Stable Diffusion a été rendue possible grâce à une collaboration avec Stability AI et Runway et s'appuie sur nos travaux précédents :
Synthèse d'images haute résolution avec modèles de diffusion latente
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 Orale | GitHub | arXiv | Page du projet
 Stable Diffusion est un modèle de diffusion latent de texte à image. Grâce à un généreux don de calcul de Stability AI et au soutien de LAION, nous avons pu former un modèle de diffusion latente sur des images 512 x 512 provenant d'un sous-ensemble de la base de données LAION-5B. Semblable à Imagen de Google, ce modèle utilise un encodeur de texte CLIP ViT-L/14 gelé pour conditionner le modèle sur des invites de texte. Avec son encodeur de texte 860M UNet et 123M, le modèle est relativement léger et fonctionne sur un GPU avec au moins 10 Go de VRAM. Voir cette section ci-dessous et la fiche modèle.
Stable Diffusion est un modèle de diffusion latent de texte à image. Grâce à un généreux don de calcul de Stability AI et au soutien de LAION, nous avons pu former un modèle de diffusion latente sur des images 512 x 512 provenant d'un sous-ensemble de la base de données LAION-5B. Semblable à Imagen de Google, ce modèle utilise un encodeur de texte CLIP ViT-L/14 gelé pour conditionner le modèle sur des invites de texte. Avec son encodeur de texte 860M UNet et 123M, le modèle est relativement léger et fonctionne sur un GPU avec au moins 10 Go de VRAM. Voir cette section ci-dessous et la fiche modèle.
Un environnement conda approprié nommé ldm peut être créé et activé avec :
conda env create -f environment.yaml
conda activate ldm
Vous pouvez également mettre à jour un environnement de diffusion latente existant en exécutant
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 fait référence à une configuration spécifique de l'architecture du modèle qui utilise un encodeur automatique à facteur de sous-échantillonnage 8 avec un encodeur de texte UNet 860M et CLIP ViT-L/14 pour le modèle de diffusion. Le modèle a été pré-entraîné sur des images 256 x 256, puis affiné sur des images 512 x 512.
Remarque : Stable Diffusion v1 est un modèle général de diffusion de texte à image et reflète donc les préjugés et les (mauvaises) conceptions présentes dans ses données d'entraînement. Des détails sur la procédure de formation et les données, ainsi que sur l'utilisation prévue du modèle, peuvent être trouvés dans la fiche modèle correspondante.
Les poids sont disponibles via l'organisation CompVis chez Hugging Face sous une licence qui contient des restrictions spécifiques basées sur l'utilisation pour éviter les abus et les dommages, comme indiqué par la carte modèle, mais reste par ailleurs permissive. Bien que l'utilisation commerciale soit autorisée selon les termes de la licence, nous ne recommandons pas d'utiliser les poids fournis pour des services ou des produits sans mécanismes et considérations de sécurité supplémentaires , car il existe des limites et des biais connus des poids, ainsi que des recherches sur le déploiement sûr et éthique de ces poids. les modèles généraux de conversion texte-image constituent un effort continu. Les poids sont des artefacts de recherche et doivent être traités comme tels.
La licence CreativeML OpenRAIL M est une licence Open RAIL M, adaptée du travail que BigScience et RAIL Initiative mènent conjointement dans le domaine des licences d'IA responsable. Voir aussi l'article sur la licence BLOOM Open RAIL sur laquelle est basée notre licence.
Nous proposons actuellement les points de contrôle suivants :
sd-v1-1.ckpt : 237k pas en résolution 256x256 sur laion2B-en. 194 000 pas à une résolution de 512x512 sur laion haute résolution (170 millions d'exemples de LAION-5B avec une résolution >= 1024x1024 ).sd-v1-2.ckpt : Reprise de sd-v1-1.ckpt . 515 000 pas à une résolution de 512x512 sur laion-aesthetics v2 5+ (un sous-ensemble de laion2B-en avec un score esthétique estimé > 5.0 , et filtré en outre sur des images avec une taille d'origine >= 512x512 et une probabilité de filigrane estimée < 0.5 . L'estimation du filigrane est issu des métadonnées LAION-5B, le score esthétique est estimé à l'aide du LAION-Aesthetics Prédicteur V2).sd-v1-3.ckpt : Reprise de sd-v1-2.ckpt . 195 000 pas à une résolution de 512x512 sur "laion-aesthetics v2 5+" et suppression de 10 % du conditionnement de texte pour améliorer l'échantillonnage de guidage sans classificateur.sd-v1-4.ckpt : Reprise de sd-v1-2.ckpt . 225 000 pas à une résolution de 512x512 sur "laion-aesthetics v2 5+" et suppression de 10 % du conditionnement de texte pour améliorer l'échantillonnage de guidage sans classificateur. Les évaluations avec différentes échelles de guidage sans classificateur (1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0, 8,0) et 50 étapes d'échantillonnage PLMS montrent les améliorations relatives des points de contrôle : 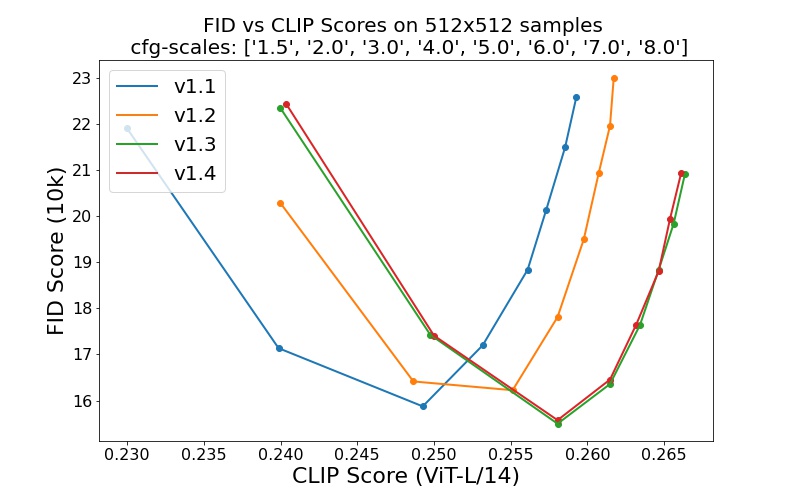


Stable Diffusion est un modèle de diffusion latente conditionné sur les intégrations de texte (non poolées) d'un encodeur de texte CLIP ViT-L/14. Nous fournissons un script de référence pour l'échantillonnage, mais il existe également une intégration de diffuseurs, dont nous espérons voir un développement communautaire plus actif.
Nous fournissons un script d'échantillonnage de référence, qui intègre
Après avoir obtenu les poids stable-diffusion-v1-*-original , liez-les
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
et échantillonner avec
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Par défaut, cela utilise une échelle de guidage de --scale 7.5 , l'implémentation par Katherine Crowson de l'échantillonneur PLMS, et restitue des images de taille 512 x 512 (sur lesquelles il a été formé) en 50 étapes. Tous les arguments pris en charge sont répertoriés ci-dessous (tapez python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Remarque : La configuration d'inférence pour toutes les versions v1 est conçue pour être utilisée avec des points de contrôle EMA uniquement. Pour cette raison, use_ema=False est défini dans la configuration, sinon le code tentera de passer des poids non-EMA aux poids EMA. Si vous souhaitez examiner l'effet de l'EMA par rapport à l'absence d'EMA, nous fournissons des points de contrôle « complets » qui contiennent les deux types de pondérations. Pour ceux-ci, use_ema=False chargera et utilisera les poids non-EMA.
Un moyen simple de télécharger et d’échantillonner Stable Diffusion consiste à utiliser la bibliothèque de diffuseurs :
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )En utilisant un mécanisme de débruitage par diffusion comme proposé pour la première fois par SDEdit, le modèle peut être utilisé pour différentes tâches telles que la traduction d'image à image guidée par le texte et la mise à l'échelle. Semblable au script d'échantillonnage txt2img, nous fournissons un script pour effectuer la modification d'image avec Stable Diffusion.
Ce qui suit décrit un exemple dans lequel une esquisse réalisée dans Pinta est convertie en une illustration détaillée.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Ici, la force est une valeur comprise entre 0,0 et 1,0, qui contrôle la quantité de bruit ajoutée à l'image d'entrée. Les valeurs proches de 1,0 permettent de nombreuses variations mais produiront également des images qui ne sont pas sémantiquement cohérentes avec l'entrée. Voir l'exemple suivant.
Saisir

Sorties


Cette procédure peut, par exemple, également être utilisée pour mettre à l'échelle des échantillons du modèle de base.
Notre base de code pour les modèles de diffusion s'appuie fortement sur la base de code ADM d'OpenAI et sur https://github.com/lucidrains/denoising-diffusion-pytorch. Merci pour l'open source !
L'implémentation de l'encodeur de transformateur provient de x-transformers de lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


