make a video pytorch
0.4.0
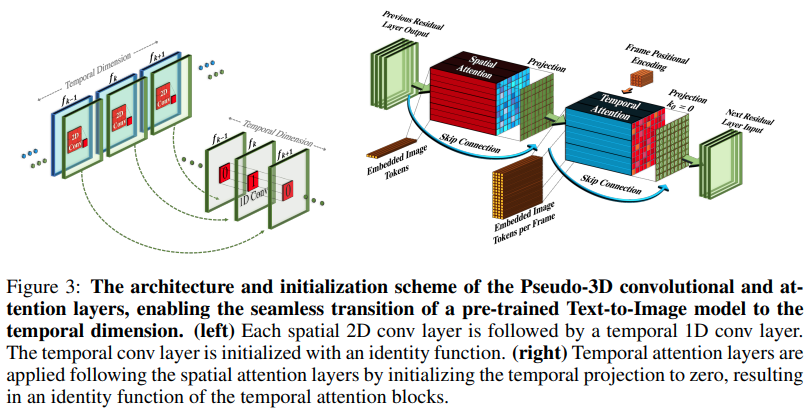
Implémentation de Make-A-Video, nouveau générateur de texte en vidéo SOTA de Meta AI, dans Pytorch. Ils combinent des convolutions pseudo-3D (convolutions axiales) et une attention temporelle et montrent une bien meilleure fusion temporelle.
Les circonvolutions pseudo-3D ne sont pas un concept nouveau. Il a déjà été exploré dans d'autres contextes, par exemple pour la prédiction de contact entre protéines en tant que «réseaux résiduels hybrides dimensionnels».
L'essentiel de l'article se résume à prendre un modèle texte-image SOTA (ici, ils utilisent DALL-E2, mais les mêmes points d'apprentissage s'appliqueraient facilement à Imagen), à apporter quelques modifications mineures pour attirer l'attention au fil du temps et d'autres manières. pour économiser sur le coût de calcul, effectuez correctement l'interpolation des images, obtenez un excellent modèle vidéo.
Explication de la pause-café IA
Stability.ai pour son généreux parrainage visant à mener des recherches de pointe sur l'intelligence artificielle
Jonathan Ho pour avoir révolutionné l'intelligence artificielle générative grâce à son article fondateur
Alex pour einops, une abstraction tout simplement géniale. Il n'y a pas d'autre mot pour ça.
$ pip install make-a-video-pytorchPasser des fonctionnalités vidéo
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)En passant des images (si l'on devait d'abord effectuer un pré-entraînement sur les images), la convolution temporelle et l'attention seront automatiquement ignorées. En d’autres termes, vous pouvez l’utiliser directement dans votre 2D Unet, puis le transférer sur une 3D Unet une fois cette phase de la formation terminée. Les modules temporels sont initialisés pour afficher l'identité comme l'avait fait l'article.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)Vous pouvez également contrôler les deux modules de sorte que lorsqu'ils sont alimentés en fonctionnalités tridimensionnelles, ils ne s'entraînent que spatialement.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) SpaceTimeUnet complet qui est indépendant des images ou de la formation vidéo, et où même si la vidéo est transmise, le temps peut être ignoré
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )prêter attention aux meilleures intégrations positionnelles que la recherche a à offrir
attire l'attention
ajouter une attention flash
assurez-vous que dalle2-pytorch peut accepter SpaceTimeUnet pour la formation
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

