cape webservices
1.0.0
Point d'entrée pour tous les services Web backend Cape.
La démo Frontend est ici (ne fonctionne que si vous avez déjà lancé un Backend).
Cape est une suite de bibliothèques open source permettant de gérer un modèle de questions-réponses qui répond aux questions en « lisant » automatiquement les documents. Il est basé sur des modèles de lecture automatique de pointe entraînés sur des ensembles de données massifs et comprend plusieurs mécanismes pour le rendre facile à utiliser et à améliorer en fonction des commentaires des utilisateurs. Il a été conçu pour être portable , c'est-à-dire qu'il fonctionne sur un seul ordinateur portable ou sur un cluster de machines parallèles pour accélérer le calcul, et est compatible Open Source pour être utilisé à tous les niveaux d'expertise.
Il permet aux utilisateurs de
Il existe plusieurs façons d’utiliser Cape :
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/capeNous recommandons au moins 3 Go de RAM et au moins 2 cœurs de processeur modernes (4 si virtuels). Si vous utilisez Docker, assurez-vous d'augmenter les limites de ressources mémoire dans les préférences de Docker.
Vous pouvez exécuter une version autonome de l'application Web qui inclut un tableau de bord de gestion. Après avoir installé Docker, mettez à jour et exécutez l'image Cape :
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
Cela lancera à la fois les services Web backend et frontend. Par défaut, cela créera également des tunnels pour les deux, affichant les URL publiques :
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","timeout":"15000"}} Extrayez la dernière version de l'image Docker (le téléchargement de toutes les dépendances et d'un modèle de lecture automatique prendra quelques instants) : docker pull bloomsburyai/cape
Exécutez le conteneur Docker et lancez une console IPython à l'intérieur à l'aide de la commande suivante : docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
Importer le répondeur : from cape_responder.responder_core import Responder
Posez une question, stockez la réponse (qui est une liste de réponses) et affichez la première réponse en utilisant : response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
Si vous souhaitez comprendre un peu plus à quoi ressemble la réponse, affichez la réponse complète en utilisant : print(response)
Pour installer nativement Cape sur un système Linux, jetez un œil à déploiement/Dockerfile.
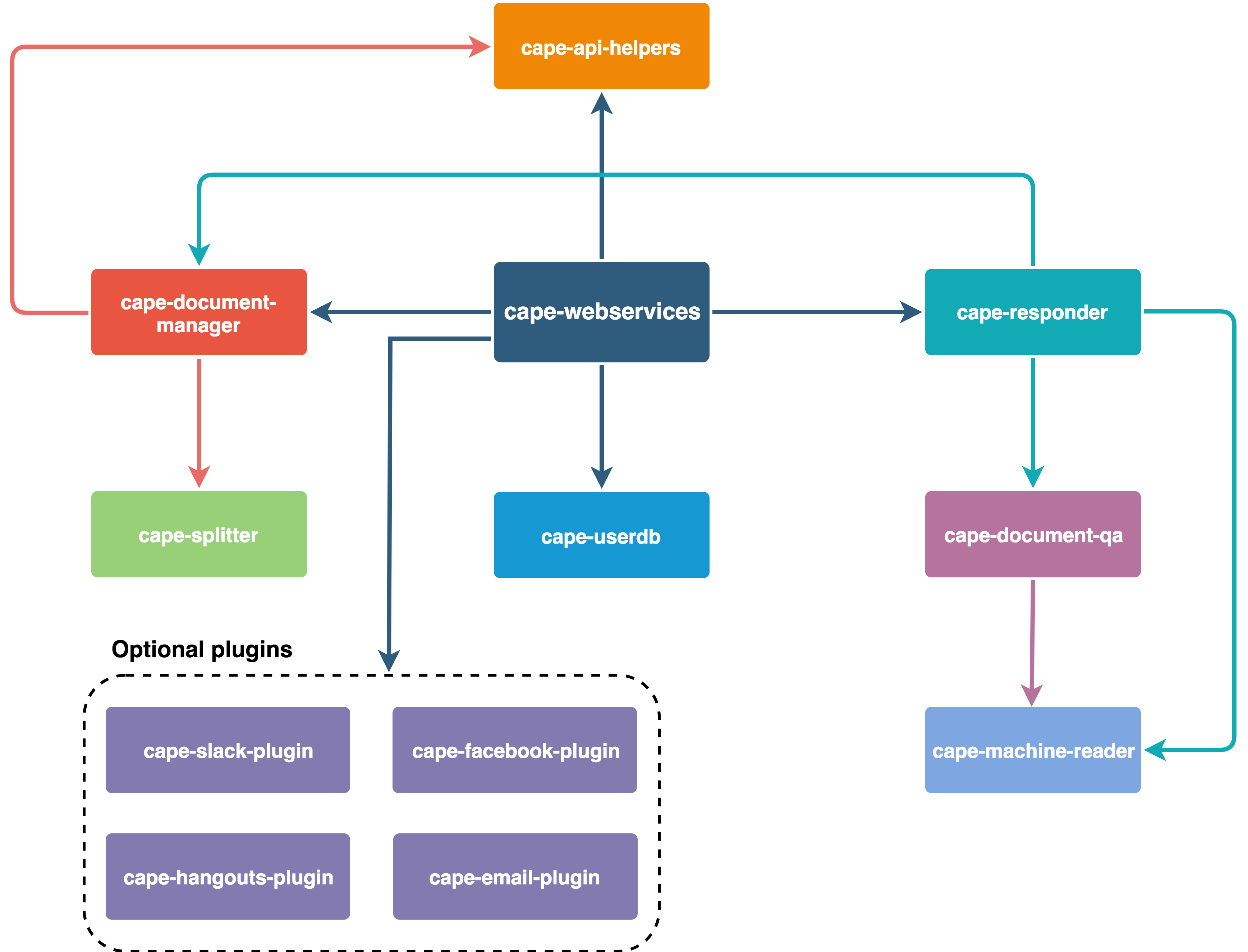
En résumé, voici comment Cape est organisé :


