muse rpc
1.0.0
Introduction : Un framework RPC léger basé sur Connect UDP, un protocole réseau personnalisé (protocole de réponse à une demande simple) et un modèle de réseau Reactor (une boucle par thread + pool de threads) !
C++ 17千级访问dans un seul réacteur esclave et quatre threads de travail !内网穿透dans le cas d'une IP non publique !留言message.Utilisation actuelle :
# 需要提前安装zlib库
# 本人开发环境 GCC 11.3 CMake 3.25 clion ubuntu 22.04
git clone [email protected]:sorise/muse-rpc.git
cd muse-rpc
cmake -S . -B build
cmake --build
cd build
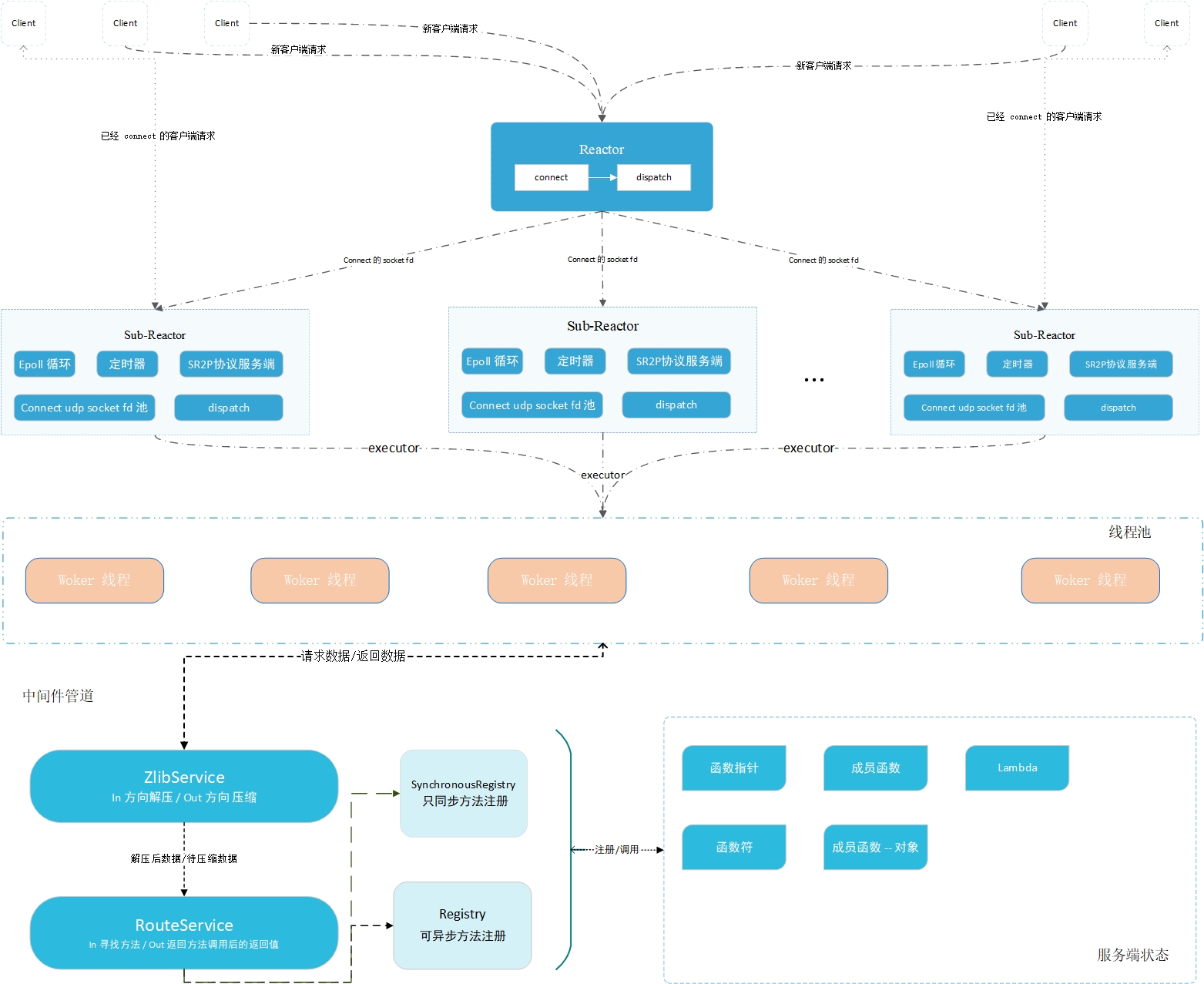
./muse #启动Schéma d'architecture :
Le contenu de la configuration de base est le suivant
int main () {
// 启动配置
// 4 设置 线程池最小线程数
// 4 设置 线程池最大线程数
// 4096 线程池任务缓存队列长度
// 3000ms; 动态线程空闲时间 3 秒
// 日志目录
// 是否将日志打印到控制台
muse::rpc::Disposition::Server_Configure ( 4 , 4 , 4096 , 3000ms, " /home/remix/log " , true );
//绑定方法的例子
Normal normal ( 10 , " remix " ); //用户自定义类
// 同步,意味着这个方法一次只能由一个线程执行,不能多个线程同时执行这个方法
muse_bind_sync ( " normal " , &Normal::addValue, & normal ); //绑定成员函数
muse_bind_async ( " test_fun1 " , test_fun1); // test_fun1、test_fun2 是函数指针
muse_bind_async ( " test_fun2 " , test_fun2);
// 开一个线程启动反应堆,等待请求
// 绑定端口 15000, 启动两个从反应堆,每个反应堆最多维持 1500虚链接
// ReactorRuntimeThread::Asynchronous 指定主反应堆新开一个线程运行,而不是阻塞当前线程
Reactor reactor ( 15000 , 2 , 1500 , ReactorRuntimeThread::Asynchronous);
try {
//开始运行
reactor. start ();
} catch ( const ReactorException &ex){
SPDLOG_ERROR ( " Main-Reactor start failed! " );
}
/*
* 当前线程的其他任务
* */
//程序结束
spdlog::default_logger ()-> flush (); //刷新日志
}Après le démarrage :

Utilisez les macros muse_bind_sync et muse_bind_async . Le premier appelle SynchronousRegistry et le second appelle Registry. Le prototype est le suivant.
# include < iostream >
# include " rpc/rpc.hpp "
using namespace muse ::rpc ;
using namespace muse ::pool ;
using namespace std ::chrono_literals ;
//绑定方法的例子
Normal normal ( 10 , " remix " );
// 绑定类的成员函数、使用 只同步方法 绑定
muse_bind_sync ( " normal " , &Normal::addValue, & normal );
// 绑定函数指针
muse_bind_async ( " test_fun1 " , test_fun1);
// 绑定 lambda 表达式
muse_bind_async ( " lambda test " , []( int val)->int{
printf ( " why call me n " );
return 10 + val;
});Les méthodes d'enregistrement côté serveur nécessitent l'utilisation d'objets Registry et SynchronousRegistry.
Explication de SynchronousRegistry : la valeur est un champ utilisé pour enregistrer le nombre de clients qui ont demandé la méthode addValue. Si 1 000 clients ont demandé addValue et sont enregistrés à l'aide du Registre, la valeur de la valeur peut ne pas être 1 000 car l'accès à la valeur n'est pas thread-safe. enregistré à l'aide de SynchronousRegistry, il doit être 1000.
class Counter {
public:
Counter ():value( 0 ){}
void addValue (){
this -> value ++;
}
private:
long value;
};Méthode d'enregistrement : Les définitions des deux macros sont les suivantes
# define muse_bind_async (...)
Singleton<Registry>()-> Bind (__VA_ARGS__);
//同步方法,一次只能一个线程执行此方法
# define muse_bind_sync (...)
Singleton<SynchronousRegistry>()-> Bind (__VA_ARGS__);Le client utilise l'objet Client, qui renverra un objet Outcome<R> , et la méthode isOK indiquera si le retour est réussi ! Si false est renvoyé, son membre protocolReason indiquera s'il y a une anomalie du réseau, et le membre de réponse indiquera s'il s'agit d'une erreur de demande et de réponse RPC.
# include " rpc/rpc.hpp "
# include " rpc/client/client.hpp "
using namespace muse ::rpc ;
using namespace muse ::timer ;
using namespace std ::chrono_literals ;
int main{
// //启动客户端配置
muse::rpc::Disposition::Client_Configure ();
// MemoryPoolSingleton 返回一个 std::shared_ptr<std::pmr::synchronized_pool_resource>
//你可以自己定一个内存池
//传入 服务器地址和服务端端口号、一个C++ 17 标准内存池
Client remix ( " 127.0.0.1 " , 15000 , MemoryPoolSingleton ());
//调用远程方法
Outcome<std::vector< double >> result = remix. call <std::vector< double >>( " test_fun2 " ,scores);
std::cout << result. value . size () << std::endl;
//调用 无参无返回值方法
Outcome< void > result =remix. call < void >( " normal " );
if (result. isOK ()){
std::printf ( " success n " );
} else {
std::printf ( " failed n " );
}
//调用
auto ri = remix. call < int >( " test_fun1 " , 590 );
std::cout << ri. value << std::endl; // 600
};
Gestion des erreurs : dans des circonstances normales, il vous suffit de vérifier si la méthode isOk est vraie. Si vous avez besoin de connaître les détails de l'erreur, vous pouvez utiliser la méthode suivante. Les deux objets d'énumération FailureReason et RpcFailureReason signalent les erreurs réseau. et erreurs de requête RPC respectivement.
auto resp = remix.call< int >( " test_fun1 " , 590 );
if (resp.isOK()){
//调用成功
std::cout << " request success n " << std::endl; // 600
std::cout << ri. value << std::endl; // 600
} else {
//调用失败
if (resp. protocolReason == FailureReason::OK){
//错误原因是RPC错误
std::printf ( " rpc error n " );
std::cout << resp. response . getReason () << std::endl;
//返回 int 值对应 枚举 RpcFailureReason
} else {
//错误原因是网络通信过程中的错误
std::printf ( " internet error n " );
std::cout << ( short )resp. protocolReason << std::endl; //错误原因
}
}
// resp.protocolReason() 返回 枚举FailureReason
enum class FailureReason : short {
OK, //没有失败
TheServerResourcesExhausted, //服务器资源耗尽,请勿链接
NetworkTimeout, //网络连接超时
TheRunningLogicOfTheServerIncorrect, //服务器运行逻辑错误,返回的报文并非所需
};
// resp.response.getReason() 返回值 是 int
enum class RpcFailureReason : int {
Success = 0 , // 成功
ParameterError = 1 , // 参数错误,
MethodNotExist = 2 , // 指定方法不存在
ClientInnerException = 3 , // 客户端内部异常,请求还没有到服务器
ServerInnerException = 4 , // 服务器内部异常,请求到服务器了,但是处理过程有异常
MethodExecutionError = 5 , // 方法执行错误
UnexpectedReturnValue = 6 , //返回值非预期
};Les requêtes non bloquantes signifient qu'il vous suffit de configurer la tâche de requête et d'enregistrer une fonction de rappel pour traiter les résultats de la requête. Le processus d'envoi est géré par l'objet Transmetteur, de sorte que le thread actuel ne soit pas bloqué pour des raisons de réseau et. Le blocage sera géré en fonction des rappels et peut être utilisé pour gérer un grand nombre de requêtes. Ici, nous avons besoin d'un objet Transmetteur et la tâche d'envoi est définie via TransmetteurEvent !
Remarque : Le nombre de tâches envoyées par un seul émetteur en même temps doit être inférieur à 100. Si le nombre de tâches de requête envoyées dépasse 100, le délai d'attente doit être augmenté. Vous pouvez appeler l'interface suivante pour définir la durée de fonctionnement.
void test_v (){
//启动客户端配置
muse::rpc::Disposition::Client_Configure ();
Transmitter transmitter ( 14500 );
// transmitter.set_request_timeout(1500); //设置请求阶段的等待超时时间
// transmitter.set_response_timeout(2000); //设置响应阶段的等待超时时间
//测试参数
std::vector< double > score = {
100.526 , 95.84 , 75.86 , 99.515 , 6315.484 , 944.5 , 98.2 , 99898.26 ,
9645.54 , 484.1456 , 8974.4654 , 4894.156 , 89 , 12 , 0.56 , 95.56 , 41
};
std::string name {
" asdasd54986198456h487s1as8d7as5d1w877y98j34512g98ad "
" sf3488as31c98aasdasd54986198sdasdasd456h487s1as8d7a "
" s5d1w877y98j34512g98ad "
};
for ( int i = 0 ; i < 1000 ; ++i) {
TransmitterEvent event ( " 127.0.0.1 " , 15000 ); //指定远程IP 、Port
event. call < int >( " read_str " , name,score); //指定方法
event. set_callBack ([](Outcome< int > t){ //设置回调
if (t. isOK ()){
printf ( " OK lambda %d n " , t. value );
} else {
printf ( " fail lambda n " );
}
});
transmitter. send ( std::move (event));
}
//异步启动发射器,将会新开一个线程持续发送
transmitter. start (TransmitterThreadType::Asynchronous);
//停止发射器,这是个阻塞方法,如果发送器还有任务没有处理完,将会等待
transmitter. stop ();
//如果想直接停止可以使用 transmitter.stop_immediately()方法
}Prend en charge la configuration du nombre de threads principaux, du nombre maximum de threads, de la longueur de la file d'attente du cache des tâches et du temps d'inactivité des threads dynamiques !
ThreadPoolSetting::MinThreadCount = 4 ; //设置 核心线程数
ThreadPoolSetting::MaxThreadCount = 4 ; //设置 核心线程数
ThreadPoolSetting::TaskQueueLength = 4096 ; //设置 任务缓存队列长度
ThreadPoolSetting::DynamicThreadVacantMillisecond = 3000ms; //动态线程空闲时间Introduction : Simple Request Response Protocol (protocole SR2P) est un protocole en deux phases spécialement personnalisé pour RPC. Il se divise en deux étapes : requête et réponse sans établir de lien.
Les champs de protocole sont les suivants, l'en-tête du protocole est de 26 octets, l'ordre des octets du champ est big endian et la partie données est small endian. En raison des limitations MTU, la norme MTU du réseau est de 576 et la partie données peut aller jusqu'à 522. octets. Plus Veuillez consulter Protocol.pdf.
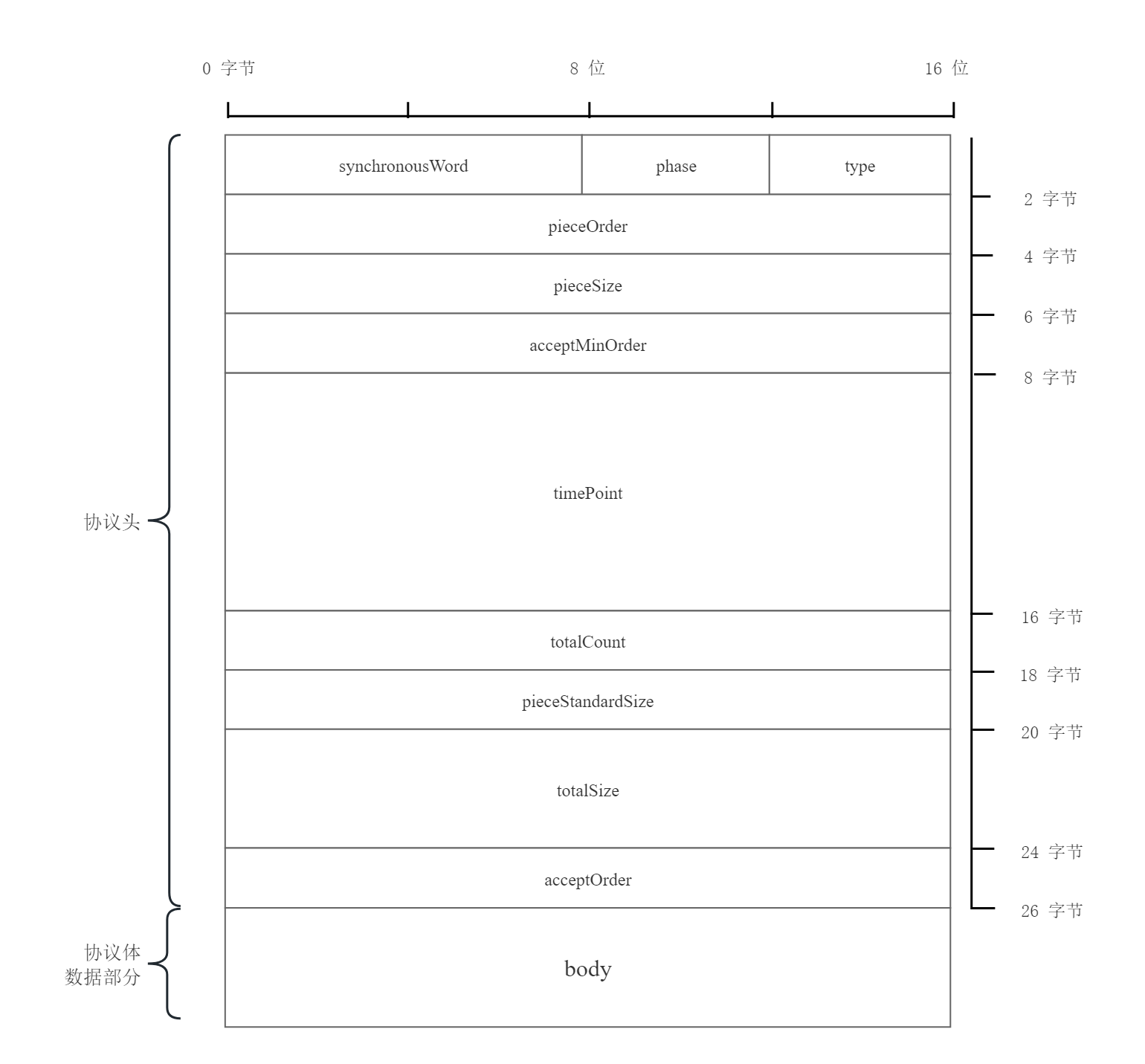
11110000 , un octet.Le protocole SR2P déterminera le nombre de datagrammes générés à chaque fois en fonction de la quantité de données générées. Ce qui suit prend 2 datagrammes à la fois à titre d'exemple. L'organigramme des requêtes dans des circonstances fondamentalement normales.
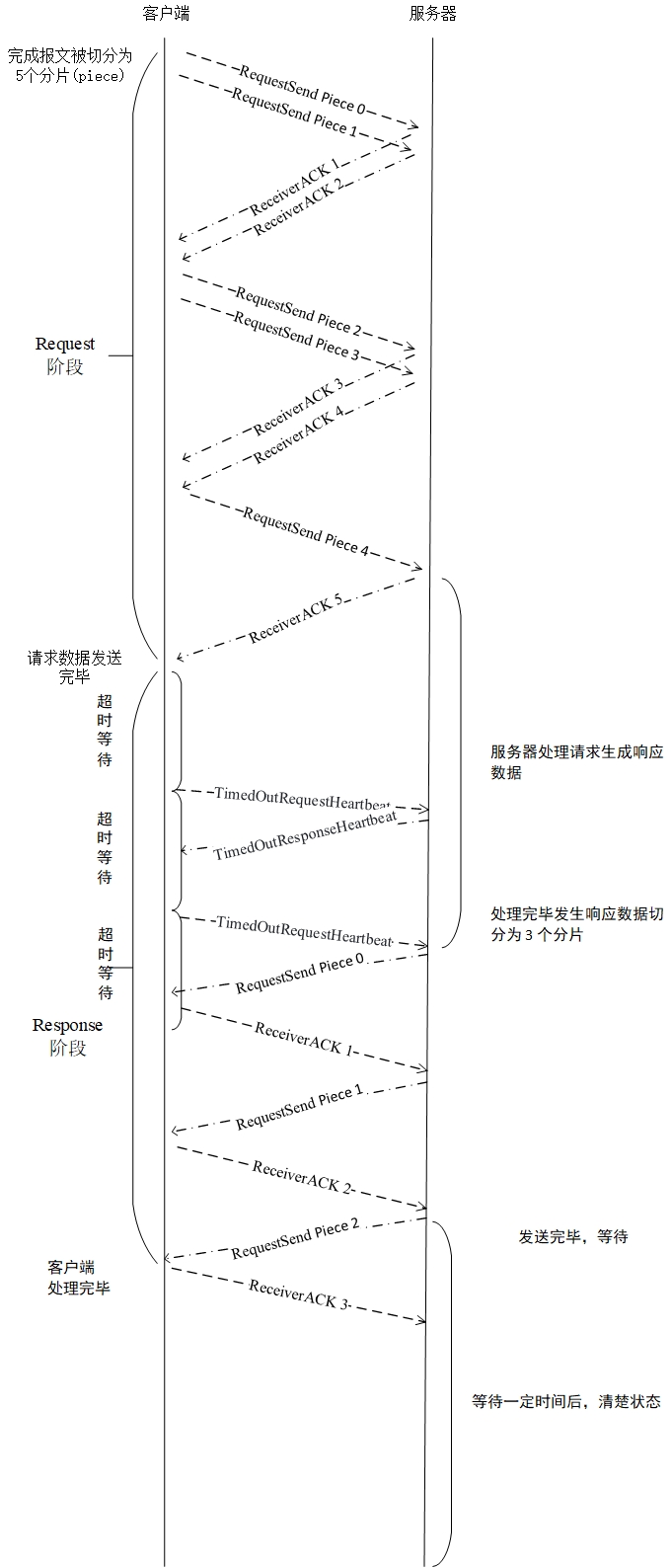
Pour plus de détails sur le processus de traitement d'autres situations, veuillez consulter le document Protocol.pdf


