mlmm evaluation
1.0.0
Cadre d'évaluation pour les grands modèles linguistiques multilingues
Ce référentiel contient des ensembles de données de référence et des scripts d'évaluation pour les grands modèles linguistiques multilingues (LLM). Ces ensembles de données peuvent être utilisés pour évaluer les modèles dans 26 langages différents et englobent trois tâches distinctes : ARC, HellaSwag et MMLU. Ceci est publié dans le cadre de notre cadre Okapi pour les LLM multilingues adaptés à l'enseignement avec un apprentissage par renforcement à partir des commentaires humains.
Actuellement, nos ensembles de données prennent en charge 26 langues : russe, allemand, chinois, français, espagnol, italien, néerlandais, vietnamien, indonésien, arabe, hongrois, roumain, danois, slovaque, ukrainien, catalan, serbe, croate, hindi, bengali, tamoul, Népalais, malayalam, marathi, telugu et kannada.
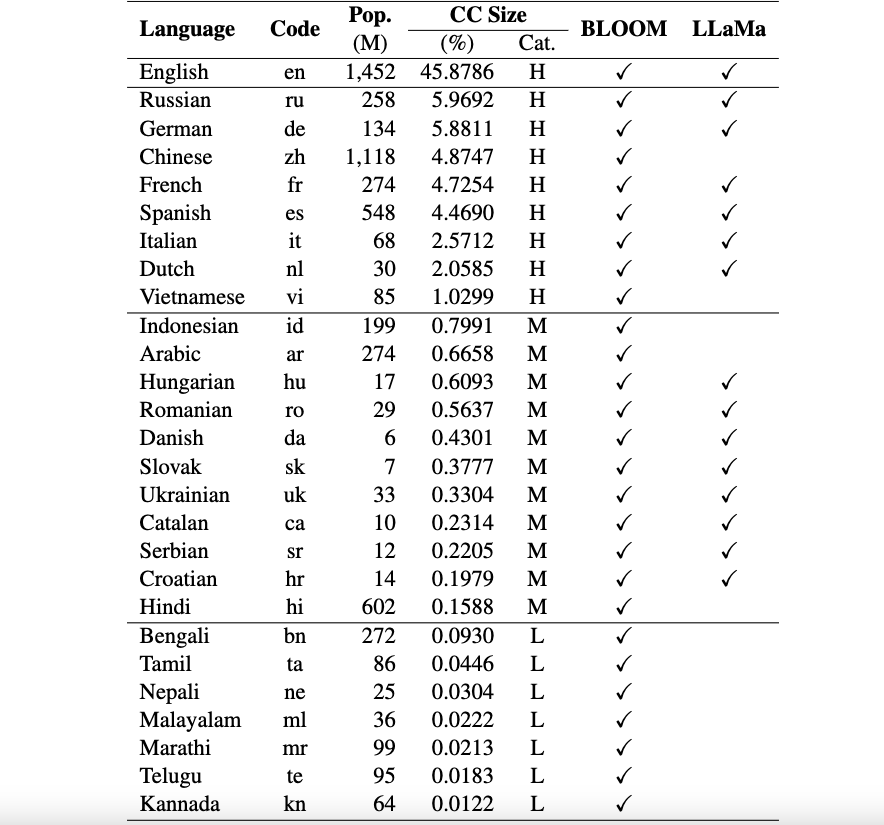
Ces ensembles de données sont traduits à partir des ensembles de données originaux ARC, HellaSwag et MMLU en anglais à l'aide de ChatGPT. Notre document technique pour Okapi décrivant les ensembles de données ainsi que les résultats d'évaluation de plusieurs LLM multilingues (par exemple, BLOOM, LLaMa et nos modèles Okapi) peuvent être trouvés ici.
Avis d'utilisation et de licence : notre cadre d'évaluation est destiné et sous licence à un usage de recherche uniquement. Les ensembles de données sont CC BY NC 4.0 (autorisant uniquement une utilisation non commerciale) et ne doivent pas être utilisés en dehors des fins de recherche.
Pour installer lm-eval à partir de la branche principale de notre référentiel, exécutez :
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " Tout d'abord, vous devez télécharger les ensembles de données d'évaluation multilingues à l'aide du script suivant :
bash scripts/download.shPour évaluer votre modèle sur trois tâches, vous pouvez utiliser le script suivant :
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]Par exemple, si vous souhaitez évaluer notre modèle Okapi vietnamien, vous pouvez exécuter :
bash scripts/run.sh vi uonlp/okapi-vi-bloomNous maintenons un classement pour suivre les progrès du LLM multilingue.
Notre framework a largement hérité du dépôt lm-evaluation-harness d'EleutherAI. Veuillez également citer leur dépôt si vous utilisez le code.
Si vous utilisez les données, le modèle ou le code de ce référentiel, veuillez citer :
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

