tabled
1.0.0
Tabled est une petite bibliothèque pour détecter et extraire des tables. Il utilise Surya pour rechercher tous les tableaux d'un PDF, identifie les lignes/colonnes et formate les cellules en markdown, csv ou html.
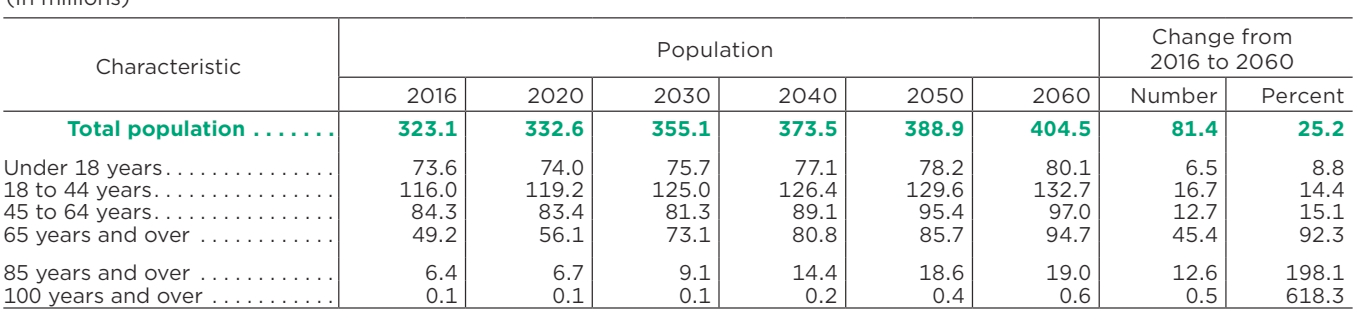
| Caractéristiques | Population | Evolution de 2016 à 2060 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016 | 2020 | 2030 | 2040 | 2050 | 2060 | Nombre | Pour cent | |
| Population totale | 323.1 | 332,6 | 355.1 | 373,5 | 388,9 | 404,5 | 81,4 | 25.2 |
| Moins de 18 ans | 73,6 | 74,0 | 75,7 | 77.1 | 78.2 | 80,1 | 6.5 | 8.8 |
| 18 à 44 ans | 116,0 | 119.2 | 125,0 | 126,4 | 129,6 | 132,7 | 16.7 | 14.4 |
| 45 à 64 ans | 84,3 | 83,4 | 81,3 | 89,1 | 95,4 | 97,0 | 12.7 | 15.1 |
| 65 ans et plus | 49.2 | 56.1 | 73.1 | 80,8 | 85,7 | 94,7 | 45.4 | 92,3 |
| 85 ans et plus | 6.4 | 6.7 | 9.1 | 14.4 | 18.6 | 19,0 | 12.6 | 198.1 |
| 100 ans et plus | 0,1 | 0,1 | 0,1 | 0,2 | 0,4 | 0,6 | 0,5 | 618.3 |
Discord est l'endroit où nous discutons du développement futur.
Il existe une API hébergée pour tabled disponible ici :
Fonctionne avec des PDF, des images, des documents Word et des PowerPoint
Vitesse constante, sans pics de latence
Haute fiabilité et disponibilité
Je souhaite que le projet soit aussi largement accessible que possible, tout en finançant mes frais de développement/formation. La recherche et l'utilisation personnelle sont toujours acceptables, mais il existe certaines restrictions concernant l'utilisation commerciale.
Les pondérations des modèles sont sous licence cc-by-nc-sa-4.0 , mais j'y renoncerai pour toute organisation inférieure à 5 millions de dollars de revenus bruts au cours de la période de 12 mois la plus récente ET inférieure à 5 millions de dollars en financement de capital-risque/investisseur providentiel à vie. soulevé. Vous ne devez pas non plus être compétitif avec l'API Datalab. Si vous souhaitez supprimer les exigences de licence GPL (double licence) et/ou utiliser les poids commercialement au-delà de la limite de revenus, consultez les options ici.
Vous aurez besoin de python 3.10+ et de PyTorch. Vous devrez peut-être d'abord installer la version CPU de Torch si vous n'utilisez pas de Mac ou de machine GPU. Voir ici pour plus de détails.
Installer avec :
pip install déposé-pdf
Post-installation :
Inspectez les paramètres dans tabled/settings.py . Vous pouvez remplacer tous les paramètres par des variables d'environnement.
Votre appareil torche sera automatiquement détecté, mais vous pouvez ignorer cela. Par exemple, TORCH_DEVICE=cuda .
Les poids des modèles seront automatiquement téléchargés la première fois que vous exécuterez le dépôt.
déposé DATA_PATH
DATA_PATH peut être une image, un pdf ou un dossier d'images/pdfs
--format spécifie le format de sortie pour chaque tableau ( markdown , html ou csv )
--save_json enregistre des informations supplémentaires sur les lignes et les colonnes dans un fichier json
--save_debug_images enregistre les images montrant les lignes et colonnes détectées
--skip_detection signifie que les images que vous transmettez sont toutes des tables recadrées et ne nécessitent aucune détection de table.
--detect_cell_boxes par défaut, tabled tentera d'extraire les informations sur les cellules du pdf. Si vous souhaitez plutôt que les cellules soient détectées par un modèle de détection, spécifiez-le (généralement, vous n'en avez besoin qu'avec les fichiers PDF contenant un mauvais texte intégré).
--save_images spécifie que les images des lignes/colonnes et cellules détectées doivent être enregistrées.
Après avoir exécuté le script, le répertoire de sortie contiendra des dossiers avec les mêmes noms de base que les noms de fichiers d'entrée. À l’intérieur de ces dossiers se trouveront les fichiers de démarques pour chaque tableau des documents sources. Il y aura également éventuellement des images des tableaux.
Il y aura également un fichier results.json à la racine du répertoire de sortie. Le fichier contiendra un dictionnaire json où les clés sont les noms de fichiers d'entrée sans extensions. Chaque valeur sera une liste de dictionnaires, un par table du document. Chaque dictionnaire de tables contient :
cells - le texte détecté et les cadres de délimitation pour chaque cellule du tableau.
bbox - bbox de la cellule dans la table bbox
text - le texte de la cellule
row_ids - identifiants des lignes auxquelles appartient la cellule
col_ids - identifiants des colonnes auxquelles appartient la cellule
order - ordre de cette cellule dans la cellule de ligne/colonne qui lui est attribuée. (trier par ligne, puis colonne, puis ordre)
rows - bboxes des lignes détectées
bbox - bbox de la ligne au format (x1, x2, y1, y2)
row_id - identifiant unique de la ligne
cols - bboxes des colonnes détectées
bbox - bbox de la colonne au format (x1, x2, y1, y2)
col_id - identifiant unique de la colonne
image_bbox - la bbox de l'image au format (x1, y1, x2, y2). (x1, y1) est le coin supérieur gauche et (x2, y2) est le coin inférieur droit. La table bbox est relative à cela.
bbox - le cadre de délimitation de la table dans l'image bbox.
pnum - numéro de page dans le document
tnum - index du tableau sur la page
J'ai inclus une application simplifiée qui vous permet d'essayer de manière interactive des images ou des fichiers PDF. Exécutez-le avec :
pip install rationalisé table_gui
à partir de tabled.extract import extract_tablesfrom tabled.fileinput import load_pdfs_imagesfrom tabled.inference.models import load_detection_models, load_recognition_modelsdet_models, rec_models =load_detection_models(),load_recognition_models()images, highres_images, noms, text_lines = load_pdfs_images(IN_PATH)page_results = extract_tables(images, highres_images, text_lines, det_models, rec_models)
| Score moyen | Temps par table | Tableaux totaux |
|---|---|---|
| 0,847 | 0,029 | 688 |
Il est difficile d'obtenir de bonnes données de vérité terrain pour les tableaux, car soit vous êtes limité à des présentations simples qui peuvent être analysées et restituées de manière heuristique, soit vous devez utiliser des LLM, qui commettent des erreurs. J'ai choisi d'utiliser les prédictions du tableau GPT-4 comme pseudo-vérité terrain.
Tabled obtient un score d'alignement .847 par rapport à GPT-4, ce qui indique l'alignement entre le texte dans les lignes/cellules du tableau. Certains des désalignements sont dus à des erreurs de GPT-4 ou à de petites incohérences dans ce que GPT-4 considère comme les bordures du tableau. En général, la qualité de l'extraction est assez élevée.
Fonctionnant sur un A10G avec 10 Go d'utilisation de VRAM et une taille de lot de 64 , le dépôt prend .029 seconde par table.
Exécutez le benchmark avec :
python benchmarks/benchmark.py out.json
Merci à Peter Jansen pour l'ensemble de données d'analyse comparative et pour la discussion sur l'analyse des tables.
Huggingface pour le code d'inférence et l'hébergement de modèles
PyTorch pour la formation/inférence


