CrawlerTutorial
1.0.0
Lorsque nous naviguons sur Internet, nous voyons souvent une variété de contenus intéressants, tels que des actualités, des produits, des vidéos, des images, etc. Mais si vous souhaitez collecter une grande quantité d’informations spécifiques à partir de ces pages Web, les opérations manuelles prendront du temps et seront laborieuses.
En ce moment, le robot d'exploration Web (Web Crawler) est utile ! En termes simples, un robot d'exploration Web est un programme capable d'imiter le comportement d'un navigateur humain et d'explorer automatiquement les informations Web. Grâce aux capacités d'automatisation de ce programme, nous pouvons facilement « explorer » les données qui nous intéressent à partir du site Web, puis stocker ces données pour une analyse ultérieure.
La façon dont un robot d'exploration Web fonctionne généralement consiste d'abord à envoyer une requête HTTP au site Web cible, puis à obtenir la réponse HTML du site Web, à analyser le contenu de la page, puis à extraire les données utiles. Par exemple, si nous souhaitons collecter le titre, l'auteur, l'heure et d'autres informations des articles sur le forum de potins des PTT, nous pouvons utiliser la technologie des robots d'exploration Web pour capturer automatiquement ces informations et les stocker. De cette façon, vous pouvez obtenir les informations dont vous avez besoin sans parcourir manuellement le site Web.
Les robots d'exploration Web ont de nombreuses applications pratiques, telles que :
Bien entendu, lorsque nous utilisons des robots d'exploration Web, nous devons respecter les conditions d'utilisation et la politique de confidentialité du site Web, et ne pouvons pas explorer les informations en violation des réglementations du site Web. Dans le même temps, afin d'assurer le fonctionnement normal du site Web, nous devons également concevoir des stratégies d'exploration appropriées pour éviter une charge excessive sur le site Web.
Ce didacticiel utilise Python3 et utilisera pip pour installer les packages requis. Les packages suivants doivent être installés :
requests : utilisé pour envoyer et recevoir des requêtes et des réponses HTTP.requests_html : utilisé pour analyser et explorer des éléments en HTML.rich : laissez les informations s'afficher magnifiquement sur la console, par exemple en affichant un beau tableau.lxml ou PyQuery : utilisé pour analyser des éléments en HTML.Utilisez les instructions suivantes pour installer ces packages :
pip install requests requests_html rich lxml PyQueryDans le chapitre de base, nous présenterons brièvement comment collecter des données à partir de la page Web PTT, telles que le titre de l'article, l'auteur et l'heure.
Utilisons les articles de lecture de versions de PTT comme cibles de nos robots !
Lors de l'exploration d'une page Web, nous utilisons la fonction requests.get() pour simuler l'envoi par le navigateur d'une requête HTTP GET pour « parcourir » la page Web. Cette fonction renverra un objet requests.Response , qui contient le contenu de la réponse de la page Web. Il convient toutefois de noter que ce contenu est présenté sous forme de code source pur texte et n’est pas restitué par le navigateur. Nous pouvons l'obtenir via la propriété response.text .
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )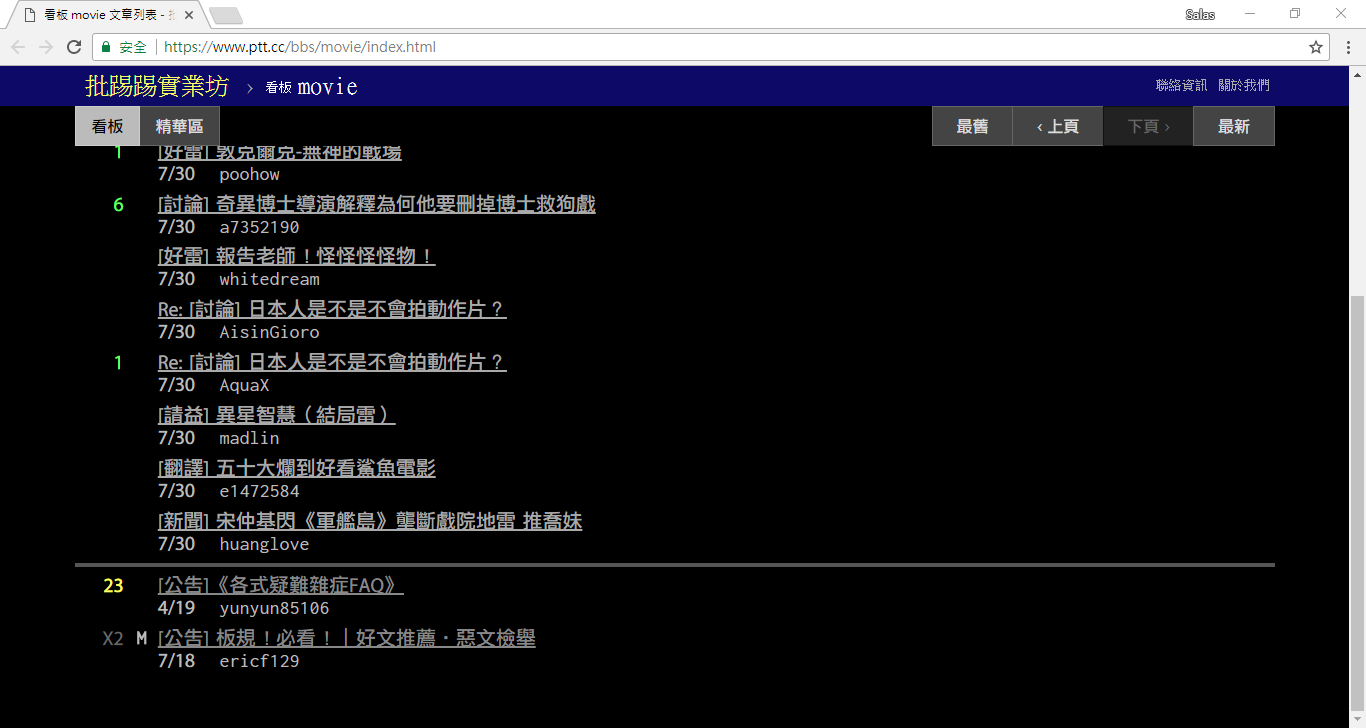
Dans les utilisations ultérieures, nous devrons utiliser requests_html requests_html.HTML développer requests En plus de requests_html comme un navigateur, nous devons également analyser response.text pages Web HTML. La réécriture est également très simple. Utilisez session.get() pour remplacer le requests.get() ci-dessus.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )Cependant, lorsque nous essayons d’appliquer cette méthode au Gossiping, nous pouvons rencontrer des erreurs. En effet, lorsque nous parcourons le forum pour la première fois, le site Web confirmera si nous avons plus de 18 ans ; lorsque nous cliquons pour confirmer, le navigateur enregistrera les cookies correspondants afin que nous ne vous le demandions plus la prochaine fois. entrez (vous pouvez essayer d'utiliser le mode navigation privée pour ouvrir le test et consulter la page d'accueil de la version Bagua). Cependant, pour les robots d'exploration du Web, nous devons enregistrer ce cookie spécial afin que nous puissions prétendre avoir réussi le test de dix-huit ans lors de la navigation.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) Ensuite, nous pouvons utiliser la méthode response.html.find() pour localiser l'élément et utiliser le sélecteur CSS pour spécifier l'élément cible. Dans cette étape, nous pouvons observer que dans la version web PTT, les informations sur le titre de chaque article se trouvent dans une balise div avec une catégorie r-ent . Nous pouvons donc utiliser le sélecteur CSS div.r-ent pour cibler ces éléments.
L'utilisation de la méthode response.html.find() renverra une liste d'éléments qui remplissent les conditions, nous pouvons donc utiliser for pour traiter ces éléments un par un. À l'intérieur de chaque élément, nous pouvons utiliser element.find() pour analyser davantage l'élément et utiliser des sélecteurs CSS pour spécifier les informations à extraire. Dans cet exemple, nous pouvons utiliser le sélecteur CSS div.title pour cibler l'élément title. De même, nous pouvons utiliser la propriété element.text pour obtenir le contenu textuel d'un élément.
Voici un exemple de code utilisant requests_html :
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
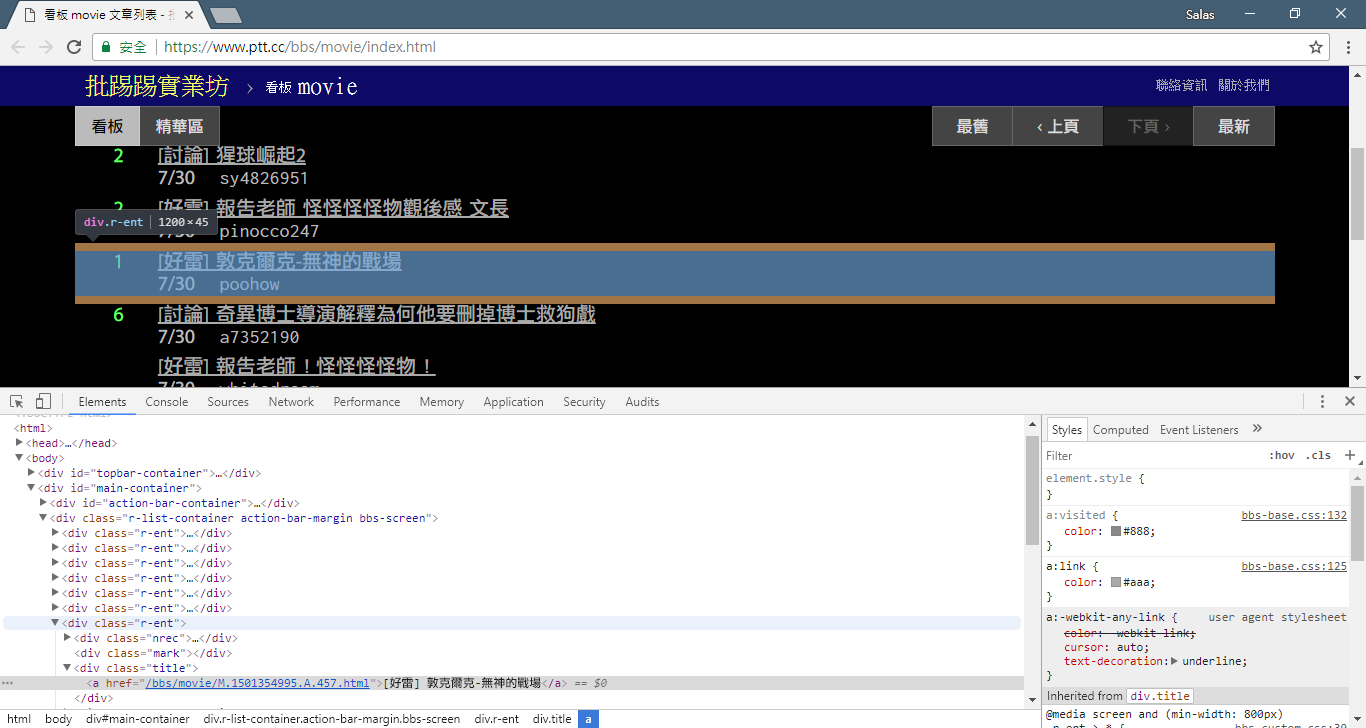
# 提取資訊... À l’étape précédente, nous avons utilisé la méthode response.html.find() pour localiser les éléments de chaque article. Ces éléments sont ciblés à l'aide du sélecteur CSS div.r-ent . Vous pouvez utiliser la fonctionnalité Outils de développement pour observer la structure des éléments d'une page Web. Après avoir ouvert la page Web et appuyé sur la touche F12, un panneau d'outils de développement s'affichera, contenant la structure HTML de la page Web et d'autres informations.
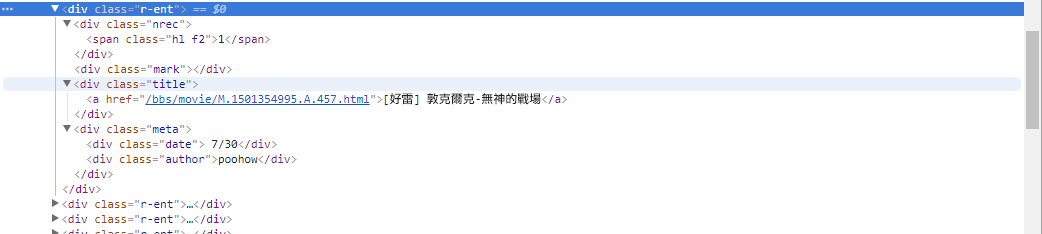
À l'aide des outils de développement, vous pouvez utiliser le pointeur de la souris pour sélectionner un élément spécifique sur la page Web, puis afficher la structure HTML de l'élément, les attributs CSS et d'autres détails dans le panneau des outils de développement. Cela vous aide à déterminer quel élément cibler et le sélecteur CSS correspondant. De plus, vous découvrirez peut-être pourquoi le programme tourne parfois mal ? ! En regardant la version Web, j'ai découvert que lorsqu'un article de la page était supprimé, la結構du code source de l'élément <本文已被刪除> sur la page Web était différente de celle d'origine ! Nous pouvons donc le renforcer davantage pour gérer la situation où des articles sont supprimés.
Revenons maintenant à l'exemple de code pour l'extraction d'informations à l'aide de requests_html :
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )Traitement de texte en sortie :
Ici, nous pouvons utiliser rich pour afficher une belle sortie. Tout d'abord, créez un objet table rich , puis remplacez print dans la boucle de l'exemple de code ci-dessus par add_row à la table. Enfin, nous utilisons la fonction print de rich pour afficher correctement la table sur le terminal.
Résultat de l'exécution
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )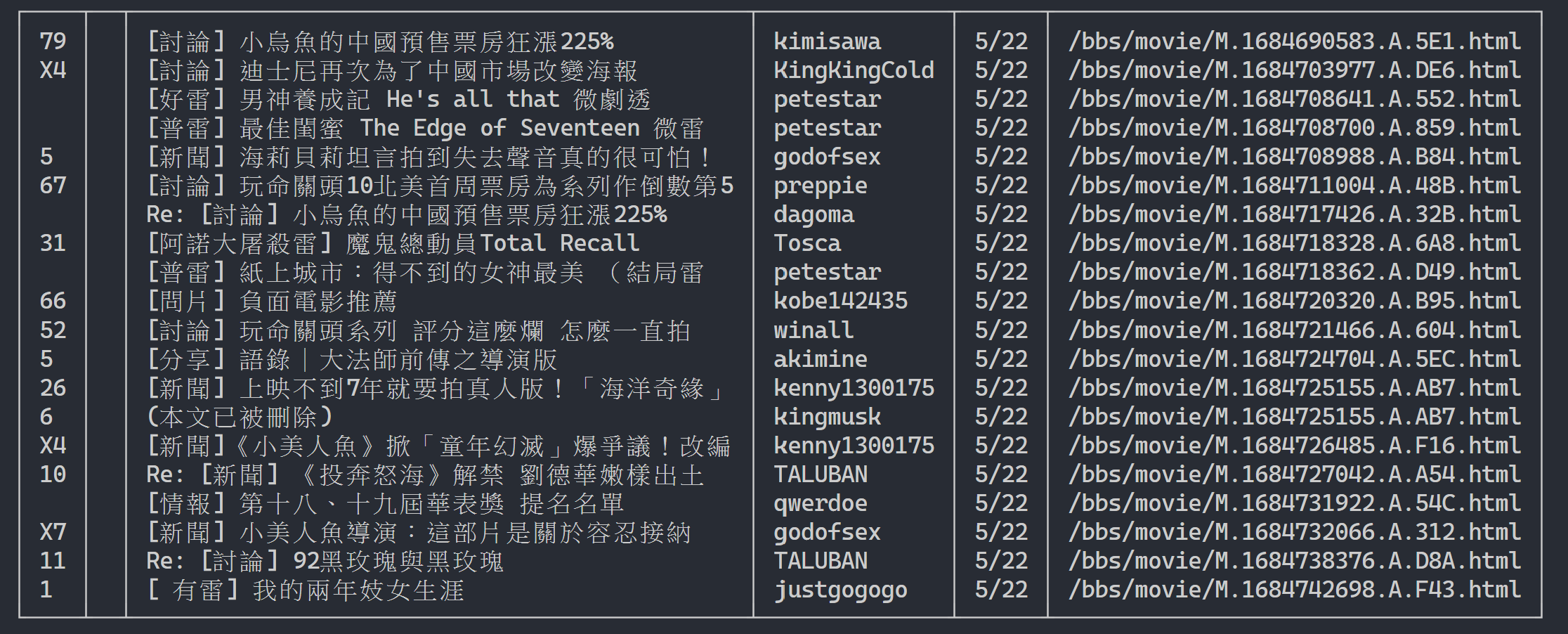
Maintenant, nous allons utiliser la « méthode d'observation » pour retrouver le lien vers la page précédente. Non, je ne vous demande pas où se trouve le bouton sur votre navigateur, mais « l'arborescence des sources » dans les outils de développement. Je pense que vous avez découvert que le lien hypertexte pour le saut de page se trouve dans l'élément <a class="btn wide"> de <div class="action-bar"> . On peut donc les extraire comme ceci :
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )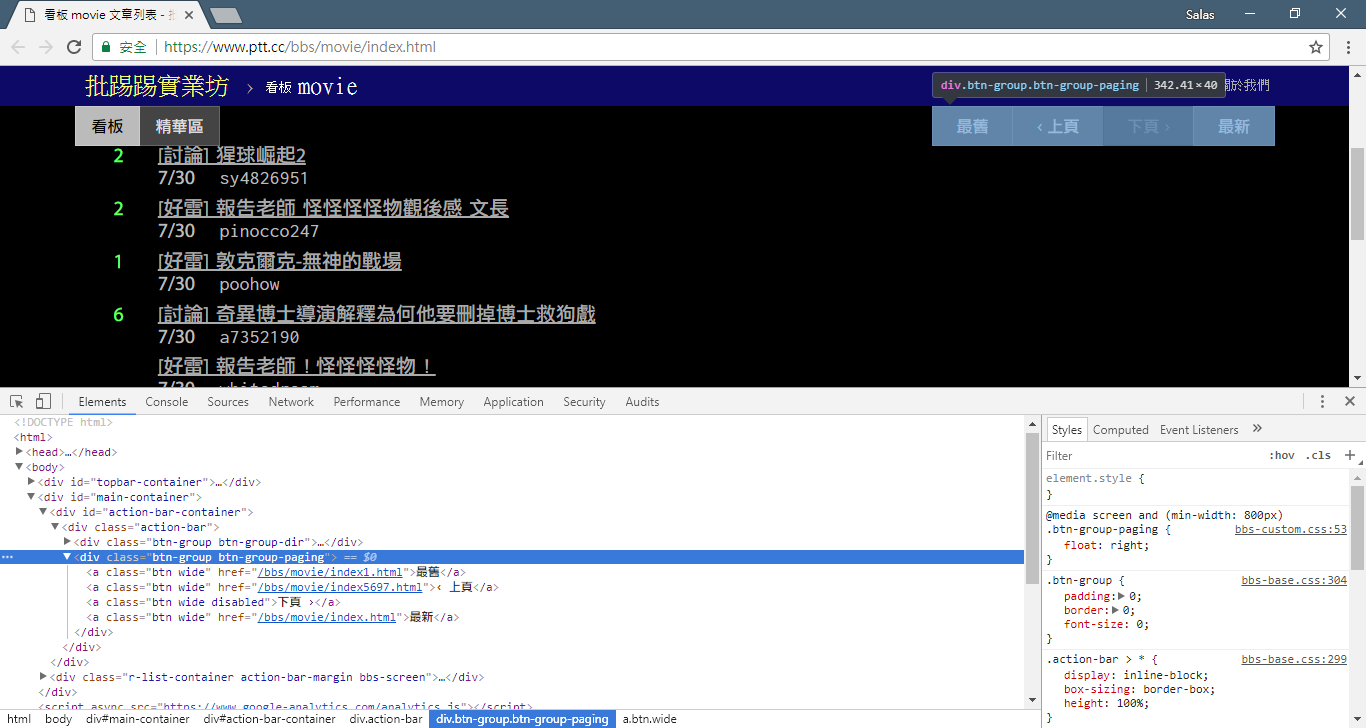
Ce dont nous avons besoin, c'est de la fonction « page précédente ». Pourquoi ? Parce que les derniers articles de PTT sont affichés au premier plan, donc si vous souhaitez trouver des informations, vous devez faire défiler vers l'avant.
Alors comment l'utiliser ? Saisissez d’abord le deuxième href dans control (l’index est 1), il peut alors ressembler à ceci /bbs/movie/index3237.html et l’adresse complète du site Web (URL) doit être https://www.ptt.cc/ ( URL du domaine), utilisez donc urljoin() (ou connexion directe par chaîne) pour comparer et fusionner le lien de la page d'accueil du film avec le nouveau lien dans une URL complète !
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url Réorganisons maintenant la fonction pour faciliter les explications ultérieures. Changeons l'exemple de traitement de chaque élément d'article à l'étape 3 : jetons un coup d'œil à ces messages de titre en une fonction indépendante parse_article_entries(elements)
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return resultsEnsuite, nous pouvons gérer le contenu de plusieurs pages
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_urlRésultat de sortie :
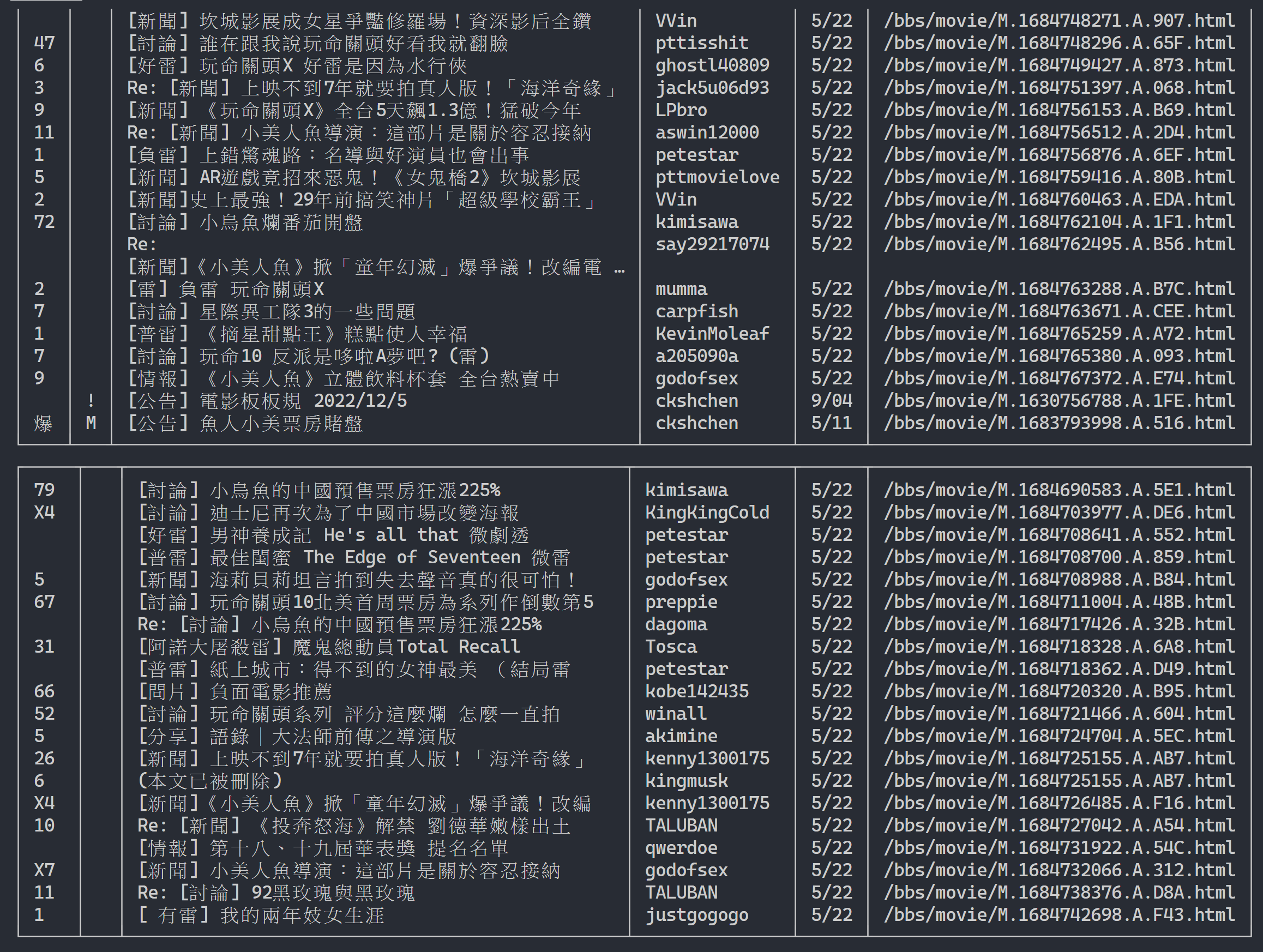
Après avoir obtenu les informations sur la liste d'articles, l'étape suivante consiste à obtenir le contenu de l'article (article PO) (contenu de la publication) ! link dans les métadonnées est le lien de chaque article. Nous utilisons également urllib.parse.urljoin pour concaténer l'URL complète puis émettons HTTP GET pour obtenir le contenu de l'article. On peut observer que la tâche de capture du contenu de chaque article est très répétitive et se prête très bien à un traitement par une méthode de parallélisation.
En Python, vous pouvez utiliser multiprocessing.Pool pour effectuer une programmation multitraitement de haut niveau ~ C'est le moyen le plus simple d'utiliser le multiprocessus en Python ! Il est très approprié pour ce scénario d'application SIMD (Single Instruction Multiple Data). Utilisez la syntaxe de l'instruction with pour libérer automatiquement les ressources du processus après utilisation. L'utilisation de ProcessPool est également très simple, pool.map(function, items) , ce qui ressemble un peu au concept de programmation fonctionnelle Appliquer une fonction à chaque élément, et enfin obtenir le même nombre de listes de résultats que d'éléments.
Utilisé dans la tâche d'exploration du contenu de l'article introduite précédemment :
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )Ci-joint les résultats expérimentaux :
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章On peut voir que la vitesse d'exécution globale a été accélérée de près de cinq fois, mais plus il y a Process mieux c'est. En plus des spécifications matérielles telles que le processeur, cela dépend principalement des limitations des périphériques externes tels que les cartes réseau et. vitesses du réseau.
Le code ci-dessus se trouve dans ( src/basic_crawler.py ) !
Nouvelle fonctionnalité dans PTT Web : Rechercher ! Enfin disponible sur la version web
Utilisons également la version cinématographique de PTT comme cible de notre robot ! Le contenu consultable dans la nouvelle fonctionnalité comprend :
Les trois premiers peuvent tous trouver des règles de la nouvelle version du code source de la page et envoyer des requêtes, mais la recherche du nombre de tweets ne semble pas être apparue dans l'interface utilisateur de la version web, voici donc les paramètres extraits par l'auteur à partir PTT 網站原始碼. Le PTT que nous parcourons habituellement comprend en fait le serveur BBS (c'est-à-dire BBS) et le serveur Web front-end (version web). Le serveur Web front-end est écrit en langage Go (Golang) et peut accéder directement au back-end. Données BBS et utilisation Le mode d'interaction général du site Web restitue le contenu dans une page Web pour la navigation.
En fait, il est très simple d'utiliser ces nouvelles fonctions. Il suffit d'utiliser une requête HTTP GET et d'ajouter une chaîne de requête standard pour obtenir ces informations. L'URL endpoint qui fournit la fonction de recherche est /bbs/{看板名稱}/search . Utilisez simplement la requête correspondante pour obtenir les résultats de la recherche à partir d'ici. Tout d’abord, prenons le mot-clé du titre comme exemple,
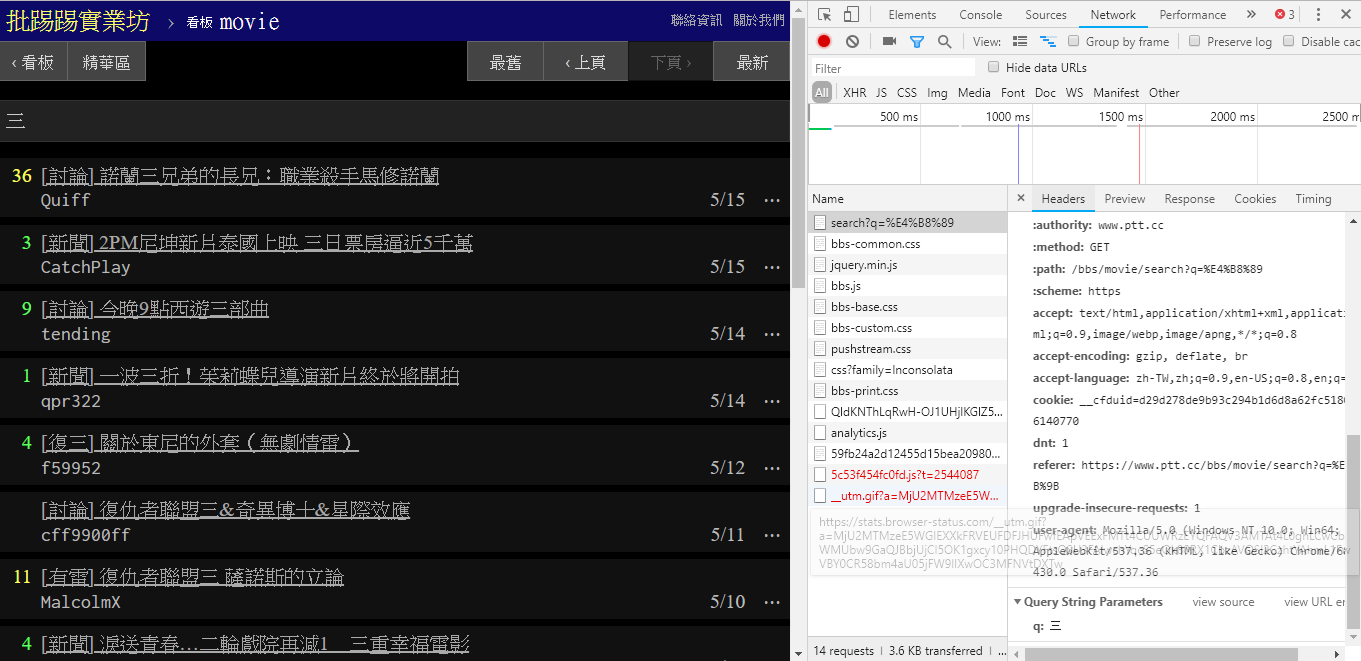
Comme on peut le voir dans le coin inférieur droit de l'image, lors d'une recherche, une requête GET avec q=三est en fait envoyée au endpoint , donc l'URL complète entière devrait ressembler à https://www.ptt.cc/bbs/movie/search?q=三, l'URL copiée à partir de la barre d'adresse peut être sous la forme https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 car le chinois a été HTML codé mais représente la même signification. Dans requests , si vous souhaitez ajouter des paramètres de requête supplémentaires, vous n'avez pas besoin de construire manuellement le formulaire de chaîne vous-même. Il vous suffit de les mettre dans les paramètres de la fonction via dict() de param= , comme ceci :
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })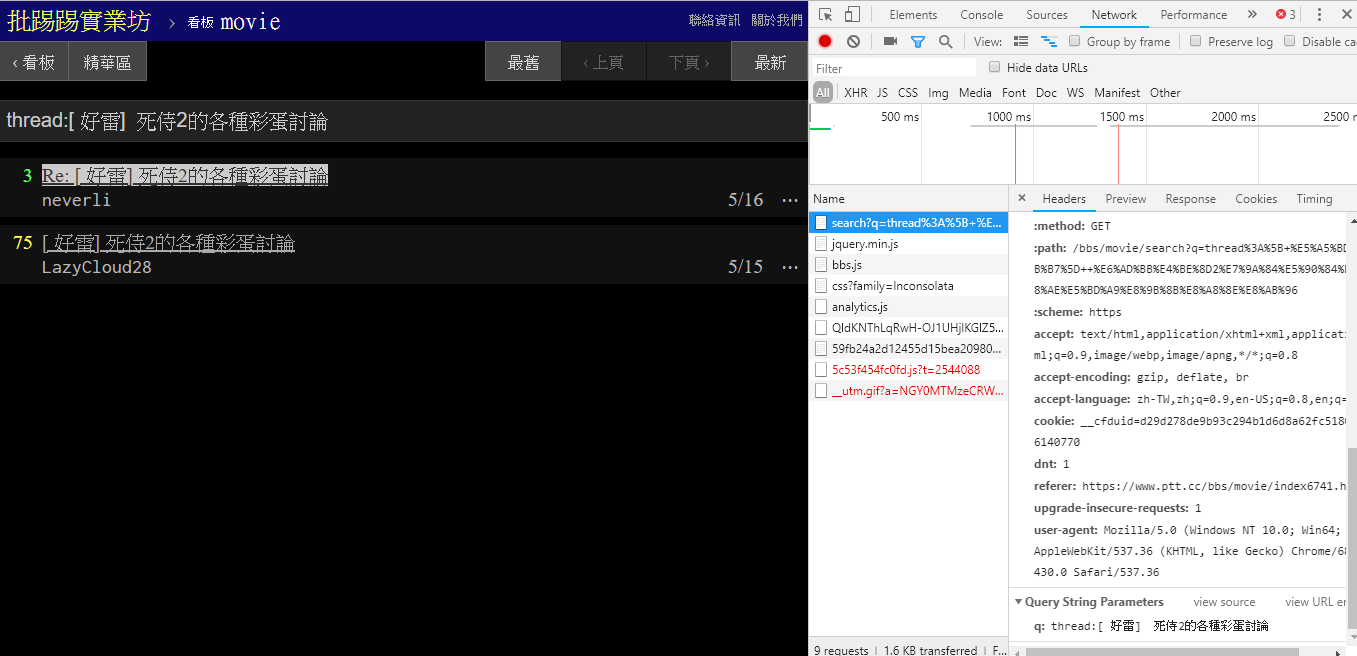
Lorsque vous recherchez le même article (thread), vous pouvez voir à partir des informations dans le coin inférieur droit que vous enchaînez réellement la chaîne thread: devant le titre et envoyez la requête.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })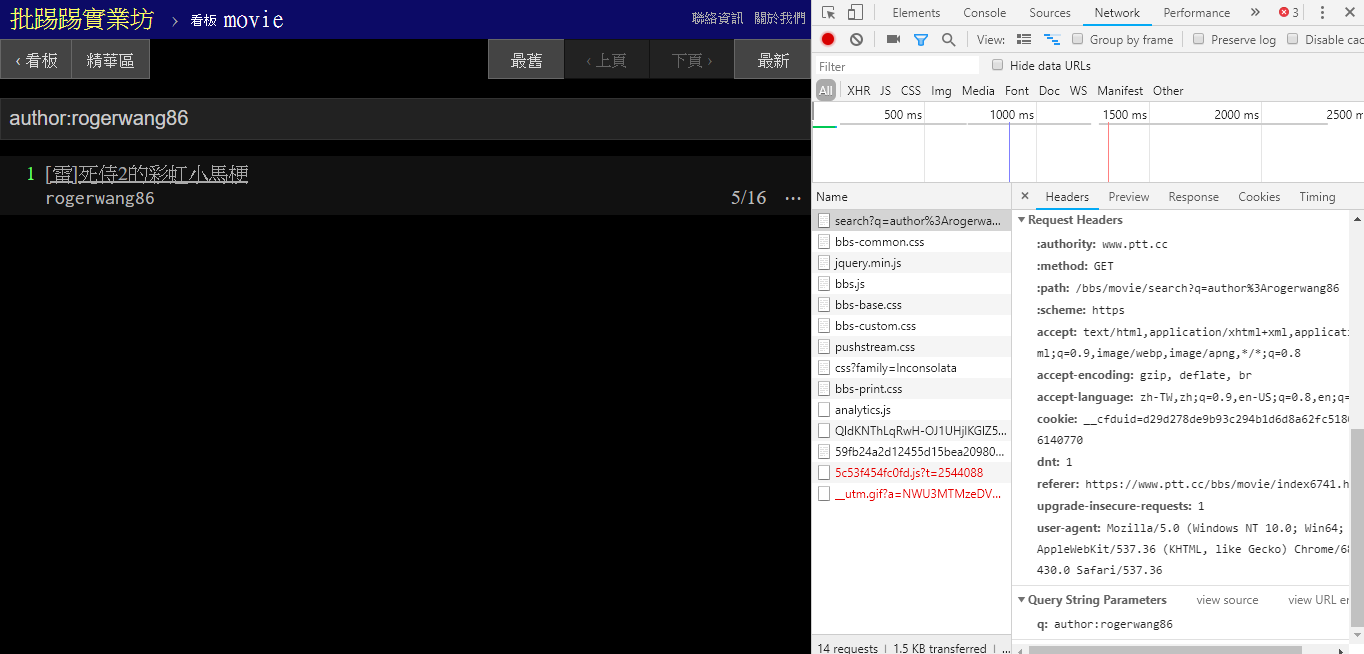
Lors de la recherche d'articles avec le même auteur (auteur), il ressort également des informations dans le coin inférieur droit que author: est concaténée avec le nom de l'auteur, puis la requête est envoyée.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })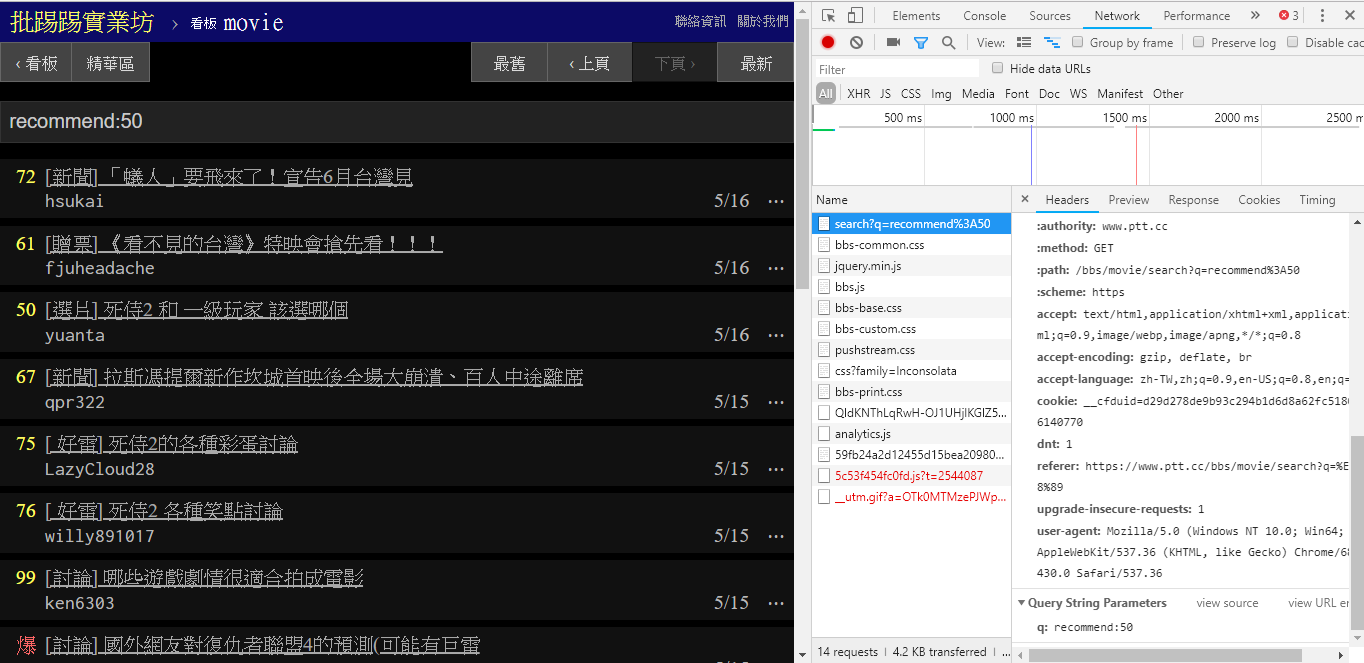
Lorsque vous recherchez des articles avec un nombre de tweets supérieur à (recommander), enchaînez la chaîne recommend: avec le nombre minimum de tweets que vous souhaitez rechercher, puis envoyez la requête. De plus, il ressort du code source du serveur Web PTT que le nombre de tweets ne peut être défini que dans une plage de ±100.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })Code source de la fonction d'analyse Web PTT de ces paramètres
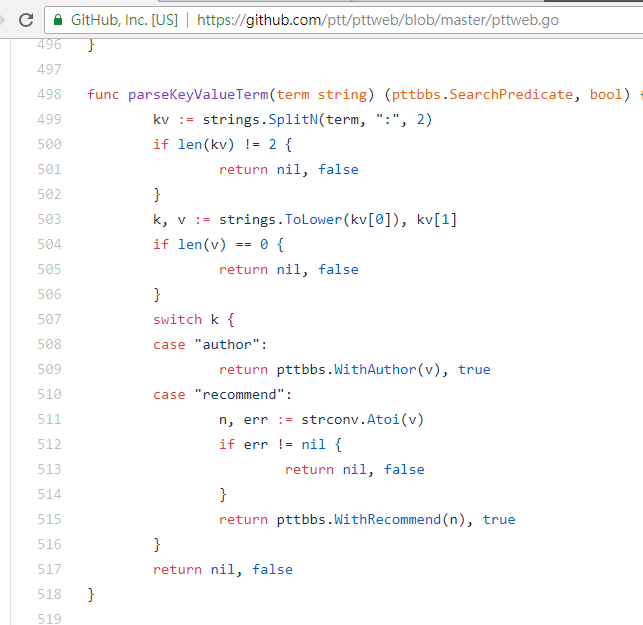
Il convient également de mentionner que la présentation finale des résultats de recherche est la même que la disposition générale évoquée dans les bases, vous pouvez donc directement réutiliser les fonctions précédentes. Don't do it again!
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] Il existe un autre paramètre dans la recherche. Le nombre de page est similaire à celui de la recherche Google. L'élément recherché peut comporter de nombreuses pages. Vous pouvez donc utiliser ce paramètre supplémentaire pour contrôler la page de résultats que vous souhaitez obtenir sans avoir à analyser le lien. la page.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) L'intégration de toutes les fonctions précédentes dans ptt-parser peut fournir des fonctions de ligne de commande et爬蟲sous la forme d'API pouvant être appelées par programme.
scrapy pour explorer de manière stable les données PTT.
Cette œuvre a été réalisée par leVirve et est publiée sous licence internationale Creative Commons Attribution 4.0.


