auctus
1.0.0
Ce projet est un robot d'exploration Web et un moteur de recherche d'ensembles de données, spécifiquement destiné aux tâches d'augmentation des données dans l'apprentissage automatique. Il est capable de rechercher des ensembles de données dans différents référentiels et de les indexer pour une récupération ultérieure.
La documentation est disponible ici
Il est divisé en plusieurs composantes :
datamart_geo . Celui-ci contient des données sur les zones administratives extraites de Wikidata et OpenStreetMap. Il vit dans son propre référentiel et est utilisé ici comme sous-module.datamart_profiler . Cela peut être installé par les clients et permettra à la bibliothèque cliente de profiler les ensembles de données localement au lieu de les envoyer au serveur. Il est également utilisé par les services apiserver et profileur.datamart_materialize . Ceci est utilisé pour matérialiser un ensemble de données provenant des différentes sources prises en charge par Auctus. Il peut être installé par les clients, ce qui leur permettra de matérialiser des jeux de données localement au lieu d'utiliser le serveur comme proxy.datamart_augmentation . Cela effectue la jointure ou l'union de deux ensembles de données et est utilisé par le service apiserver, mais pourrait éventuellement être utilisé de manière autonome.datamart_core . Celui-ci contient du code commun pour les services. Utilisé uniquement pour les composants du serveur. Le code de verrouillage du système de fichiers est séparé en tant que datamart_fslock pour des raisons de performances (doit être importé rapidement).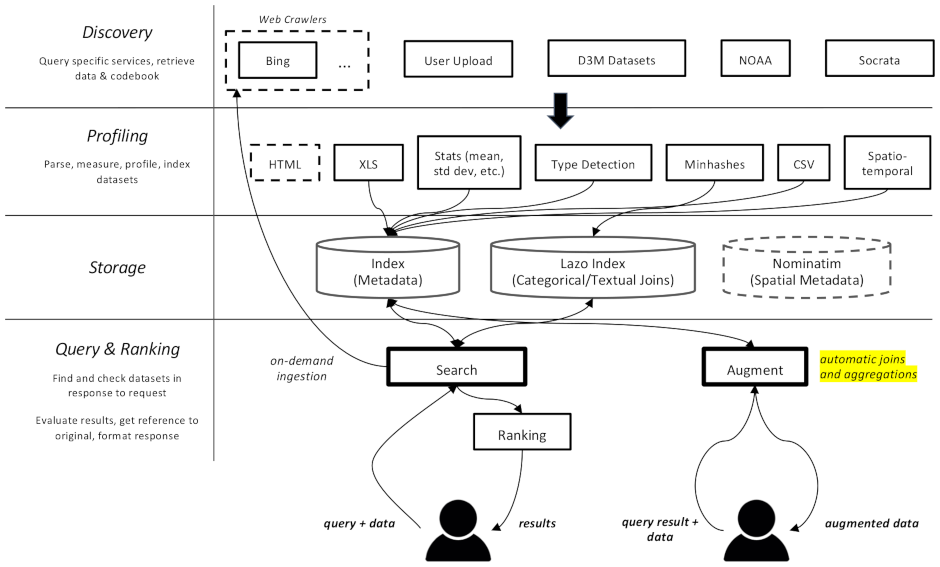
Elasticsearch est utilisé comme index de recherche, stockant un document par ensemble de données connu.
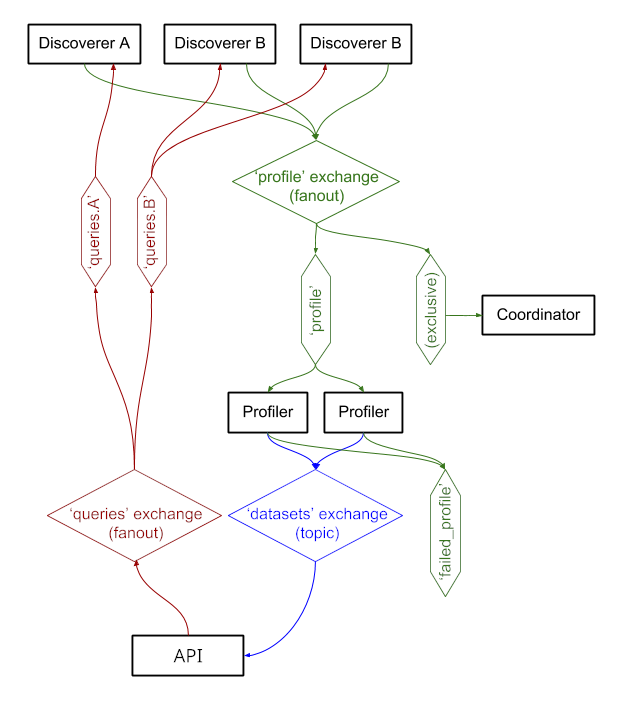
Les services échangent des messages via RabbitMQ , ce qui nous permet d'avoir des modèles de messagerie complexes avec une sémantique de mise en file d'attente et de nouvelle tentative, ainsi que des modèles complexes tels que les requêtes à la demande.
Le système fonctionne actuellement sur https://auctus.vida-nyu.org/. Vous pouvez voir l'état du système sur https://grafana.auctus.vida-nyu.org/.
Pour déployer le système localement à l'aide de docker-compose, suivez ces étapes :
Assurez-vous d'avoir extrait le sous-module avec git submodule init && git submodule update
Assurez-vous que Git LFS est installé et configuré ( git lfs install )
Copiez env.default dans .env et mettez-y à jour les variables. Vous souhaiterez peut-être mettre à jour le mot de passe pour un déploiement de production.
Assurez-vous que votre nœud est configuré pour exécuter Elasticsearch. Vous devrez probablement augmenter la limite mmap.
L' API_URL est l'URL à laquelle les conteneurs apiserver seront visibles pour les clients. Dans un déploiement de production, il s'agit probablement d'une URL HTTPS publique. Il peut s'agir de la même URL que celle à laquelle le composant « coordinateur » sera servi si vous utilisez un proxy inverse (voir nginx.conf).
Pour exécuter des scripts localement, vous pouvez charger les variables d'environnement dans votre shell en exécutant : . scripts/load_env.sh (c'est des scripts d'espace de points... )
Exécutez scripts/setup.sh pour initialiser les volumes de données. Cela définira les autorisations correctes sur les volumes/ sous-répertoires.
Si jamais vous souhaitez repartir de zéro, vous pouvez supprimer volumes/ mais assurez-vous de réexécuter scripts/setup.sh par la suite pour définir les autorisations.
$ docker-compose build --build-arg version=$(git describe) apiserver
$ docker-compose up -d elasticsearch rabbitmq redis minio lazo
Ceux-ci prendront quelques secondes pour être opérationnels. Ensuite, vous pouvez démarrer les autres composants :
$ docker-compose up -d cache-cleaner coordinator profiler apiserver apilb frontend
Vous pouvez utiliser l'option --scale pour démarrer davantage de conteneurs de profileur ou de serveur d'API, par exemple :
$ docker-compose up -d --scale profiler=4 --scale apiserver=8 cache-cleaner coordinator profiler apiserver apilb frontend
Port :
$ scripts/docker_import_snapshot.sh
Cela téléchargera un dump Elasticsearch depuis auctus.vida-nyu.org et l'importera dans votre conteneur Elasticsearch local.
$ docker-compose up -d socrata zenodo
$ docker-compose up -d elasticsearch_exporter prometheus grafana
Prometheus est configuré pour trouver automatiquement les conteneurs (voir prometheus.yml)
Une image RabbitMQ personnalisée est utilisée, avec des plugins ajoutés (gestion et prometheus).


