Phi2 mini Chinese
1.0.0
Ce projet est un projet expérimental, avec du code open source et des poids de modèle, et moins de données de pré-formation. Si vous avez besoin d'un meilleur petit modèle chinois, vous pouvez vous référer au projet ChatLM-mini-Chinese.
Prudence
Ce projet est un projet expérimental et peut être soumis à des changements majeurs à tout moment, notamment les données d'entraînement, la structure du modèle, la structure des répertoires de fichiers, etc. La première version du modèle et veuillez vérifier tag v1.0
Par exemple, ajouter des points à la fin des phrases, convertir le chinois traditionnel en chinois simplifié, supprimer les signes de ponctuation répétés (par exemple, certains supports de dialogue contiennent beaucoup de "。。。。。" ), la normalisation NFKC Unicode (principalement le problème de la pleine- conversion de la largeur en demi-largeur et données de page Web u3000 xa0) etc.
Pour le processus spécifique de nettoyage des données, veuillez vous référer au projet ChatLM-mini-Chinese.
Ce projet utilise le tokenizer BPE byte level . Il existe deux types de codes de formation fournis pour les segmenteurs de mots : char level et byte level .
Après la formation, le tokenizer se souvient de vérifier s'il existe des symboles spéciaux courants dans le vocabulaire, tels que t , n , etc. Vous pouvez essayer d' encode et decode un texte contenant des caractères spéciaux pour voir s'il peut être restauré. Si ces caractères spéciaux ne sont pas inclus, ajoutez-les via la fonction add_tokens . Utilisez len(tokenizer) pour obtenir la taille du vocabulaire tokenizer.vocab_size ne compte pas les caractères ajoutés via la fonction add_tokens .
La formation Tokenizer consomme beaucoup de mémoire :
L'entraînement de 100 millions de caractères byte level nécessite au moins 32G de mémoire (en fait, 32G ne suffisent pas et l'échange sera déclenché fréquemment. L'entraînement 13600k prend environ une heure).
La formation char level de 650 millions de caractères (ce qui correspond exactement à la quantité de données dans Wikipédia chinois) nécessite au moins 32 Go de mémoire. Étant donné que l'échange est déclenché plusieurs fois, l'utilisation réelle est bien supérieure à 32 Go. La formation 13600K prend environ la moitié d'une mémoire. heure.
Par conséquent, lorsque l'ensemble de données est volumineux (niveau Go), il est recommandé d'échantillonner l'ensemble de données lors de la formation tokenizer .
Utiliser une grande quantité de texte pour une pré-formation non supervisée, principalement en utilisant l'ensemble de données BELLE de bell open source .
Format de l'ensemble de données : une phrase pour un échantillon. Si elle est trop longue, elle peut être tronquée et divisée en plusieurs échantillons.
Pendant le processus de pré-entraînement CLM, les entrées et sorties du modèle sont les mêmes, et lors du calcul de la perte d'entropie croisée, elles doivent être décalées d'un bit ( shift ).
Lors du traitement d'un corpus encyclopédique, il est recommandé d'ajouter la marque '[EOS]' à la fin de chaque entrée. Les autres traitements de corpus sont similaires. La fin d'un doc (qui peut être la fin d'un article ou la fin d'un paragraphe) doit être marquée par '[EOS]' . La marque de départ '[BOS]' peut être ajoutée ou non.
Utilisez principalement l'ensemble de données de bell open source . Merci patronne BELLE.
Le format des données pour la formation SFT est le suivant :
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Lorsque le modèle calculera la perte, il ignorera la partie avant la marque "##回答:" ( "##回答:" sera également ignoré), à partir de la fin de "##回答:" .
N'oubliez pas d'ajouter la marque spéciale de fin de phrase EOS , sinon vous ne saurez pas quand vous arrêter lors du decode du modèle. La marque de début de la phrase BOS peut être remplie ou laissée vide.
Adoptez une méthode d’optimisation des préférences DPO plus simple et économisant davantage de mémoire.
Affinez le modèle SFT en fonction des préférences personnelles. L'ensemble de données doit construire trois colonnes : prompt , chosen et rejected . La colonne rejected contient des données du modèle principal à l'étape sft (par exemple, sft entraîne 4 epoch et prend une ). Modèle de point de contrôle epoch 0,5) Générez, si la similarité entre le rejected généré et chosen est supérieure à 0,9, alors ces données ne seront pas nécessaires.
Il existe deux modèles dans le processus DPO, l'un est le modèle à former et l'autre est le modèle de référence Lors du chargement, il s'agit en fait du même modèle, mais le modèle de référence ne participe pas aux mises à jour des paramètres.
Référentiel de poids modèle huggingface : Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
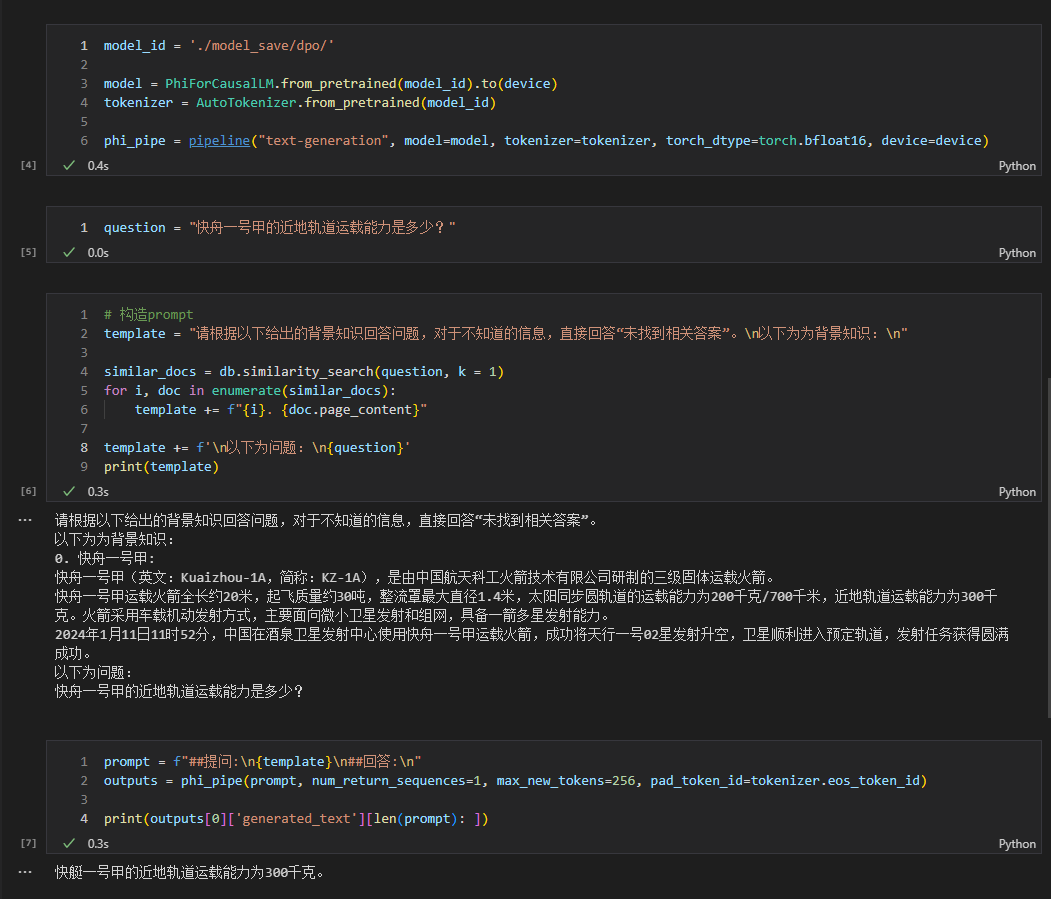
- 另外,如果感冒了,建议及时就医。 Voir rag_with_langchain.ipynb pour le code spécifique.
Si vous pensez que ce projet vous est utile, merci de le citer.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Ce projet n'assume pas les risques et les responsabilités liés à la sécurité des données et aux risques d'opinion publique causés par les modèles et codes open source, ni les risques et responsabilités découlant de tout modèle induit en erreur, abusé, diffusé ou mal exploité.


