feathr
v1.0.0

Feathr est une plateforme d'ingénierie de données et d'IA largement utilisée en production chez LinkedIn depuis de nombreuses années et qui a été open source en 2022. Il s'agit actuellement d'un projet sous LF AI & Data Foundation.
Lisez notre annonce sur Open Sourcing Feathr et Feathr sur Azure, ainsi que l'annonce de LF AI & Data Foundation.
Featherr vous permet de :
Feathr est particulièrement utile dans la modélisation de l'IA où il calcule automatiquement vos transformations de fonctionnalités et les associe à vos données d'entraînement, en utilisant une sémantique ponctuelle correcte pour éviter les fuites de données, et prend en charge la matérialisation et le déploiement de vos fonctionnalités pour une utilisation en ligne en production.
Le moyen le plus simple d'essayer Feathr est d'utiliser le Feathr Sandbox qui est un conteneur autonome doté de la plupart des capacités de Feathr et vous devriez être productif en 5 minutes. Pour l'utiliser, exécutez simplement cette commande :
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0Et vous pouvez consulter le notebook Jupyter de démarrage rapide Feather :
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbAprès avoir exécuté le notebook, toutes les fonctionnalités seront enregistrées dans l'interface utilisateur et vous pourrez visiter l'interface utilisateur Feathr à l'adresse :
http://localhost:8081Si vous souhaitez installer le client Featherr dans un environnement Python, utilisez ceci :
pip install feathrOu utilisez le dernier code de GitHub :
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr dispose d'intégrations natives avec Databricks et Azure Synapse :
Suivez le guide de déploiement Feathr ARM pour exécuter Feathr sur Azure. Cela vous permet de démarrer rapidement avec le déploiement automatisé à l’aide du modèle Azure Resource Manager.
Si vous souhaitez tout configurer manuellement, vous pouvez consulter le guide de déploiement Feathr CLI pour exécuter Feathr sur Azure. Cela vous permet de comprendre ce qui se passe et de configurer une ressource à la fois.
| Nom | Description | Plate-forme |
|---|---|---|
| Démo de taxi à New York | Carnet de démarrage rapide qui montre comment définir, matérialiser et enregistrer des fonctionnalités avec des exemples de données de prédiction des tarifs de taxi à New York. | Azure Synapse, Databricks, Spark local |
| Démo de taxi de New York Quickstart Databricks | Carnet de démarrage rapide Databricks avec des exemples de données de prévision des tarifs de taxi à New York. | Briques de données |
| Intégration de fonctionnalités | Exemple Feathr UDF montrant comment définir et utiliser l'intégration de fonctionnalités avec un modèle Transformer pré-entraîné et des exemples de données d'avis d'hôtel. | Briques de données |
| Démo de détection de fraude | Un exemple pour démontrer Feature Store utilisant plusieurs sources de données telles que les données de compte utilisateur et de transaction. | Azure Synapse, Databricks, Spark local |
| Démo de recommandation de produit | Exemple de bloc-notes Featherr Feature Store avec un scénario de recommandation de produit | Azure Synapse, Databricks, Spark local |
Veuillez lire Featherr Full Capabilities pour plus d’exemples. En voici quelques-unes sélectionnées :
Feathr fournit une interface utilisateur intuitive afin que vous puissiez rechercher et explorer toutes les fonctionnalités disponibles et leurs lignées correspondantes.
Vous pouvez utiliser Feathr UI pour rechercher des fonctionnalités, identifier des sources de données, suivre les lignées de fonctionnalités et gérer les contrôles d'accès. Découvrez la dernière démo en direct ici pour voir ce que Feathr UI peut faire pour vous. Utilisez l'un des comptes suivants lorsque vous êtes invité à vous connecter :
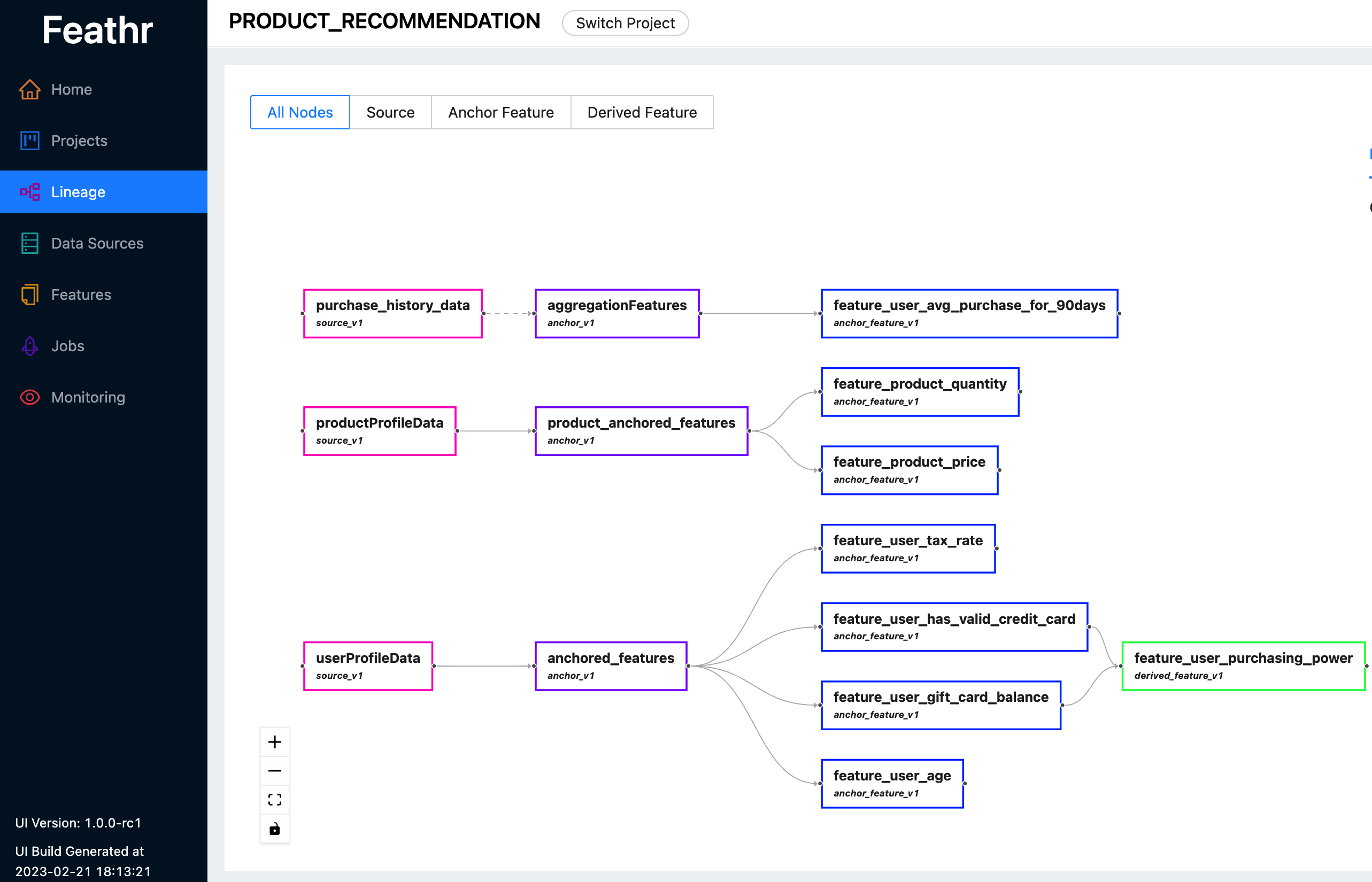
Pour plus d'informations sur l'interface utilisateur Feathr et le registre qui la sous-tend, veuillez vous référer au registre des fonctionnalités Feathr.
Feathr propose des UDF hautement personnalisables avec une intégration native de PySpark et Spark SQL pour réduire la courbe d'apprentissage des data scientists :
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Lisez le Guide d’ingestion de sources de streaming pour plus de détails.
Lisez Exactitude ponctuelle et Rejoignez-nous à un moment précis dans Feathr pour plus de détails.
Suivez le démarrage rapide de Jupyter Notebook pour l'essayer. Il existe également un guide de démarrage rapide complémentaire contenant un peu plus d'explications sur le portable.
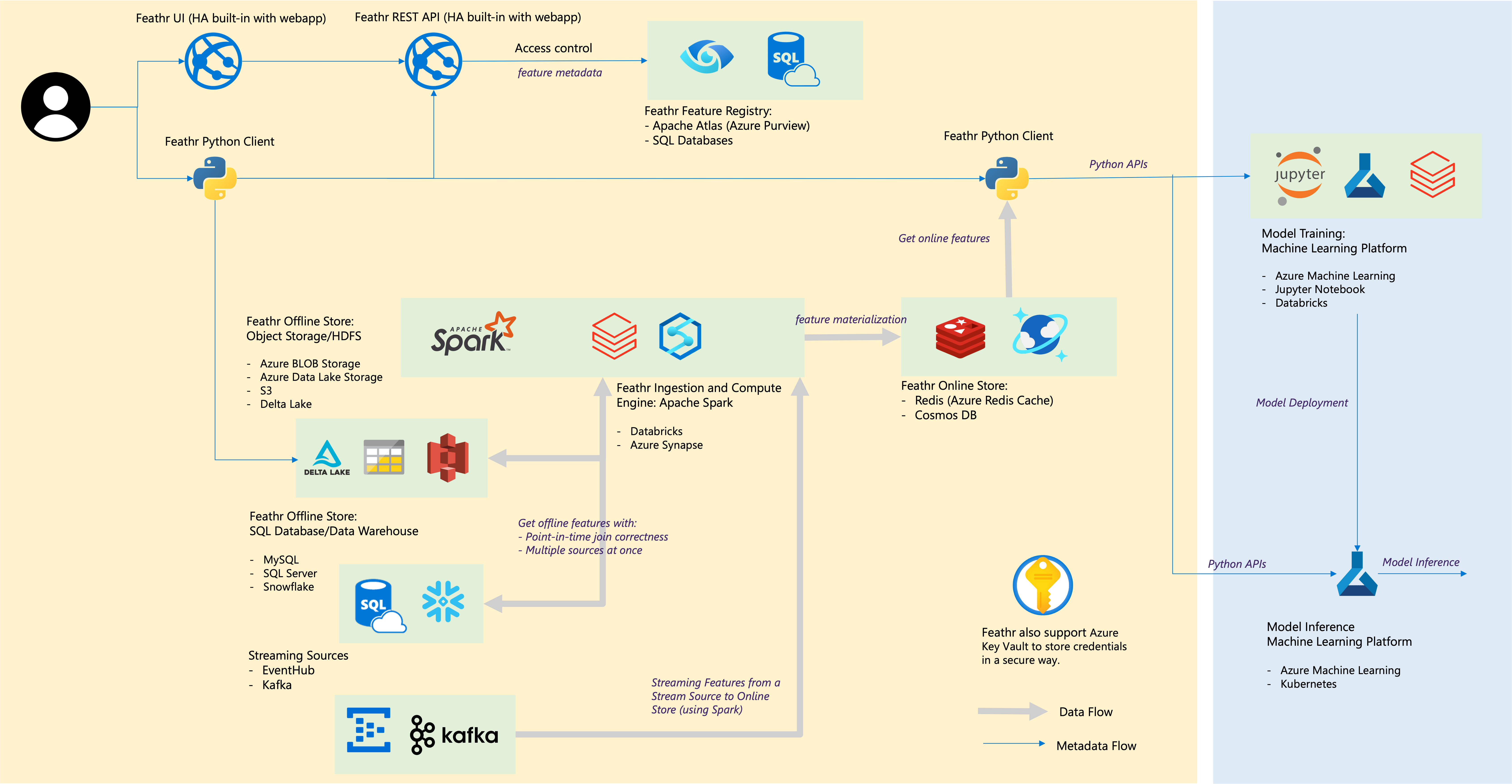
| Composant plume | Intégrations cloud |
|---|---|
| Boutique hors ligne – Boutique d'objets | Stockage Blob Azure, Azure ADLS Gen2, AWS S3 |
| Boutique hors ligne – SQL | Azure SQL DB, pools SQL dédiés Azure Synapse, Azure SQL dans VM, Snowflake |
| Source de diffusion | Kafka, EventHub |
| Boutique en ligne | Redis, Azure Cosmos DB |
| Registre des fonctionnalités et gouvernance | Azure Purview, ANSI SQL tel qu'Azure SQL Server |
| Moteur de calcul | Pools Azure Synapse Spark, Databricks |
| Plateforme d'apprentissage automatique | Azure Machine Learning, bloc-notes Jupyter, bloc-notes Databricks |
| Format de fichier | Parquet, ORC, Avro, JSON, Delta Lake, CSV |
| Informations d'identification | Coffre de clés Azure |
Construire pour la communauté et construire par la communauté. Consultez les directives de la communauté.
Rejoignez notre chaîne Slack pour des questions et des discussions (ou cliquez sur le lien d'invitation).


