http connection lifecycle
1.0.0
Table des matières
Lors de l'entretien technique ou autrement, les questions fréquemment posées sont la suivante : que se passe-t-il lorsque vous saisissez une URL dans le navigateur ? Que se passe-t-il dans les coulisses lorsque vous naviguez sur un site Web ? Qu’implique le cycle de vie typique d’une connexion HTTP ? Je répondrai à ces questions au meilleur de mes connaissances.
Avant de plonger dans le processus de connexion, passons en revue le modèle de base OSI (Open Systems Interconnection model). Le modèle OSI est un modèle conceptuel qui standardise la communication entre deux systèmes : l'un d'où provient la requête (le client) et l'autre qui répond à la requête et renvoie une réponse (le serveur). Le tableau ci-dessous montre certaines des caractéristiques importantes de chaque couche.
| Non | Couche | Matériel | Fonction | Protocoles/Applications | Ajouts |
|---|---|---|---|---|---|
| 7 | Application | Serveur/PC | Applications, interface utilisateur | HTTP, SMTP, DNS | En-tête L7 |
| 6 | Présentation | Serveur/PC | Gère les changements de chiffrement et de syntaxe | JPEG, MP3 | En-tête L6 |
| 5 | Session | Serveur/PC | Authentification, autorisations, sessions | Planification SCP et OS | En-tête L5 |
| 4 | Transport | Pare-feu | Livraison de bout en bout, contrôle des erreurs | TCP, UDP | En-tête L4 |
| 3 | Réseau | Routeurs | Adressage réseau, routage, commutation | IP | En-tête L3 |
| 2 | Lien de données | Commutateurs | Adresse physique, détection d'erreurs, flux | Ethernet, relais de trames | En-tête/remorque L2 |
| 1 | Physique | Câbles | Bit transféré sur le réseau physique | EIE/AIT | En-tête L1 |
Dès que vous tapez l'URL dans le navigateur et appuyez sur la touche Entrée/Retour, le navigateur (ou tout client d'ailleurs) analysera l'URL [1] pour en extraire les composants importants. Un exemple d'URL est donné ci-dessous :
https://www.google.com/search?q=cats
Ici, nous recherchons simplement des chats sur Google. À partir de l'URL ci-dessus, https:// est le protocole, google.com est l'hôte sur www (Internet), /search est le paramètre de chemin et ?q=cats est le paramètre de chaîne de requête qui indique que nous interrogeons Google pour les chats [ 2].
Désormais, puisque le navigateur connaît l'hôte qu'il tente d'atteindre, dans ce cas google.com , il tentera d'obtenir ses adresses IP correspondantes. Des domaines comme « .com » ou « .org » ont été créés pour que nous puissions nous en souvenir facilement. Mais pour que le navigateur envoie la demande réelle, disons à google.com, il a besoin de l'adresse IP de l'hôte. La résolution DNS nous aide à obtenir les informations sur l’adresse IP d’un nom de domaine donné. DNS réside sur la couche application (L7) du tableau ci-dessus.
Étapes de la résolution DNS :
$ ipconfig /displaydns sous Windows ou $ log stream --predicate 'process == "mDNSResponder"' --info sous mac/linux..com , .org , etc. sont des noms de domaine de premier niveau. Le nom du TLD renverrait alors l'adresse IP du ou des serveurs de noms faisant autorité.$ dig google.com
; << >> DiG 9.10.6 <<>> google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14345
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 9
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 180 IN A 172.217.164.174
;; AUTHORITY SECTION:
google.com. 60552 IN NS ns1.google.com.
google.com. 60552 IN NS ns2.google.com.
google.com. 60552 IN NS ns3.google.com.
google.com. 60552 IN NS ns4.google.com.
;; ADDITIONAL SECTION:
ns1.google.com. 60438 IN A 216.239.32.10
ns1.google.com. 58273 IN AAAA 2001:4860:4802:32::a
ns2.google.com. 60438 IN A 216.239.34.10
ns2.google.com. 131763 IN AAAA 2001:4860:4802:34::a
ns3.google.com. 163770 IN A 216.239.36.10
ns3.google.com. 60541 IN AAAA 2001:4860:4802:36::a
ns4.google.com. 75597 IN A 216.239.38.10
ns4.google.com. 60541 IN AAAA 2001:4860:4802:38::a
;; Query time: 13 msec
;; SERVER: 10.4.4.10#53(10.4.4.10)
;; WHEN: Mon Jun 24 12:20:50 PDT 2019
;; MSG SIZE rcvd: 303A chaque couche du modèle OSI, les informations sont appelées PDU (Packet Data Unit). Ainsi, les informations au niveau de la couche application sont appelées PDU L7, tandis que les informations au niveau de la couche réseau sont appelées PDU L3. À chaque couche, un en-tête de couche correspondant est ajouté. L'en-tête précède son corps et contient l'adressage et d'autres données nécessaires pour atteindre sa destination prévue. En revanche, les données sont transmises de la couche supérieure vers le bas. Les en-têtes L4, L3 et L2 sont illustrés ci-dessous :
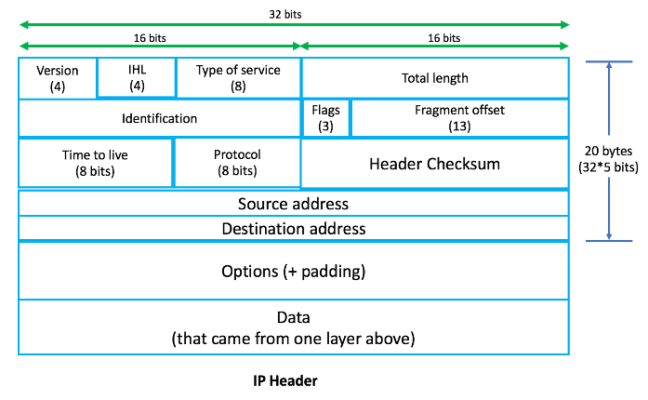
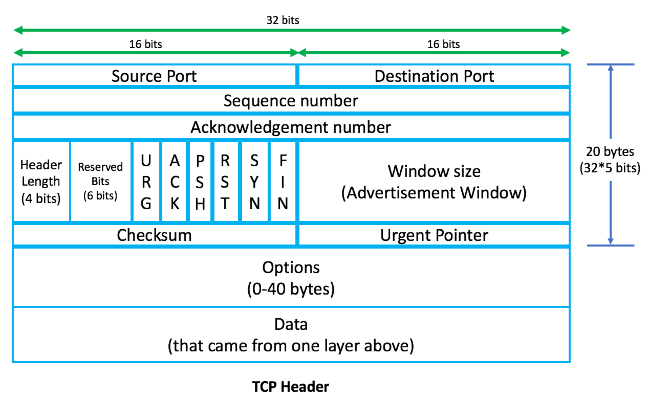
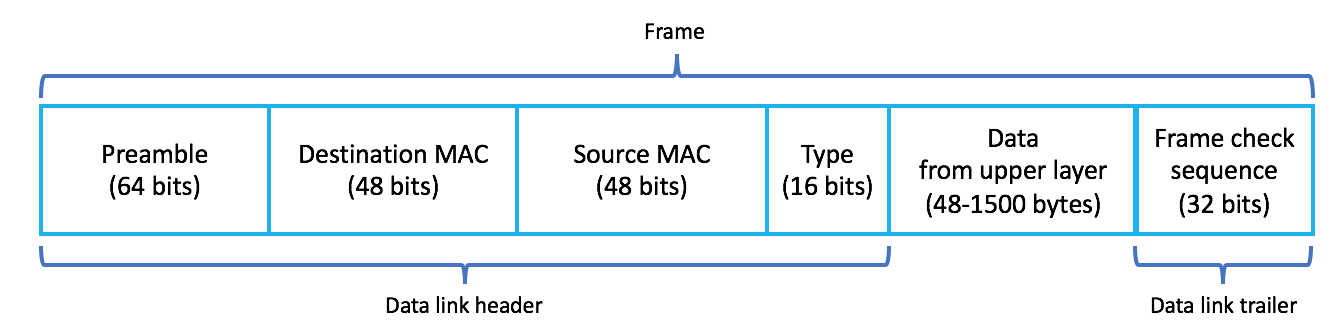
Avant que le paquet ne soit envoyé sur Internet pour finalement atteindre le serveur de domaine Google, il doit d'abord être acheminé via le routeur. Chaque fois qu'un appareil doit se connecter physiquement à un autre appareil (dans ce cas, le routeur local), il a besoin de l'adresse MAC (adresse matérielle) de cet appareil. Mais comment la machine locale sait-elle que le routeur est la route de sortie par défaut ? Ces informations sont acquises via la route par défaut configurée pour chaque interface au sein de la machine locale. Vous pouvez vérifier la route par défaut en utilisant la commande $ ifconfig .
L'adresse IP est utilisée pour localiser un appareil sur le réseau tandis que l'adresse MAC est utilisée pour identifier l'appareil réel. Le protocole ARP est utilisé pour acquérir l'adresse MAC de l'appareil, compte tenu de la connaissance de l'adresse IP. Ici, nous supposerons que la machine requérante a déjà reçu une adresse IP (soit statiquement, soit via le protocole DHCP).
ARP réside sur la couche liaison de données du modèle OSI. Dans ce cas, le navigateur Web exécuté sur la machine locale se connectera au routeur qui est une passerelle vers Internet.
arp -a .Les paquets sont ensuite acheminés vers la route par défaut. Si vous n’avez pas défini d’itinéraire par défaut, ils seront acheminés vers le routeur. Vous pouvez vérifier l'itinéraire par défaut en utilisant la commande
route get default | grep gateway ou netstat -rn sur mac/linux ou ipconfig sur windows.
Par exemple, si vous êtes sur un réseau 192.168.10.0/24 et que vous essayez d'atteindre le réseau Google à 172.217.164.174/24, par exemple lorsque le paquet arrive au routeur, le routeur vérifiera la table de routage et décidera comment acheminer le trafic vers atteindre le réseau de destination. Il enverra donc le paquet à la passerelle spécifiée pour atteindre la destination 172.217.164.174/24.
Connexion entre le client et le serveur ; dans ce cas, votre ordinateur local vers le serveur Google prend de nombreux sauts. Chaque saut est essentiellement un routeur le long du chemin vers la destination. Le routeur permet ici de passer d'un réseau à l'autre. Chaque appareil en transit possède une adresse MAC (adresse matérielle) qui est unique au monde.
Maintenant, la machine locale crée une requête avec l'en-tête L7 (HTTP), l'en-tête L4 (TCP), l'en-tête L3 (IP), l'en-tête L2 (ARP, adresses MAC), la fin L2 (séquence de vérification de trame) et les données réelles. Lorsque le routeur reçoit le paquet, il le décapsule, modifie l'en-tête/la fin L2 et encapsule à nouveau le paquet.
Le routeur le reçoit maintenant et commence à décapsuler. Il examine l'en-tête L2 et voit que le Mac de destination est pour lui-même. Maintenant, il supprime l'en-tête L2 et examine maintenant l'en-tête L3 et comprend que la demande ne concerne pas lui-même mais le serveur Google. Le routeur décrémente ensuite la valeur TTL qui se trouve à l'intérieur de l'en-tête L3. Le routeur examine maintenant dans sa table de routage toutes les routes possibles que les autres routeurs auraient annoncées à ce routeur (via RIP ou IGP) pour atteindre la destination. Un routeur effectue ensuite ARP pour obtenir l'adresse MAC du routeur du saut suivant s'il n'a pas l'adresse MAC dans son cache.
Le routeur ajoute ensuite également le CRC qui se poursuit vers la bande-annonce L2. Cela aide le routeur suivant à savoir qu'aucun problème sur les routes ne s'est produit qui aurait pu corrompre le paquet sur le câble. S'il est corrompu, le cadre sera supprimé.
Dans ce cas, le routeur a modifié l'en-tête L2 et la fin L2 mais il n'a pas touché l'en-tête L3 et donc aucun en-tête au-dessus.
Numéro du port source sera un numéro de port éphémère et le numéro de port de destination sera 80.
TCP - Service de commande fiable et identique. La première chose que fera la machine locale est d'établir maintenant une négociation à trois avec le serveur Google, car elle connaît l'itinéraire vers le serveur. L'établissement de la connexion permet de finaliser certaines variables d'état telles que la taille MSS, le numéro de séquence initial, le type ACK, la taille du tampon, etc.
Dans ce cas, le port source ainsi que le port de destination dans l'en-tête TCP sont de 16 bits, donc 2 ^ 16 est 65535. Le port source est utilisé pour identifier l'application client tandis que le port de destination est utilisé pour identifier le service ou le démon exécuté sur le serveur Web.
Le client (navigateur Web) récupère n'importe quel port compris entre 49152 et 65535. Cela garantit qu'aucune application n'utilise le même port. L'adresse du port ainsi que l'adresse IP sont appelées socket TCP. Le port de destination est le port 80 du paquet IP.
Commencer la communication :
Avec les trois étapes ci-dessus, la négociation TCP réussit entre le client et le serveur et les deux ont désormais accepté les règles communes pour le transfert de données.
Après la négociation TCP, la négociation TLS a lieu si vous vous connectez à un site Web sécurisé. Avec la négociation TLS, le client et le serveur acceptent les conditions communes de communication sécurisée.
Désormais, la session TLS transmet les données de l'application (HTTP) cryptées avec la clé symétrique convenue.
Le serveur traite les demandes et renvoie une réponse appropriée. Lorsque la requête arrive au serveur sur le port 80 (HTTP) ou le port 443 (HTTPS) un serveur web comme Apache ou Nginx écoute le port 443, gère la connexion de la requête et l'achemine vers un autre port éphémère sur lequel se trouve le service web. en cours d'exécution.
Tout client, serveur ou proxy HTTP peut fermer une connexion de transport TCP à tout moment. Par exemple, lorsque le client détecte que le transfert de données est terminé et que le canal de connexion ouvert n'est plus nécessaire, il envoie une demande de fermeture de connexion au serveur. La prochaine fois que le client souhaite communiquer avec le serveur, une nouvelle connexion devra être établie entre les deux machines.
| [1] | La norme URL |
| [2] | Composants ou URL |


