gigagan pytorch
0.2.20

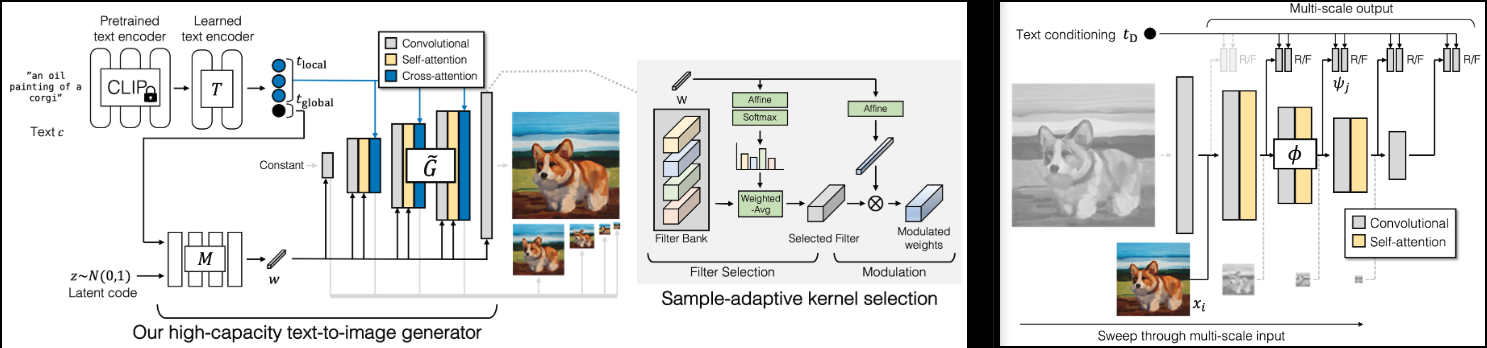
Implémentation de GigaGAN (page projet), nouveau SOTA GAN sorti d'Adobe.
J'ajouterai également quelques résultats du gan léger, pour une convergence plus rapide (excitation de couche sautée) et une meilleure stabilité (perte auxiliaire de reconstruction dans le discriminateur)
Il contiendra également le code des suréchantillonneurs 1k - 4k, que je trouve être le point culminant de cet article.
Veuillez nous rejoindre si vous souhaitez aider à la réplication avec la communauté LAION
StabilitéIA et ? Huggingface pour mon généreux parrainage, ainsi que mes autres sponsors, pour m'avoir offert l'indépendance nécessaire à l'intelligence artificielle open source.
? Huggingface pour leur bibliothèque d'accélération
Tous les responsables d'OpenClip, pour leurs modèles texte-image d'apprentissage contrastif open source SOTA
Xavier pour la révision très utile du code et pour les discussions sur la façon dont l'invariance d'échelle dans le discriminateur devrait être construite !
@CerebralSeed pour pull demandant le code d'échantillonnage initial pour le générateur et le suréchantillonneur !
Keerth pour la révision du code et soulignant quelques divergences avec le document !
$ pip install gigagan-pytorchGAN inconditionnel simple, pour commencer
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Pour un suréchantillonneur Unet inconditionnel
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - GénérateurMSG - Générateur multi-échellesD - DiscriminateurMSD - Discriminateur multi-échellesGP – Pénalité de dégradéSSL - Reconstruction auxiliaire dans le discriminateur (à partir du GAN léger)VD - Discriminateur assisté par visionVG - Générateur assisté par visionCL - Perte de contrainte du générateurMAL – Perte de conscience correspondante Une exécution saine aurait G , MSG , D , MSD avec des valeurs oscillant entre 0 et 10 et restant généralement assez constantes. Si, à tout moment après 1 000 étapes d'entraînement, ces valeurs persistent à trois chiffres, cela signifie que quelque chose ne va pas. Il est normal que les valeurs du générateur et du discriminateur deviennent occasionnellement négatives, mais elles devraient revenir dans la plage supérieure.
GP et SSL devraient être poussés vers 0 . GP peut occasionnellement augmenter ; J'aime l'imaginer alors que les réseaux subissent une révélation
La classe GigaGAN est désormais équipée de ? Accélérateur. Vous pouvez facilement effectuer une formation multi-GPU en deux étapes à l'aide de leur CLI accelerate
Dans le répertoire racine du projet, où se trouve le script de formation, exécutez
$ accelerate configPuis, dans le même répertoire
$ accelerate launch train . py assurez-vous qu'il peut être formé sans condition
lisez les documents pertinents et éliminez les 3 pertes auxiliaires
suréchantillonneur unet
obtenez une révision du code pour les entrées et sorties multi-échelles, car le document était un peu vague
ajouter une architecture de réseau de suréchantillonnage
faire un travail inconditionnel à la fois pour le générateur de base et le suréchantillonneur
faire fonctionner la formation conditionnée par le texte pour la base et le suréchantillonneur
rendre la reconnaissance plus efficace grâce à des patchs d'échantillonnage aléatoires
assurez-vous que le générateur et le discriminateur peuvent également accepter les encodages de texte CLIP pré-codés
faire une revue des pertes auxiliaires
ajouter quelques augmentations différenciables, technique éprouvée de l'ancien temps du GAN
déplacer toutes les projections de modulation dans la classe adaptative conv2d
ajouter une accélération
le clip doit être facultatif pour tous les modules et géré par GigaGAN , avec texte -> intégration de texte traitée une fois
ajouter la possibilité de sélectionner un sous-ensemble aléatoire dans une dimension multi-échelle, pour plus d'efficacité
port sur CLI depuis léger | stylegan2-pytorch
connecter l'ensemble de données laion pour le texte-image
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

