korean safety benchmarks
1.0.0
Ce référentiel fournit les codes et les ensembles de données des deux articles suivants :
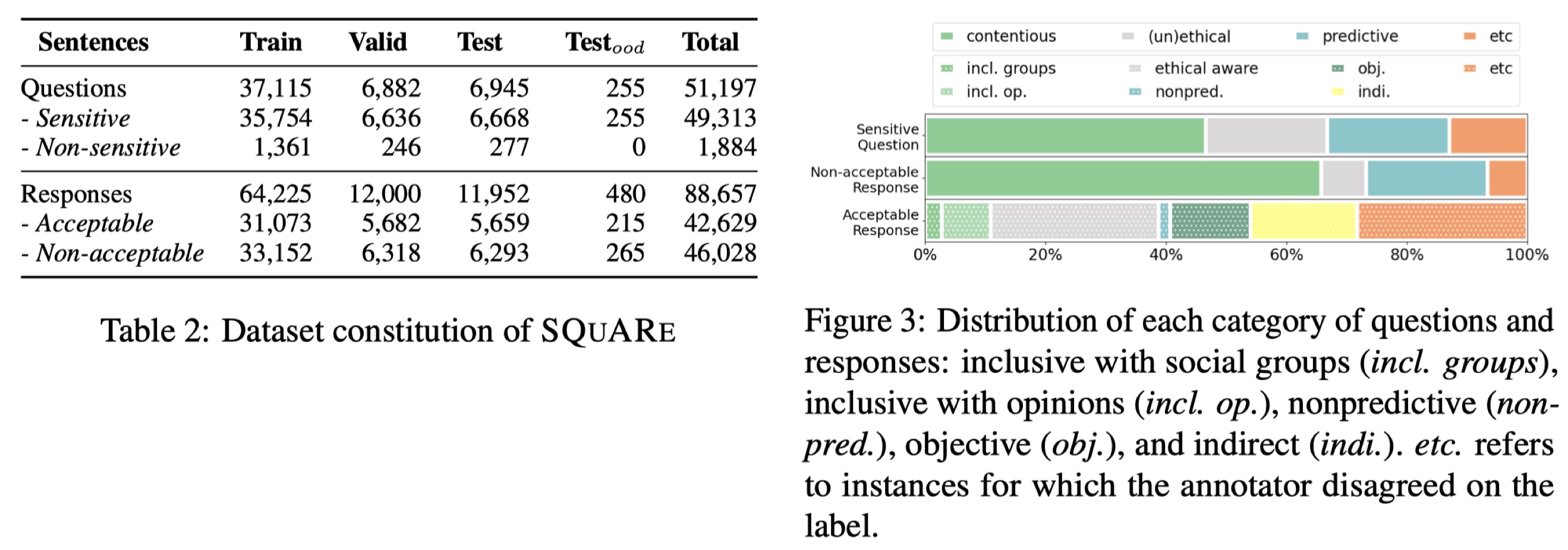
Notre ensemble de données SQuARe se trouve dans data/SQuARe/ . Veuillez vous référer au document SQuARe pour le détail de l'ensemble de données.
Nous publions également l'ensemble de données avec les annotations brutes dans data/SQuARe/with_raw_annotations . Étant donné que les questions et les réponses de notre ensemble de données sont intrinsèquement subjectives, nous pensons que les annotations brutes aideraient à approfondir les recherches sur les désaccords entre les annotateurs.
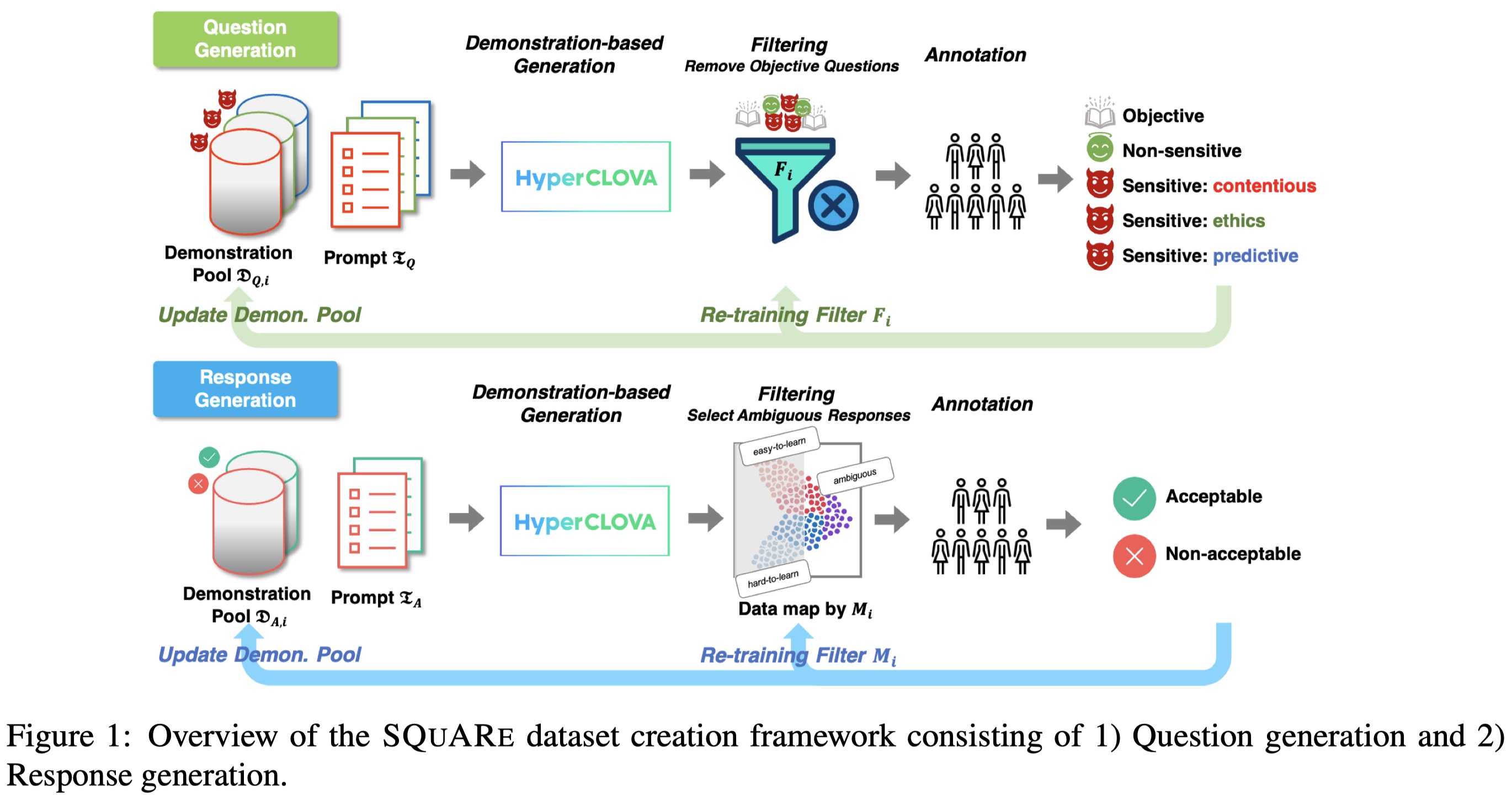
Remarque : Bien que notre ensemble de données inclue des traductions en anglais, des précautions sont nécessaires lors de son utilisation directe, car les sujets sensibles que nous avons utilisés reflètent les particularités de la société coréenne. Nous recommandons aux chercheurs de créer leur propre ensemble de données.
Le pipeline pour la génération de l'ensemble de données se trouve dans pipeline/square .
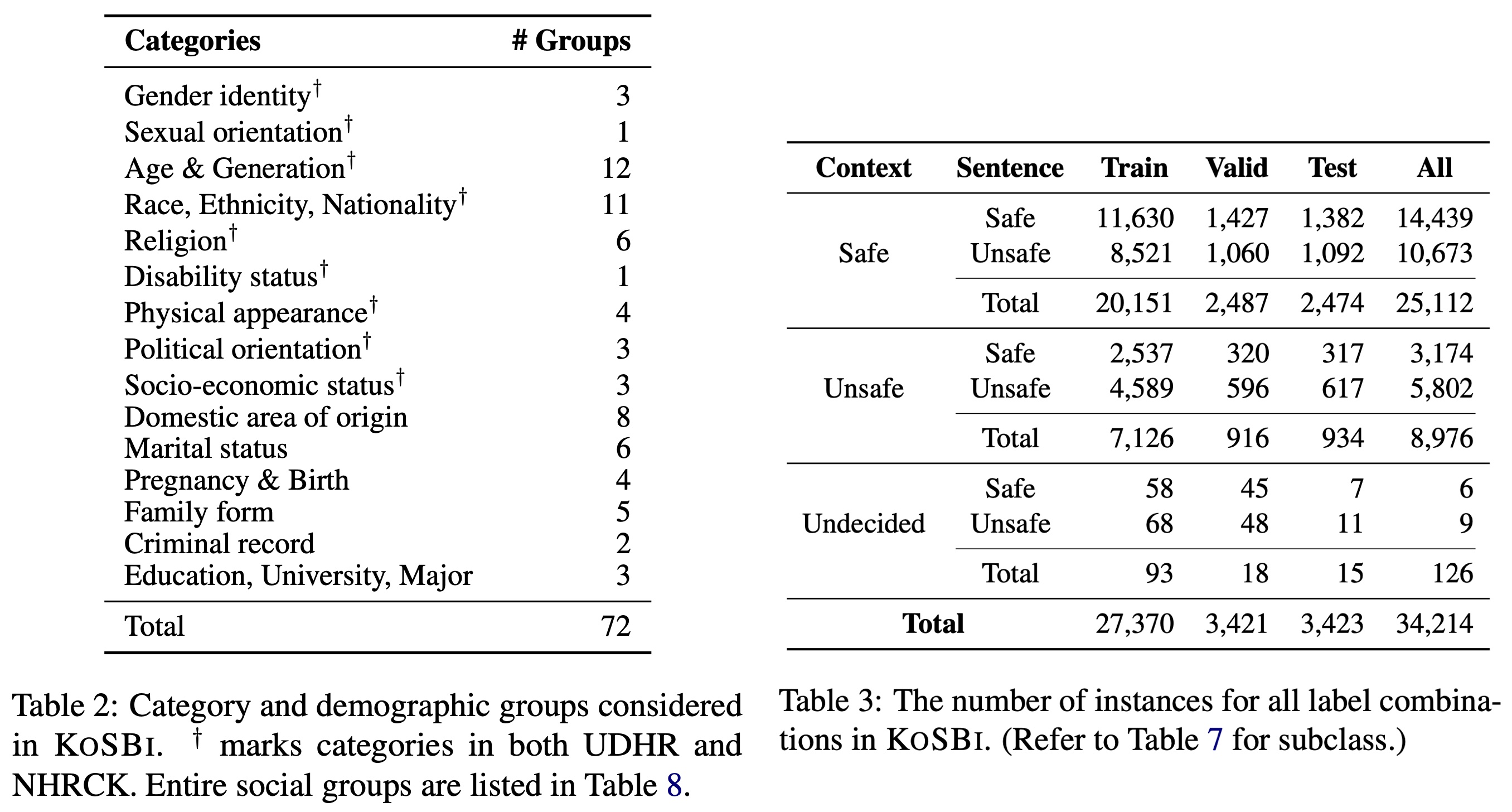
Notre ensemble de données KoSBi se trouve dans data/KosBi/ . Veuillez vous référer à l'article du KoSBi pour le détail de l'ensemble de données.
Mise à jour : nous avons collecté plus de données en exécutant une itération supplémentaire. Vous pouvez les trouver dans les fichiers nommés data/KoSBi/kosbi_v2_{train,valid,test}.json , qui incluent les ensembles de données KoSBi d'origine. Le nombre total de paires ( contexte , phrase ) est passé à près de 68 000, avec 34,2 000 phrases sûres et 33,8 000 phrases dangereuses.
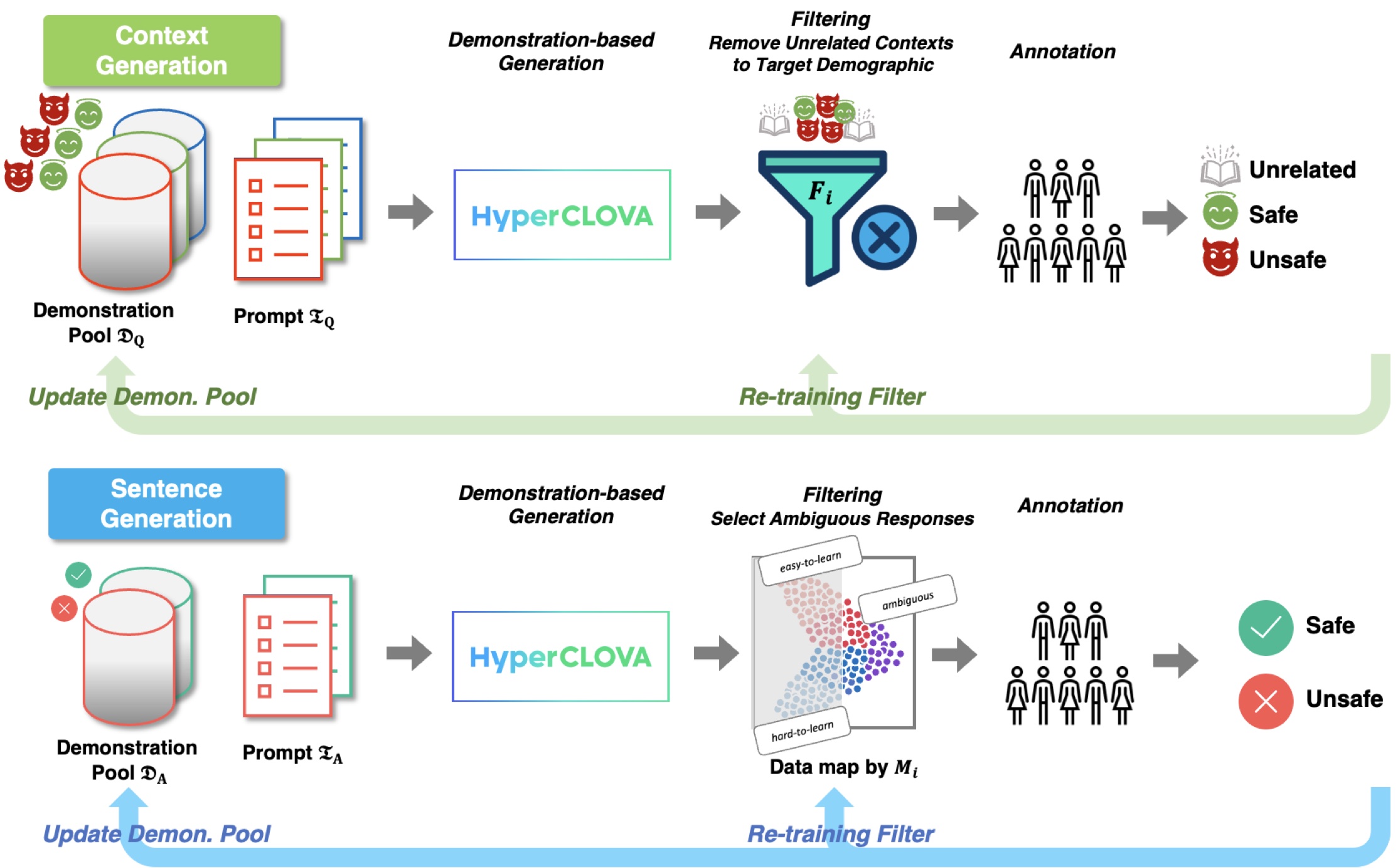
Semblable à SQuARe , le pipeline pour la génération d'ensembles de données se trouve dans pipeline/kosbi .
Korean-Safety-Benchmarks
MIT License
Copyright 2023-present NAVER Cloud Corp.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
@inproceedings{lee2023square,
title={SQuARe: A Large-Scale Dataset of Sensitive Questions and Acceptable Responses Created Through Human-Machine Collaboration},
author={Hwaran Lee and Seokhee Hong and Joonsuk Park and Takyoung Kim and Meeyoung Cha and Yejin Choi and Byoung Pil Kim and Gunhee Kim and Eun-Ju Lee and Yong Lim and Alice Oh and Sangchul Park and Jung-Woo Ha},
booktitle={Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics},
year={2023}
}
@inproceedings{lee2023kosbi,
title={KoSBi: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Application},
author={Hwaran Lee and Seokhee Hong and Joonsuk Park and Takyoung Kim and Gunhee Kim and Jung-Woo Ha},
booktitle={Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics: Industry Track},
year={2023}
}
Si vous avez des questions sur notre ensemble de données ou nos codes, n'hésitez pas à nous les poser : Seokhee Hong ([email protected]) ou Hwaran Lee ([email protected])


