intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? Signaux de trading intelligents ? https://t.me/intelligent_trading_signals
Le projet vise à développer un robot de trading intelligent pour le trading automatisé de crypto-monnaies en utilisant des algorithmes d'apprentissage automatique (ML) de pointe et une ingénierie de fonctionnalités. Le projet fournit les fonctionnalités majeures suivantes :
Le service de signalisation fonctionne dans le cloud et envoie ses signaux à ce canal Telegram :
? Signaux de trading intelligents ? https://t.me/intelligent_trading_signals
Tout le monde peut s'abonner à la chaîne pour avoir une idée des signaux générés par ce bot.
Actuellement, le bot est configuré à l'aide des paramètres suivants :
Il y a des périodes de silence pendant lesquelles le score est inférieur au seuil et aucune notification n'est envoyée à la chaîne. Si le score est supérieur au seuil, alors chaque minute une notification est envoyée qui ressemble à
₿ 24.518 ??? Note : -0,26
Le premier chiffre est le dernier cours de clôture. Le score -0,26 signifie qu'il est très probable que le prix soit inférieur au prix de clôture actuel.
Si le score dépasse un certain seuil spécifié dans le modèle, un signal d'achat ou de vente est généré, ce qui signifie que c'est le bon moment pour effectuer une transaction. Ces notifications se présentent comme suit :
? ACHETER : ₿ 24 033 Score : +0,34
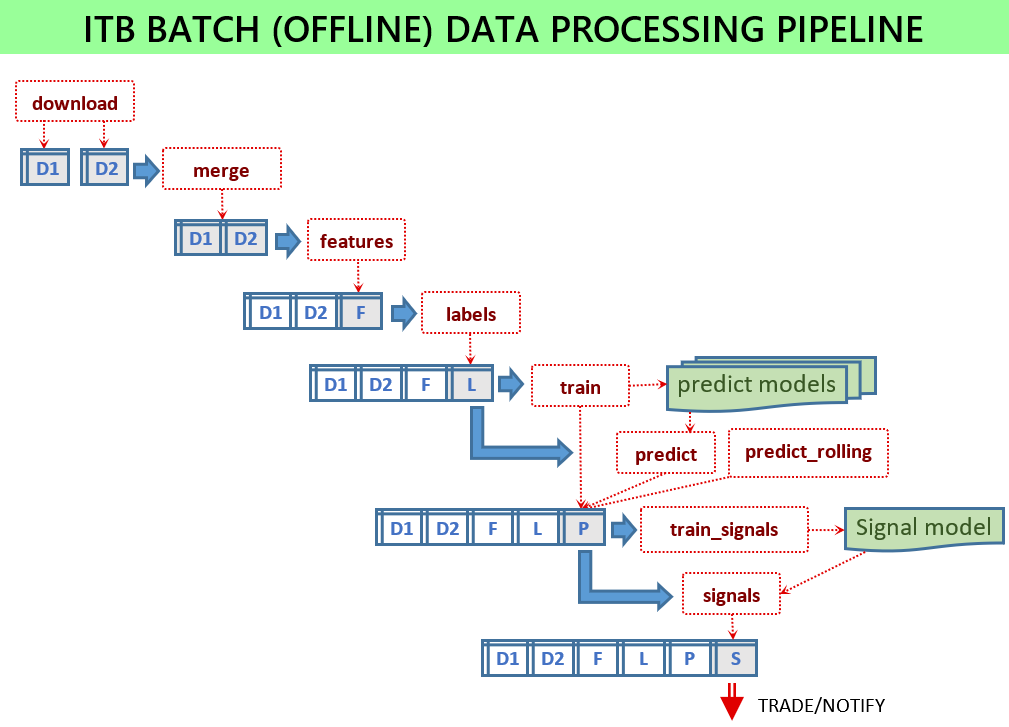
Pour que le service de signalement fonctionne, un certain nombre de modèles ML doivent être formés et les fichiers modèles disponibles pour le service. Tous les scripts s'exécutent en mode batch en chargeant certaines données d'entrée et en stockant certains fichiers de sortie. Les scripts batch se trouvent dans le module scripts .
Si tout est configuré alors les scripts suivants doivent être exécutés :
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json Sans fichier de configuration, les scripts utiliseront les paramètres par défaut, ce qui est utile à des fins de test et non destiné à afficher de bonnes performances. Utilisez des exemples de fichiers de configuration fournis pour chaque version, comme config-sample-v0.6.0.jsonc .
Le paramètre de configuration principal pour les deux scripts est une liste de sources dans data_sources . Une entrée de cette liste spécifie une source de données ainsi que column_prefix utilisé pour distinguer les colonnes portant le même nom provenant de différentes sources.
Téléchargez les dernières données historiques : python -m scripts.download_binance -c config.json
Fusionnez plusieurs ensembles de données historiques en un seul ensemble de données : python -m scripts.merge -c config.json
Ce script est destiné au calcul des fonctionnalités dérivées :
python -m scripts.features -c config.json La liste des fonctionnalités à générer est configurée via la liste feature_sets dans le fichier de configuration. La manière dont les fonctionnalités sont générées est définie par le générateur de fonctionnalités, chacun ayant certains paramètres spécifiés dans sa section de configuration.
talib s'appuie sur la bibliothèque d'analyse technique TA-lib. Voici un exemple de sa configuration : "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats implémente des fonctions qui peuvent être trouvées dans tsfresh comme scipy_skew , scipy_kurtosis , lsbm (frappe la plus longue en dessous de la moyenne), fmax (premier emplacement du maximum), mean , std , area , slope . Voici les paramètres typiques : "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib implémenté dans ITB mais la plupart de ses fonctionnalités peuvent être générées (beaucoup plus rapidement) via talibtsfresh génère des fonctions à partir de la bibliothèque tsfresh Ce script est similaire à la génération de fonctionnalités car il ajoute de nouvelles colonnes au fichier d'entrée. Cependant, ces colonnes décrivent quelque chose que nous voulons prédire et ce qui n'est pas connu lors de l'exécution en mode en ligne. Par exemple, il pourrait s’agir d’une augmentation des prix à l’avenir :
python -m scripts.labels -c config.json La liste des étiquettes à générer est configurée via la liste label_sets dans la configuration. Un jeu d'étiquettes pointe vers la fonction qui génère des colonnes supplémentaires. Leur configuration est très similaire aux configurations de fonctionnalités.
highlow renvoie True si le prix est supérieur au seuil spécifié dans un horizon futur.highlow2 Calcule les augmentations (diminutions) futures à condition qu'il n'y ait pas de diminutions (augmentations) significatives avant cela. Voici sa configuration type "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot Obsolètetopbot2 Calcule les valeurs maximales et minimales (étiquetées comme True). Chaque maximum (minimum) étiqueté est garanti être entouré de minimums (maximums) inférieurs (supérieurs) au niveau spécifié. La différence minimale requise entre les minimums et maximums adjacents est spécifiée via les paramètres level . Le paramètre tolérance permet d'inclure également des points proches du maximum/minimum. Voici une configuration typique : "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} Ce script utilise les fonctionnalités d'entrée et les étiquettes spécifiées pour entraîner plusieurs modèles ML :
python -m scripts.train -c config.jsonprediction-metrics.txt avec les scores de prédiction pour tous les modèlesConfiguration:
model_store.pytrain_featureslabelsalgorithms Le but de cette étape est d’agréger les scores de prédiction générés par différents algorithmes pour différentes étiquettes. Le résultat est un score qui est censé être consommé par les règles de signal à l'étape suivante. Les paramètres d'agrégation sont spécifiés dans la section score_aggregation . Les buy_labels et sell_labels spécifient les scores de prédiction d'entrée traités par la procédure d'agrégation. window est le nombre d'étapes précédentes utilisées pour l'agrégation continue et combine est une façon dont deux types de scores (achat et étiquettes) sont combinés en un seul score de sortie.
Le score généré par la procédure d'agrégation est un nombre et le but des règles de signal est de prendre les décisions de trading : acheter, vendre ou ne rien faire. Les paramètres des règles de signal sont décrits dans le trade_model .
Ce script simule les transactions en utilisant de nombreux paramètres de signal d'achat-vente, puis choisit les paramètres de signal les plus performants :
python -m scripts.train_signals -c config.jsonCe script démarre un service qui exécute périodiquement une seule et même tâche : charger les dernières données, générer des fonctionnalités, faire des prédictions, générer des signaux, notifier les abonnés :
python -m service.server -c config.jsonIl y a deux problèmes :
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.jsonLes paramètres de configuration sont spécifiés dans deux fichiers :
service.App.py dans le champ config de la classe App-c config.jsom pour les services et les scripts. Les valeurs de ce fichier de configuration écraseront celles du App.config lorsque ce fichier sera chargé dans un script ou un service Voici quelques champs les plus importants (dans App.py et config.json ) :
data_folder - emplacement des fichiers de données nécessaires uniquement pour les scripts batch hors lignesymbol c'est une paire de trading comme BTCUSDTlabels Liste des noms de colonnes qui sont traités comme des étiquettes. Si vous définissez un nouveau label utilisé pour l'entraînement puis pour la prédiction alors vous devez préciser son nom icialgorithms Liste des noms d'algorithmes utilisés pour la formationtrain_features Liste de tous les noms de colonnes utilisés comme fonctionnalités d'entrée pour l'entraînement et la prédiction.buy_labels et sell_labels Listes de colonnes prédites utilisées pour les signauxtrade_model Paramètres du signaleur (principalement quelques seuils)trader est une section pour les paramètres du trader. Actuellement, pas testé de manière approfondie.collector Cette section de paramètres est destinée aux services de collecte de données. Il existe deux types de services de collecte de données : synchrone avec des requêtes régulières auprès du fournisseur de données et un service de streaming asynchrone qui s'abonne au fournisseur de données et reçoit des notifications dès que de nouvelles données sont disponibles. Ils fonctionnent mais n’ont pas été minutieusement testés et intégrés au service principal. Le principal modèle d'utilisation actuel repose sur des mises à jour manuelles de données par lots, la génération de fonctionnalités et la formation de modèles. L'une des raisons d'avoir ces services de collecte de données est 1) d'avoir des mises à jour plus rapides 2) d'avoir des données non disponibles dans l'API normale comme le carnet de commandes (il existe certaines fonctionnalités qui utilisent ces données mais elles ne sont pas intégrées dans le flux de travail principal).Consultez les exemples de fichiers de configuration et les commentaires dans App.config pour plus de détails.
Chaque minute, le signaleur effectue les étapes suivantes pour prédire si le prix est susceptible d'augmenter ou de diminuer :
Remarques :
Démarrage du service : python3 -m service.server -c config.json
Le trader fonctionne mais n'est pas complètement débogué, en particulier, n'a pas été testé pour sa stabilité et sa fiabilité. Il doit donc être considéré comme un prototype doté de fonctionnalités de base. Il est actuellement intégré au Signaler mais, dans une meilleure conception, il devrait s'agir d'un service distinct.
Backtesting
Intégrations externes


