amazon sagemaker clip search
1.0.0
Ce référentiel vise à créer un prototype de moteur de recherche alimenté par l'apprentissage automatique (ML) pour récupérer et recommander des produits basés sur des requêtes de texte ou d'images. Il s'agit d'un guide étape par étape expliquant comment créer des modèles SageMaker avec un pré-entraînement contrastif en langage-image (CLIP), utiliser les modèles pour encoder des images et du texte dans des intégrations, ingérer des intégrations dans l'index Amazon OpenSearch Service et interroger l'index. en utilisant la fonctionnalité KNN (K-Nearest Neighbours) d'OpenSearch Service.
La récupération basée sur l'intégration (EBR) est bien utilisée dans les systèmes de recherche et de recommandation. Il utilise des algorithmes de recherche du voisin le plus proche (approximatif) pour trouver des éléments similaires ou étroitement liés à partir d'un magasin d'intégration (également connu sous le nom de base de données vectorielles). Les mécanismes de recherche classiques dépendent fortement de la correspondance de mots-clés et ignorent la signification lexicale ou le contexte de la requête. L'objectif d'EBR est de fournir aux utilisateurs la possibilité de trouver les produits les plus pertinents en utilisant du texte libre. Il est populaire car, comparé à la correspondance de mots clés, il exploite des concepts sémantiques dans le processus de récupération.
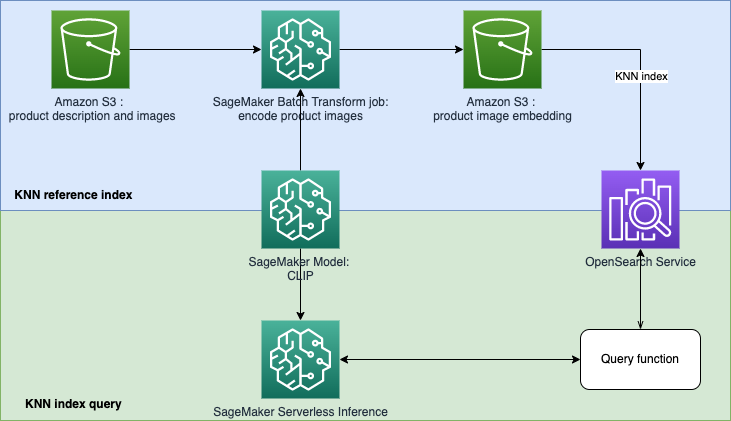
Dans ce référentiel, nous nous concentrons sur la création d'un prototype de moteur de recherche alimenté par l'apprentissage automatique (ML) pour récupérer et recommander des produits basés sur des requêtes de texte ou d'images. Cela utilise Amazon OpenSearch Service et sa fonctionnalité k-plus proches voisins (KNN), ainsi qu'Amazon SageMaker et sa fonctionnalité d'inférence sans serveur. Amazon SageMaker est un service entièrement géré qui offre à chaque développeur et data scientist la possibilité de créer, former et déployer des modèles ML pour n'importe quel cas d'utilisation avec une infrastructure, des outils et des flux de travail entièrement gérés. Amazon OpenSearch Service est un service entièrement géré qui facilite l'analyse interactive des journaux, la surveillance des applications en temps réel, la recherche sur des sites Web, etc.
Le Contrastive Language-Image Pre-Training (CLIP) est un réseau neuronal formé sur une variété de paires d'images et de texte. Le ou les réseaux neuronaux CLIP sont capables de projeter à la fois des images et du texte dans le même espace latent, ce qui signifie qu'ils peuvent être comparés à l'aide d'une mesure de similarité, telle que la similarité cosinus. Vous pouvez utiliser CLIP pour encoder les images ou la description de vos produits dans des intégrations, puis les stocker dans une base de données vectorielle. Vos clients peuvent ensuite effectuer des requêtes dans la base de données pour récupérer les produits susceptibles de les intéresser. Pour interroger la base de données, vos clients doivent fournir des images ou du texte d'entrée, puis l'entrée sera codée avec CLIP avant d'être envoyée à la base de données vectorielle pour la recherche KNN.
La base de données vectorielles joue ici le rôle de moteur de recherche. Cette base de données vectorielles prend en charge la recherche unifiée d'images et de texte, ce qui est particulièrement utile dans les secteurs du commerce électronique et de la vente au détail. Un exemple de recherche basée sur l'image est que vos clients peuvent rechercher un produit en prenant une photo, puis interroger la base de données à l'aide de l'image. Concernant la recherche textuelle, vos clients peuvent décrire un produit sous forme de texte libre, puis utiliser le texte comme requête. Les résultats de la recherche seront triés selon un score de similarité (similarité cosinus), si un élément de votre inventaire est plus similaire à la requête (une image ou un texte saisi), le score sera plus proche de 1, sinon le score sera plus proche de 0. Les K premiers produits de vos résultats de recherche sont les produits les plus pertinents de votre inventaire.
OpenSearch Service fournit une correspondance de texte et une recherche basée sur KNN intégrée. Nous utiliserons l'intégration de la recherche basée sur KNN dans cette solution. Vous pouvez utiliser à la fois une image et du texte comme requête pour rechercher des éléments dans l'inventaire. La mise en œuvre de cette application de recherche unifiée d'images et de tests basée sur KNN comprend deux phases :
La solution utilise les services et fonctionnalités AWS suivants :
Dans le modèle opensearch.yml , il créera un domaine OpenSearch et accordera à votre rôle d'exécution SageMaker Studio l'utilisation du domaine.
Dans le modèle sagemaker-studio-opensearch.yml , il créera un nouveau domaine SageMaker, un profil utilisateur dans le domaine et un domaine OpenSearch. Vous pouvez donc utiliser le profil utilisateur StageMaker pour construire ce POC.
Vous pouvez choisir l'un des modèles à exécuter en suivant les étapes répertoriées ci-dessous.
Étape 1 : Accédez à CloudFormation Service dans votre console AWS. 
Étape 2 : Téléchargez un modèle pour créer une pile CloudFormation clip-poc-stack .
Si vous disposez déjà d'un SageMaker Studio en cours d'exécution, vous pouvez utiliser le modèle opensearch.yml . 
Si vous n'avez pas de SageMaker Studio pour le moment, vous pouvez utiliser le modèle sagemaker-studio-opensearch.yml . Il créera un domaine Studio et un profil utilisateur pour vous.
Étape 3 : Vérifiez l'état de la pile CloudFormation. Il faudra environ 20 minutes pour terminer la création. 
Une fois la pile créée, vous pouvez accéder à la console SageMaker et cliquer sur Open Studio pour accéder à l'environnement Jupyter. 
Si pendant l'exécution, CloudFormation affiche des erreurs concernant le rôle lié au service OpenSearch, elles sont introuvables. Vous devez créer un rôle lié à un service en exécutant aws iam create-service-linked-role --aws-service-name es.amazonaws.com dans votre compte AWS.
Veuillez ouvrir le fichier blog_clip.ipynb avec SageMaker Studio et utiliser le noyau Data Science Python 3 . Vous pouvez exécuter des cellules depuis le début.
L'ensemble de données d'objets Amazon Berkeley est utilisé dans l'implémentation. L'ensemble de données est une collection de 147 702 listes de produits avec des métadonnées multilingues et 398 212 images de catalogue uniques. Nous utiliserons uniquement les images et les noms des articles en anglais américain. À des fins de démonstration, nous allons utiliser environ 1 600 produits.
Cette section décrit les considérations financières liées à l'exécution de cette démo. La réalisation du POC permettra de déployer un cluster OpenSearch et un studio SageMaker qui coûteront moins de 2 $ de l'heure. Remarque : le prix indiqué ci-dessous est calculé en utilisant la région us-east-1. Le coût varie d'une région à l'autre. Et le coût peut également changer avec le temps (le prix ici est enregistré le 2022-11-22).
D’autres ventilations des coûts sont présentées ci-dessous.
Service OpenSearch – Les prix varient en fonction de l'utilisation du type d'instance et du coût du stockage. Pour plus d'informations, consultez la tarification d'Amazon OpenSearch Service.
t3.small.search s'exécute pendant environ 1 heure à 0,036 $ par heure.SageMaker – Les prix varient en fonction de l'utilisation de l'instance EC2 pour les applications Studio, les tâches de transformation par lots et les points de terminaison d'inférence sans serveur. Pour plus d'informations, consultez Tarification Amazon SageMaker.
ml.t3.medium pour Studio Notebooks fonctionne pendant environ 1 heure à 0,05 $ par heure.ml.c5.xlarge pour Batch Transform s'exécute pendant environ 6 minutes à 0,204 $ par heure.S3 – Faible coût, les prix varient en fonction de la taille des modèles/artefacts stockés. Les 50 premiers To chaque mois ne coûteront que 0,023 $ par Go stocké. Pour plus d'informations, consultez Tarification Amazon S3.
Voir CONTRIBUTION pour plus d'informations.
Cette bibliothèque est sous licence MIT-0. Voir le fichier LICENCE.


