ndvr
1.0.0
2e rang pour le Neural Search Hackathon ?
Nous avons assisté à une croissance explosive des données vidéo sur une variété de sites Web de partage de vidéos, avec des milliards de vidéos disponibles sur Internet. Il devient donc un défi majeur d'effectuer une récupération vidéo quasi-dupliquée (NDVR) à partir d'une base de données vidéo à grande échelle. NDVR vise à récupérer les vidéos quasi-dupliquées à partir d'une base de données vidéo massive, où les vidéos quasi-dupliquées sont définies comme des vidéos visuellement proches des vidéos originales.
Les utilisateurs sont fortement incités à copier une courte vidéo tendance et à télécharger une version augmentée pour attirer l'attention. Avec la croissance des vidéos courtes, de nouvelles difficultés et défis pour détecter les vidéos courtes quasi-dupliquées apparaissent.
Ici, nous avons construit une solution de recherche neuronale utilisant Jina pour résoudre le défi du NDVR.
Table des matières

Exemple de vidéos de candidats très positifs. Rangée supérieure : côté morroré, filtré en couleur et lavé à l'eau. Rangée du milieu : écran horizontal remplacé par écran vertical avec de grandes marges noires. Rangée du bas : pivotée
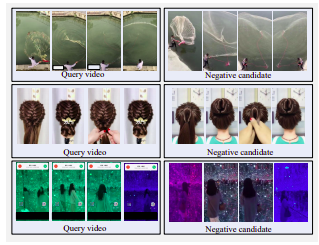
Exemple de vidéos négatives. Tous les candidats sont visuellement similaires à la requête, mais ne sont pas quasiment en double.
Il existe trois stratégies pour sélectionner les vidéos candidates :
Nous avons décidé d'opter pour la stratégie de récupération transformée en raison des contraintes de temps et de ressources. Dans les applications réelles, les utilisateurs copiaient des vidéos tendances pour des incitations personnelles. Les utilisateurs choisissent généralement de modifier légèrement leurs vidéos copiées pour contourner la détection. Ces modifications contiennent le recadrage vidéo, l'insertion de bordures, etc.
Pour imiter un tel comportement utilisateur, nous définissons une transformation temporelle, c'est-à-dire la vitesse de la vidéo, et trois transformations spatiales, c'est-à-dire le recadrage vidéo, l'insertion d'une bordure noire et la rotation vidéo.
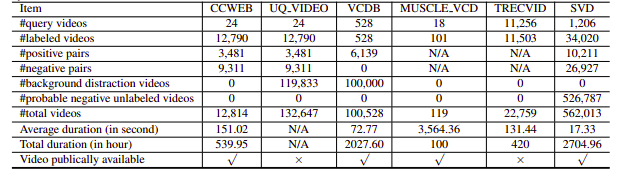
Malheureusement, les ensembles de données NDVR étudiés étaient soit à faible résolution, soit énormes, soit spécifiques à un domaine, soit non accessibles au public (nous en avons également contacté quelques-uns personnellement). Par conséquent, nous avons décidé de créer notre petit ensemble de données personnalisé sur lequel expérimenter.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t indexL'index Flow est défini comme suit :
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : trueCela se décompose en les étapes suivantes :
Ici, nous utilisons un fichier YAML pour définir un Flow et l'utiliser pour indexer les données. La fonction index prend un paramètre input_fn qui prend un itérateur pour transmettre les chemins de fichiers, qui seront ensuite encapsulés dans un IndexRequest et envoyés au Flow.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query Vous pouvez ensuite ouvrir Jinabox avec le point de terminaison personnalisé http://localhost:45678/api/search
Le flux de requête est défini comme suit :
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.ymlLe flux de requête se décompose en les étapes suivantes :


