LLaMA LoRA Tuner
v0.0.20230421
Faciliter l'évaluation et le réglage fin des modèles LLaMA avec adaptation de bas rang (LoRA).
Mise à jour :
Sur la branche
dev, il existe une nouvelle interface utilisateur de chat et une nouvelle configuration du mode démo comme moyen simple et facile de démontrer de nouveaux modèles.Cependant, la nouvelle version ne dispose pas encore de fonctionnalité de réglage fin et n'est pas rétrocompatible car elle utilise une nouvelle façon de définir la façon dont les modèles sont chargés, ainsi qu'un nouveau format de modèles d'invite (de LangChain).
Pour plus d'informations, voir : #28.
LLM.Tuner.Chat.UI.en.Demo.Mode.mp4
Voir une démo sur Hugging Face * Sert uniquement à la démonstration de l'interface utilisateur. Pour essayer la formation ou la génération de texte, exécutez sur Colab.
Opérationnel en 1 clic dans Google Colab avec un environnement d'exécution GPU standard.
Charge et stocke les données dans Google Drive.
Évaluez différents modèles LLaMA LoRA stockés dans votre dossier ou depuis Hugging Face. 
Basculez entre les modèles de base tels que decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b ou EleutherAI/pythia-6.9b .
Affinez les modèles LLaMA avec différents modèles d'invite et formats d'ensemble de données de formation. 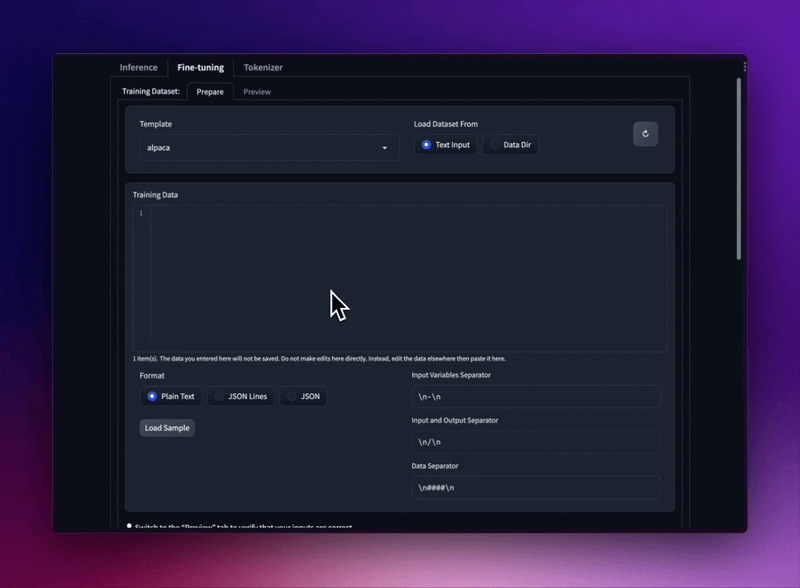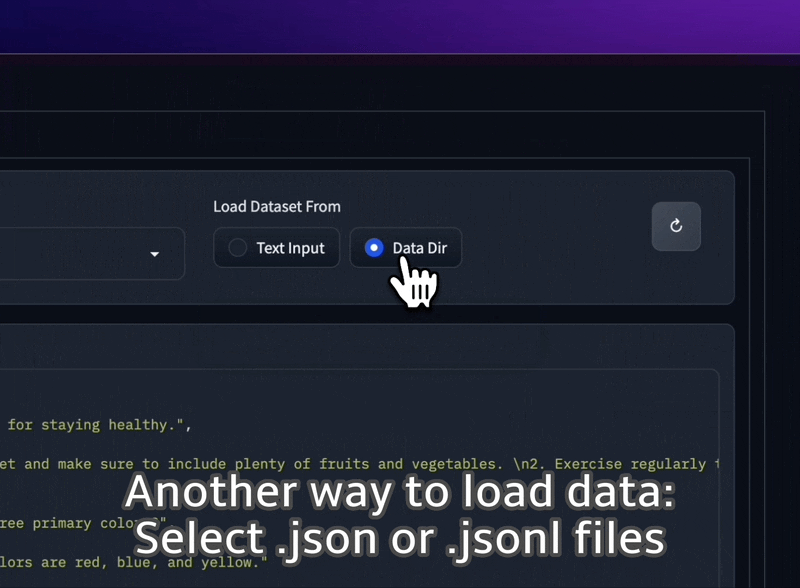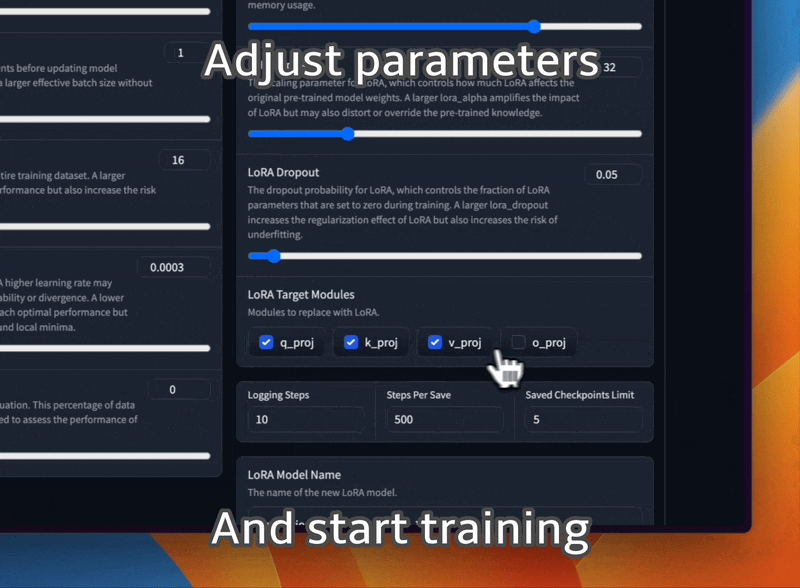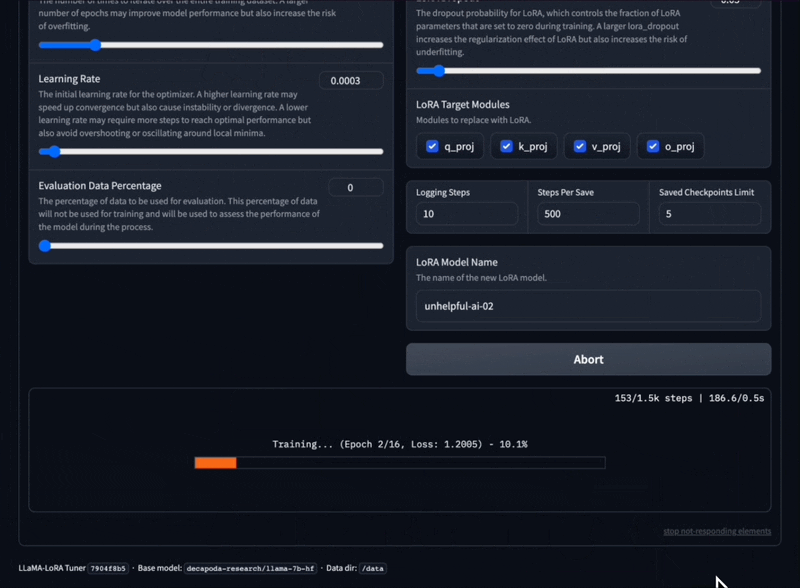
Chargez des ensembles de données JSON et JSONL à partir de votre dossier, ou collez même du texte brut directement dans l'interface utilisateur.
Prend en charge le format Stanford Alpaca seed_tasks, alpaca_data et OpenAI « invite »-« achèvement ».
Utilisez des modèles d’invite pour garder votre ensemble de données SEC.
Il existe différentes manières d'exécuter cette application :
Exécuter sur Google Colab : Le moyen le plus simple de commencer, tout ce dont vous avez besoin est un compte Google. Le temps d'exécution GPU standard (gratuit) est suffisant pour exécuter la génération et l'entraînement avec une taille de micro-lot de 8. Cependant, la génération de texte et l'entraînement sont beaucoup plus lents que sur d'autres services cloud, et Colab peut mettre fin à l'exécution en cas d'inactivité lors de l'exécution de tâches longues.
Exécuter sur un service cloud via SkyPilot : Si vous disposez d'un compte de service cloud (Lambda Labs, GCP, AWS ou Azure), vous pouvez utiliser SkyPilot pour exécuter l'application sur un service cloud. Un bucket cloud peut être monté pour préserver vos données.
Exécuter localement : Dépend du matériel dont vous disposez.
Voir la vidéo pour des instructions étape par étape.
Ouvrez ce bloc-notes Colab et sélectionnez Runtime > Tout exécuter ( ⌘/Ctrl+F9 ).
Vous serez invité à autoriser l'accès à Google Drive, car Google Drive sera utilisé pour stocker vos données. Consultez la section "Config"/"Google Drive" pour les paramètres et plus d'informations.
Après environ 5 minutes d'exécution, vous verrez l'URL publique dans la sortie de la section "Lancer"/"Démarrer Gradio UI " (comme Running on public URL: https://xxxx.gradio.live ). Ouvrez l'URL dans votre navigateur pour utiliser l'application.
Après avoir suivi le guide d'installation de SkyPilot, créez un .yaml pour définir une tâche d'exécution de l'application :
# llm-tuner.yamlresources : accélérateurs : A10:1 # 1x GPU NVIDIA A10, environ 0,6 US$/h sur Lambda Cloud. Exécutez `sky show-gpus` pour les types de GPU pris en charge et `sky show-gpus [GPU_NAME]` pour les informations détaillées d'un type de GPU.
cloud : lambda # Facultatif ; s'il est laissé de côté, SkyPilot choisira automatiquement le cloud.file_mounts le moins cher : # Montez un stockage cloud prédéfini qui sera utilisé comme répertoire de données.
# (pour stocker les ensembles de données d'entraînement des modèles formés)
# Voir https://skypilot.readthedocs.io/en/latest/reference/storage.html pour plus de détails.
/data:name: llm-tuner-data # Assurez-vous que ce nom est unique ou que vous possédez ce bucket. S'il n'existe pas, SkyPilot essaiera de créer un bucket avec ce nom.store : s3 # Peut être l'un des modes [s3, gcs] : MOUNT# Clonez le dépôt LLaMA-LoRA Tuner et installez ses dépendances.setup : | conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # Clonez le dépôt LLaMA-LoRA Tuner et installez ses dépendances [ ! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo 'Installation des dépendances...' pip install -r llm_tuner/requirements.lock.txt # Facultatif : installer wandb sur activer la journalisation dans Weights & Biases pip install wandb # Facultatif : corrigez les bits et octets pour contourner l'erreur "libbitsandbytes_cpu.so : symbole non défini : cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'Correction de bitsandbytes pour la prise en charge GPU...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo 'Dépendances installées.' # Facultatif : installez et configurez Cloudflare Tunnel pour exposer l'application à Internet avec un nom de domaine personnalisé [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Installing Cloudflare" && curl -L --output cloudflared.deb https : //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo cloudflared désinstallation du service || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # Facultatif : les modèles de pré-téléchargement echo "Pré-téléchargement des modèles de base pour ne pas avoir à attendre pendant longtemps une fois que l'application est prête..." python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# Démarrez l'application. `hf_access_token`, `wandb_api_key` et `wandb_project` sont facultatifs.run : | conda active llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='Atlantique/Reykjavik' --base_model= 'decapoda-research/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --shareLancez ensuite un cluster pour exécuter la tâche :
sky launch -c llm-tuner llm-tuner.yaml
-c ... est un indicateur facultatif pour spécifier un nom de cluster. S'il n'est pas spécifié, SkyPilot en générera automatiquement un.
Vous verrez l'URL publique de l'application dans le terminal. Ouvrez l'URL dans votre navigateur pour utiliser l'application.
Notez que quitter sky launch ne fera que quitter le streaming des journaux et n'arrêtera pas la tâche. Vous pouvez utiliser sky queue --skip-finished pour voir l'état des tâches en cours d'exécution ou en attente, sky logs <cluster_name> <job_id> se reconnectent au streaming des journaux et sky cancel <cluster_name> <job_id> pour arrêter une tâche.
Lorsque vous avez terminé, exécutez sky stop <cluster_name> pour arrêter le cluster. Pour mettre fin à un cluster à la place, exécutez sky down <cluster_name> .
N'oubliez pas d'arrêter ou d'arrêter le cluster lorsque vous avez terminé pour éviter d'encourir des frais inattendus. Exécutez sky cost-report pour voir le coût de vos clusters.
Pour vous connecter à la machine cloud, exécutez ssh <cluster_name> , tel que ssh llm-tuner .
Si sshfs est installé sur votre ordinateur local, vous pouvez monter le système de fichiers de la machine cloud sur votre ordinateur local en exécutant une commande comme la suivante :
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner conda active llm-tuner
pip install -r exigences.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlantique/Reykjavik' --share
Vous verrez les URL locales et publiques de l'application dans le terminal. Ouvrez l'URL dans votre navigateur pour utiliser l'application.
Pour plus d'options, consultez python app.py --help .
Pour tester l'interface utilisateur sans charger le modèle de langage, utilisez l'indicateur --ui_dev_mode :
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Pour utiliser le rechargement automatique de Gradio, un fichier
config.yamlest requis car les arguments de ligne de commande ne sont pas pris en charge. Il existe un exemple de fichier pour commencer :cp config.yaml.sample config.yaml. Ensuite, exécutez simplementgradio app.py.
Voir la vidéo sur YouTube.
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
À confirmer


