baker example page template
1.0.0
Une démonstration de la façon de créer et de publier des pages avec l'outil de construction Baker.
Le Los Angeles Times utilise Baker pour créer les pages statiques publiées sur latimes.com/projects. Le système du Times s'appuie sur une version privée d'un référentiel semblable à celui-ci. Cet exemple simplifié publie des versions intermédiaires et de production dans des compartiments publics sur Amazon S3.
Serveur de test local avec mise à jour en direct
Modèle HTML avec Nunjucks
CSS étendu avec Sass
Regroupement JavaScript avec Rollup et Babel
Importations de données avec quaff
Génération de pages dynamique basée sur des entrées structurées
Déploiement automatique de chaque branche dans un environnement de transfert sur chaque événement push via GitHub Action
Déploiement par bouton-poussoir dans l'environnement de production à chaque événement release via GitHub Action
Messages Slack qui relaient l'état de chaque déploiement via l'action Github datadesk/notify-slack-on-build
Node.js version 12, 14 ou 16, mais au minimum 12.20, 14.14 ou 16.0.
Gestionnaire de packages de nœuds
git
Avec un peu de configuration, vous pouvez utiliser ce modèle pour publier facilement une page. Avec un peu de personnalisation, vous pouvez lui donner l'apparence que vous souhaitez. Ce guide vous présentera les bases.
Création d'une nouvelle page
Explorer le référentiel
Accéder aux actifs
Accéder aux données
Pages dynamiques
Déploiement
Variables globales
baker.config.js
La première étape consiste à cliquer sur le bouton « Utiliser ce modèle » de GitHub pour créer vous-même une copie du référentiel.
Il vous sera demandé de fournir un slug pour votre projet. Une fois cela fait, un nouveau référentiel sera disponible sur https://github.com/your-username/your-slug .
Ensuite, vous devrez le cloner sur votre ordinateur pour travailler avec le code.
Ouvrez votre terminal et placez-le dans votre dossier de code. Clonez le projet dans votre dossier. Cela copiera le projet sur votre ordinateur.
git clone https://github.com/your-username/your-slug
Si cette commande ne fonctionne pas pour vous, cela peut être dû au fait que votre ordinateur a été configuré différemment et que vous devez cloner sur le référentiel à l'aide de SSH. Essayez d'exécuter ceci dans votre terminal :
git clone [email protected]:votre-nom d'utilisateur/votre-slug.git
Une fois le téléchargement du référentiel terminé, insérez votre-slug et installez les dépendances Node.js.
installation npm
Une fois les dépendances installées, vous êtes prêt à prévisualiser le projet. Exécutez ce qui suit pour démarrer le serveur de test.
npm démarrer
Allez maintenant sur localhost:3000 dans votre navigateur. Vous devriez voir une page passe-partout prête pour vos personnalisations.
Une solution alternative consiste à créer une nouvelle page avec bluprint, l'outil d'échafaudage en ligne de commande développé par le département graphique de Reuters.
bluprint ajouter https://github.com/datadesk/baker-example-page-template mkdir ma-nouvelle-pagecd ma-nouvelle-page Bluprint démarrer la page d'exemple de Baker
Voici les fichiers et dossiers standards que vous trouverez lorsque vous clonez un nouveau projet à partir de notre modèle de page. Vous passerez plus de temps à travailler avec certains fichiers qu'avec d'autres, mais il est bon d'avoir une idée générale de ce qu'ils font tous.
Le dossier de données contient des données pertinentes pour le projet. Nous utilisons ce dossier pour stocker les informations requises sur chaque projet, comme l'URL à laquelle il doit résider. Vous pouvez également stocker ici divers autres types de données, notamment .aml , .csv et .json .
Le fichier meta.aml contient des informations importantes sur la page telles que le titre, la signature, le slug, la date de publication et d'autres champs. Le remplir garantit que votre page s'affiche correctement et peut être indexée par les moteurs de recherche. Une liste complète de tous les attributs peut être trouvée dans nos documents de référence. Vous pouvez étendre cela pour inclure autant ou aussi peu d’options que vous le souhaitez.
Ce dossier qui stocke le modèle de base de notre site et les extraits de code réutilisables. Lorsque vous débutez, il est peu probable que vous puissiez changer quoi que ce soit ici. Dans les cas d'utilisation plus avancés, c'est là que vous pouvez stocker le code qui est réutilisé sur plusieurs pages.
base.htmlLe fichier base.html contient tout le HTML fondamental trouvé sur chaque page que nous créons. L’exemple ici est rudimentaire de par sa conception. Vous souhaiterez probablement en inclure beaucoup plus dans une implémentation réelle.
L'espace de travail est un endroit où vous pouvez mettre tout ce qui est pertinent pour le projet et qui n'a pas besoin d'être publié sur le Web. Fichiers IA, bouts de code, écriture, etc. C'est à vous de décider.
Ceci est utilisé pour stocker des médias et d'autres actifs tels que des images, des vidéos, de l'audio, des polices, etc. Ils peuvent être extraits dans la page via les balises de modèle static .
Les fichiers JavaScript sont stockés dans ce dossier. Le fichier principal de JavaScript s'appelle app.js , dans lequel vous pouvez écrire votre code directement. Les packages installés via npm peuvent être importés et exécutés comme n'importe quel autre script Node.js. Vous pouvez créer d'autres fichiers pour écrire votre code JavaScript dans ce dossier, mais vous devez vous assurer que le fichier est démarré à partir de app.js .
Nos feuilles de style sont écrites en SASS, un langage de feuilles de style puissant qui donne aux développeurs plus de contrôle sur CSS. Si vous n'êtes pas à l'aise avec SASS, vous pouvez écrire du CSS simple dans les feuilles de style.
Le dossier styles se compose d'une feuille de style ( app.scss ) dans laquelle vous pouvez ajouter tous vos styles personnalisés à votre projet, même si vous souhaiterez parfois créer des feuilles de style supplémentaires et les importer dans app.scss . Cet exemple de projet n'inclut que le strict minimum nécessaire pour simuler un site simple. Vous voudriez probablement commencer avec beaucoup plus dans une mise en œuvre réelle.
Le fichier baker.config.js est l'endroit où nous mettons les options que Baker utilise pour servir et construire le projet. Cela a été entièrement documenté ailleurs dans ce dossier. À l'exception du paramètre domain , seuls les utilisateurs avancés devront modifier ce fichier.
Le modèle par défaut pour votre page. C'est ici que vous disposerez votre page. Il utilise le système de modèles Nujucks pour créer du HTML.
Ces fichiers suivent les dépendances Node utilisées dans nos projets. Lorsque vous exécutez npm install les bibliothèques que vous ajoutez seront automatiquement suivies ici pour vous.
Il s'agit d'un répertoire spécial pour stocker les fichiers que GitHub utilise pour interagir avec nos projets et notre code. Le répertoire .github/workflows contient l'action GitHub qui gère nos déploiements de développement. Vous n'avez pas besoin de modifier quoi que ce soit ici.
Les magasins de fichiers dans le répertoire des ressources sont optimisés et hachés dans le cadre du processus de déploiement. Pour garantir que vos références à des images et autres fichiers statiques, vous devez utiliser la balise {% static %} . Cela garantit que le fichier est fortement mis en cache lors de sa publication et que le lien vers l'image fonctionne dans tous les environnements. Vous voudrez l'utiliser pour toutes les photos et vidéos.
<figure>
<img src="{% static 'assets/images/baker.jpg' %}" alt="Logo Baker" width=200>
</figure> Les fichiers de données structurées stockés dans votre dossier _data sont accessibles via des templatetags ou JavaScript. Dans cette démonstration, un fichier appelé example.json a été inclus pour illustrer ce qui est possible. D'autres formats de fichiers comme CSV, YAML et AML sont pris en charge.
Les fichiers du dossier _data sont disponibles par leur nom dans vos modèles. Ainsi, avec _data/example.json , vous pouvez écrire quelque chose comme :
{% pour obj dans l'exemple %}
{{ obj.year }} : {{ obj.wheat }}{% endfor %}Un besoin courant pour quiconque crée un projet dans Baker est d'accéder aux données brutes dans un fichier JavaScript. Souvent, ces données sont ensuite transmises au code écrit à l'aide de d3 ou Svelte pour dessiner des graphiques ou créer des tableaux HTML sur la page.
Si les données auxquelles vous accédez sont déjà disponibles sur une URL dont vous êtes sûr qu'elle restera active, c'est simple. Mais que se passe-t-il si ce n’est pas le cas et qu’il s’agit de données que vous avez préparées vous-même ?
Il est possible d'accéder aux enregistrements de votre dossier _data. La seule mise en garde est que la conversion de ce fichier dans un état utilisable relève de votre responsabilité. Une bonne bibliothèque pour cela est d3-fetch .
Pour créer l'URL de ce fichier d'une manière que Baker comprend, utilisez ce format :
import { json } from 'd3-fetch';// le premier paramètre doit être le chemin d'accès au fichier// le deuxième paramètre *doit* être « import.meta.url » const url = new URL('../_data /example.json', import.meta.url);// Appelez-le inconst data = wait json(url); Une autre approche consiste à imprimer les données dans votre modèle sous forme de balise script . Le filtre jsonScript prend la variable qui lui est transmise, exécute JSON.stringify dessus et génère le JSON dans le code HTML dans une balise <script> avec l'ID défini que vous transmettez en paramètre.
{{ exemple|jsonScript('exemple-données') }}Une fois cela en place, vous pouvez désormais récupérer le JSON stocké dans la page par ID dans votre JavaScript.
// récupère l'élément jsonScript créé en utilisant le même ID que vous avez passé inconst dataElement = document.getElementById('example-data');// convertit le contenu de cet élément en JSON// fait ce que vous devez faire avec "data" !const data = JSON.parse(dataElement.textContent); Bien que la méthode URL soit recommandée, cette méthode peut néanmoins être préférée lorsque vous essayez d'éviter des requêtes réseau supplémentaires. Il présente également l'avantage supplémentaire de ne pas nécessiter de bibliothèque spéciale pour convertir les données .csv en JSON.
Vous pouvez générer un nombre illimité de pages statiques en alimentant une source de données structurées à l'option createPages du fichier baker.config.js . Par exemple, cet extrait générera une page pour chaque enregistrement du fichier example.json .
exporter par défaut {
// ... toutes les autres options au-dessus de celle-ci ont été exclues pour faire valoir le point
createPages : createPages(createPage, data) {// Récupérez les données du dossier _dataconst pageList = data.example;// Parcourez les enregistrements pour (const d of pageList) { // Définissez le modèle de base qui sera utilisé pour chaque objet . C'est dans le dossier _layouts const template = 'year-detail.html'; // Définit l'URL de la page const url = `${d.year}`; // Définit les variables qui seront transmises dans le contexte du modèle const context = { obj: d }; // Utilisez la fonction fournie pour afficher la page createPage(template, url, context);}
},}; Cela pourrait être utilisé pour créer des URL telles que /baker-example-page-template/1775/ et /baker-example-page-template/1780/] avec un seul modèle.
Avant de pouvoir déployer une page créée par ce référentiel, vous devrez configurer votre compte Amazon AWS et ajouter un ensemble d'informations d'identification à votre compte GitHub.
Tout d'abord, vous devrez créer deux compartiments dans le service de stockage S3 d'Amazon. L’un est destiné à votre site de préparation. L'autre est destiné à votre site de production. Pour cet exemple simple, chacun doit autoriser l’accès public et être configuré pour servir un site Web statique. Dans une configuration plus sophistiquée, comme celle que nous utilisons au Los Angeles Times, les compartiments pourraient être liés à des noms de domaine enregistrés et le site intermédiaire protégé de la vue du public via un système d'authentification.
Les noms de ces buckets doivent ensuite être stockés sous forme de « secrets » GitHub accessibles aux actions qui déploient le site. Vous devriez visiter votre panneau de paramètres pour votre compte ou votre organisation. Commencez par ajouter ces deux secrets.
| Nom | Valeur |
|---|---|
BAKER_AWS_S3_STAGING_BUCKET | Le nom de votre bucket intermédiaire |
BAKER_AWS_S3_STAGING_REGION | La région S3 où votre bucket intermédiaire a été créé |
BAKER_AWS_S3_PRODUCTION_BUCKET | Le nom de votre bucket de production |
BAKER_AWS_S3_PRODUCTION_REGION | La région S3 où votre compartiment de production a été créé |
Ensuite, vous devez vous assurer que vous disposez d'une paire de clés d'AWS capable de télécharger des fichiers publics dans vos deux compartiments. Les valeurs doivent également être ajoutées à vos secrets.
| Nom | Valeur |
|---|---|
BAKER_AWS_ACCESS_KEY_ID | La clé d'accès AWS |
BAKER_AWS_SECRET_ACCESS_KEY | La clé secrète AWS |
Une action GitHub incluse avec ce référentiel publiera automatiquement une version intermédiaire pour chaque branche. Par exemple, le code poussé vers la branche main par défaut apparaîtra sur https://your-staging-bucket-url/your-repo/main/ .
Si vous deviez créer une nouvelle branche git appelée bugfix et pousser votre code, vous verriez bientôt une nouvelle version intermédiaire sur https://your-staging-bucket-url/your-repo/bugfix/ .
Avant d'envoyer votre page en direct, vous devez choisir un dernier slug pour l'URL. Cela définira le sous-répertoire de votre compartiment dans lequel la page sera publiée. Cette fonctionnalité permet au Times de publier de nombreuses pages dans le même compartiment, chaque page étant gérée par un référentiel différent.
La première étape consiste à saisir le slug de votre URL dans le fichier de configuration _data/meta.aml .
slug : votre-page-slug
Ce n'est jamais une mauvaise idée de s'assurer que votre limace n'a pas déjà été capturée. Vous pouvez le faire en visitant https://your-production-bucket-url/your-slug/ et en vous assurant qu'il renvoie une erreur de page introuvable.
Si vous souhaitez publier votre page à la racine de votre bucket, vous pouvez laisser le slug nul.
limace:
Ensuite, vous validez votre modification dans le fichier de configuration et assurez-vous qu'elle est transmise à la branche principale de GitHub.
git ajouter _data/meta.aml git commit -m « Définir le slug de page » git push origine principal
Visitez la section des versions de la page de votre référentiel sur GitHub. Vous pouvez le trouver sur la page d'accueil du dépôt.
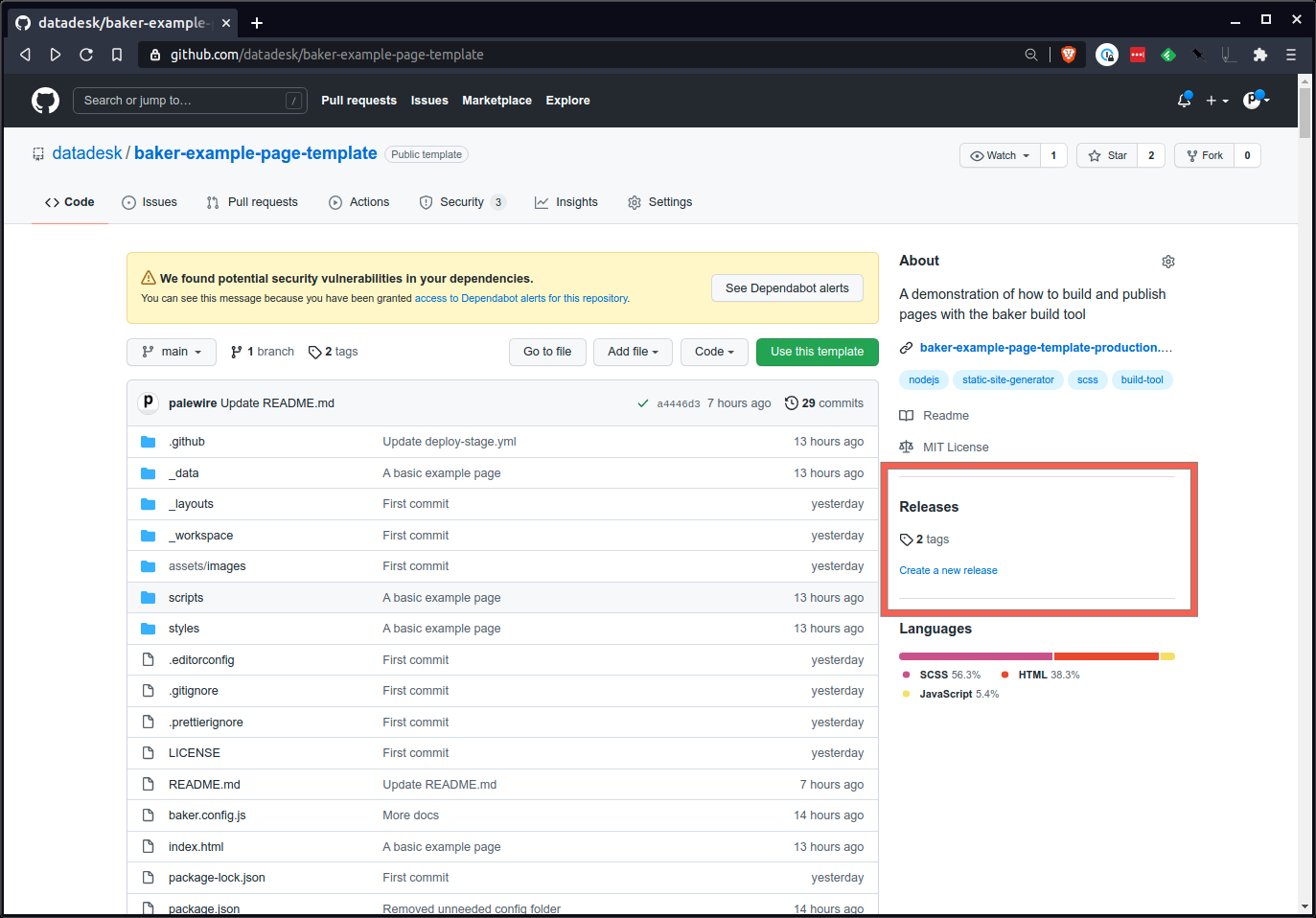
Rédigez une nouvelle version.
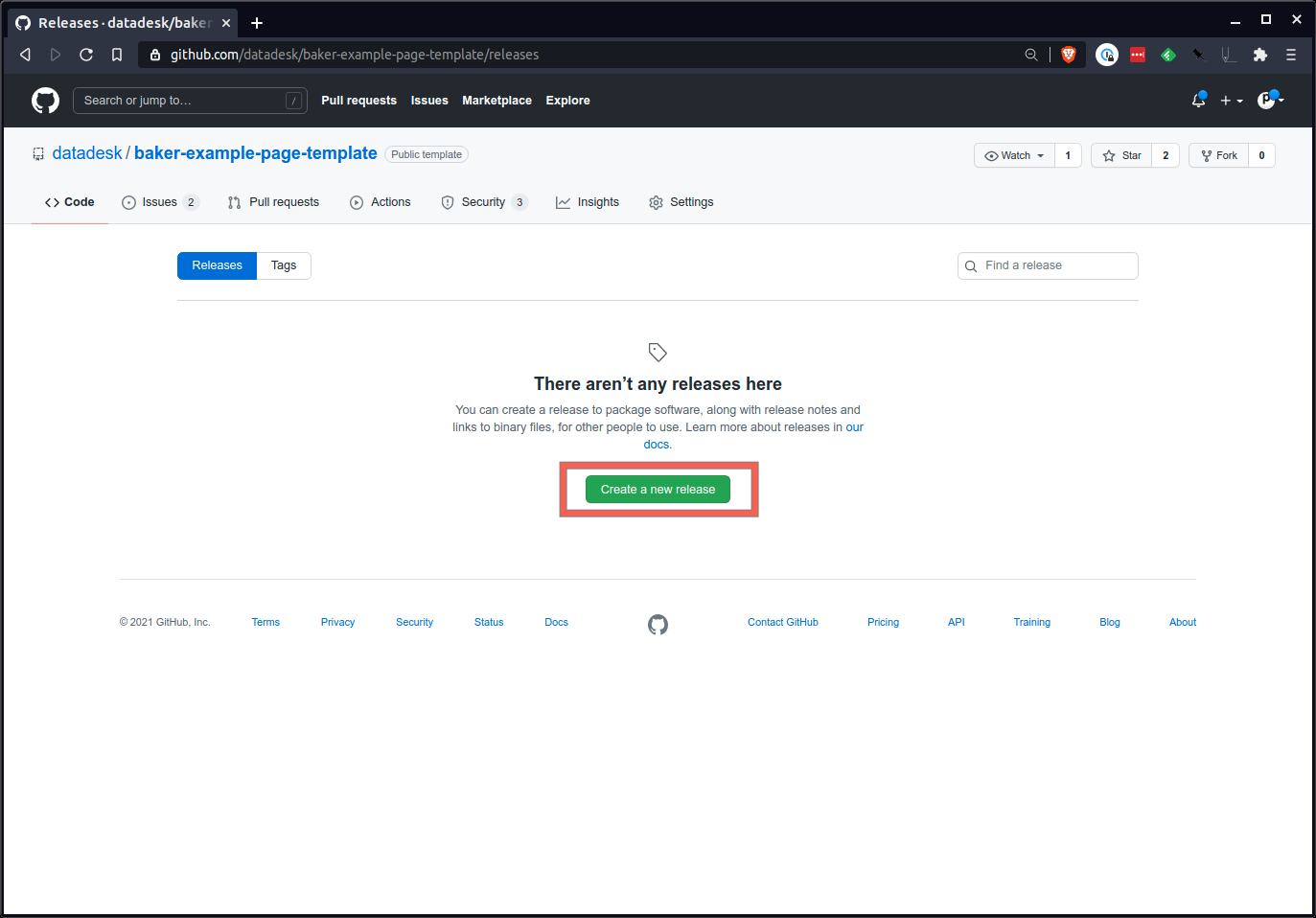
Là, vous allez créer un nouveau numéro de balise. Une bonne approche consiste à commencer avec un numéro au format xxx qui respecte les normes de version sémantique. 1.0.0 est un bon début.
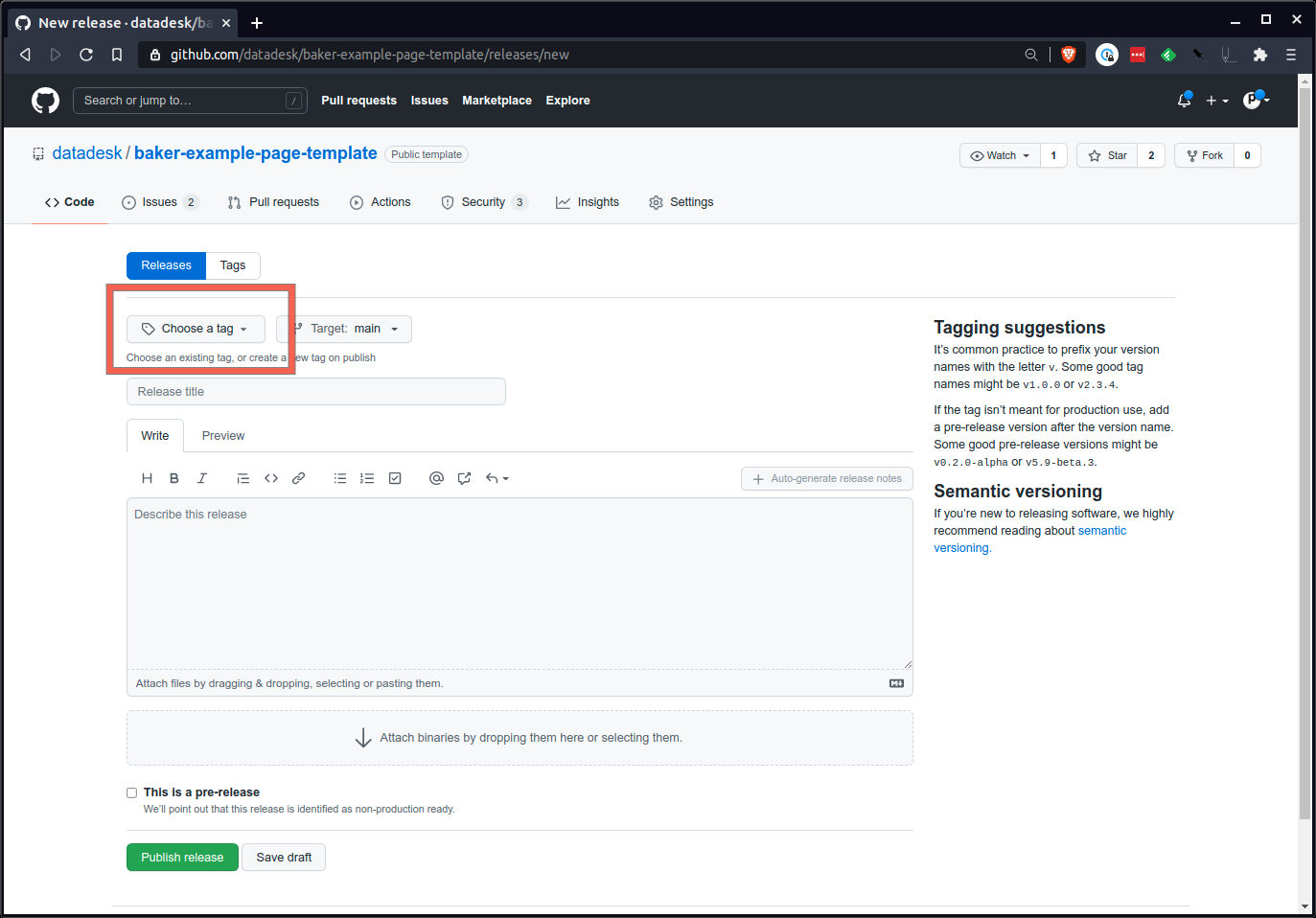
Enfin, appuyez sur le gros bouton vert en bas et envoyez le communiqué.
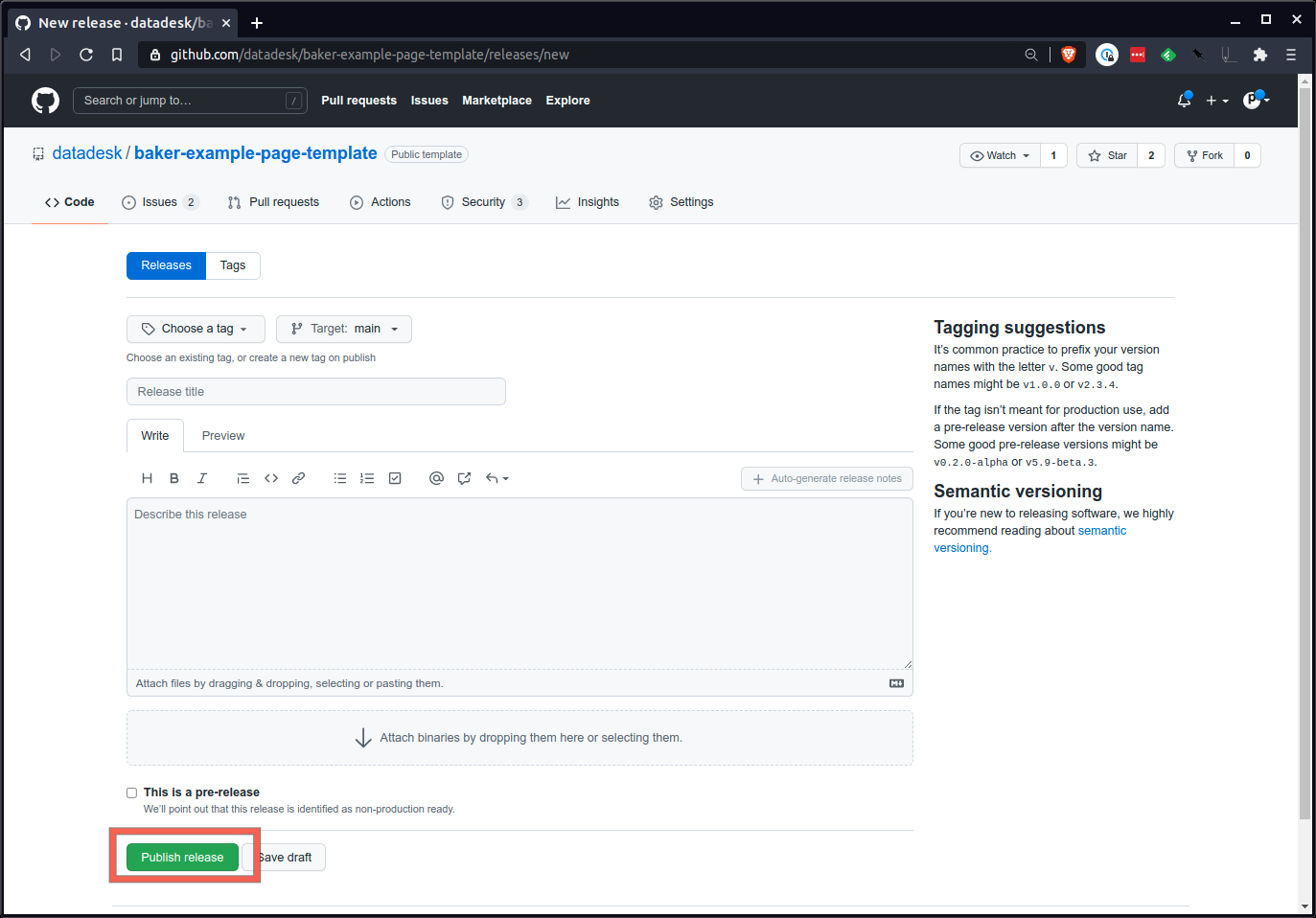
Attendez quelques minutes et votre page devrait apparaître sur https://your-production-bucket-url/your-slug/ .
Le serveur de test Baker peut se connecter plus en détail en commençant par l'option suivante.
DEBUG = 1 npm démarrage
Pour limiter les journaux à Baker Run :
DEBUG=baker :* npm start
Si votre build échoue, vous pouvez essayer de créer vous-même le site statique localement via votre terminal. S'il y a des erreurs lors de la création de la page, elles seront imprimées sur votre terminal.
npm exécuter la construction
Baker est livré avec un ensemble de variables globales qui sont les mêmes sur chaque page qu'il crée, ainsi qu'un autre ensemble de variables spécifiques à la page qui sont définies en fonction de la page en cours de création. Vous pouvez utiliser ces variables pour ajouter du contenu aux pages de manière conditionnelle ou filtrer les données non liées en fonction de la page actuelle.
NODE_ENV La variable NODE_ENV aura toujours l'une des deux valeurs suivantes : development ou production . Cela correspond au type de build exécuté sur la page.
Lorsque vous exécutez npm start , vous êtes en mode development . Lorsque vous exécutez npm run build , vous êtes en mode production .
Ceci est particulièrement utile pour ajouter des éléments aux pages uniquement lorsque vous êtes en mode development .
{% if NODE_ENV == 'development' %}<p>Vous ne verrez jamais cela sur le site en ligne !</p>{% endif %}DOMAIN La variable DOMAIN sera toujours la même que l'option domain passée dans baker.config.js , ou une chaîne vide si aucune n'a été transmise.
PATH_PREFIX La variable PATH_PREFIX sera toujours la même que l'option pathPrefix passée dans baker.config.js , ou une seule barre oblique ( / ) si elle n'a pas été transmise.
page.url L'URL relative au projet vers la page actuelle. Inclura le pathPrefix s'il en est fourni dans le fichier baker.config.js - en d'autres termes, il tiendra compte de tout cheminement de projet en cours et pointera vers la bonne page du projet.
page.absoluteUrl L'URL absolue de la page actuelle. Cela combine le domain , pathPrefix et le chemin actuel dans une URL complète. Ceci est actuellement utilisé pour afficher l'URL canonique et toutes les URL des balises sociales <meta> .
<link rel="canonical" href="{{ page.absoluteUrl }}">page.inputUrl Il s'agit du chemin d'accès au modèle d'origine utilisé pour créer cette page par rapport au répertoire du projet en cours. Si vous avez un fichier HTML situé à page-two/index.html , page.inputUrl serait page-two/index.html .
page.outputUrl Il s'agit du chemin d'accès au fichier HTML généré pour créer cette page par rapport au dossier _dist . Si vous avez un fichier HTML situé à page-two.html , page.outputUrl serait page-two/index.html .
Chaque projet Baker sur lequel nous travaillons inclut un fichier baker.config.js dans le répertoire racine. Ce fichier est chargé de transmettre les informations à Baker afin qu'il puisse construire correctement votre projet.
exporter par défaut {
// le répertoire où se trouvent les actifs
actifs : 'actifs',
// créer des pages
createPages : non défini,
// le répertoire de données
données : '_data',
// un domaine personnalisé facultatif à utiliser dans la création de chemins
domaine : non défini,
// un chemin ou un ensemble de chemins de chaque point d'entrée JavaScript
points d'entrée : 'scripts/app.js',
// le répertoire d'entrée global, généralement le dossier actuel
entrée : process.cwd(),
// où se trouvent les mises en page des modèles, les macros et les inclusions
mises en page : '_layouts',
// un objet avec les clés et valeurs des variables globales à être
// transmis à tous les modèles Nunjucks
nunjucksVariables : non défini,
// un objet de clé (nom) + valeur (fonction) pour ajouter une personnalisation
// filtre vers Nunjucks
nunjucksFilters : non défini,
// un objet de clé (nom) + valeur (fonction) pour ajouter une personnalisation
// tags vers Nunjucks
nunjucksTags : non défini,
// où sortir les fichiers compilés
sortie : '_dist',
// un préfixe à ajouter au début de chaque chemin résolu, comment
// les limaces fonctionnent
cheminPréfixe : '/',
// un répertoire facultatif dans lequel placer tous les actifs, rarement utilisé
racine_statique : '',} ; par défaut : ”assets”
Cela indique à Baker quel dossier traiter comme répertoire d'actifs. Vous n’aurez probablement pas besoin de changer cela.
par défaut : undefined
createPages est un paramètre facultatif qui permet de créer dynamiquement des pages à l'aide des données et des modèles du projet.
exporter par défaut {
//…
// createPage - transmet un modèle, un nom de sortie et le contexte des données
// data - les données préparées dans le dossier `_data`
createPages(createPage, data) {for (titre const de data.titles) { createPage('template.html', `${title}.html`, {context: { title }, });}
},}; par défaut : ”_data”
L'option data indique à Baker quel dossier traiter comme source de données. Vous n’aurez probablement pas besoin de changer cela.
par défaut : undefined
L'option domain indique à Baker quoi utiliser lorsqu'il crée des URL absolues. Le bakery-template le prérégle sur https://www.latimes.com .
par défaut : ”scripts/app.js”
L'option entrypoints indique à Baker quels fichiers JavaScript traiter comme points de départ pour les bundles de scripts. Il peut s'agir d'un chemin vers un fichier ou d'un fichier global, permettant de créer plusieurs bundles en même temps.
par défaut : process.cwd()
L'option input indique à Baker quel dossier traiter comme répertoire principal pour l'ensemble du projet. Par défaut, il s'agit du dossier dans lequel se trouve le fichier baker.config.js . Vous n'aurez probablement pas besoin de le définir.
par défaut : ”_layouts”
L'option layouts indique à Baker où se trouvent les modèles, les inclusions et les macros. Par défaut, il s'agit du dossier _layouts . Vous n’aurez probablement pas besoin de définir cela.
par défaut : undefined
Vous pouvez utiliser nunjucksFilters pour transmettre vos propres filtres personnalisés. Dans l'objet, chaque clé est le nom du filtre et la valeur de la fonction est ce qui est appelé lorsque vous utilisez le filtre.
exporter par défaut {
//...
// passe un objet de filtres à ajouter à Nunjucks
nunjucksFilters : {carré(n) { n = +n ; retourner n * n;}
},} {{ valeur|carré }} par défaut : undefined
Vous pouvez utiliser nunjucksTags pour transmettre vos propres balises personnalisées. Ceux-ci diffèrent des filtres dans le sens où ils facilitent la sortie de blocs de texte ou de HTML.
exporter par défaut {
//...
// passe un objet de filtres à ajouter à Nunjucks
nunjucksTags : {doubler(n) { return `<p>${n} doublé est ${n * 2}</p>`;}
},}; {% valeur double %} par défaut : ”_dist”
L'option output indique à Baker où placer les fichiers lorsque npm run build est exécuté. Par défaut, il s'agit du dossier _dist . Vous n’aurez probablement pas besoin de définir cela.
défaut: ”/”
pathPrefix indique à Baker quel préfixe de chemin ajouter à toutes les URL qu'il crée. Si domain est également transmis, il sera combiné avec pathPrefix lors de la création des URL absolues. Vous ne définirez généralement pas cela manuellement : il est utilisé lors des déploiements pour créer des URL avec des slugs de projet.
défaut: ””
L'option staticRoot demande à Baker de placer tous les actifs dans un répertoire supplémentaire. Ceci est utile pour les projets qui doivent avoir des slugs uniques sur chaque page sans imbrication, leur permettant ainsi de partager des ressources statiques. Cependant, il s'agit d'un cas particulier et nécessite une configuration personnalisée pour les déploiements. N'essayez pas de l'utiliser sans une bonne raison.


