cyac
1.0.0
Outil de recherche et de correspondance de mots clés haute performance.
Il est implémenté par cython et sera compilé en cpp. La structure de données du trie est en cèdre, qui est un trie à double tableau optimisé. il prend en charge Python2.7 et 3.4+. Il prend en charge le vidage et le chargement des cornichons.
Si vous avez trouvé cela utile, donnez une étoile !
Ce module est écrit en cython. Vous devez installer Cython.
pip install cyac
Créez ensuite un Trie
>>> from cyac import Trie
>>> trie = Trie()
ajouter/obtenir/supprimer un mot clé
>>> trie.insert(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.get(u"哈哈") # return keyword id in trie, return -1 if doesn't exist
>>> trie.remove(u"呵呵") # return keyword in trie
>>> trie[id] # return the word corresponding to the id
>>> trie[u"呵呵"] # similar to get but it will raise exeption if doesn't exist
>>> u"呵呵" in trie # test if the keyword is in trie
obtenir tous les mots-clés
>>> for key, id_ in trie.items():
>>> print(key, id_)
préfixe/prédire
>>> # return the string in the trie which starts with given string
>>> for id_ in trie.predict(u"呵呵"):
>>> print(id_)
>>> # return the prefix of given string which is in the trie.
>>> for id_, len_ in trie.prefix(u"呵呵"):
>>> print(id_, len_)
trie extraire, remplacer
>>> python_id = trie.insert(u"python")
>>> trie.replace_longest("python", {python_id: u"hahah"}, set([ord(" ")])) # the second parameter is seperator. If you specify seperators. it only matches strings tween seperators. e.g. It won't match 'apython'
>>> for id_, start, end in trie.match_longest(u"python", set([ord(" ")])):
>>> print(id_, start, end)
Extrait d'Aho Corasick
>>> ac = AC.build([u"python", u"ruby"])
>>> for id, start, end in ac.match(u"python ruby"):
>>> print(id, start, end)
Exportez vers un fichier, nous pouvons ensuite utiliser mmap pour charger un fichier et partager des données entre les processus.
>>> ac = AC.build([u"python", u"ruby"])
>>> ac.save("filename")
>>> ac.to_buff(buff_object)
Initier à partir du tampon Python
>>> import mmap
>>> with open("filename", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
>>> AC.from_buff(buff_object, copy=True) # it allocs new memory
>>> AC.from_buff(buff_object, copy=False) # it shares memory
Exemple multi-processus
import mmap
from multiprocessing import Process
from cyac import AC
def get_mmap():
with open("random_data", "r+b") as bf:
buff_object = mmap.mmap(bf.fileno(), 0)
ac_trie = AC.from_buff(buff_object, copy=False)
# Do your aho searches here. "match" function is process safe.
processes_list = list()
for x in range(0, 6):
p = Process(
target=get_mmap,
)
p.start()
processes_list.append(p)
for p in processes_list:
p.join()
Pour plus d'informations sur le multitraitement et l'analyse de la mémoire dans cyac, consultez ce numéro.
La fonction "match" de l'automate AC est thread/process safe. Il est possible de trouver des correspondances en parallèle avec un automate AC partagé, mais pas d'y écrire/y ajouter des modèles.
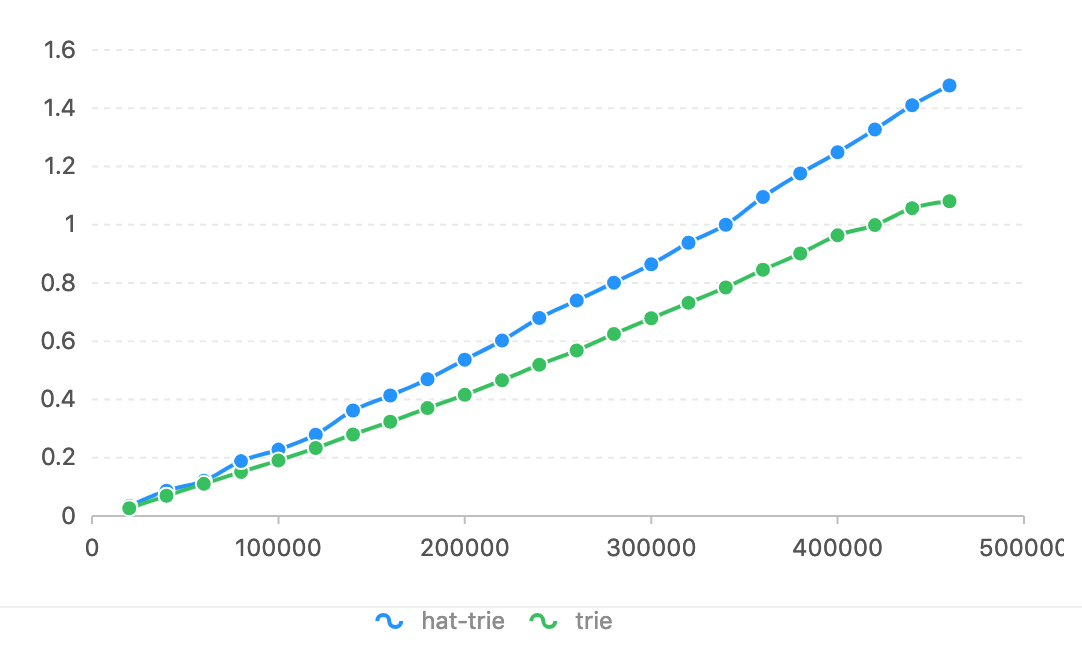
Sur Ubuntu 14.04.5/Intel(R) Core(TM) i7-4790K CPU à 4,00 GHz.
Par rapport à HatTrie, l'axe Horizon est le numéro de jeton. L'axe vertical est le temps utilisé (secondes).
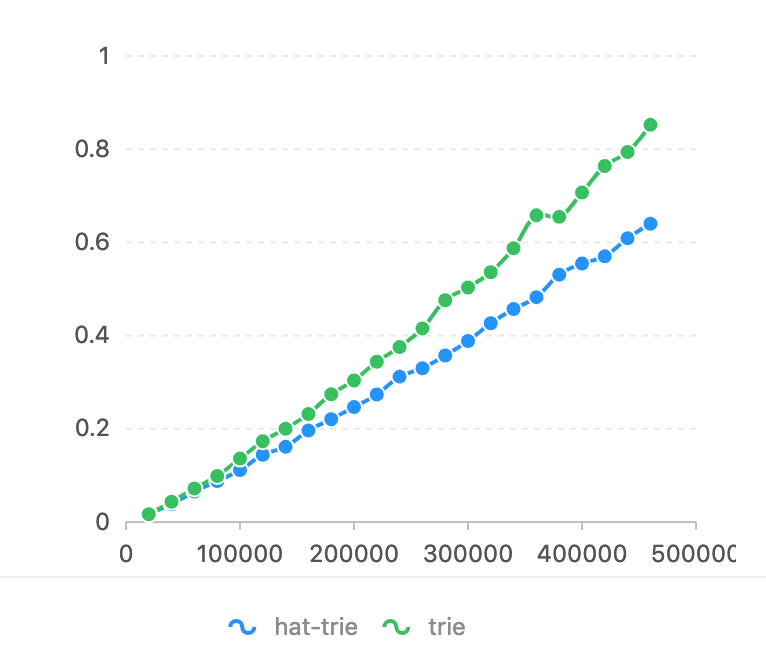
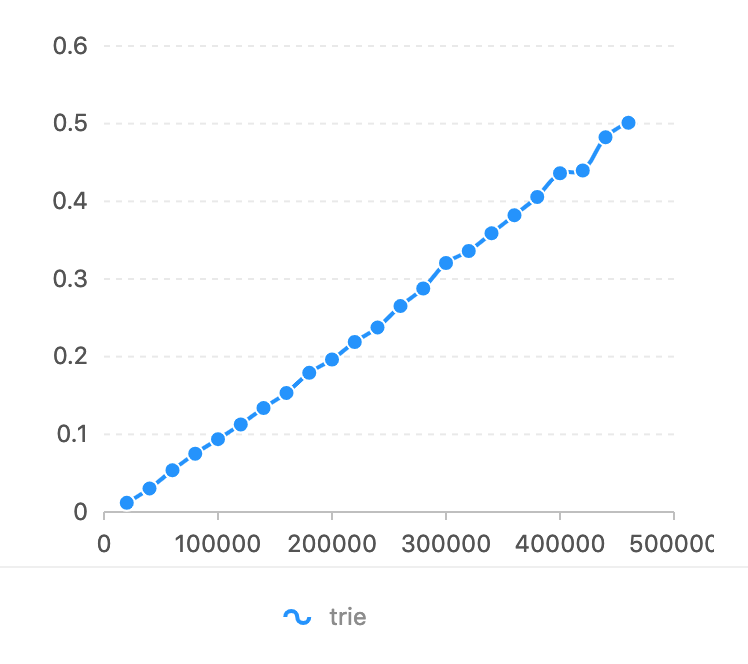
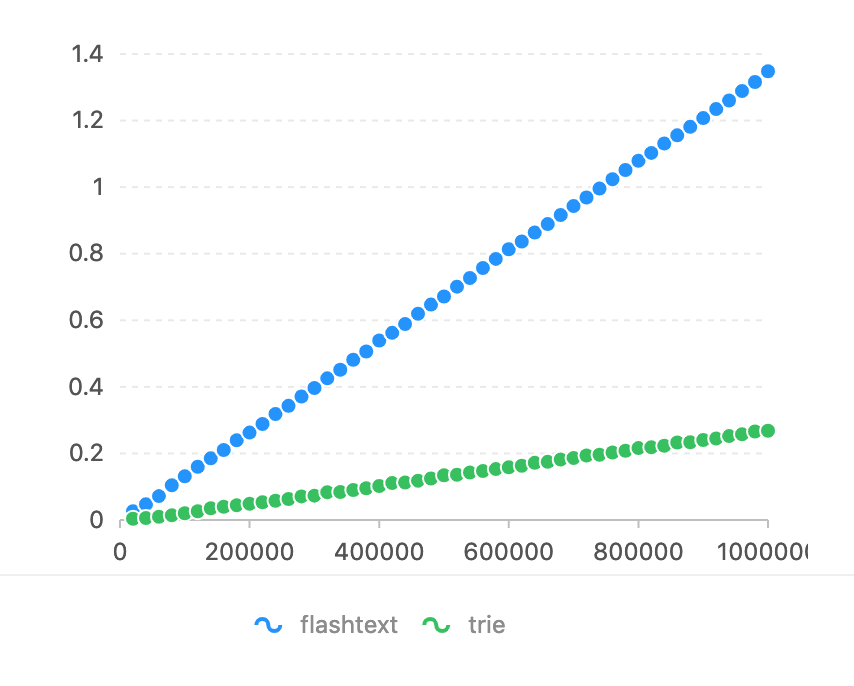
Par rapport à flashText. L'expression régulière est trop lente dans cette tâche (voir le benchmark de flashText). L'axe d'horizon est le numéro de caractère qui doit correspondre. L'axe vertical est le temps utilisé (secondes).
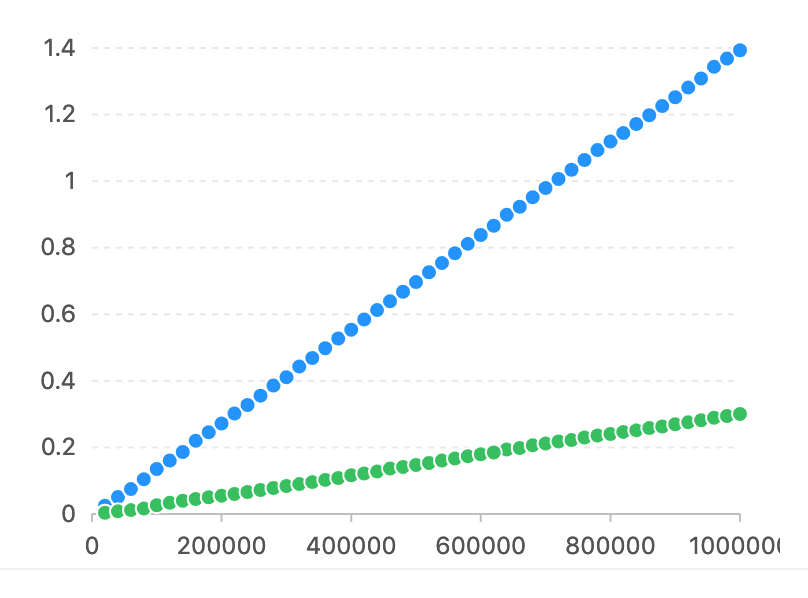
Comparé à pyahocorasick, l'axe Horizon est le numéro de char qui doit correspondre. L'axe vertical est le temps utilisé (secondes).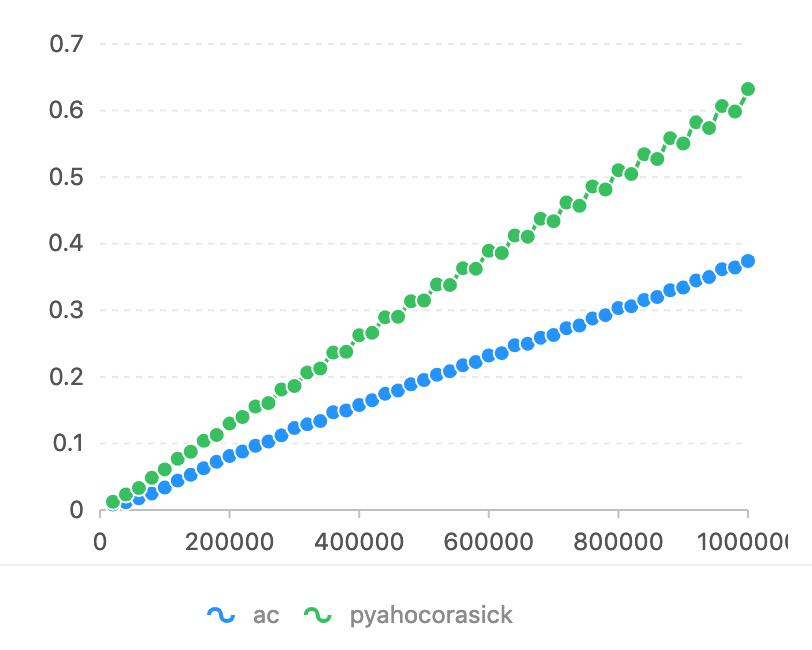
>>> len(char.lower()) == len(char) # this is always true in python2, but not in python3
>>> len(u"İstanbul") != len(u"İstanbul".lower()) # in python3
En cas de correspondance insensible, cette bibliothèque s'en occupe et renvoie le décalage correct.
python setup.py build
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 tests/test_all.py
PYTHONPATH= $( pwd ) /build/BUILD_DST python3 bench/bench_ * .py

