rtdl num embeddings
v0.0.11
Important
Découvrez le nouveau modèle DL tabulaire : TabM
arXiv ? Paquet PythonAutres projets DL tabulaires
Il s'agit de l'implémentation officielle de l'article « Sur les intégrations de fonctionnalités numériques dans l'apprentissage profond tabulaire ».
En une phrase : transformer les caractéristiques continues scalaires d'origine en vecteurs avant de les mélanger dans le squelette principal (par exemple dans MLP, Transformer, etc.) améliore les performances en aval des réseaux de neurones tabulaires.
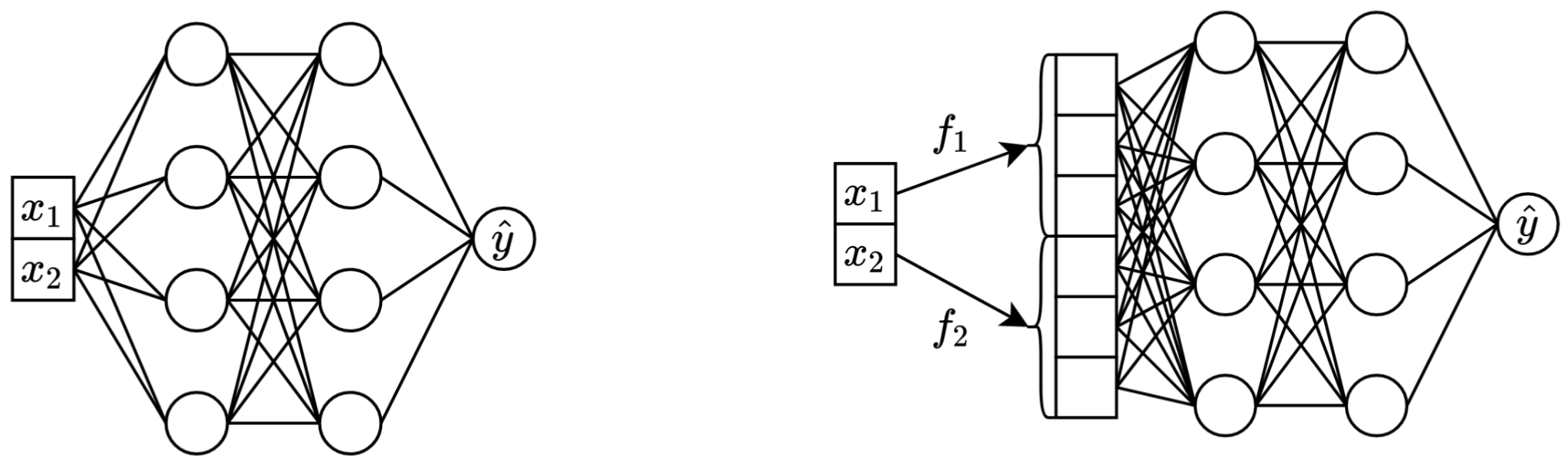
À gauche : Vanilla MLP prenant deux fonctionnalités continues en entrée.
À droite : le même MLP, mais maintenant avec des intégrations pour des fonctionnalités continues.
Plus en détail :
À proprement parler, il n’y a pas d’explication unique. De toute évidence, les intégrations aident à relever divers défis associés aux fonctionnalités continues et à améliorer les propriétés d'optimisation globales des modèles.
En particulier, les entités continues irrégulièrement distribuées (et leurs distributions conjointes irrégulières avec des étiquettes) sont une chose habituelle dans les données tabulaires du monde réel, et elles posent un défi d'optimisation fondamental majeur pour les modèles DL tabulaires traditionnels. Une excellente référence pour comprendre ce défi (et un excellent exemple de résolution de ces défis en transformant l'espace d'entrée) est l'article « Les fonctionnalités de Fourier permettent aux réseaux d'apprendre les fonctions à haute fréquence dans les domaines de faible dimension ».
Cependant, il n’est pas clair si les distributions irrégulières sont la seule raison pour laquelle les intégrations sont utiles.
Le package Python dans le répertoire package/ est la manière recommandée pour utiliser le document dans la pratique et pour les travaux futurs.
Le reste du document :
Le répertoire exp/ contient de nombreux résultats et hyperparamètres (ajustés) pour divers modèles et ensembles de données utilisés dans l'article.
Par exemple, explorons les métriques du modèle MLP. Commençons par charger les rapports (les fichiers report.json ) :
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])Maintenant, pour chaque ensemble de données, calculons la moyenne du score du test sur toutes les graines aléatoires :
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Le résultat correspond exactement au tableau 3 de l'article :
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
L'approche ci-dessus peut également être utilisée pour explorer les hyperparamètres afin d'avoir une intuition sur les valeurs d'hyperparamètres typiques pour différents algorithmes. Par exemple, voici comment calculer le taux d'apprentissage médian ajusté pour le modèle MLP :
Note
Pour certains algorithmes (par exemple MLP, MLP-LR, MLP-PLR), des projets plus récents offrent davantage de résultats pouvant être explorés de manière similaire. Par exemple, consultez cet article sur TabR.
Avertissement
Utilisez cette approche avec prudence. Lors de l'étude des valeurs d'hyperparamètres :
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358Important
Cette section est longue. Utilisez la fonctionnalité « Aperçu » sur GitHub dans votre éditeur de texte pour avoir un aperçu de cette section.
Préliminaires:
/usr/local/cuda-11.1/bin est toujours dans votre variable d'environnement PATH export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsLICENCE : en téléchargeant notre ensemble de données, vous acceptez les licences de tous ses composants. Nous n'imposons aucune nouvelle restriction en plus de ces licences. Vous pouvez trouver la liste des sources dans le journal.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarLe code ci-dessous reproduit les résultats pour MLP sur l'ensemble de données California Housing. Le pipeline pour les autres algorithmes et ensembles de données est absolument le même.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
La section « Métriques » montre comment résumer les résultats obtenus.
Le code est organisé comme suit :
bintrain4.py pour les réseaux de neurones (il implémente toutes les intégrations et backbones du papier)xgboost_.py pour XGBoostcatboost_.py pour CatBoosttune.py pour le réglageevaluate.py pour l'évaluationensemble.py pour l'assemblagedatasets.py a été utilisé pour créer les divisions de l'ensemble de donnéessynthetic.py pour générer les ensembles de données synthétiques compatibles GBDTtrain1_synthetic.py pour les expériences avec des données synthétiqueslib contient des outils courants utilisés par les programmes dans binexp contient les configurations et les résultats des expériences (métriques, configurations optimisées, etc.). Les noms des dossiers imbriqués suivent les noms du papier (exemple : exp/mlp-plr correspond au modèle MLP-PLR du papier).package contient le package Python pour cet articleCUDA_VISIBLE_DEVICES lors de l'exécution de scriptslib.dump_config et lib.load_config au lieu des bibliothèques TOML nuesLe modèle courant pour exécuter des scripts est le suivant :
python bin/my_script.py a/b/c.toml où a/b/c.toml est le fichier de configuration d'entrée (config). La sortie sera située à a/b/c . La structure de configuration suit généralement la classe Config de bin/my_script.py .
Il existe également des scripts qui prennent des arguments de ligne de commande au lieu de configurations (par exemple bin/{evaluate.py,ensemble.py} ).
Vous en avez tous besoin pour reproduire les résultats, mais vous n'avez besoin que train4.py pour les travaux futurs, car :
bin/train1.py implémente un surensemble de fonctionnalités de bin/train0.pybin/train3.py implémente un surensemble de fonctionnalités de bin/train1.pybin/train4.py implémente un surensemble de fonctionnalités de bin/train3.py Pour voir lequel des quatre scripts a été utilisé pour exécuter une expérience donnée, vérifiez le champ « programme » de la configuration de réglage correspondante. Par exemple, voici la configuration de réglage pour MLP sur l'ensemble de données California Housing : exp/mlp/california/0_tuning.toml . La configuration indique que bin/train0.py a été utilisé. Cela signifie que les configurations dans exp/mlp/california/0_evaluation sont spécifiquement compatibles avec bin/train0.py . Pour vérifier cela, vous pouvez copier l'un d'entre eux dans un emplacement distinct et le transmettre à bin/train0.py :
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


