VSA
1.0.0
[Page du projet] [?Papier] [?Hugging Face Space] [Model Zoo] [Introduction] [?Vidéo]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
La démo locale est basée sur gradio, et vous pouvez simplement l'exécuter avec :
python app.py
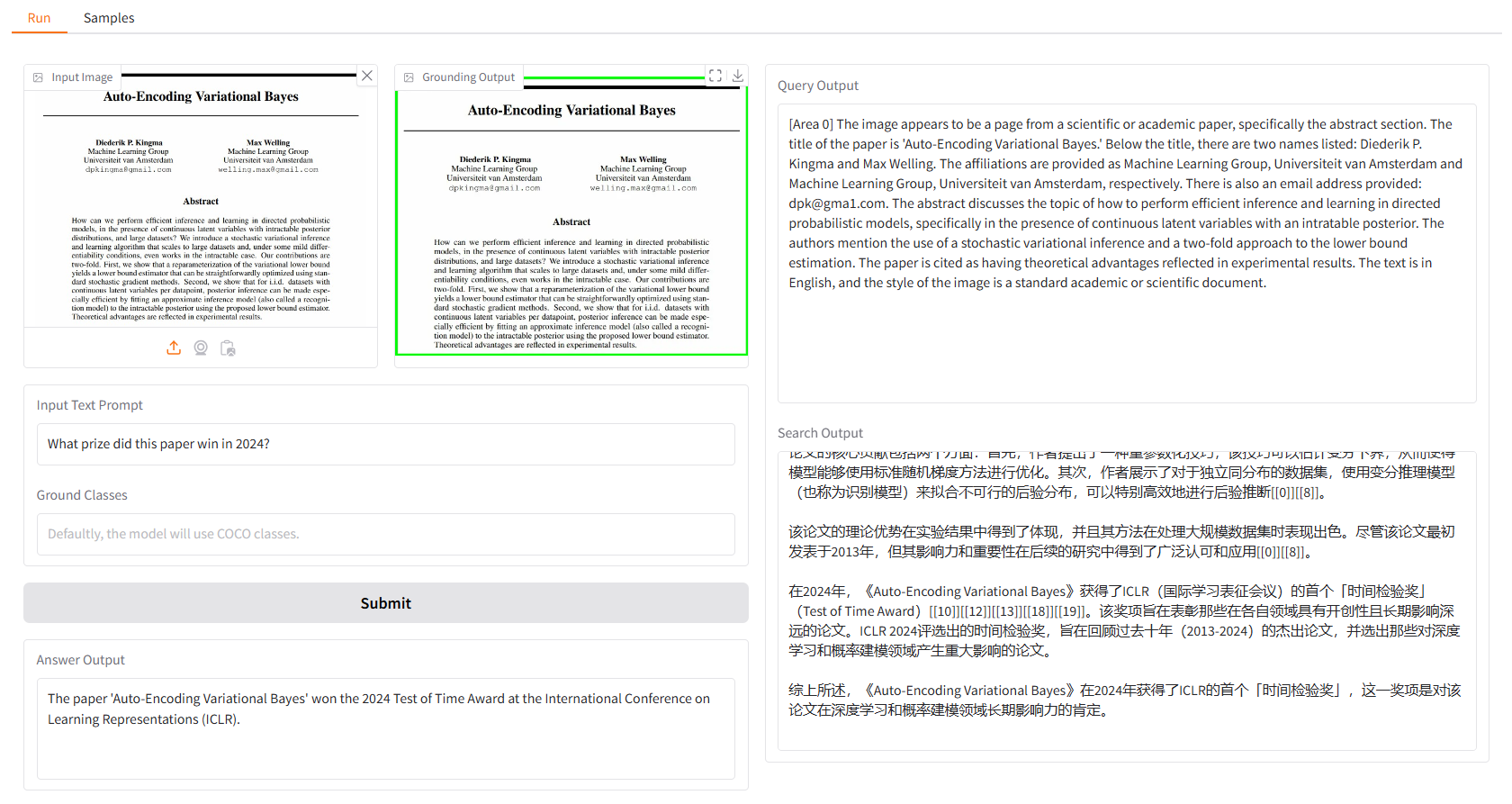
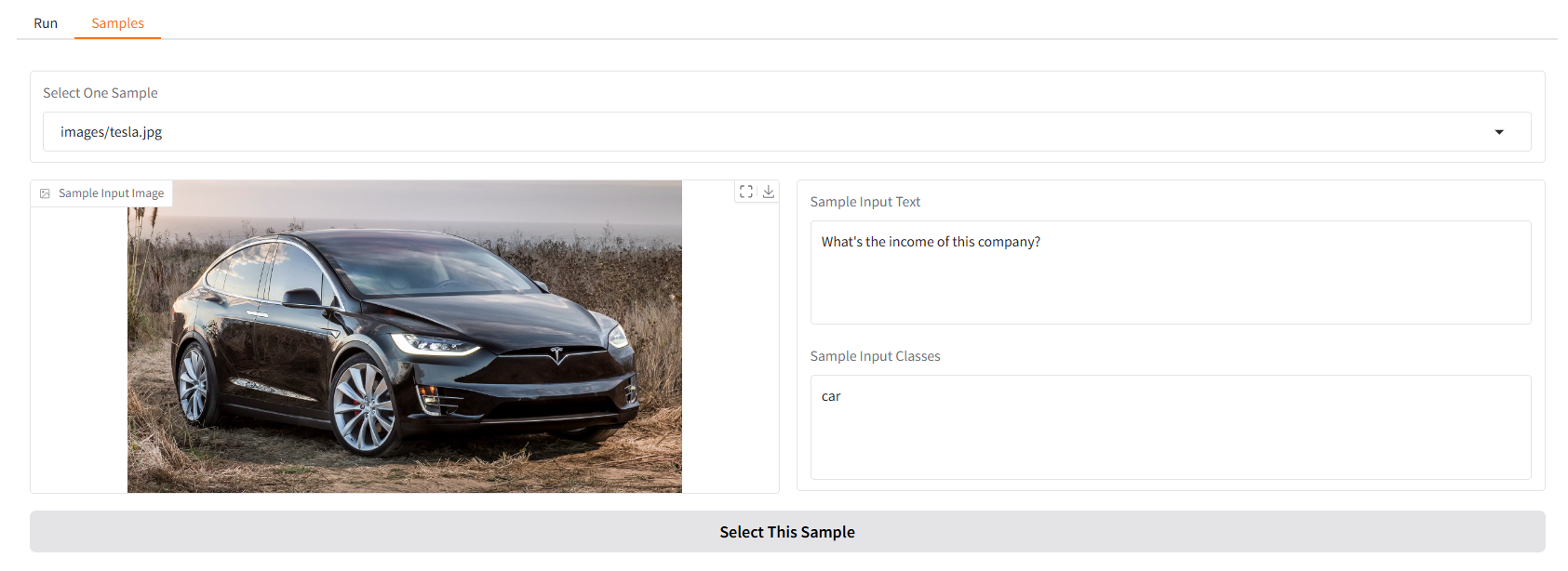
Nous vous fournissons quelques échantillons pour commencer. Dans l'interface utilisateur « Échantillons », vous pouvez en sélectionner un dans le panneau « Échantillons », cliquer sur « Sélectionner cet échantillon » et vous constaterez que l'échantillon d'entrée a déjà été renseigné dans l'interface utilisateur « Exécuter ».
Vous pouvez également discuter avec notre Vision Search Assistant dans le terminal en exécutant.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
Ensuite, sélectionnez une image et saisissez votre question.
Ce projet est publié sous la licence Apache 2.0.
Vision Search Assistant s'inspire grandement des contributions exceptionnelles suivantes à la communauté open source : GroundingDINO, LLaVA, MindSearch.
Si vous trouvez ce projet utile dans votre recherche, pensez à citer :
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


