linformer pytorch
version
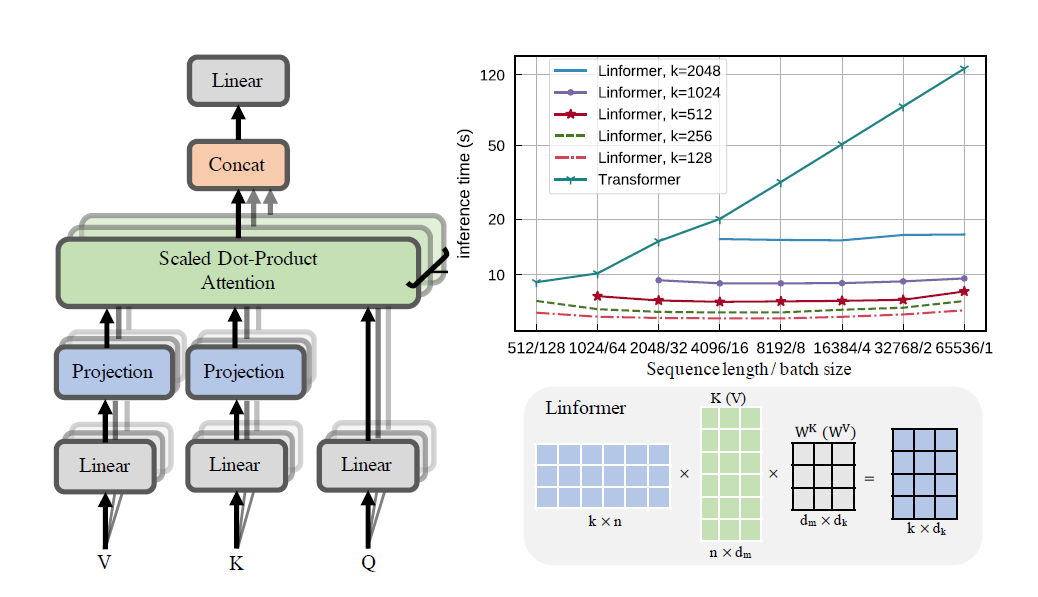
Une mise en œuvre pratique de l'article de Linformer. Il s'agit d'une attention avec seulement une complexité linéaire en n, permettant de s'occuper de très longues longueurs de séquence (1 mil+) sur du matériel moderne.
Ce référentiel est un transformateur de style Attention Is All You Need, complet avec un module encodeur et décodeur. La nouveauté ici est que désormais, on peut rendre les têtes d'attention linéaires. Découvrez comment l’utiliser ci-dessous.
Ceci est en cours de validation sur wikitext-2. Actuellement, il fonctionne au même niveau que d’autres mécanismes d’attention clairsemés, comme le Sinkhorn Transformer, mais les meilleurs hyperparamètres doivent encore être trouvés.
La visualisation des têtes est également possible. Pour voir plus d’informations, consultez la section Visualisation ci-dessous.
Je ne suis pas l'auteur de l'article.
1,23 million de jetons
pip install linformer-pytorch
Alternativement,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Modèle de langage Linformer
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer auto-attention, piles de MHAttention et FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer Multihead attention
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)La tête d'attention linéaire, la nouveauté du papier
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Un module encodeur/décodeur.
Remarque : Pour les séquences causales, on peut activer l'indicateur causal=True dans le LinformerLM pour masquer le coin supérieur droit dans la matrice d'attention (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Un moyen simple d’obtenir les matrices E et F peut être effectué en appelant la fonction get_EF . A titre d'exemple, pour un n de 1000 et un k de 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) Avec l'indicateur method , on peut définir la méthode avec laquelle le linformer effectue le sous-échantillonnage. Actuellement, trois méthodes sont prises en charge :
learnable : Cette méthode de sous-échantillonnage crée un module n,k nn.Linear apprenable.convolution : Cette méthode de sous-échantillonnage crée une convolution 1D, avec une longueur de foulée et une taille de noyau n/k .no_params : Cela crée une matrice n,k fixe avec des valeurs de N(0,1/k)À l’avenir, je pourrai inclure la mutualisation ou autre chose. Mais pour l’instant, ce sont les options qui existent.
Pour tenter d'introduire davantage d'économies de mémoire, le concept de niveaux de points de contrôle a été introduit. Les trois niveaux de points de contrôle actuels sont C0 , C1 et C2 . Lorsqu'on monte des niveaux de points de contrôle, on sacrifie la vitesse au profit des économies de mémoire. Autrement dit, le niveau de point de contrôle C0 est le plus rapide, mais occupe le plus d'espace sur le GPU, tandis que C2 est le plus lent, mais occupe le moins d'espace sur le GPU. Les détails de chaque niveau de point de contrôle sont les suivants :
C0 : Pas de point de contrôle. Les modèles fonctionnent tout en conservant toutes les têtes d'attention et les couches ff dans la mémoire GPU.C1 : Checkpoint de chaque attention MultiHead ainsi que de chaque couche ff. Ainsi, l’augmentation depth devrait avoir un impact minimal sur la mémoire.C2 : Parallèlement aux optimisations au niveau C1 , vérifiez chaque tête dans chaque couche MultiHead Attention. Avec cela, l’augmentation nhead devrait avoir moins d’impact sur la mémoire. Cependant, concilier les têtes avec torch.cat prend encore beaucoup de mémoire, et cela sera, espérons-le, optimisé à l'avenir.Les détails des performances sont encore inconnus, mais l'option existe pour les utilisateurs qui souhaitent essayer.
Une autre tentative visant à introduire des économies de mémoire dans le document consistait à introduire le partage de paramètres entre les projections. Ceci est mentionné dans la section 4 du document ; en particulier, les auteurs ont discuté de 4 types différents de partage de paramètres, et tous ont été implémentés dans ce référentiel. La première option occupe le plus de mémoire et chaque option suivante réduit les besoins en mémoire nécessaires.
none : Il ne s'agit pas de partage de paramètres. Pour chaque tête et pour chaque couche, une nouvelle matrice E et une nouvelle matrice F est calculée pour chaque tête de chaque couche.headwise : Chaque couche a une matrice E et F unique. Toutes les têtes de la couche partagent cette matrice.kv : Chaque couche a une matrice de projection unique P , et E = F = P pour chaque couche. Toutes les têtes partagent cette matrice de projection P .layerwise : il existe une matrice de projection P , et chaque tête de chaque couche utilise E = F = P . Comme indiqué dans l'article, cela signifie que pour un réseau à 12 couches et 12 têtes, il y aurait respectivement 288 , 24 , 12 et 1 matrices de projection différentes.
Notez qu'avec l'option k_reduce_by_layer , l'option layerwise ne sera pas efficace, puisqu'elle utilisera la dimension de k pour le premier calque. Par conséquent, si la valeur de k_reduce_by_layer est supérieure à 0 , il ne faut probablement pas utiliser l'option de partage layerwise .
A noter également que selon les auteurs, dans la figure 3, ce partage de paramètres n'affecte pas vraiment trop le résultat final. Il est donc peut-être préférable de s'en tenir au partage layerwise pour tout, mais les utilisateurs ont la possibilité de l'essayer.
Un léger problème avec l'implémentation actuelle de Linformer est que la longueur de votre séquence doit correspondre à l'indicateur input_size du modèle. Le Padder complète la taille d'entrée de telle sorte que le tenseur puisse être introduit dans le réseau. Un exemple :
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 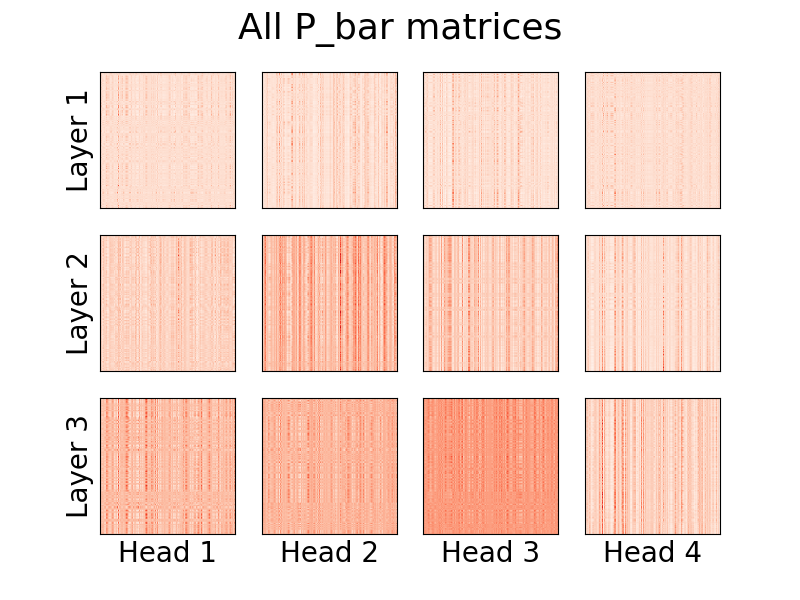
A partir de la version 0.8.0 , on peut désormais visualiser les têtes d'attention du linformer ! Pour voir cela en action, importez simplement la classe Visualizer et exécutez la fonction plot_all_heads() pour voir une image de toutes les têtes d'attention à chaque niveau, de taille (n,k). Assurez-vous de spécifier visualize=True dans la passe avant, car cela enregistre la matrice P_bar afin que la classe Visualizer puisse visualiser correctement la tête.
Un exemple fonctionnel du code peut être trouvé ci-dessous, et le même code peut être trouvé dans ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Une explication détaillée de la signification de ces têtes peut être trouvée au #15.
Semblable au Reformer, je vais essayer de créer un module encodeur/décodeur, afin que la formation puisse être simplifiée. Cela fonctionne comme 2 classes LinformerLM . Les paramètres peuvent être ajustés individuellement pour chacun, l'encodeur ayant le préfixe enc_ pour tous les hyperparams et le décodeur ayant le préfixe dec_ de la même manière. Jusqu’à présent, ce qui est mis en œuvre est :
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Je prévois d'avoir un moyen de générer une séquence de texte pour cela.
ff_intermediate Désormais, la dimension du modèle peut être différente dans les couches intermédiaires. Ce changement s'applique au module ff, et uniquement à l'encodeur. Maintenant, si le drapeau ff_intermediate n'est pas Aucun, les couches ressembleront à ceci :
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
Contrairement à
channels -> ff_dim -> channels (For all layers)
input_size et dim_k , respectivement.apex devraient fonctionner avec cela, mais dans la pratique, cela n'a pas été testé.input_size , k= dim_k et d= dim_d . LinformerEncDec C'est la première fois que je reproduis un résultat à partir d'un article, donc certaines choses peuvent être fausses. Si vous rencontrez un problème, veuillez ouvrir un problème et j'essaierai d'y travailler.
Merci à lucidrains, dont les autres référentiels d'attention clairsemés m'ont aidé dans la conception de ce Linformer Repo.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"Écoutez avec attention..."


