ou un synonyme plus large, quels que soient les termes exacts utilisés, la recherche par mot clé échouera.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.La recherche vectorielle est parfaite si vous ne connaissez pas les termes de requête exacts ou si vous êtes intéressé par un sujet, une signification ou un synonyme plus large, quels que soient les termes de requête exacts utilisés. Mais si vous recherchez des termes exacts, par exemple des noms propres, des numéros, des plaques d'immatriculation, des noms de domaine et des expressions (par exemple, détection de plagiat), vous devez toujours utiliser la recherche par mots clés. La recherche vectorielle ne fera qu’enterrer le résultat exact que vous recherchez parmi une myriade de résultats qui ne sont liés que d’une manière ou d’une autre. Il a un bon rappel, mais une faible précision et une latence plus élevée. Il est sujet aux faux positifs, par exemple lors de la détection de plagiat, car les mots exacts et l'ordre des mots sont perdus.
La recherche de vecteurs vous permet de rechercher non seulement du texte similaire, mais tout ce qui peut être transformé en vecteur : texte, images (reconnaissance faciale, empreintes digitales), audio et vous permet de faire des choses magiques comme reine - femme + homme = roi .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generationLa recherche vectorielle ne remplace pas la recherche par mot-clé, mais constitue un complément complémentaire . Il est préférable de l'utiliser dans le cadre d'une solution hybride où les atouts des deux approches sont combinés. La recherche par mot-clé n’est pas obsolète, mais a fait ses preuves .
Nous avons (partiellement) porté la base de code SeekStorm de C# vers Rust
Rust est idéal pour les applications critiques en termes de performances qui traitent du Big Data et/ou de nombreux utilisateurs simultanés. Les algorithmes rapides brilleront encore plus avec un langage de programmation soucieux des performances ?
voir ARCHITECTURE.md
cargo build --release
ATTENTION : assurez-vous de définir la variable d'environnement MASTER_KEY_SECRET sur un secret, sinon vos clés API générées seront compromises.
https://docs.rs/seekstorm
Construire la documentation
cargo doc --no-deps
Accéder à la documentation localement
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
Ajoutez les caisses requises à votre projet
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;utiliser un runtime Rust asynchrone
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {créer un index
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;ouvrir l'index (ou créer un index)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; indexer les documents
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; valider des documents
index_arc . commit ( ) . await ;index de recherche
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;afficher les résultats
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}recherche multithread
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}indexer le fichier JSON au format JSON, JSON délimité par une nouvelle ligne et JSON concaténé
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;indexer tous les fichiers PDF dans le répertoire et les sous-répertoires
ingest de la console) : [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;indexer le fichier PDF
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;indexer les octets du fichier PDF
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;obtenir les octets du fichier PDF
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;effacer l'index
index . clear_index ( ) ;supprimer l'index
index . delete_index ( ) ;fermer l'index
index . close_index ( ) ;chaîne de version de la bibliothèque seekstorm
let version= version ( ) ;
println ! ( "version {}" ,version ) ;Les facettes sont définies à 3 endroits différents :
Un exemple fonctionnel minimal d’indexation et de recherche à facettes ne nécessite que 60 lignes de code. Mais tout comprendre à partir de la seule documentation pourrait être fastidieux. C'est pourquoi nous fournissons ici un exemple de démarrage rapide :
Ajoutez les caisses requises à votre projet
cargo add seekstorm
cargo add tokio
cargo add serde_jsonAjouter des déclarations d'utilisation
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;utiliser un runtime Rust asynchrone
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {créer un index
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;indexer les documents
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; valider des documents
index_arc . commit ( ) . await ;index de recherche
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;afficher les résultats
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}afficher les facettes
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;fin de la fonction principale
Ok ( ( ) )
} Un didacticiel rapide, étape par étape, sur la façon de créer un moteur de recherche Wikipédia à partir d'un corpus Wikipédia à l'aide du serveur SeekStorm en 5 étapes simples.

Télécharger SeekStorm
Téléchargez SeekStorm depuis le référentiel GitHub
Décompressez dans le répertoire de votre choix, ouvrez dans le code Visual Studio.
ou bien
git clone https://github.com/SeekStorm/SeekStorm.git
Construire SeekStorm
Installez Rust (s'il n'est pas encore présent) : https://www.rust-lang.org/tools/install
Dans le terminal de Visual Studio Code tapez :
cargo build --release
Obtenir le corpus Wikipédia
Corpus Wikipédia anglais prétraité (5 032 105 documents, 8,28 Go décompressés). Bien que wiki-articles.json ait une extension .JSON, ce n'est pas un fichier JSON valide. Il s'agit d'un fichier texte, où chaque ligne contient un objet JSON avec les attributs url, title et body. Le format s'appelle ndjson ("Newline délimité JSON").
Télécharger le corpus Wikipédia
Décompressez le corpus Wikipédia.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
Déplacez le wiki-articles.json décompressé vers le répertoire de publication
Démarrer le serveur SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexage
Tapez « ingest » dans la ligne de commande du serveur SeekStorm en cours d'exécution :
ingest
Cela crée l'index de démonstration et indexe le fichier wikipedia local.
Commencez la recherche dans l'interface Web intégrée
Ouvrez l'interface utilisateur Web intégrée dans le navigateur : http://127.0.0.1
Entrez une requête dans le champ de recherche
Test des points de terminaison de l'API REST
Ouvrez src/seekstorm_server/test_api.rest dans VSC avec l'extension VSC "Rest client" pour exécuter des appels API et inspecter les réponses.
exemples de points de terminaison d'API interactifs
Définissez la « clé API individuelle » dans test_api.rest sur la clé API affichée dans la console du serveur lorsque vous avez tapé « index » ci-dessus.
Supprimer l'index de démonstration
Tapez « supprimer » dans la ligne de commande du serveur SeekStorm en cours d'exécution :
delete
Arrêter le serveur
Tapez « quitter » dans la ligne de commande du serveur SeekStorm en cours d'exécution.
quit
Personnalisation
Voulez-vous utiliser quelque chose de similaire pour votre propre projet ? Jetez un œil à la documentation sur l’ingestion et l’interface utilisateur Web.
Un didacticiel rapide étape par étape sur la façon de créer un moteur de recherche PDF à partir d'un répertoire contenant des fichiers PDF à l'aide du serveur SeekStorm.
Rendez tous vos articles scientifiques, ebooks, CV, rapports, contrats, documentations, manuels, lettres, relevés bancaires, factures, bons de livraison consultables - à la maison ou dans votre organisation.
Construire SeekStorm
Installez Rust (s'il n'est pas encore présent) : https://www.rust-lang.org/tools/install
Dans le terminal de Visual Studio Code tapez :
cargo build --release
Télécharger PDFium
Téléchargez et copiez la bibliothèque Pdfium dans le même dossier que seekstorm_server.exe : https://github.com/bblanchon/pdfium-binaries
Démarrer le serveur SeekStorm
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
Indexage
Choisissez un répertoire contenant les fichiers PDF que vous souhaitez indexer et rechercher, par exemple vos documents ou votre répertoire de téléchargement.
Tapez « ingest » dans la ligne de commande du serveur SeekStorm en cours d'exécution :
ingest C:UsersJohnDoeDownloads
Cela crée le pdf_index et indexe tous les fichiers PDF du répertoire spécifié, y compris les sous-répertoires.
Commencez la recherche dans l'interface Web intégrée
Ouvrez l'interface utilisateur Web intégrée dans le navigateur : http://127.0.0.1
Entrez une requête dans le champ de recherche
Supprimer l'index de démonstration
Tapez « supprimer » dans la ligne de commande du serveur SeekStorm en cours d'exécution :
delete
Arrêter le serveur
Tapez « quitter » dans la ligne de commande du serveur SeekStorm en cours d'exécution.
quit
Recherche en texte intégral 30 millions de messages Hacker News ET pages Web liées
DeepHN.org
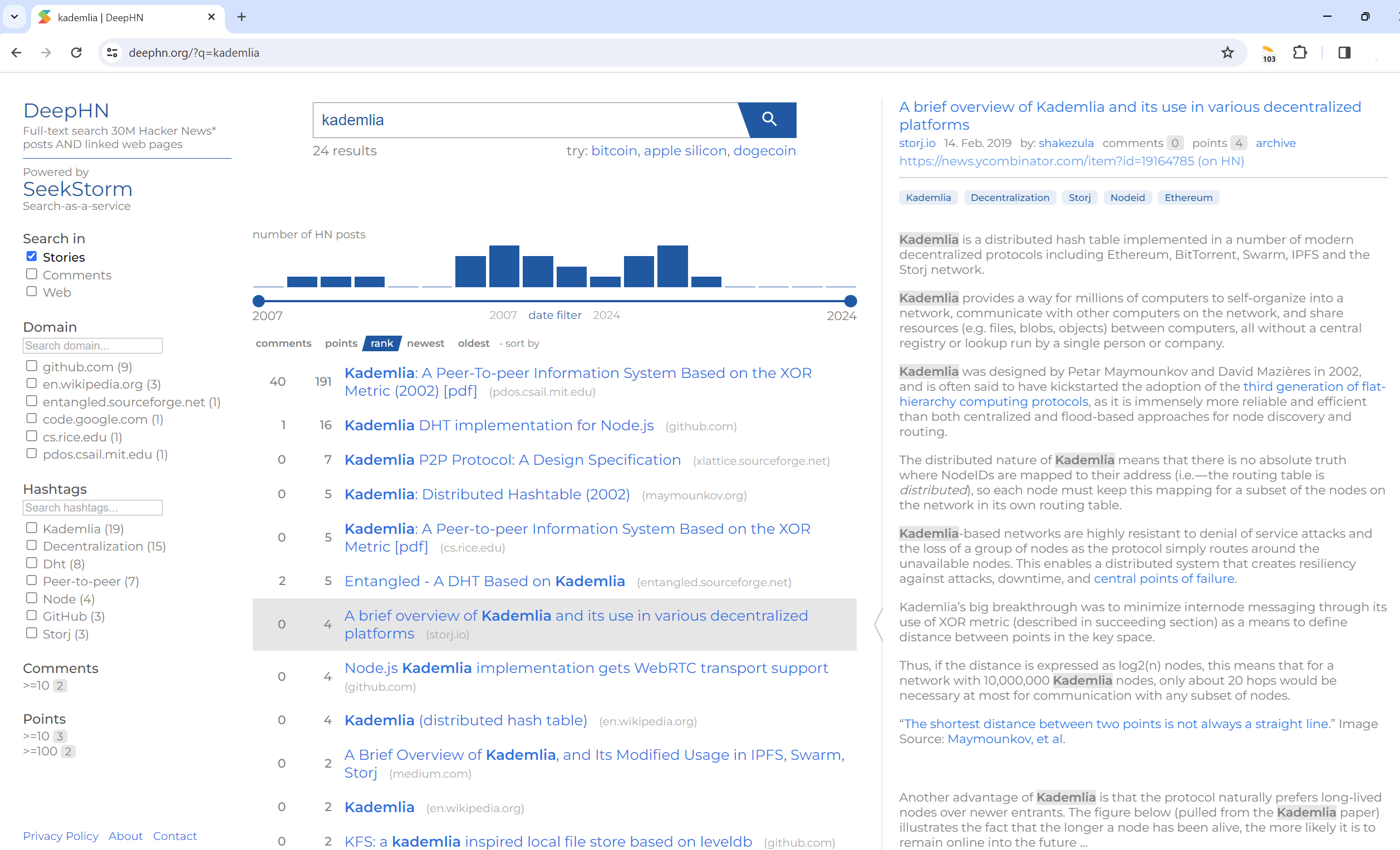
La démo DeepHN est toujours basée sur la base de code SeekStorm C#.
Nous portons actuellement toutes les fonctionnalités manquantes requises.
Voir la feuille de route ci-dessous.
Le portage Rust n’est pas encore complet. Les fonctionnalités suivantes sont actuellement portées.
Portage
Améliorations
Nouvelles fonctionnalités


