alpaga-rlhf
Mise au point de LLaMA avec RLHF (Reinforcement Learning with Human Feedback).
Démo en ligne
Modifications sur DeepSpeed Chat
Étape 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- Définir des jetons spéciaux
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Entraînez-vous uniquement sur les réponses et ajoutez des eos
- Supprimer end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- Les étiquettes diffèrent de l'entrée
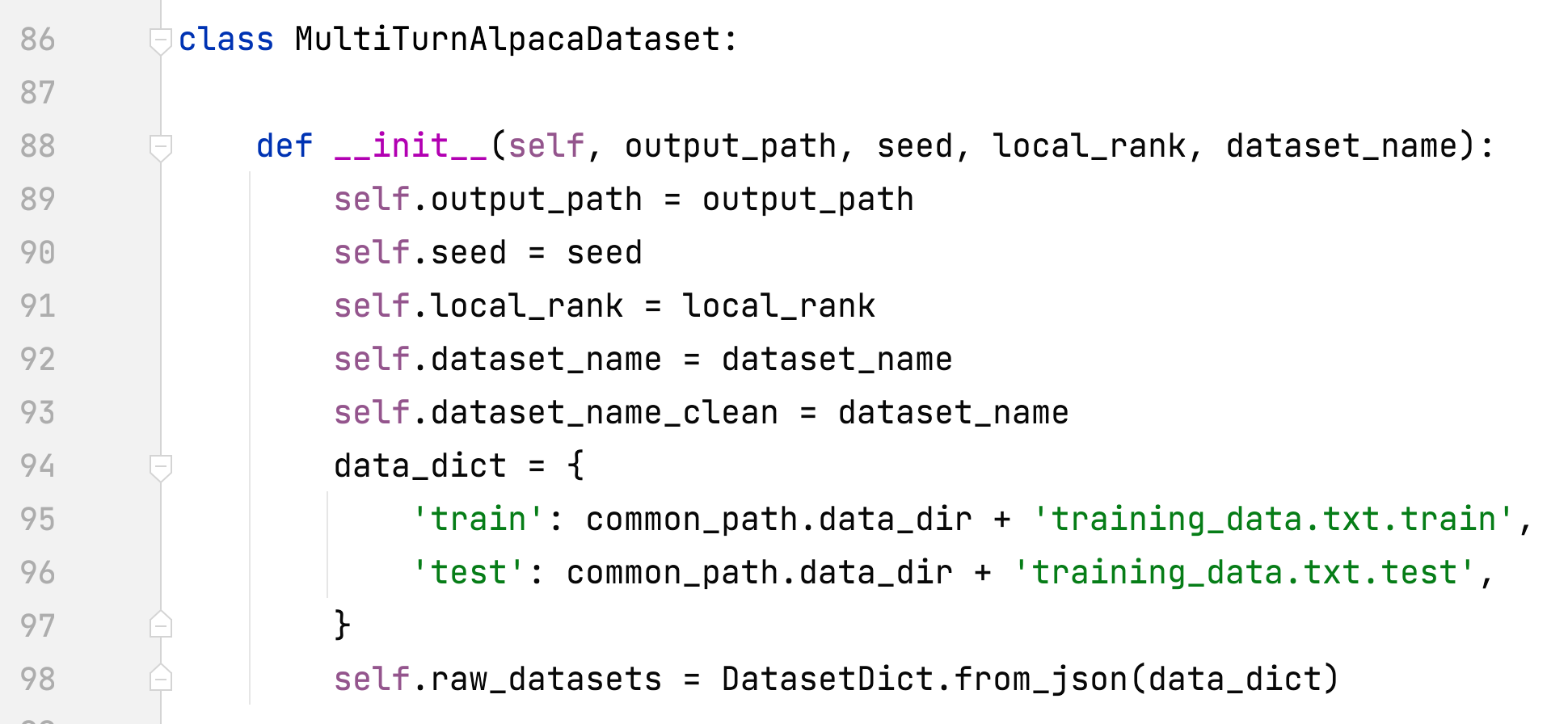
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- ajouter MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- Prise en charge de plusieurs noms de modules pour Lora
Étape 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- Définir des jetons spéciaux
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- Correction de l'instabilité numérique
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Supprimer end_of_conversation_token
Étape 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- Définir des jetons spéciaux
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Correction d'un bug de longueur maximale
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# appel
- Correction d'un bug côté rembourrage
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
- Masquez les jetons après l'eos
Stey par étape
- Exécution des trois étapes sur 2 x A100 80G
- Ensembles de données
- Dahoas/rm-static huggingface papier GitHub
- MultiTurnAlpaga
- Il s'agit d'une version multi-tours de l'ensemble de données alpaga et est construite sur la base d'AlpacaDataCleaned et ChatAlpaca.
- Entrez d’abord le répertoire ./alpaca_rlhf, puis exécutez les commandes suivantes :
- étape 1 : sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- lorsque --sft_only_data_path MultiTurnAlpaca est ajouté, veuillez d'abord décompresser data/data.zip.
- étape 2 : sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
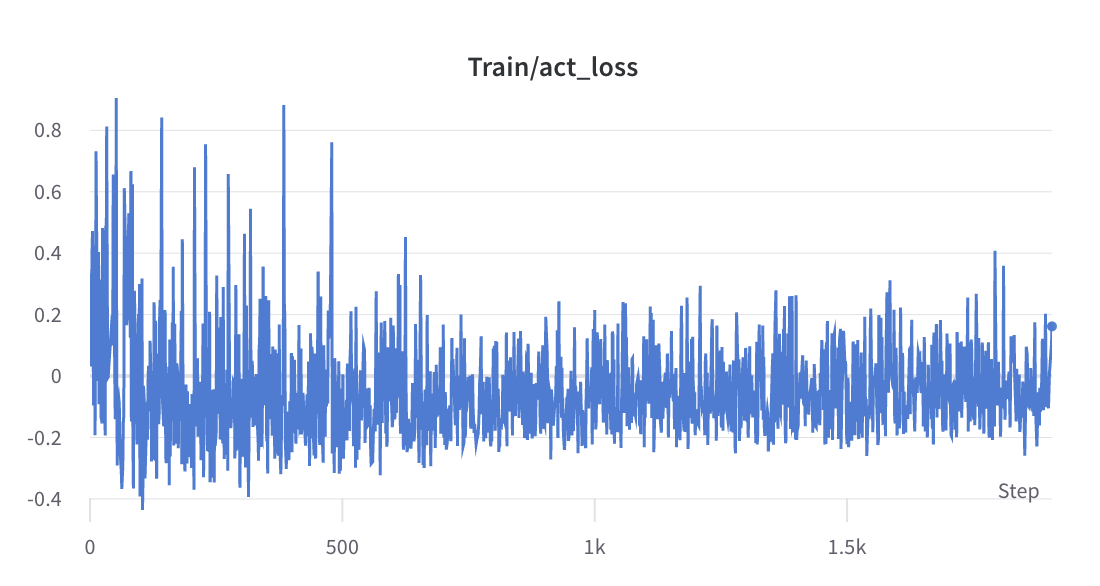
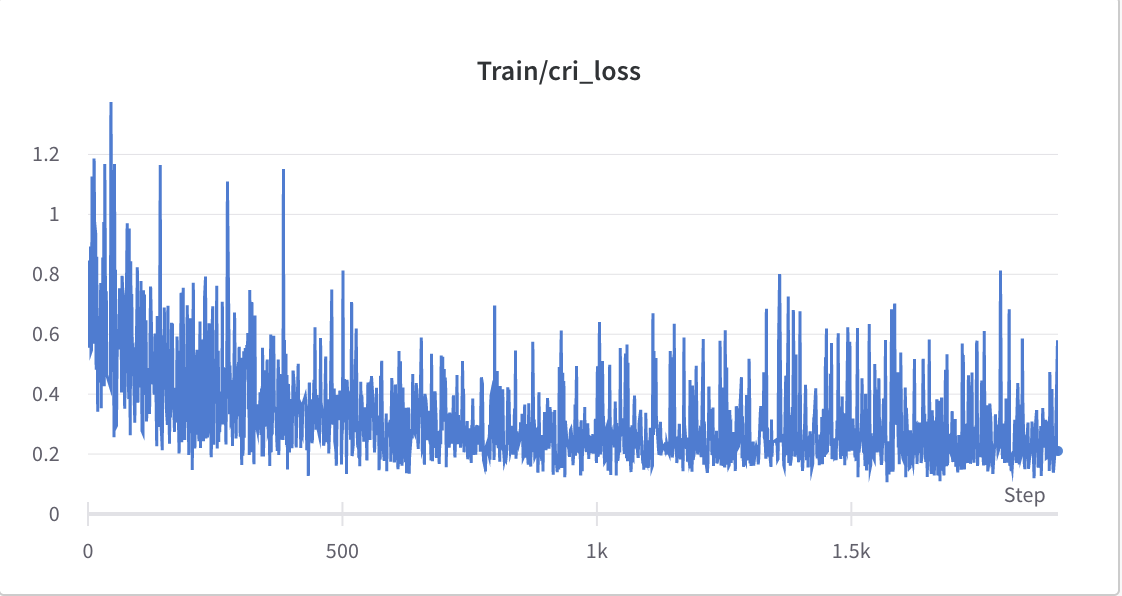
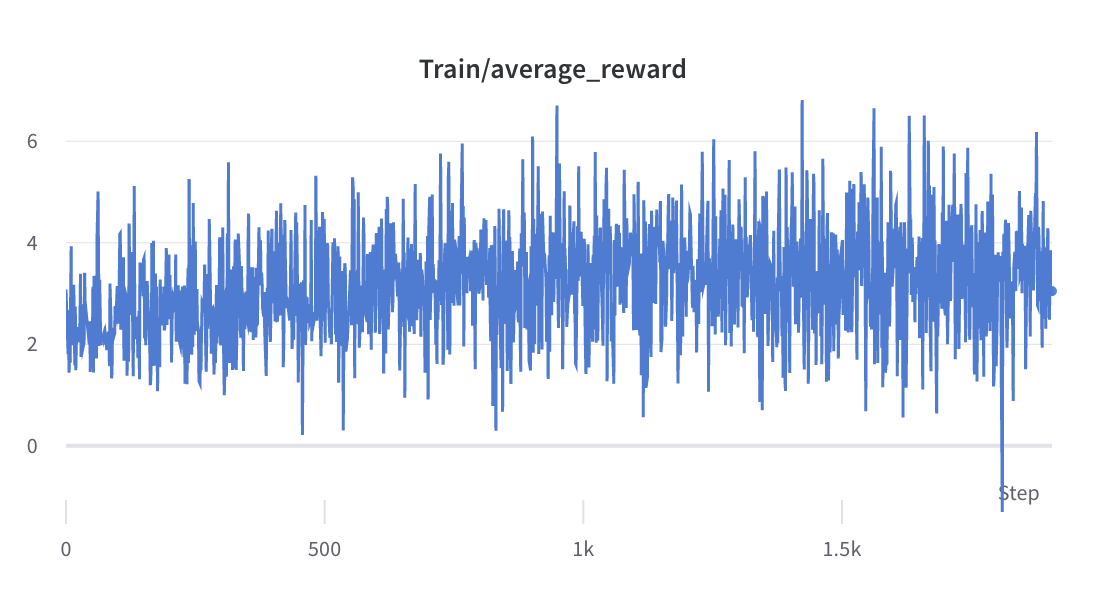
- le processus de formation de l'étape 2
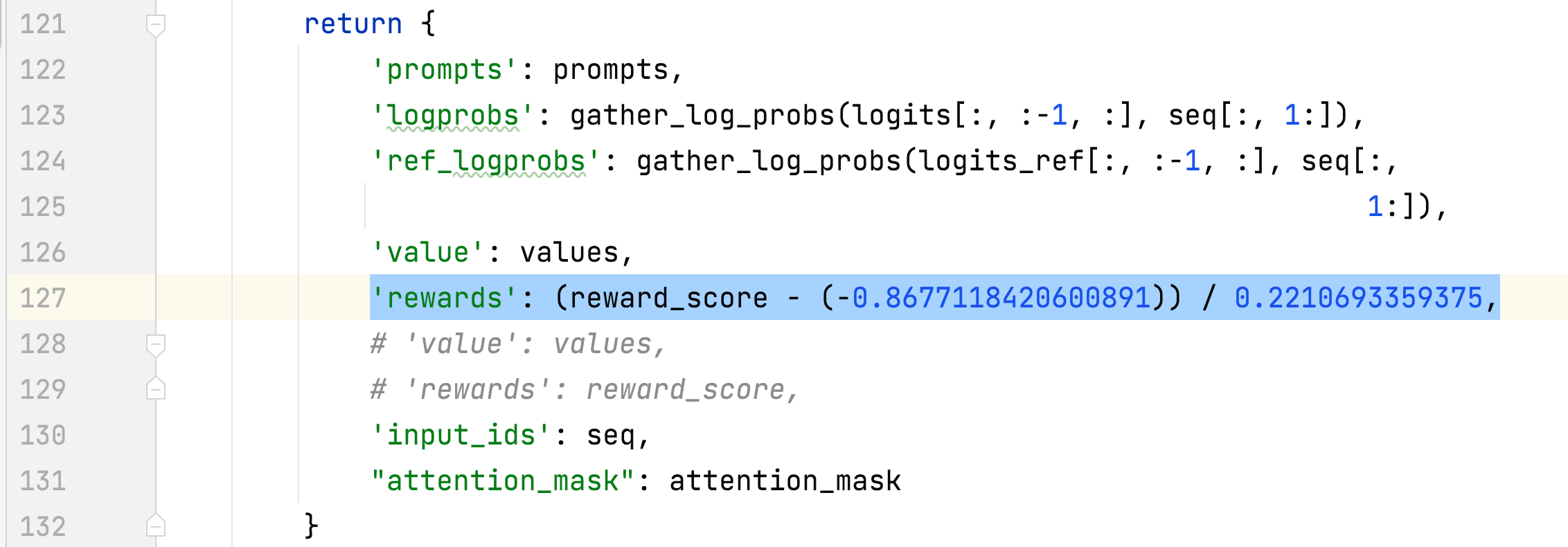
- La moyenne et l'écart type de la récompense des réponses choisies sont collectés et utilisés pour normaliser la récompense à l'étape 3. Dans une expérience, ils sont respectivement de -0,8677118420600891 et 0,2210693359375 et sont utilisés dans le méthodes alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience : 'récompenses' : (reward_score - (-0.8677118420600891)) / 0.2210693359375.
- étape 3 : sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/acteur/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
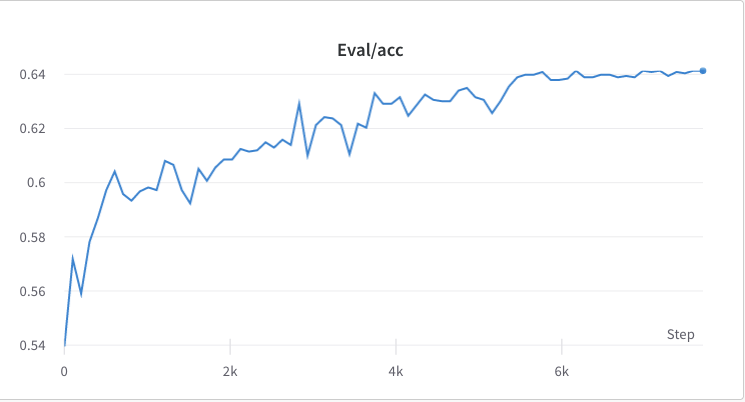
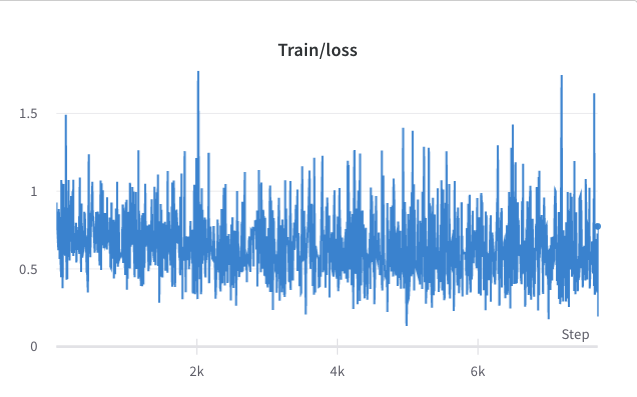
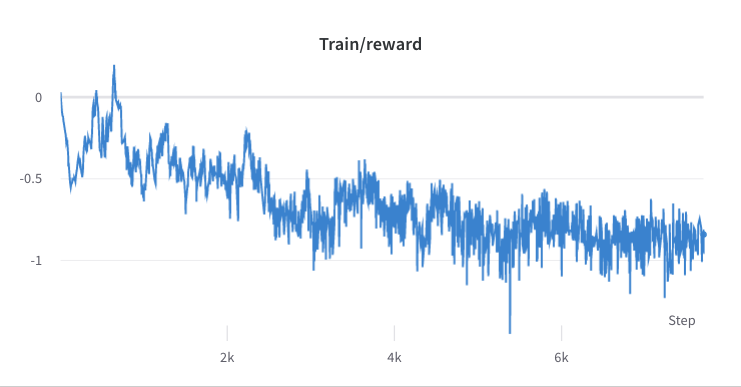
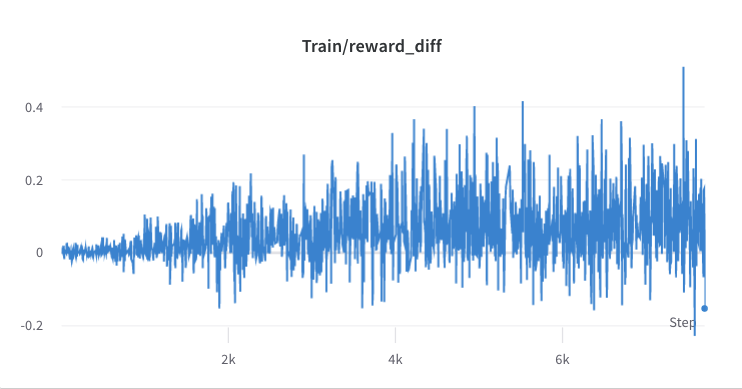
- le processus de formation de l'étape 3
- Inférence
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
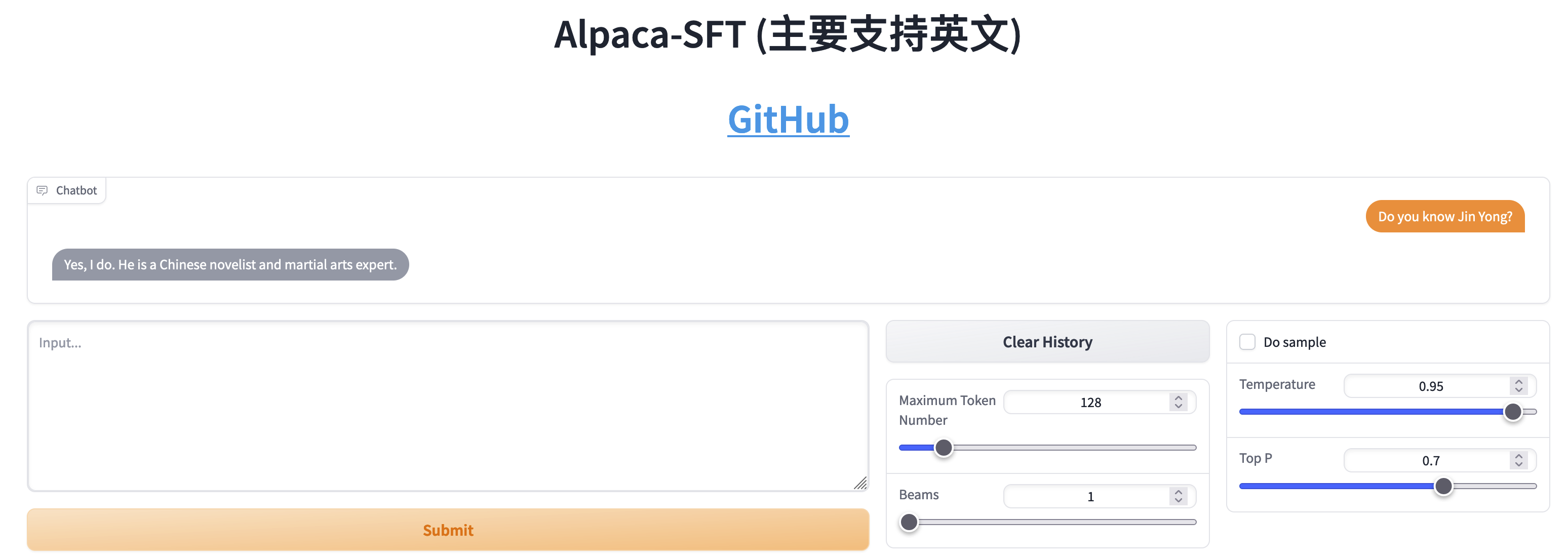
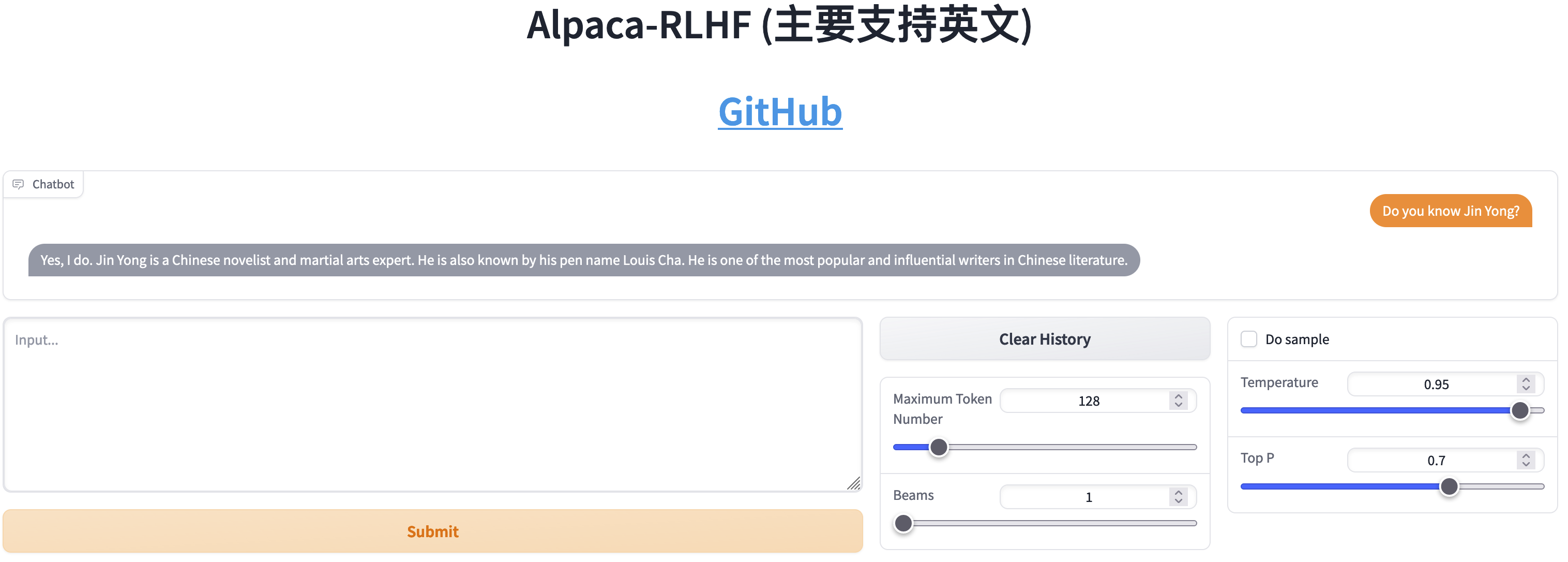
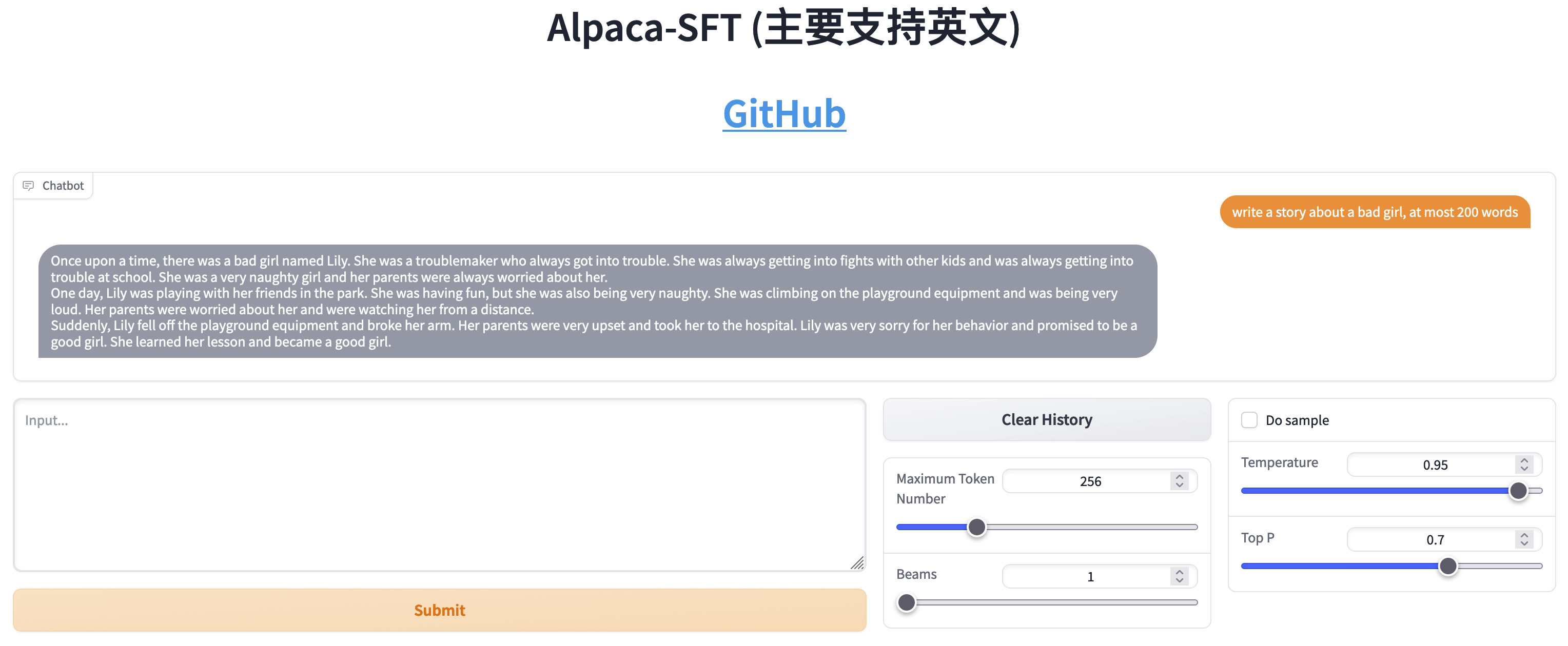
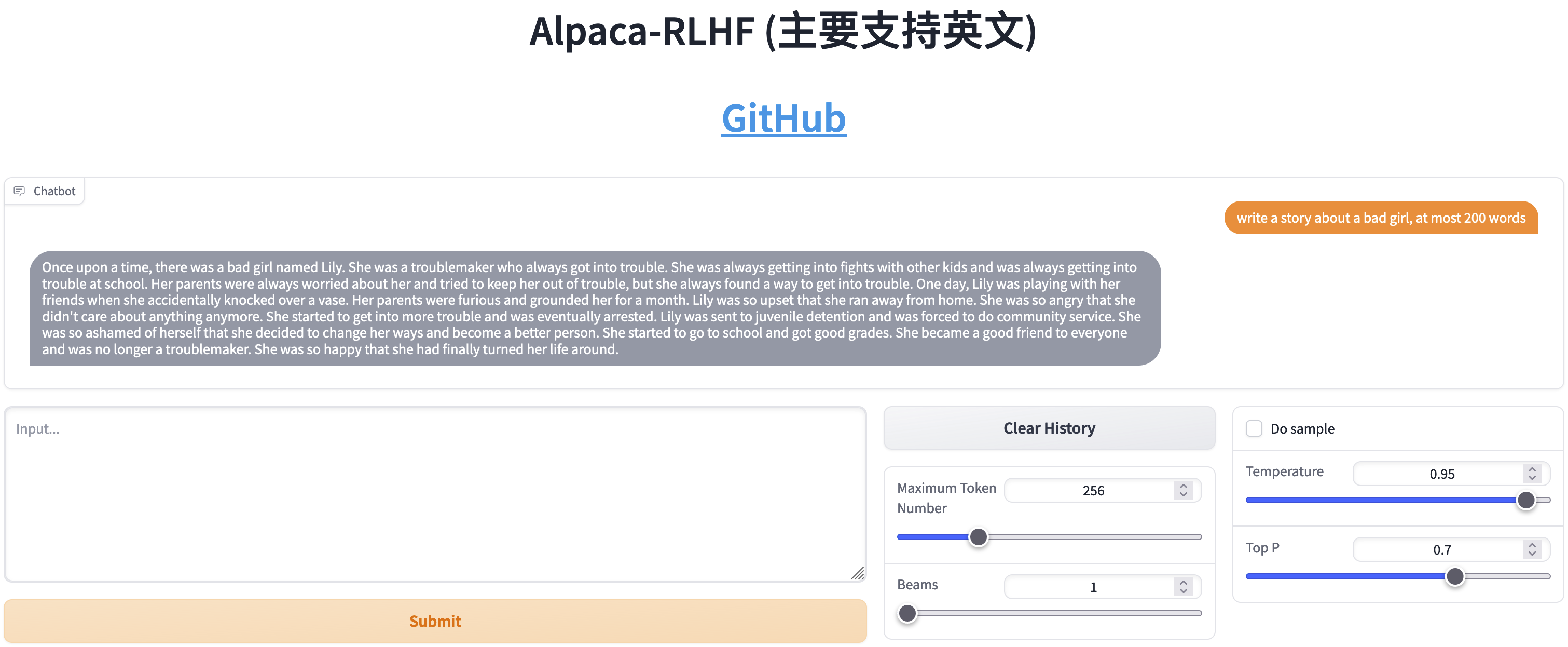
Comparaison entre SFT et RLHF
- Chat
- Écrire des histoires
Références
Articles
- 如何正确复现 Instruire GPT / RLHF ?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
Sources
Outils
Ensembles de données
- Ensemble de données sur les préférences humaines de Stanford (SHP)
- HH-RLHF
- hh-rlhf
- Former un assistant utile et inoffensif grâce à l'apprentissage par renforcement à partir de la rétroaction humaine [article]
- Dahoas/statique-hh
- Dahoas/rm-statique
- GPT-4-LLM
- Assistant ouvert
Dépôts associés
- mon-alpaga
- alpaga multi-tours