ACM MM'18 Meilleur article étudiant
Le projet Multi-Human Parsing du groupe Learning and Vision (LV) de l'Université nationale de Singapour (NUS) vise à repousser les frontières de la compréhension visuelle fine des humains dans une scène de foule.
L'analyse multi-humaine est très différente des tâches traditionnelles de reconnaissance d'objets bien définies, telles que la détection d'objets, qui ne fournit que des prédictions grossières de l'emplacement des objets (cadres de délimitation) ; la segmentation des instances, qui prédit uniquement le masque au niveau de l'instance sans aucune information détaillée sur les parties du corps et les catégories de mode ; l'analyse humaine, qui opère sur une prédiction par pixel au niveau de la catégorie sans différencier les différentes identités.
Dans un scénario du monde réel, la mise en scène de plusieurs personnes ayant des interactions est plus réaliste et habituelle. Ainsi, une tâche, des ensembles de données correspondants et des méthodes de base permettant de prendre en compte à la fois les informations sémantiques fines de chaque individu et les relations et interactions de l’ensemble du groupe de personnes sont hautement souhaitées.
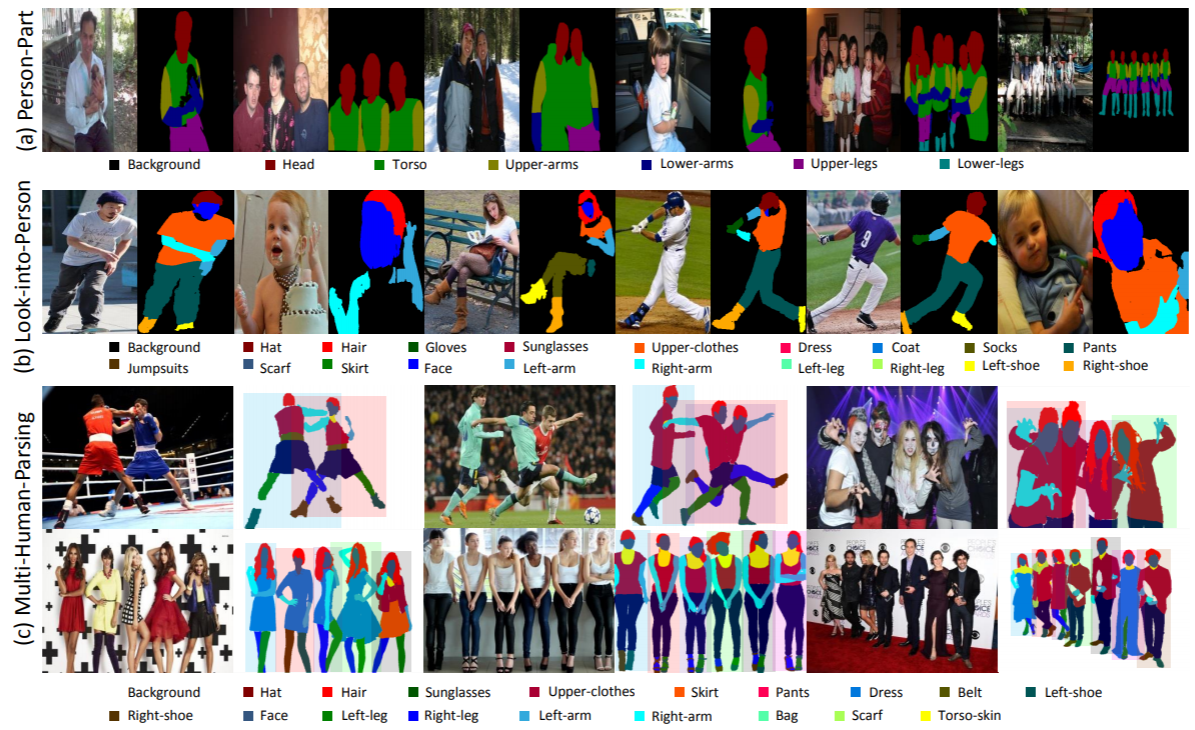
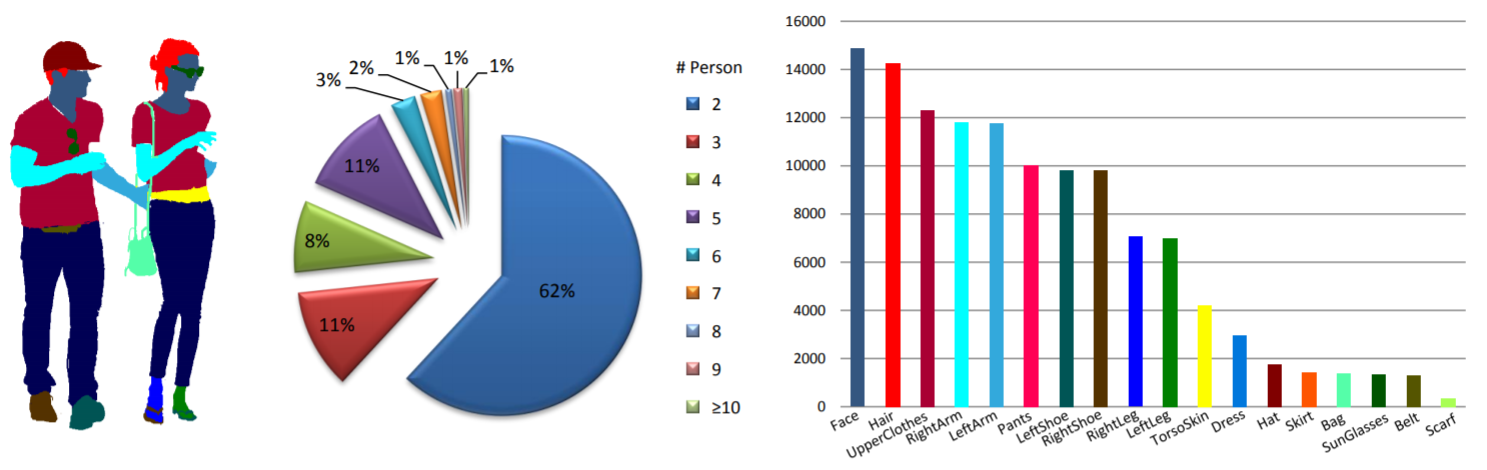
Statistiques : L'ensemble de données MHP v1.0 contient 4 980 images, chacune avec au moins deux personnes (la moyenne est de 3). Nous choisissons au hasard 980 images et leurs annotations correspondantes comme ensemble de tests. Le reste forme un ensemble de formation de 3 000 images et un ensemble de validation de 1 000 images. Pour chaque instance, 18 catégories sémantiques sont définies et annotées à l'exception de la catégorie « fond », à savoir « chapeau », « cheveux », « lunettes de soleil », « vêtements d'extérieur », « jupe », « pantalon », « robe », « ceinture", "chaussure gauche", "chaussure droite", "visage", "jambe gauche", "jambe droite", "bras gauche", "bras droit", "sac", "écharpe" et "peau du torse". Chaque instance possède un ensemble complet d'annotations chaque fois que la catégorie correspondante apparaît dans l'image actuelle.
Actualités WeChat.
Téléchargement : L'ensemble de données MHP v1.0 est disponible sur Google Drive et Baidu Drive (mot de passe : cmtp).
Veuillez vous référer à notre article MHP v1.0 (soumis à l'IJCV) pour plus de détails.

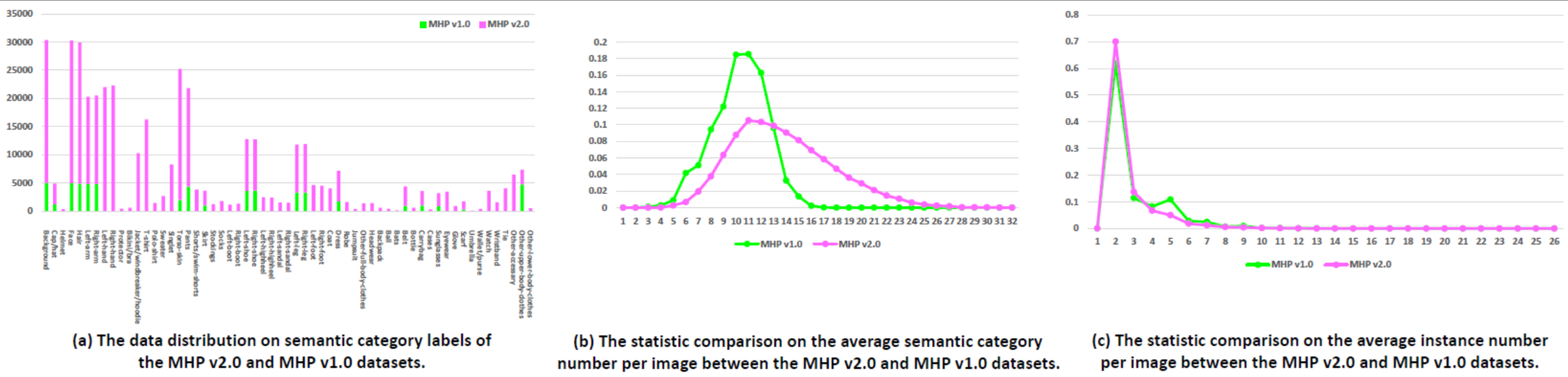

Statistiques : L'ensemble de données MHP v2.0 contient 25 403 images, chacune avec au moins deux personnes (la moyenne est de 3). Nous choisissons au hasard 5 000 images et leurs annotations correspondantes comme ensemble de tests. Le reste forme un ensemble de formation de 15 403 images et un ensemble de validation de 5 000 images. Pour chaque instance, 58 catégories sémantiques sont définies et annotées à l'exception de la catégorie "fond", à savoir "casquette/chapeau", "casque", "visage", "cheveux", "bras gauche", "bras droit", "main gauche", "main droite", "protecteur", "bikini/soutien-gorge", "veste/coupe-vent/sweat à capuche", "t-shirt", "polo-shirt", "pull", "singlet", "torse-peau", "pantalon", "shorts/shorts de bain", "jupe", "bas", "chaussettes", "botte gauche", "botte droite", "chaussure gauche", "chaussure droite", "talon haut gauche", "talon droit", "sandale gauche", "sandale droite", "jambe gauche", "jambe droite", "pied gauche", "pied droit", "manteau", "robe", "robe", "combinaison", "autres vêtements complets", "couvre-chefs", "sacs à dos", "balles", "chauves-souris", "ceintures", "bouteilles", "sacs de transport", "étuis", "lunettes de soleil", "lunettes", "gant", "écharpe", "parapluie", "portefeuille/sac à main", "montre", "bracelet", "cravate", "autre accessoire", "autres vêtements du haut du corps" et "autres vêtements du bas du corps". -vêtements-de-corps". Chaque instance possède un ensemble complet d'annotations chaque fois que la catégorie correspondante apparaît dans l'image actuelle. De plus, des poses humaines 2D avec 16 points clés denses ("épaule droite", "coude droit", "poignet droit", "épaule gauche", "coude gauche", "poignet gauche", "droite- hanche", "genou droit", "cheville droite", "hanche gauche", "genou gauche", "cheville gauche", "tête", "cou", "colonne vertébrale" et "bassin". Chacun le point clé a un drapeau indiquant s'il est visible-0/occlus-1/out-of-image-2) et des cadres de délimitation de tête et d'instance sont également fournis pour faciliter la recherche d'estimation de pose multi-humaine.
Téléchargement : L'ensemble de données MHP v2.0 est disponible sur Google Drive et Baidu Drive (mot de passe : uxrb).
Veuillez vous référer à notre article MHP v2.0 (ACM MM'18 Best Student Paper) pour plus de détails.
Analyse multi-humaine : nous utilisons deux métriques centrées sur l'humain pour l'évaluation de l'analyse multi-humaine, qui sont initialement rapportées dans notre article MHP v1.0. Les deux mesures sont la précision moyenne basée sur la partie (AP p ) (%) et le pourcentage de parties sémantiques correctement analysées (PCP) (%). Pour le code d'évaluation, veuillez vous référer au dossier « Évaluation » sous notre référentiel « Multi-Human-Parsing_MHP ».
Estimation de pose multi-humaine : suivi du MPII, nous utilisons la mesure d'évaluation mAP (%).
Nous avons organisé l'atelier CVPR 2018 sur la compréhension visuelle des humains dans la scène de foule (VUHCS 2018). Cet atelier est collaboré par NUS, CMU et SYSU. Sur la base du VUHCS 2017, nous avons encore renforcé cet atelier en l'augmentant de 5 pistes de compétition : l'analyse humaine par une seule personne, l'analyse humaine par plusieurs personnes, l'estimation de la pose par une seule personne, l'estimation de la pose par plusieurs humains et la fine- analyse multi-humaine granuleuse.
Soumission des résultats et classement.
Actualités WeChat.
Veuillez consulter et envisager de citer les articles suivants :
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


