omochi
1.0.0

Moteur de recherche en texte intégral à partir de zéro par Golangʕ◔ϖ◔ʔ (Juste un jouet)
Créez un réseau Docker (omochi_network) en :
$ docker network create omochi_network
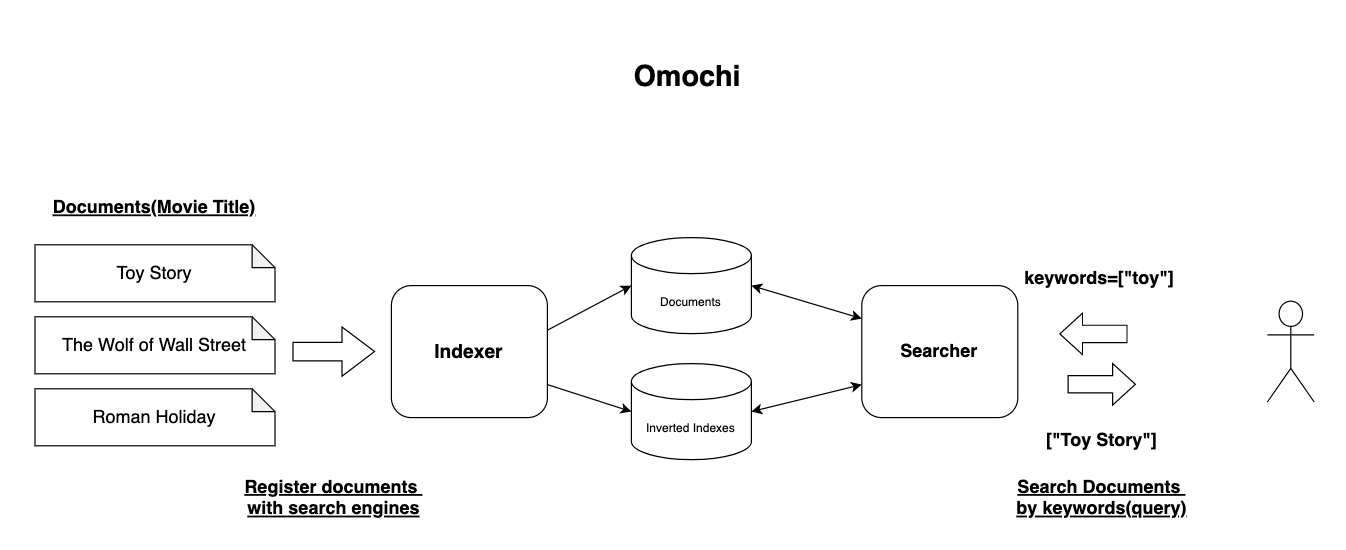
Omochi utilise MariaDB pour stocker les index et documents inversés, et Ent pour ORM.
Pour la migration de la base de données, connectez le shell du conteneur Docker en :
$ docker-compose run api bash
Ensuite, exécutez la migration de la base de données en :
$ go run ./cmd/migrate/migrate.go
Pour essayer le moteur de recherche, ce projet fournit deux ensembles de données comme exemples au format TSV.
L'ensemble de données pour l'anglais est un ensemble de données de titre de film , et l'ensemble de données pour le japonais est un ensemble de données de titre de bande dessinée Doraemon .
Dans un premier temps, connectez le shell du conteneur Docker en :
$ docker-compose run api bash
Ensuite, amorcez les données par :
$ go run {path to seed.go}
Si vous initialisez avec un ensemble de données japonais, {path to seed.go} devrait être ./cmd/seeds/ja/seed.go . En revanche, pour l'anglais, ./cmd/seeds/eng/seed.go .
Une fois la configuration terminée, vous pouvez démarrer l'application en exécutant :
$ docker-compose up
Cette application démarre une API RESTful et écoute les connexions sur le port 8081.
Après avoir semé les données, vous pouvez rechercher des documents en envoyant une requête GET à /v1/document/search .
Les paramètres de requête sont les suivants :
"keywords" : Mots-clés à rechercher. S'il y a plusieurs termes de recherche, spécifiez-les séparés par des virgules comme "hoge,fuga,piyo""mode" : Mode de recherche. Les modes de recherche pouvant être spécifiés sont "And" et "Or" Après l'ensemencement des données par l'ensemble de données du titre de la bande dessinée Doraemon , vous pouvez rechercher des documents qui incluent « ドラえもん » en :
$ curl "http://localhost:8081/v1/document/search?keywords=ドラえもん" | jq .
{
"documents": [
{
"id": 12054,
"content": "ドラえもんの歌",
"tokenized_content": [
"ドラえもん",
"歌"
],
"created_at": "2022-07-08T12:59:49+09:00",
"updated_at": "2022-07-08T12:59:49+09:00"
},
{
"id": 11992,
"content": "恋するドラえもん",
"tokenized_content": [
"恋する",
"ドラえもん"
],
"created_at": "2022-07-08T12:59:48+09:00",
"updated_at": "2022-07-08T12:59:48+09:00"
},
{
"id": 11230,
"content": "ドラえもん登場!",
"tokenized_content": [
"ドラえもん",
"登場"
],
"created_at": "2022-07-08T12:59:44+09:00",
"updated_at": "2022-07-08T12:59:44+09:00"
},
...
Après l'amorçage des données par ensemble de données de titre de film , vous pouvez rechercher des documents comprenant « jouet » et « histoire » en :
$ curl "http://localhost:8081/v1/document/search?keywords=toy,story&mode=And" | jq .
{
"documents": [
{
"id": 1,
"content": "Toy Story",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:49:24+09:00",
"updated_at": "2022-07-08T13:49:24+09:00"
},
{
"id": 39,
"content": "Toy Story of Terror!",
"tokenized_content": [
"toy",
"story",
"terror"
],
"created_at": "2022-07-08T13:49:34+09:00",
"updated_at": "2022-07-08T13:49:34+09:00"
},
{
"id": 83,
"content": "Toy Story That Time Forgot",
"tokenized_content": [
"toy",
"story",
"time",
"forgot"
],
"created_at": "2022-07-08T13:49:53+09:00",
"updated_at": "2022-07-08T13:49:53+09:00"
},
{
"id": 213,
"content": "Toy Story 2",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:50:35+09:00",
"updated_at": "2022-07-08T13:50:35+09:00"
},
{
"id": 352,
"content": "Toy Story 3",
"tokenized_content": [
"toy",
"story"
],
"created_at": "2022-07-08T13:51:23+09:00",
"updated_at": "2022-07-08T13:51:23+09:00"
}
]
}
MIT


