icl selective annotation
1.0.0
Le code pour l'annotation sélective sur papier améliore les modèles de langage
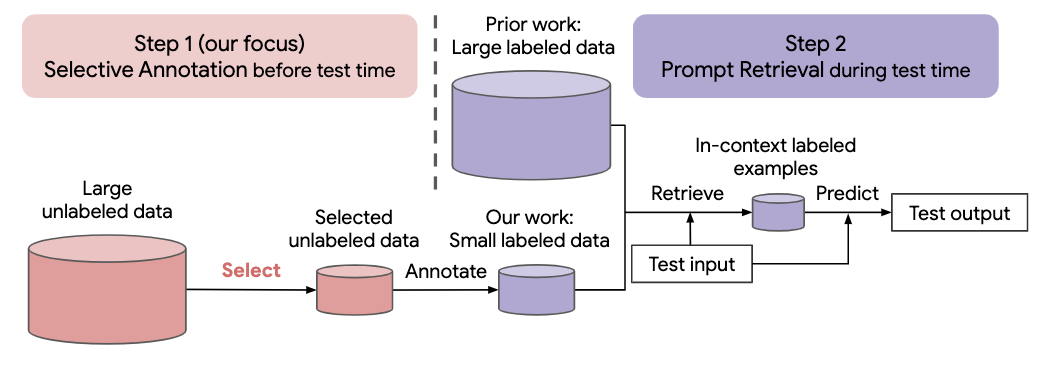
De nombreuses approches récentes des tâches en langage naturel reposent sur les capacités remarquables des grands modèles de langage. Les grands modèles de langage peuvent effectuer un apprentissage en contexte, où ils apprennent une nouvelle tâche à partir de quelques démonstrations de tâches, sans aucune mise à jour des paramètres. Ce travail examine les implications de l'apprentissage en contexte pour la création d'ensembles de données pour de nouvelles tâches en langage naturel. En nous éloignant des méthodes récentes d'apprentissage en contexte, nous formulons un cadre d'annotation efficace en deux étapes : une annotation sélective qui choisit à l'avance un pool d'exemples à annoter à partir de données non étiquetées, suivie d'une récupération rapide qui récupère des exemples de tâches du pool annoté à temps d'essai. Sur la base de ce cadre, nous proposons une méthode d'annotation sélective non supervisée basée sur des graphes, vote-k , pour sélectionner divers exemples représentatifs à annoter. Des expériences approfondies sur 10 ensembles de données (couvrant la classification, le raisonnement de bon sens, le dialogue et la génération de texte/code) démontrent que notre méthode d'annotation sélective améliore considérablement la performance des tâches. En moyenne, vote-k réalise un gain relatif de 12,9 %/11,4 % avec un budget d'annotation de 18/100, par rapport à une sélection aléatoire d'exemples à annoter. Par rapport aux approches de réglage fin supervisé de pointe, il offre des performances similaires avec un coût d'annotation 10 à 100 fois inférieur sur 10 tâches. Nous analysons plus en détail l'efficacité de notre cadre dans divers scénarios : modèles de langage de tailles variables, méthodes d'annotation sélective alternatives et cas où il existe un changement de domaine de données de test. Nous espérons que nos études serviront de base aux annotations de données alors que les grands modèles de langage sont de plus en plus appliqués à de nouvelles tâches.
Exécutez la commande suivante pour cloner ce dépôt
git clone https://github.com/HKUNLP/icl-selective-annotation
Pour établir l'environnement, exécutez ce code dans le shell :
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
Cela créera l'environnement sélective_annotation que nous avons utilisé.
Activez l'environnement en exécutant
conda activate selective_annotation
GPT-J comme modèle d'apprentissage en contexte, DBpedia comme tâche et vote-k comme méthode d'annotation sélective (1 GPU, 40 Go de mémoire)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
Si vous trouvez notre travail utile, veuillez nous citer
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


