eye in the sky
1.0.0
Classification des images satellite, InterIIT Techmeet 2018, IIT Bombay.
Équipe : Manideep Kolla, Aniket Mandle, Apoorva Kumar
Ce référentiel contient l'implémentation de deux algorithmes à savoir U-Net : Convolutional Networks for Biomedical Image Segmentation et Pyramid Scene Parsing Network modifié pour le problème de classification d'images satellite.
main_unet.py : Code Python pour entraîner l'algorithme avec l'architecture U-Net incluant l'encodage des vérités terrain.unet.py : Contient notre implémentation des couches U-Net.test_unet.py : Code pour les tests, calcul des précisions, calcul des matrices de confusion pour la formation et la validation et sauvegarde des prédictions par le modèle U-Net sur les images de formation, de validation et de test.Inter-IIT-CSRE : Contient toutes les données de formation, de validation et de tests.Comparison_Test.pdf : Comparaison côte à côte des données de test avec les prédictions du modèle U-Net sur les données.train_predictions : prédictions du modèle U-Net sur les images d'entraînement et de validation.plots : Tracés de précision et de perte pour la formation et la validation de l'architecture U-Net.Test_images , Test_outputs : Contient des images de test et leurs prédictions du modèle U-Net.class_masks , compare_pred_to_gt , images_for_doc : Contient plusieurs images pour la documentation.PSPNet : Contient des fichiers de formation pour la mise en œuvre de l'algorithme PSPNet pour la classification des images satellite. Clonez le référentiel, remplacez votre répertoire de travail actuel par le répertoire cloné. Créez des dossiers avec les noms train_predictions et test_outputs pour enregistrer les sorties prévues du modèle sur les images d'entraînement et de test (non requis maintenant car le dépôt contient déjà ces dossiers)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
Pour entraîner le modèle U-Net et économiser des poids, exécutez la commande ci-dessous
$ python3 main_unet.py
Pour tester le modèle U-Net, calculer les précisions, calculer les matrices de confusion pour la formation et la validation et enregistrer les prédictions du modèle sur les images de formation, de validation et de test.
$ python3 test_unet.py
Vous pourriez obtenir une erreur xrange is not defined lors de l'exécution de notre code. Cette erreur n'est pas due à des erreurs dans notre code mais à un package python non à jour nommé libtiff (certaines parties du code source du package sont en python2 et d'autres en python3) que nous avons utilisé pour lire l'ensemble de données dans lequel les images sont au format .tif. Nous n'avons pas pu utiliser d'autres bibliothèques comme openCV ou PIL pour lire les images car elles ne prennent pas correctement en charge la lecture des images .tif à 4 canaux.
Cette erreur peut être résolue en éditant le code source de la bibliothèque libtiff .
Accédez au fichier dans le code source de la bibliothèque d'où survient l'erreur (le nom du fichier sera affiché dans le terminal lorsqu'il affichera l'erreur) et remplacez toutes les fonctions xrange() (python2) du fichier par range() (python3).
Nous fournissons ici des poids pré-entraînés raisonnablement bons afin que les utilisateurs n'aient pas besoin de s'entraîner à partir de zéro.
| Description | Tâche | Ensemble de données | Modèle |
|---|---|---|---|
| Architecture UNet | Classification des images satellites | Ensemble de données IITB (voir dossier Inter-IIT-CSRE ) | télécharger (.h5) |
Pour utiliser les poids pré-entraînés, modifiez le nom du fichier .h5 (fichier de poids) mentionné dans test_unet.py pour qu'il corresponde au nom du fichier de poids que vous avez téléchargé, si nécessaire.
Discutons maintenant
1. De quoi parle ce projet,
2. Architectures que nous avons utilisées et expérimentées et
3. Quelques nouvelles stratégies de formation que nous avons utilisées dans le projet
La télédétection est la science qui consiste à obtenir des informations sur des objets ou des zones à distance, généralement à partir d'avions ou de satellites.
Nous avons réalisé le problème de la classification des images satellites comme un problème de segmentation sémantique et avons construit des algorithmes de segmentation sémantique en apprentissage profond pour résoudre ce problème.
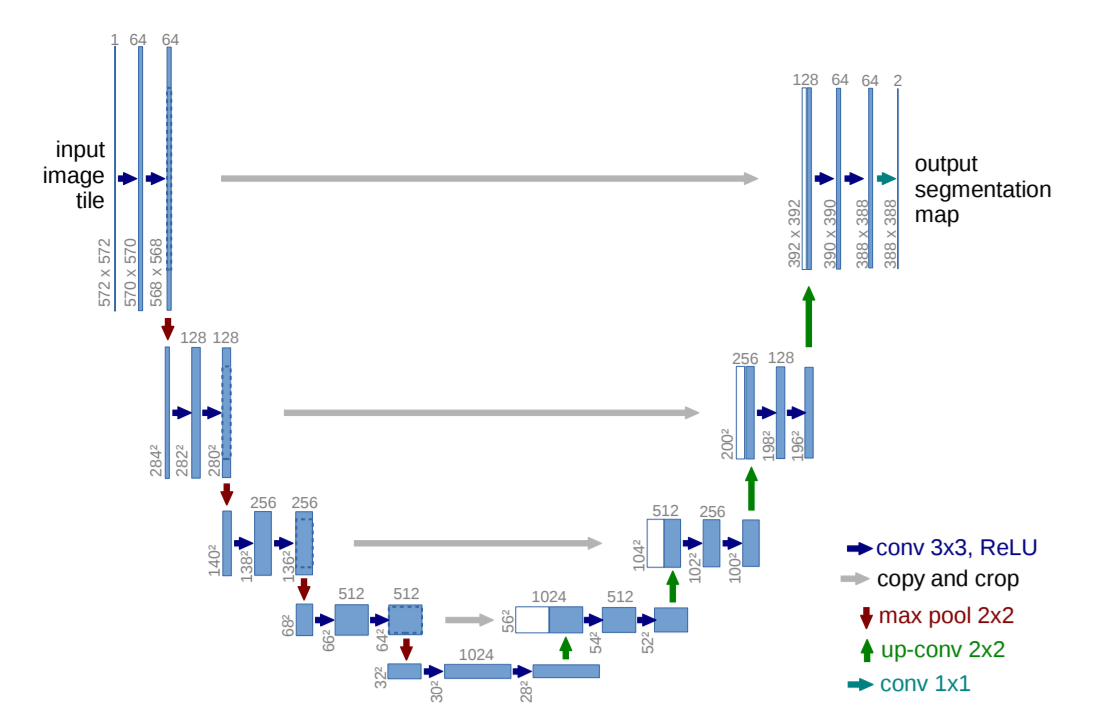
U-Net : réseaux convolutifs pour la segmentation d'images biomédicales
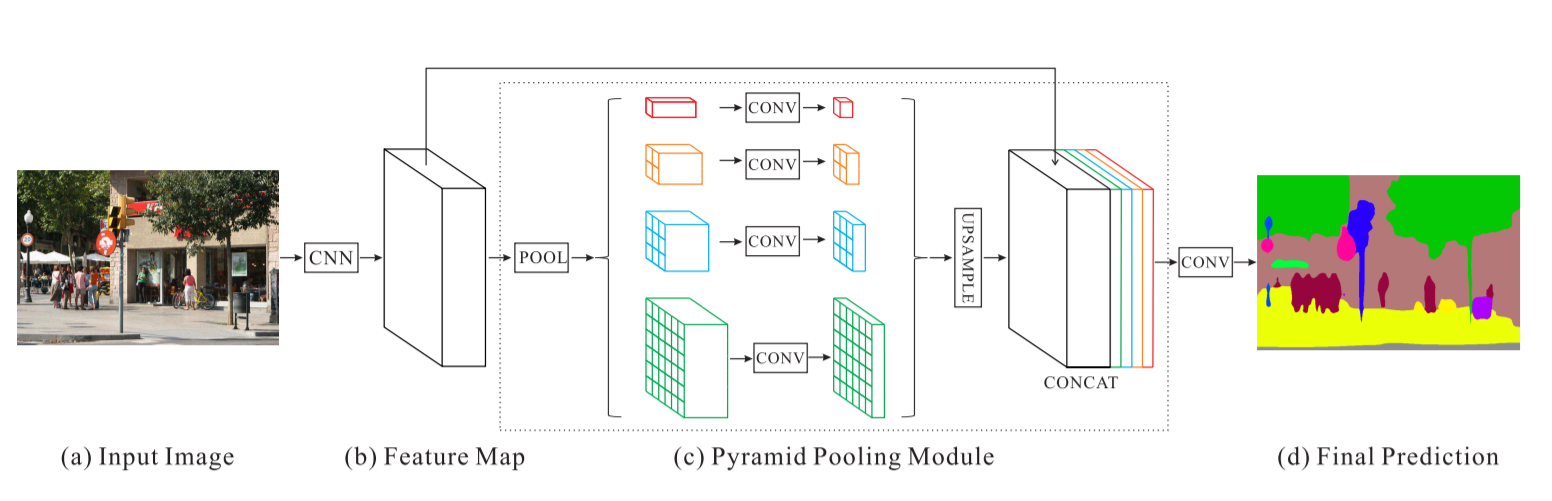
Réseau d'analyse de scènes pyramidales - PSPNet
Les vérités fondamentales fournies sont des images RVB à 3 canaux. Dans l'ensemble de données actuel, il n'y a que 9 valeurs RVB uniques dans les vérités terrain, car 9 classes doivent être classées. Ces 9 valeurs RVB différentes sont codées à chaud pour générer une vérité terrain codée à 9 canaux, chaque canal représentant une classe particulière.
Ci-dessous le schéma de codage
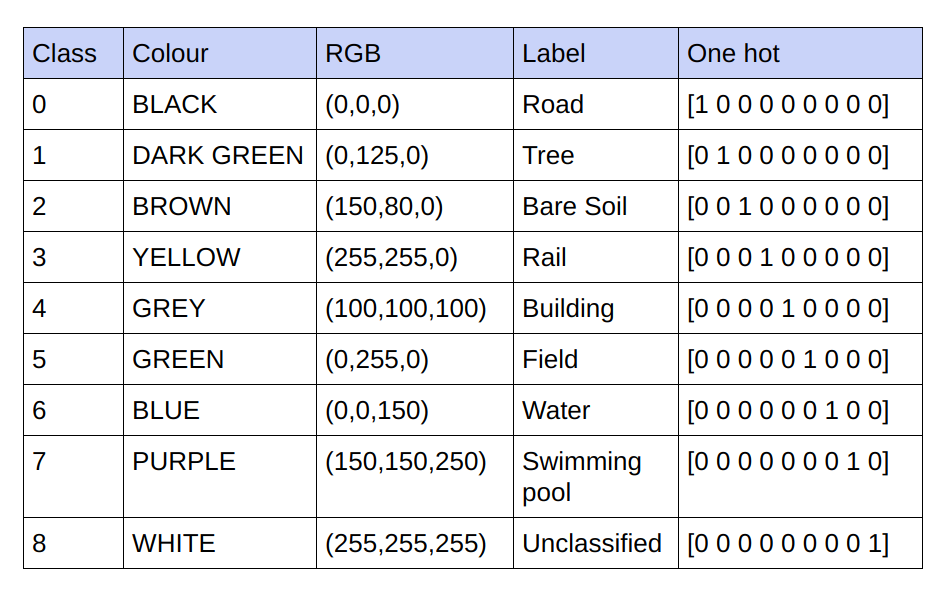
Réalisation de chaque canal dans la vérité terrain codée en tant que classe

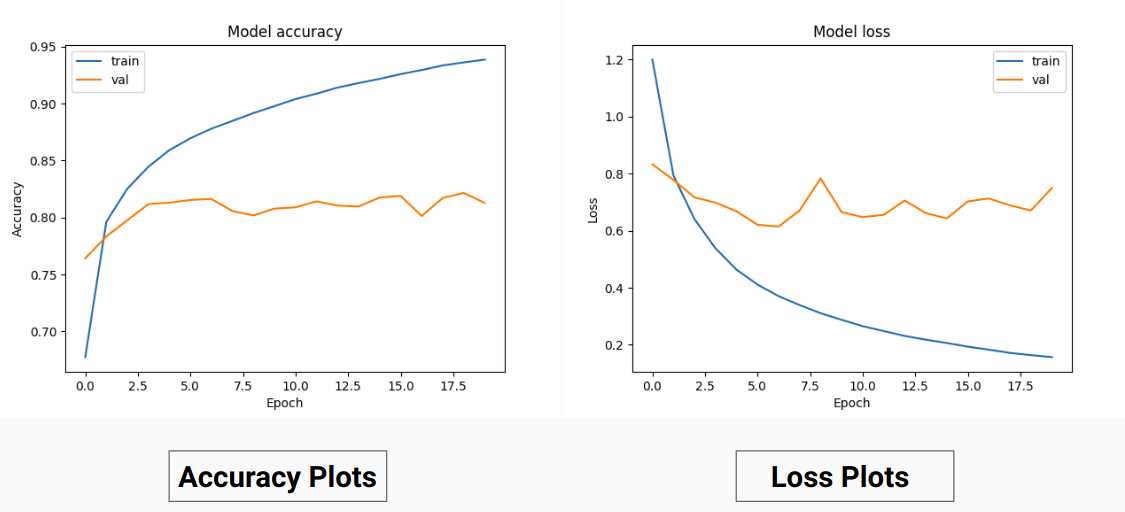
Ainsi, au lieu de nous entraîner sur les valeurs RVB de la vérité terrain, nous les avons converties en valeurs ponctuelles de différentes classes. Cette approche nous a donné une précision de validation de 85 % et une précision de formation de 92 %, contre 71 % de précision de validation et 65 % de précision de formation lorsque nous utilisions les valeurs de vérité terrain RVB pour la formation.
Cela pourrait être dû à une diminution de la variance et de la moyenne de la vérité terrain des données d'entraînement, car elle agit comme une technique de normalisation efficace. Les meilleures performances de cette technique de formation sont également dues au fait que le modèle donne une sortie avec 9 cartes de caractéristiques, chaque carte indiquant une classe, c'est-à-dire que cette technique de formation agit comme si le modèle était formé sur chacune des 9 classes séparément dans une certaine mesure ( mais ici définitivement la prédiction sur un canal qui correspond à une classe particulière dépend des autres) .
Nos résultats sur PSPNet pour la classification des images satellites :
Précision de la formation - 49 % Précision de la validation - 60 %
Raisons :
U-Net :
U-Net modifié :
Pour la formation et la validation, nous avons utilisé les 14 images '.tif' dans le dossier Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset .
Pour la formation, nous avons utilisé les 13 premières images de l'ensemble de données et pour la validation, la 14ème image est utilisée .
Chaque image satellite du dossier sat contient 4 canaux à savoir R (Band 1), G (Band 2), B (Band 3) et NIR (Band 4).
Les images de vérité terrain dans le répertoire gt sont des images RVB et représentent 8 classes : routes, bâtiments, arbres, herbe, sol nu, eau, chemins de fer et piscines.
La raison pour laquelle nous n'avons considéré qu'une seule image (14ème image) comme ensemble de validation est qu'il s'agit de l'une des plus petites images de l'ensemble de données et nous ne voulons pas laisser moins de données pour l'entraînement car l'ensemble de données est assez petit. L'ensemble de validation (14ème image) que nous avons considéré ne contient pas 3 classes (sol nu, rail, sondage Swimmimg) qui ont des précisions d'entraînement assez élevées. La précision de la validation aurait été meilleure si nous avions considéré une image contenant toutes les classes (aucune image dans l'ensemble de données ne contient toutes les classes, il manque au moins une classe dans toutes les images).
Le recadrage strié :
Pour disposer de données de formation suffisantes à partir des images haute définition données, un recadrage est nécessaire pour former le classificateur qui possède environ 31 millions de paramètres de notre implémentation U-Net. Avec la taille de recadrage de 64x64, nous constatons une sous-représentation des classes individuelles et la géométrie et la continuité des objets sont perdues, diminuant le champ de vision des circonvolutions.
Utilisation d'une fenêtre de recadrage de 128x128 pixels avec une foulée de 32 résultante de 15887 entraînements de 414 images de validation.
Dimensions de l'image :
Avant le recadrage, les dimensions des images d'entraînement sont converties en multiples de foulée pour plus de commodité lors du recadrage par foulée.
Pour les cas où le no. des cultures n'est pas le multiple des dimensions de l'image que nous avons initialement essayé avec un remplissage nul, nous avons réalisé que l'ajout d'un remplissage ajouterait des artefacts indésirables sous la forme de pixels noirs dans les images d'entraînement et de test conduisant à un entraînement sur de fausses données et des limites d'image.
Alternativement, nous avons correctement modifié les dimensions de l'image en ajoutant des pixels supplémentaires à l'extrême droite et en bas de l'image. Nous avons donc comblé la différence entre la partie la plus à gauche de l'image et son extrémité droite déficitaire et de la même manière pour le haut et le bas de l'image.
Exemple de formation 1 : Image « 2.tif » à partir des données de formation
Exemple de formation 2 : Image « 4.tif » à partir des données de formation
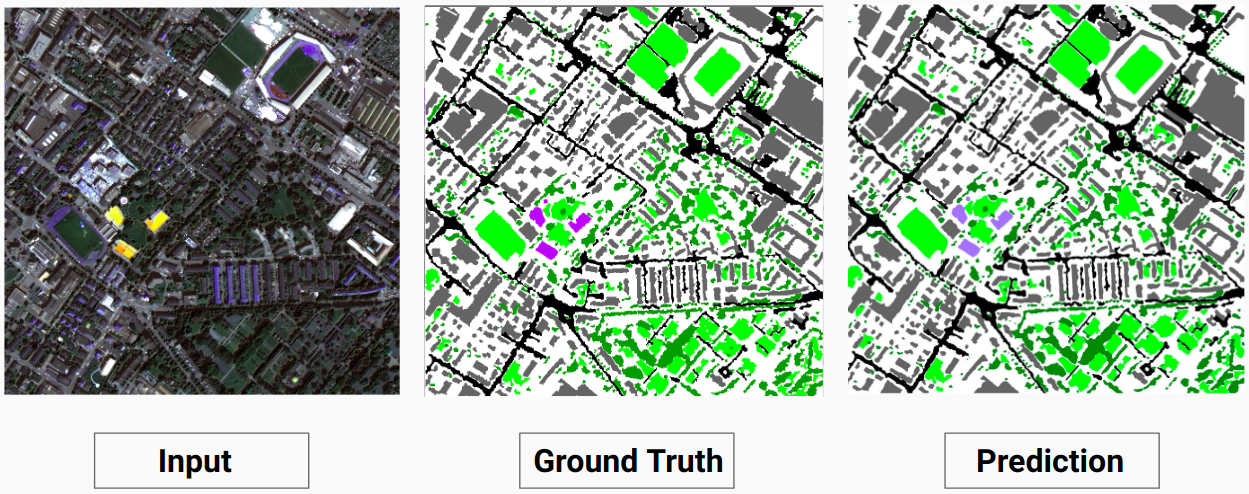
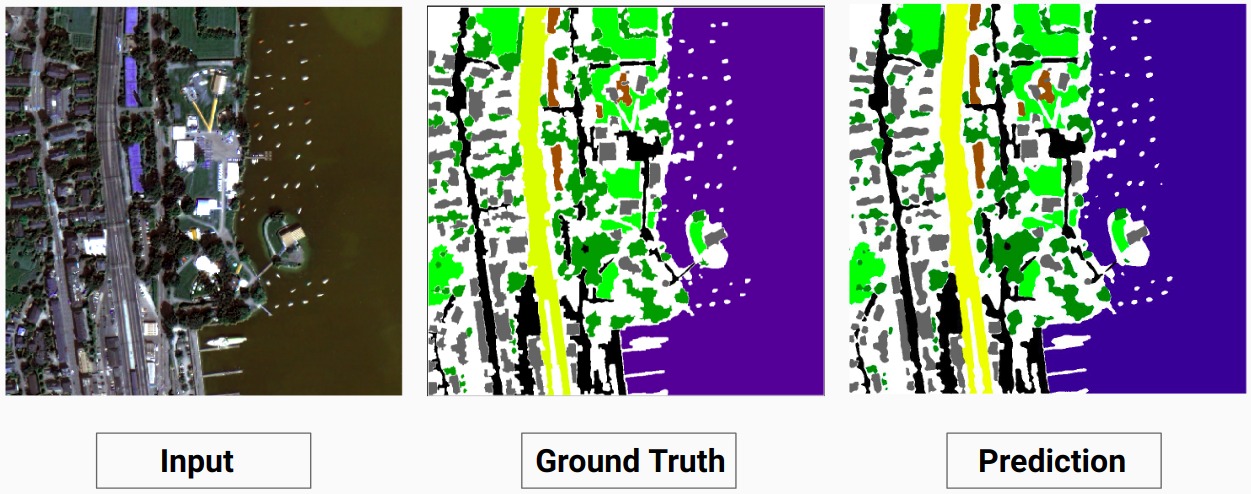
Exemple de validation : image « 14.tif » de l'ensemble de données

Notre modèle est capable de prédire certaines classes, ce qu'un annotateur humain n'était pas capable de faire. Les classes non identifiables dans les images sont étiquetées comme pixels blancs par l'annotateur humain. Notre modèle est capable de prédire correctement certains de ces pixels blancs en tant que classe, mais cela a entraîné une diminution de la précision globale car les pixels blancs sont considérés comme une classe distincte par le modèle.
Ici, le modèle est capable de prédire les pixels blancs comme un bâtiment, ce qui est correct et clairement visible dans l'image d'entrée.
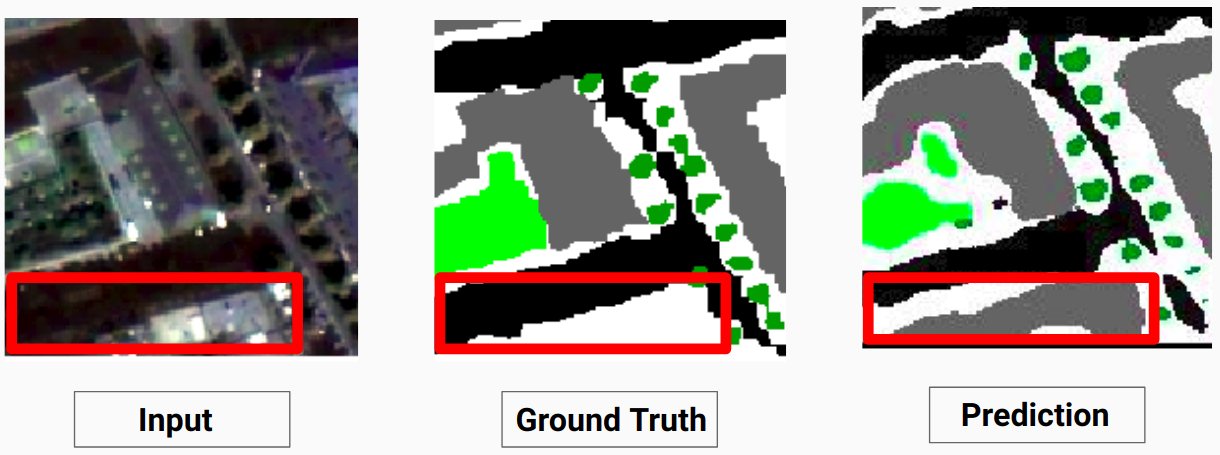
Consultez Comparison_Test.pdf pour une comparaison entre les images de test et leurs sorties prévues par le modèle
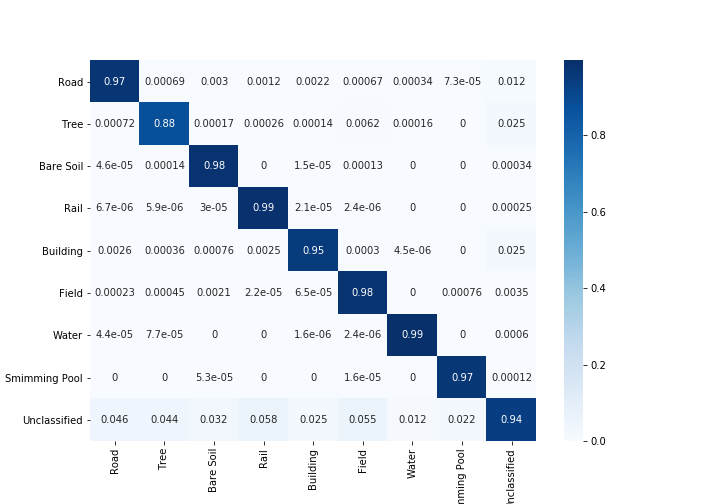
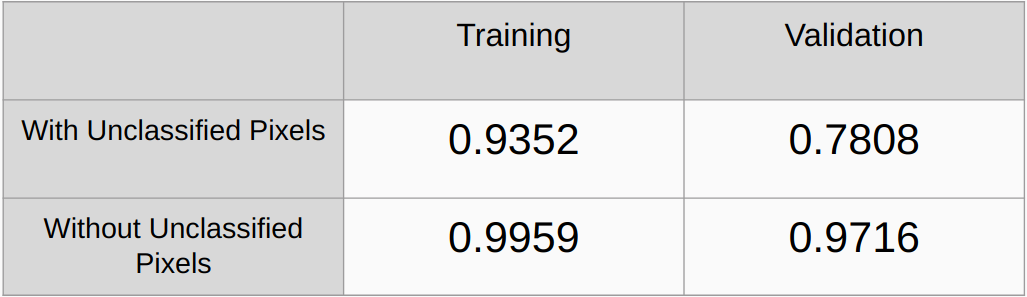
Coefficients Kappa Avec et Sans en considérant les pixels non classés
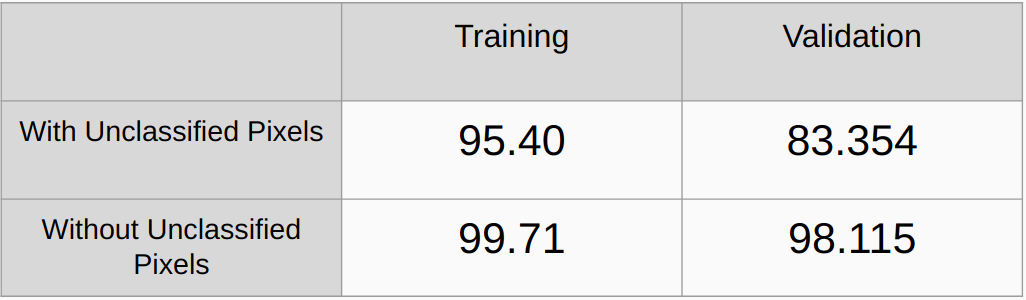
Précision globale avec et sans prise en compte des pixels non classés
Besoin d'ajouter des méthodes de régularisation telles que la régularisation L2 et l'abandon et de vérifier les performances
Implémentez un algorithme pour détecter automatiquement toutes les valeurs RVB uniques dans les vérités fondamentales et les encoder à chaud au lieu de trouver manuellement les valeurs RVB.
[1] U-Net : Réseaux convolutifs pour la segmentation d'images biomédicales, Olaf Ronneberger, Philipp Fischer et Thomas Brox
[2] Réseau d'analyse de scènes pyramidales, Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
[3] Un guide 2017 sur la segmentation sémantique avec le Deep Learning, Sasank Chilamkurthy


