reflexion
1.0.0
Ce référentiel contient le code, les démos et les fichiers journaux pour reflexion : Agents linguistiques avec apprentissage par renforcement verbal par Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao.
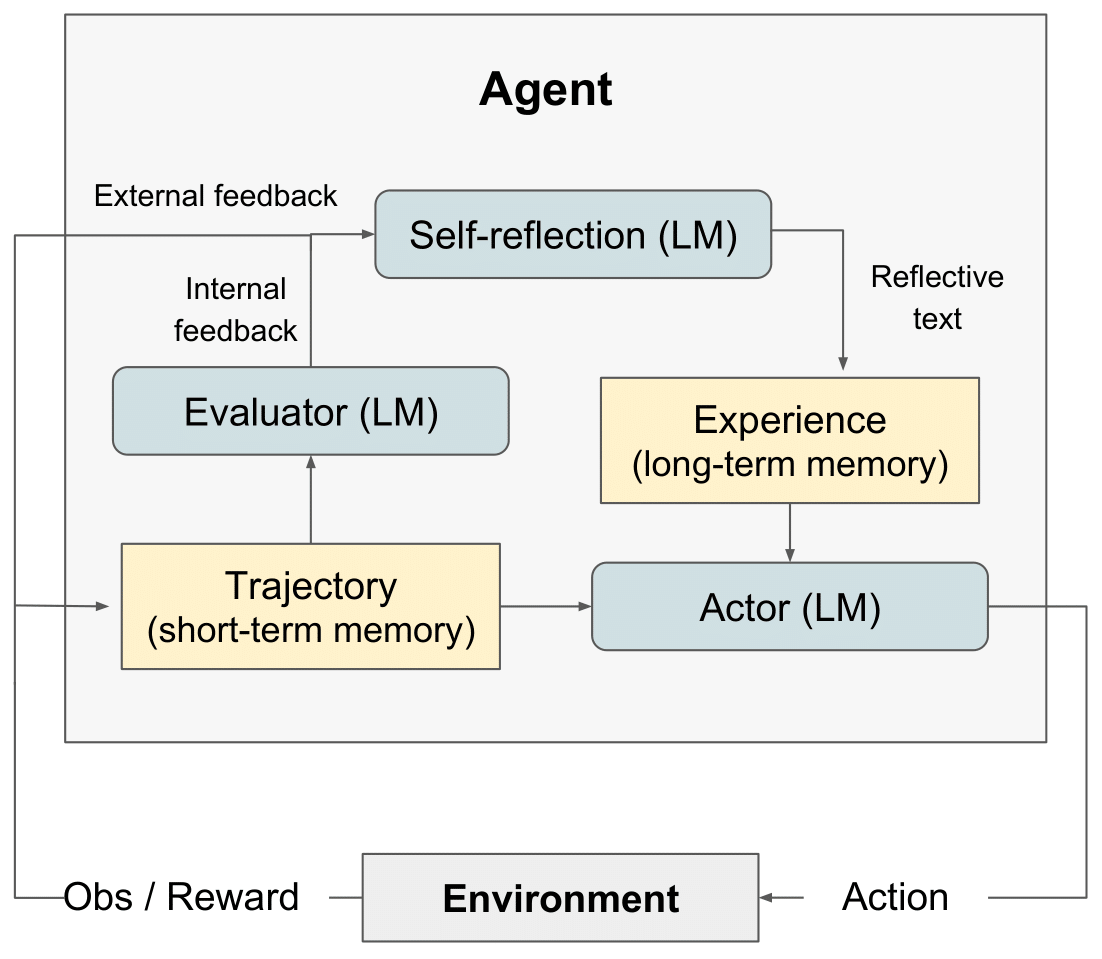 diagramme RL de réflexion" style="max-width: 100%;">
diagramme RL de réflexion" style="max-width: 100%;">
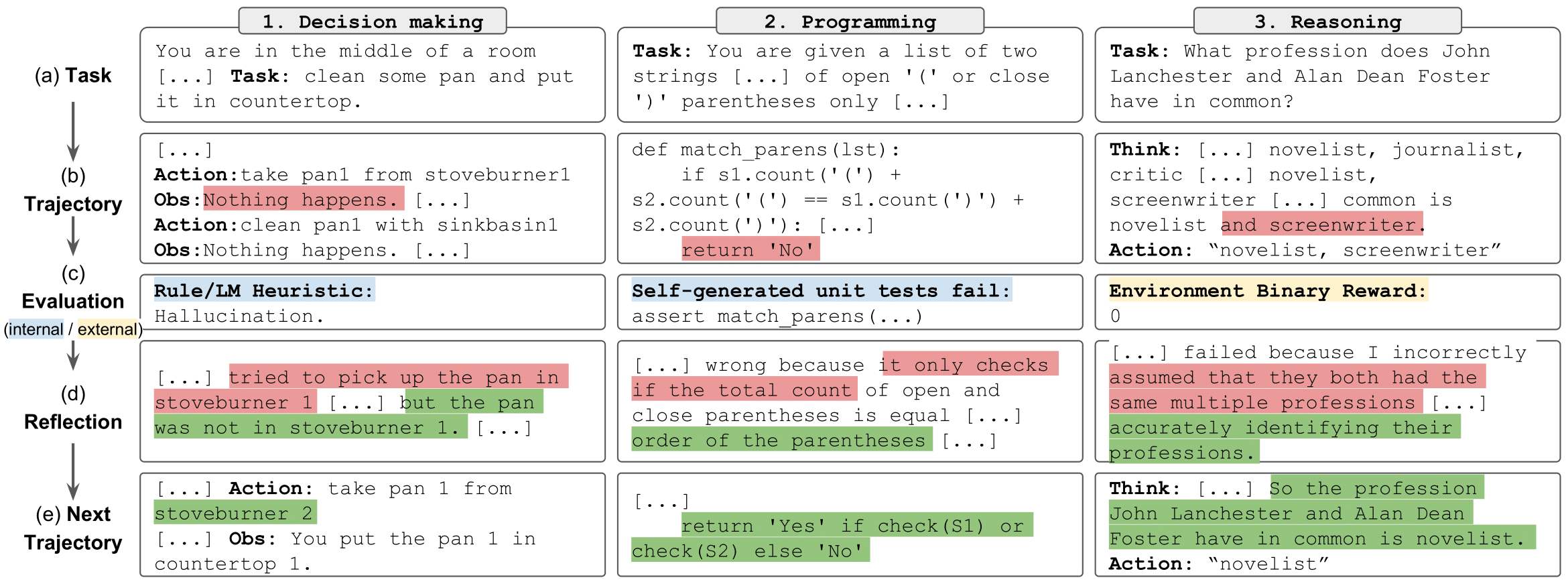 tâches de réflexion" style="max-width: 100%;">
tâches de réflexion" style="max-width: 100%;">
Nous avons publié le LeetcodeHardGym ici
Nous avons fourni un ensemble de cahiers pour exécuter, explorer et interagir facilement avec les résultats des expériences de raisonnement. Chaque expérience consiste en un échantillon aléatoire de 100 questions provenant de l'ensemble de données de distraction HotPotQA. Chaque question de l’échantillon est tentée par un agent avec un type et une stratégie reflexion spécifiques.
Pour commencer :
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY sur votre clé API OpenAI : export OPENAI_API_KEY= < your key > Le type d'agent est déterminé par le notebook que vous choisissez d'exécuter. Les types d'agents disponibles incluent :
ReAct - Agent ReAct
CoT_context - L'agent CoT reçoit un contexte de support sur la question
CoT_no_context - L'agent CoT ne reçoit aucun contexte de support sur la question
Le bloc-notes de chaque type d'agent se trouve dans le répertoire ./hotpot_runs/notebooks .
Chaque cahier permet de préciser la stratégie reflexion à utiliser par les agents. Les stratégies reflexion disponibles, définies dans un Enum , incluent :
reflexion Strategy.NONE - L'agent ne reçoit aucune information sur sa dernière tentative.
reflexion Strategy.LAST_ATTEMPT - L'agent reçoit la trace de son raisonnement de sa dernière tentative sur la question comme contexte.
reflexion Strategy. reflexion - L'agent reçoit comme contexte son auto-réflexion sur la dernière tentative.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - L'agent reçoit à la fois sa trace de raisonnement et son auto-réflexion sur la dernière tentative comme contexte.
Clonez ce dépôt et déplacez-vous vers le répertoire AlfWorld
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Spécifiez les paramètres d'exécution dans ./run_ reflexion .sh . num_trials : nombre d'étapes d'apprentissage itératives num_envs : nombre de paires tâche-environnement par essai run_name : le nom de cette exécution use_memory : utiliser la mémoire persistante pour stocker les auto-réflexions (désactiver pour exécuter une exécution de référence) is_resume : utiliser le répertoire de journalisation pour reprendre une exécution précédente resume_dir : le répertoire de journalisation à partir duquel reprendre l'exécution précédente start_trial_num : en cas de reprise de l'exécution, alors le numéro d'essai à partir duquel démarrer
Exécutez l'essai
./run_ reflexion .sh Les journaux seront envoyés à ./root/<run_name> .
En raison de la nature de ces expériences, il n'est peut-être pas possible pour les développeurs individuels de réexécuter les résultats, car GPT-4 a un accès limité et des frais d'API importants. Toutes les analyses de l'article et les résultats supplémentaires sont enregistrés dans ./alfworld_runs/root pour la prise de décision, ./hotpotqa_runs/root pour le raisonnement et ./programming_runs/root pour la programmation.
Consultez le code pour le code original ici
Lire un article de blog ici
Découvrez une implémentation intéressante de prédiction de type ici : OpenTau
Pour toutes questions, contactez [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

