machine learning experiments
1.0.0
?? L'UKRAINE EST ATTAQUÉE PAR L'ARMÉE RUSSE. DES CIVILS SONT TUÉS. LES ZONES RÉSIDENTIELLES SONT BOMBÉES.
- Aidez l’Ukraine via :
- Fondation caritative Serhiy Prytula
- Fondation caritative Come Back Alive
- Banque nationale d'Ukraine
- Plus d’informations sur war.ukraine.ua et le ministère des Affaires étrangères d’Ukraine
Il s'agit d'une collection d'expériences interactives d'apprentissage automatique. Chaque expérience comprend ?️ un notebook Jupyter/Colab (pour voir comment un modèle a été formé) et ? page de démonstration (pour voir un modèle en action directement dans votre navigateur).
Vous pourriez également être intéressé par GPT fait maison • JS
️ Ce référentiel contient des expériences d'apprentissage automatique et non un code et des modèles prêts à la production, réutilisables, optimisés et affinés. Il s’agit plutôt d’un bac à sable ou d’un terrain de jeu pour apprendre et essayer différentes approches, algorithmes et ensembles de données d’apprentissage automatique. Les modèles peuvent ne pas fonctionner correctement et il existe une possibilité de surajustement/sous-ajustement.
La plupart des modèles de ces expériences ont été entraînés à l'aide de TensorFlow 2 avec le support Keras.
L'apprentissage supervisé, c'est lorsque vous avez des variables d'entrée X et une variable de sortie Y et que vous utilisez un algorithme pour apprendre la fonction de mappage de l'entrée à la sortie : Y = f(X) . L'objectif est de si bien approximer la fonction de mappage que lorsque vous disposez de nouvelles données d'entrée X , vous pouvez prédire les variables de sortie Y pour ces données. C'est ce qu'on appelle l'apprentissage supervisé car le processus d'apprentissage d'un algorithme à partir de l'ensemble de données de formation peut être considéré comme un enseignant supervisant le processus d'apprentissage.
Un perceptron multicouche (MLP) est une classe de réseau neuronal artificiel à action directe (ANN). Les perceptrons multicouches sont parfois appelés réseaux neuronaux « vanille » (composés de plusieurs couches de perceptrons), surtout lorsqu'ils ont une seule couche cachée. Il peut distinguer les données qui ne sont pas linéairement séparables.
| Expérience | Démo modèle et formation | Balises | Ensemble de données | |
|---|---|---|---|---|
 | Reconnaissance de chiffres manuscrits (MLP) | MLP | MNIST | |
 | Reconnaissance de croquis manuscrits (MLP) | MLP | Dessin rapide |
Un réseau de neurones convolutifs (CNN ou ConvNet) est une classe de réseaux de neurones profonds, le plus souvent appliqué à l'analyse d'images visuelles (photos, vidéos). Ils sont utilisés pour détecter et classer des objets sur des photos et des vidéos, pour le transfert de style, la reconnaissance faciale, l'estimation de pose, etc.
| Expérience | Démo modèle et formation | Balises | Ensemble de données | |
|---|---|---|---|---|
 | Reconnaissance de chiffres manuscrits (CNN) | CNN | MNIST | |
 | Reconnaissance de croquis manuscrits (CNN) | CNN | Dessin rapide | |
 | Pierre Papier Ciseaux (CNN) | CNN | RPS | |
 | Pierre Papier Ciseaux (MobilenetV2) | MobileNetV2 , Transfer learning , CNN | RPS, ImageNet | |
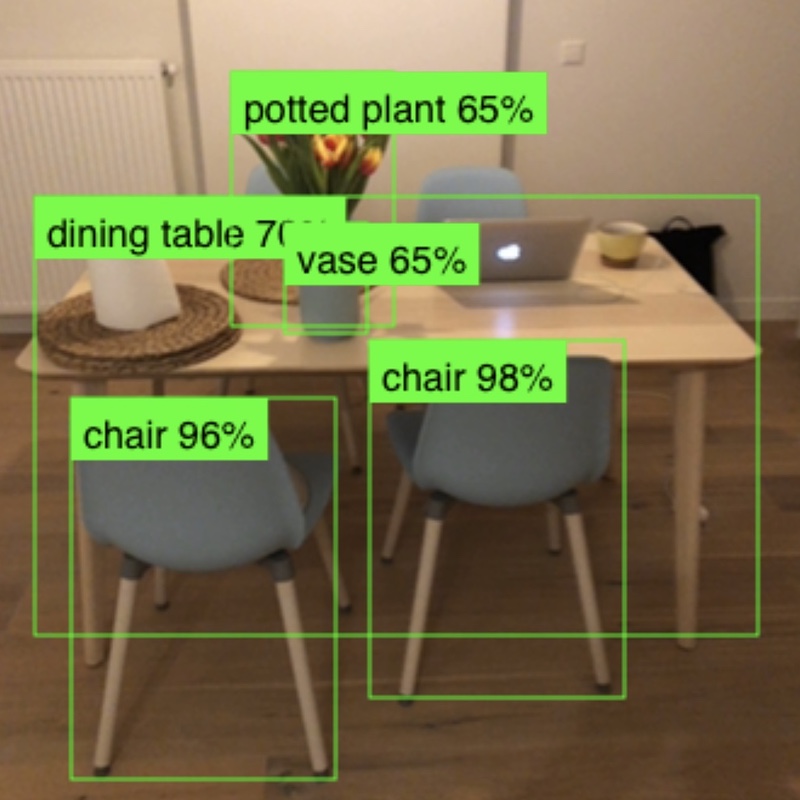 | Détection d'objets (MobileNetV2) | MobileNetV2 , SSDLite , CNN | COCO | |
 | Classification des images (MobileNetV2) | MobileNetV2 , CNN | ImageNet |
Un réseau neuronal récurrent (RNN) est une classe de réseaux neuronaux profonds, le plus souvent appliqué aux données basées sur des séquences telles que la parole, la voix, le texte ou la musique. Ils sont utilisés pour la traduction automatique, la reconnaissance vocale, la synthèse vocale, etc.
| Expérience | Démo modèle et formation | Balises | Ensemble de données | |
|---|---|---|---|---|
 | Somme des nombres (RNN) | LSTM , Sequence-to-sequence | Généré automatiquement | |
 | Génération de texte Shakespeare (RNN) | LSTM , Character-based RNN | Shakespeare | |
 | Génération de texte Wikipédia (RNN) | LSTM , Character-based RNN | Wikipédia | |
 | Génération de recettes (RNN) | LSTM , Character-based RNN | Coffret recettes |
L'apprentissage non supervisé se produit lorsque vous n'avez que des données d'entrée X et aucune variable de sortie correspondante. L'objectif de l'apprentissage non supervisé est de modéliser la structure ou la distribution sous-jacente des données afin d'en apprendre davantage sur les données. C’est ce qu’on appelle l’apprentissage non supervisé car contrairement à l’apprentissage supervisé ci-dessus, il n’y a pas de bonnes réponses et il n’y a pas d’enseignant. Les algorithmes sont laissés à eux-mêmes pour découvrir et présenter la structure intéressante des données.
Un réseau contradictoire génératif (GAN) est une classe de cadres d'apprentissage automatique dans lesquels deux réseaux de neurones s'affrontent dans un jeu. Deux modèles sont formés simultanément par un processus contradictoire. Par exemple, un générateur (« l’artiste ») apprend à créer des images qui semblent réelles, tandis qu’un discriminateur (« le critique d’art ») apprend à distinguer les vraies images des fausses.
| Expérience | Démo modèle et formation | Balises | Ensemble de données | |
|---|---|---|---|---|
 | Génération de vêtements (DCGAN) | DCGAN | Mode MNIST |
# Create "experiments" environment (from the project root folder).
python3 -m venv .virtualenvs/experiments
# Activate environment.
source .virtualenvs/experiments/bin/activate
# or if you use Fish...
source .virtualenvs/experiments/bin/activate.fish Pour quitter un environnement, exécutez deactivate .
# Upgrade pip and setuptools to the latest versions.
pip install --upgrade pip setuptools
# Install packages
pip install -r requirements.txt Pour installer de nouveaux packages, exécutez pip install package-name . Pour ajouter de nouveaux packages aux exigences, exécutez pip freeze > requirements.txt .
Pour jouer avec les notebooks Jupyter et voir comment les modèles ont été formés, vous devez lancer un serveur Jupyter Notebook.
# Launch Jupyter server.
jupyter notebook Jupyter sera disponible localement sur http://localhost:8888/ . Les blocs-notes contenant des expériences peuvent être trouvés dans le dossier experiments .
L'application de démonstration est réalisée sur React au moyen de create-react-app.
# Switch to demos folder from project root.
cd demos
# Install all dependencies.
yarn install
# Start demo server on http.
yarn start
# Or start demo server on https (for camera access in browser to work on localhost).
yarn start-https Les démos seront disponibles localement sur http://localhost:3000/ ou sur https://localhost:3000/ .
L'environnement converter est utilisé pour convertir les modèles formés au cours des expériences du format .h5 Keras vers des formats compréhensibles Javascript (formats tfjs_layers_model ou tfjs_graph_model avec les fichiers .json et .bin ) pour une utilisation ultérieure avec TensorFlow.js dans l'application de démonstration.
# Create "converter" environment (from the project root folder).
python3 -m venv .virtualenvs/converter
# Activate "converter" environment.
source .virtualenvs/converter/bin/activate
# or if you use Fish...
source .virtualenvs/converter/bin/activate.fish
# Install converter requirements.
pip install -r requirements.converter.txt La conversion des modèles keras aux formats tfjs_layers_model / tfjs_graph_model se fait par tfjs-converter :
Par exemple:
tensorflowjs_converter --input_format keras
./experiments/digits_recognition_mlp/digits_recognition_mlp.h5
./demos/public/models/digits_recognition_mlp
️ Convertir les modèles en formats JS compréhensibles et les charger directement dans le navigateur n'est peut-être pas une bonne pratique car dans ce cas, l'utilisateur peut avoir besoin de charger des dizaines ou des centaines de mégaoctets de données dans le navigateur, ce qui n'est pas efficace. Normalement, le modèle est servi depuis le back-end (c'est-à-dire TensorFlow Extended) et au lieu de tout charger dans le navigateur, l'utilisateur effectuera une requête HTTP légère pour effectuer une prédiction. Mais comme l'application de démonstration n'est qu'une expérience et non une application prête pour la production et par souci de simplicité (pour éviter d'avoir un back-end opérationnel), nous convertissons les modèles en formats compréhensibles JS et les chargeons directement dans le navigateur.
Versions recommandées :
> 3.7.3 .>= 12.4.0 .>= 1.13.0 . Si vous disposez de Python version 3.7.3 vous pourriez rencontrer RuntimeError: dictionary changed size during iteration lors de la tentative d' import tensorflow (voir le problème).


