404 Introuvable Base de connaissances
Dernière mise à jour : 2020/06/28
Nouvellement ajouté la semaine dernière :
- [Emballage et publication du projet Python](# outils)
Table des matières:
- bases de l'informatique
- Bases de la théorie informatique
- réseau informatique
- système opérateur
- Structures de données et algorithmes
- base de données
- Bases de la cryptographie
- Bases de la technologie informatique
- langue
- cadre
- outil
- technologie
- recherche sous-jacente
- Sécurité
- technologie de sécurité
- failles
- Sécurité Internet
- Tests d'intrusion
- Vérification des codes
- Sécurité des données
- Sécurité du cloud
- outils de sécurité
- recherche sur la sécurité
- Détection APT
- Échantillons malveillants
- Équipe rouge
- WAF
- Détection d'URL malveillantes
- Lutte contre le trafic des machines
- Détection d'anomalies
- Chiffres et sécurité
- IA et sécurité
- Construction de sécurité d'entreprise
- Développement sécurisé
- Tests de sécurité
- produits de sécurité
- Fonctionnement sûr
- Gestion de la sécurité
- Pensez en toute sécurité
- architecture de sécurité
- Affrontement rouge et bleu
- Sécurité intranet
- Sécurité des données
- Nouvelle technologie et nouvelle sécurité
- Aperçu
- natif du cloud
- informatique de confiance
- DevSecOps
- développement sécuritaire
- développement personnel
- Développement de l'industrie
- données
- Système de données
- Analyse des données et opérations
- Analyse des données de sécurité
- algorithme
- IA
- Système d'algorithme
- connaissances de base
- apprentissage automatique
- apprentissage profond
- apprentissage par renforcement
- Domaines d'application
- Développement de l'industrie
- Qualité complète
- Profession
- planification de carrière
- pensée
- communiquer
- gérer
- pense
- Choses à noter
- appendice
- Personnel technique national exceptionnel
- Excellents sites technologiques étrangers
- abandonné
bases de l'informatique
Bases de la théorie informatique
système opérateur
- [L'examen informatique d'entrée aux études supérieures 408 est le plus complet de tout le réseau !!!!!] Système d'exploitation informatique Kingly
- Interruptions et exceptions
- Comment comprendre de manière simple la pagination et la segmentation de la gestion de la mémoire dans le système d'exploitation ?
Granularité, unités logiques d'information et unités physiques d'information, longueurs indéterminées et déterministes, adresses bidimensionnelles et adresses unidimensionnelles, informations complètes et allocation discrète de mémoire. - Résumé de l'état du noyau et de l'état utilisateur du système d'exploitation
- Compilation de questions d'entretien courantes - système d'exploitation (un must pour tout développeur)
réseau informatique
- Compilation de questions d'entretien courantes - réseau informatique (un must pour tout développeur)
La différence entre TCP et UDP, la poignée de main à trois voies TCP et la vague à quatre voies, le processus après que le navigateur entre dans l'URL, le type de demande du protocole HTTP, la différence entre GET et POST, le protocole de résolution d'adresse ARP - Un processus complet de requête de page de processus de demande de navigateur (navigateur, HTTP) comprend une série de processus tels que la prise de contact à trois voies TCP, tels que la résolution de nom de domaine, le lancement de la prise de contact à trois voies TCP, le lancement de la requête HTTP, la réponse du serveur à la requête HTTP. , et le navigateur obtient le code HTML et le navigateur analyse le code HTML et demande les ressources dans le code HTML. Le navigateur affiche la page et la présente à l'utilisateur.
- Que signifie exactement la fiabilité de TCP ? - Réponse de CYS - Zhihu
La fiabilité de TCP fait référence à la fourniture de services de transmission de données fiables au niveau de la couche de transport basés sur la couche IP peu fiable. Cela signifie principalement que les données ne seront pas endommagées ou perdues et que toutes les données seront transmises dans l'ordre dans lequel elles ont été envoyées. Les mécanismes suivants sont utilisés pour obtenir une transmission fiable de TCP : somme de contrôle (pour vérifier si les données sont endommagées), minuterie (retransmission en cas de perte du paquet), numéro de séquence (utilisé pour détecter les paquets perdus et les paquets redondants), confirmation (récepteur informant l'expéditeur qu'un paquet a été reçu correctement et le prochain paquet attendu), un accusé de réception négatif (le récepteur informe l'expéditeur d'un paquet qui n'a pas été reçu correctement), des fenêtres et un pipeline (utilisés pour augmenter le débit du canal).
Structures de données et algorithmes
- Algorithme 3 : le tri rapide le plus couramment utilisé
trier et trier rapidement. L'idée du tri rapide est de creuser des trous et de remplir des nombres + diviser pour régner. - Une question d'entretien avec Tencent : ma tasse est tellement géniale (je l'ai appris)
Méthode de résolution de problèmes 1 : méthode de bissection ; méthode de résolution de problèmes 2 : méthode d'intervalle de recherche segmentée ; méthode de résolution de problèmes 3 : méthode basée sur des équations mathématiques ; méthode de résolution de problèmes 4 : méthode de programmation dynamique (appris), décrite par la formule : W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n est un numéro de tasse, k est le nombre d'étages) - Comment rédiger efficacement des questions algorithmiques
Les questions sur LeetCode sont grossièrement divisées en trois types : examiner les structures de données : telles que les listes chaînées, les piles, les files d'attente, les tables de hachage, les graphiques, les essais, les arbres binaires, etc. ; examiner les algorithmes de base : tels que la profondeur d'abord, la largeur d'abord, les binaires. recherche, récursivité, etc. ; Examiner les idées algorithmiques de base : récursivité, diviser pour mieux régner, recherche en arrière, programmation gourmande et dynamique. - Une brève discussion sur ce qu'est l'algorithme diviser pour régner (appris)
Problème de permutation complète, problème de tri par fusion, problème de tri rapide et problème de la Tour de Hanoï sous l'idée de diviser pour mieux régner. - 2018.08 Dans l'entretien d'embauche, le kième plus grand nombre dans le tableau désordonné, la médiane dans le tableau désordonné : pointeur de tri rapide, O(N).
- [Explication vidéo] Problème LeetCode n°1 : La somme de deux nombres
- Stratégies pour récupérer les enveloppes rouges lors des réunions annuelles
Bases de la cryptographie
- Explication détaillée des avantages et des inconvénients du cryptage symétrique et du cryptage asymétrique. Le cryptage symétrique est également appelé cryptage à clé unique. Les algorithmes incluent : AES, RC4, 3DES. Il est rapide et peut être utilisé lorsqu'une grande quantité de données doit être cryptée. Le montant du calcul est faible et l'efficacité est élevée. Si la clé secrète d'une partie est révélée, l'ensemble du cryptage sera dangereux. Cryptage asymétrique, les algorithmes incluent RSA, DSA/DSS, lent et hautement sécurisé. Les algorithmes de hachage incluent MD5, SHA1 et SHA256. Trois types d'algorithmes constituent la base de la communication HTTPS .
base de données
- Entretien Tencent : Quelles sont les raisons pour lesquelles une instruction SQL s'exécute lentement ?
Apprentissage supplémentaire : moteur de base de données (InnoDB prend en charge le traitement des transactions et les clés étrangères, mais est plus lent, ISAM et MyISAM utilisent peu d'espace et de mémoire et insèrent les données rapidement), encodage de base de données ( character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system ), base de données index (index de clé primaire, index clusterisé et index non clusterisé) et autres points de connaissances de base.
Les raisons pour lesquelles une instruction SQL est exécutée lentement sont divisées en deux catégories : 1) Normales dans la plupart des cas, parfois très lentes : (1) La base de données actualise les pages sales, telles que redo Lorsque le journal est plein, il doit être synchronisé sur le disque ; (2) Des verrous sont rencontrés lors de l'exécution, tels que des verrous de table et des verrous de ligne ; 2) Il est toujours lent : (1) L'index n'est pas utilisé : par exemple ; , le champ n'a pas d'index en raison de l'index ne peut pas être utilisé en raison de calculs et d'opérations de fonction ; (2) Le mauvais index est sélectionné dans la base de données. Comparez le nombre de lignes analysées de l'index cluster à l'index de clé primaire et. la recherche directe de table complète. Il est possible que le problème d'échantillonnage soit mal évalué et qu'une analyse de table complète soit effectuée. - C'est probablement la solution d'optimisation SQL la plus complète
Bases de la technologie informatique
langue
- Une analyse approfondie des décorateurs Python dans un article de 10 000 mots
- Itérateurs et générateurs Python3
Python : Les itérateurs ont deux méthodes de base : iter() et next(). Les objets itérables tels que les chaînes, les tuples et les listes peuvent être utilisés pour créer des itérateurs (en effet, ces classes implémentent la fonction __iter__() en interne. Après avoir appelé iter(). , cela devient un list_iterator un objet, vous constaterez que la méthode __next__() a été ajoutée. Tous les objets qui implémentent __iter__ et __next__ sont des itérateurs). obtenir les bons éléments lors de la prochaine itération. __iter__ renvoie l'itérateur lui-même __next__ renvoie la valeur suivante dans le conteneur. Générateur : une fonction qui utilise le rendement est appelée un générateur. Lorsqu'une fonction génératrice est appelée, un objet itérateur est renvoyé. Le générateur peut être considéré comme un itérateur. - itérateur, générateur, décorateur de technologie python black
- Que savez-vous des fonctionnalités avancées de Python ? Comparons
Python : fonction anonyme lambda, la fonction consiste à effectuer une expression ou une opération simple sans définir complètement la fonction ; La fonction Map est une fonction Python intégrée qui peut appliquer des fonctions aux éléments de diverses structures de données. Fonction intégrée de filtre similaire à ; Fonction Map, mais renvoie uniquement les éléments pour lesquels la fonction appliquée renvoie True ; le module Itertools est une collection d'outils de traitement des itérateurs, qui sont un type de données qui peut être utilisé dans les instructions de boucle ; la fonction Generator est une fonction de type itérateur ; . - Pourquoi utiliser le langage Go ? Quels sont les avantages du langage Go ?
Go : Les avantages du go et les utilisations du go. Les principaux avantages de go incluent : un langage statique, une concurrence multiple, une multiplateforme, une compilation directe en code machine, une bibliothèque standard riche, etc. Les principales utilisations de Go incluent la programmation serveur, la programmation réseau, les systèmes distribués, les bases de données en mémoire et les plates-formes cloud. - Série de pratiques Gin - Introduction à Golang et installation de l'environnement
Go : installation de l'environnement Go, la signification de chaque dossier après l'installation de l'environnement ; l'espace de travail de Go, la signification de chaque dossier dans l'espace de travail. - ruby-on-rails - Quelle est la différence entre Ruby et JRuby
Ruby : Ruby est un langage de programmation. L'interpréteur Ruby auquel nous faisons généralement référence fait référence à CRuby. CRuby s'exécute dans l'environnement d'interprétation du langage C local. JRuby est un interpréteur Ruby implémenté en Java pur.
cadre
- Gin - Introduction et utilisation du framework Web Golang hautes performances
Gin : est un framework d'application web écrit en Go. - Quelle est la différence entre Spring Boot et Spring MVC ?
Spring -> Spring MVC -> Spring Boot.
outil
- Comparaison entre étincelle et tempête
Outils technologiques Big Data - type de calcul : Comparez les aspects du modèle de calcul en temps réel, de la latence du calcul en temps réel, du débit, du mécanisme de transaction, de la robustesse/tolérance aux pannes, de l'ajustement dynamique du parallélisme, etc. Le streaming Spark est un modèle quasi-temps réel. Il collecte des données sur une période donnée et les traite comme un RDD. Le délai de calcul en temps réel est de deuxième niveau et a un débit élevé. Il prend en charge les mécanismes de transaction mais n'est pas suffisamment complet. .Il a une robustesse moyenne et ne prend pas en charge la dynamique.Ajustez le degré de parallélisme ; Storm est un modèle purement en temps réel. Il reçoit et traite une donnée. Le délai de calcul en temps réel est de l'ordre de la milliseconde. il prend en charge un mécanisme de transaction complet, est très robuste et prend en charge l'ajustement dynamique du degré de parallélisme. Scénarios d'application : Storm peut être utilisé dans des scénarios où le temps réel pur ne peut pas tolérer des retards supérieurs à 1 seconde ; pour les fonctions informatiques en temps réel qui nécessitent des mécanismes de transaction et des mécanismes de fiabilité fiables, c'est-à-dire que le traitement des données est totalement précis, Storm peut également être pris en compte ; Si vous devez également ajuster dynamiquement le parallélisme des programmes informatiques en temps réel pendant les périodes de pointe et de faible pointe pour maximiser l'utilisation des ressources, vous pouvez également envisager une tempête si le projet est purement informatique en temps réel, ce n'est pas nécessaire ; pour exécuter des requêtes interactives SQL au milieu, etc. Pour d'autres opérations, utiliser storm est un meilleur choix. D'un autre côté, si vous n'avez pas besoin de mécanismes de transaction fiables en temps réel ou d'un ajustement dynamique du parallélisme, vous pouvez envisager le streaming spark. Le plus grand avantage du streaming spark est qu'il fait partie de la pile technologique écologique spark. perspective macro du projet, si non seulement le temps réel est requis, l'informatique nécessite également un traitement par lots hors ligne et une requête interactive, et dans le calcul en temps réel, cela impliquera également un traitement par lots à haute latence, une requête interactive et d'autres fonctions. utilisez Spark Core pour développer un traitement par lots hors ligne et Spark SQL pour développer une requête interactive. Le streaming développe l'informatique en temps réel, s'intègre de manière transparente et offre une grande évolutivité au système. Cette fonctionnalité améliore considérablement les avantages de Spark Streaming. Les deux frameworks conviennent à différents scénarios de segmentation. - Tutoriel de démarrage de Ziyu Big Data Spark (version Python) (plus important)
- Quelles sont les différences et les connexions entre les systèmes de collecte de grumes Flume et Kafka ? Quand sont-ils utilisés respectivement et quand peuvent-ils être combinés ?
Outils technologiques Big data - type middleware : Kafka peut être compris comme un middleware, ou un système de cache, ou une base de données, sa fonction principale est de maintenir la stabilité. Flume peut être compris comme une collecte active de données de journalisation. Par rapport à Kafka, il est difficile de promouvoir l'interface de modification d'application en ligne pour écrire des données dans Kafka. - Quels sont les avantages et les inconvénients entre Logstash et Flume, et à quels scénarios conviennent-ils ?
Outils technologiques Big Data - Type d'agent : selon les besoins, logstash et flume existent en tant qu'agents. Logstash a plus de plug-ins et de meilleurs produits de support tels que elasticsearch, mais le langage de développement de logstash est Ruby et l'environnement d'exploitation est. JRuby. De plus, les données transmises peuvent être perdues ; il existe un mécanisme à l'intérieur de Flume pour garantir qu'une certaine quantité de données est transmise sans perte. Le langage de développement de Flume est Java, ce qui est facile pour le développement secondaire. que le JVM prend beaucoup de mémoire. - Liste des touches de raccourci Mac
MAC : touches de raccourci de base : captures d'écran, dans les applications, traitement de texte, dans le finder, dans les navigateurs ; touches de raccourci pour le démarrage et l'arrêt du MAC. - Feuilles de commandes Git couramment utilisées
Git : Entrepôt distant-"Entrepôt local->Zone de transit-"Espace de travail, git add., git commit -m message, git push. - git-lfs
Git-lfs : outil d'extension de téléchargement de fichiers volumineux git. - paquet pcap d'analyse statistique tshark
- [Emballage et publication du projet Python](# outils)
Mémo : 1. setup.py : long_description et long_description_content_type (notez les problèmes de rendu des formats md et rst). 2. manifest.in contre gitignore. 3. readme.rst contre readme.md. 4. .pypirc contre gitconfig. 5. téléchargement python setup.py bdist_wheel.
technologie
- Décodage et XSS ( il y a une
\u72 dans le texte original "après le codage de l'entité HTML" devrait être -
Séquence de décodage de la technologie du navigateur : le décodage du navigateur implique principalement deux parties : le moteur de rendu et l'analyseur js. Ordre de décodage : le décodage est effectué dans n'importe quel environnement. L'ordre de décodage est le suivant : le codage correspondant à l'environnement le plus externe est décodé en premier. Par exemple : en <a href=javascript:alert(1)>click</a> alert(1) se trouve dans l'environnement html->url->js. 1. Click utilise le codage Unicode e, qui ne peut pas être décodé dans les environnements HTML ou URL. Il ne peut être décodé qu'en caractère e dans l'environnement js, donc aucune fenêtre contextuelle ne s'affichera.
2. Click utilise le codage d'URL Avant d'exécuter js, l'url décode %65, donc lorsque le moteur js démarre, vous voyez l'alerte complète (1)
3. Cliquez sur le décodage de l'entité HTML est exécuté en premier
4. Cliquez sur Dans le processus de décodage d'URL, JavaScript ne sera pas considéré comme un pseudo-protocole et des erreurs se produiront.
5. Cliquez sur htmlparser qui sera exécuté avant l'analyseur JavaScript. Le processus d'analyse consiste donc à décoder d'abord les caractères de htmlencode, puis à exécuter l'événement JavaScript.
L'ordre de décodage du navigateur constitue la base du contournement dans XSS . - La relation entre dockerfile et docker-compose
technologie docker : la relation entre les fichiers et les dossiers. - Quelle est la différence entre dockerfile et docker-compose ?
technologie docker : docker-compose sert à orchestrer les conteneurs. - Qu'est-ce qu'une machine à bastions ?
Technologie hôte Bastion : définit une entrée pour l'accès au cluster ; facilite le contrôle et la surveillance des autorisations. - Sous quels aspects faut-il analyser la faisabilité d’un produit ?
Analyse de faisabilité : La faisabilité du produit est divisée en : faisabilité technique, faisabilité économique et faisabilité sociale. Parmi eux, je me concentre sur la faisabilité technique. La faisabilité technique est principalement mesurée à partir de la comparaison des fonctions des concurrents, des risques techniques et des méthodes d'évitement, de la facilité d'utilisation et du seuil d'utilisation, de la dépendance de l'environnement du produit, etc. - Quels rôles Nginx et Gunicorn jouent-ils sur le serveur ?
Serveur d'applications : scénario de déploiement Nginx : équilibrage de charge (les frameworks tels que tornado ne prennent en charge qu'un seul cœur, le déploiement multi-processus nécessite donc un équilibrage de charge inversé. gunicorn lui-même est multi-processus et n'en a pas besoin), prise en charge des fichiers statiques, pression anti-concurrence , contrôle d'accès supplémentaire. - Wikipédia : Kerberos
Kerberos : Description de base, contenu du protocole et processus spécifique de Kerberos. - La relation entre dockerfile et docker-compose
technologie docker : la relation entre les fichiers et les dossiers. - Quelle est la différence entre dockerfile et docker-compose ?
technologie docker : docker-compose sert à orchestrer les conteneurs. - Qu'est-ce qu'une machine à bastions ?
Technologie hôte Bastion : définit une entrée pour l'accès au cluster ; facilite le contrôle et la surveillance des autorisations. - Sous quels aspects faut-il analyser la faisabilité d’un produit ?
Analyse de faisabilité : La faisabilité du produit est divisée en : faisabilité technique, faisabilité économique et faisabilité sociale. Parmi eux, je me concentre sur la faisabilité technique. La faisabilité technique est principalement mesurée à partir de la comparaison des fonctions des concurrents, des risques techniques et des méthodes d'évitement, de la facilité d'utilisation et du seuil d'utilisation, de la dépendance à l'environnement du produit, etc. - Quels rôles Nginx et Gunicorn jouent-ils sur le serveur ?
Serveur d'applications : scénario de déploiement Nginx : équilibrage de charge (les frameworks tels que tornado ne prennent en charge qu'un seul cœur, le déploiement multi-processus nécessite donc un équilibrage de charge inversé. gunicorn lui-même est multi-processus et n'en a pas besoin), prise en charge des fichiers statiques, pression anti-concurrence , contrôle d'accès supplémentaire. - Wikipédia : Kerberos
Kerberos : Description de base, contenu du protocole et processus spécifique de Kerberos. - Qu’est-ce que l’architecture des microservices** ?
- Qu'est-ce que Service Mesh (Service Mesh)
Architecture des microservices : Pourquoi : Pourquoi utiliser un maillage de services ? Dans l'architecture traditionnelle des applications Web MVC à trois niveaux, la communication entre les services n'est pas compliquée et peut être gérée au sein de l'application. Cependant, dans les sites Web complexes à grande échelle d'aujourd'hui, les applications uniques sont décomposées en de nombreux microservices et la communication entre les services l'est. complexe. Quoi : Le maillage de services est la couche d'infrastructure pour la communication entre les services. Il peut être comparé au TCP/IP entre les applications ou les microservices. Il est responsable des appels réseau, de la limitation du courant, de la coupure des circuits et de la surveillance entre les services. Caractéristiques de Service Mesh : couche intermédiaire pour la communication inter-applications, proxy réseau léger, tentatives/expirations d'application découplées et indépendantes des applications, surveillance, traçage et découverte de services. Les logiciels open source actuellement populaires sont Istio et Linkerd, qui peuvent tous deux être intégrés dans l'environnement Cloud Native Kubernetes. - Le programme de mise à jour échoue s'il n'est pas exécuté en tant qu'administrateur, même sur une installation utilisateur
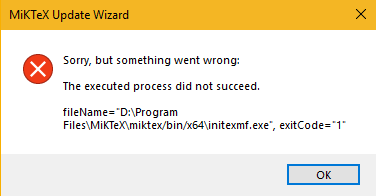
LaTeX : MiKTeX (problème de registre et problème de droits d'administrateur) + TeXnicCenter (impossible de générer un problème de pdf, définissez le chemin d'exécution d'Adobe dans Build sur AcroRd32.exe authentique) + Adobe Acrobat Reader DC, puis utilisez la version crackée d'Adobe Acrobat DC pour convertir vers d'autres formats. - Principe HTTPS et processus d'interaction
HTTPS : HTTPS nécessite une négociation entre le navigateur et le site Web avant de transmettre les données. Au cours du processus de négociation, les informations de mot de passe utilisées par les deux parties pour crypter les données transmises seront confirmées. Obtenir la clé publique -> Le navigateur génère une clé secrète aléatoire (symétrique) -> Utiliser la clé publique pour chiffrer la clé secrète symétrique -> Envoyer la clé secrète symétrique chiffrée -> communication chiffrée par la clé secrète symétrique. L'ensemble du processus de communication HTTPS utilise le cryptage symétrique, le cryptage asymétrique et les algorithmes HASH . - Politique de même origine du navigateur
Technologie du navigateur : La politique de même origine est la fonction de sécurité centrale et la plus élémentaire du navigateur. La politique de même origine est définie comme : protocole/hôte/port. - Neuf principes de mise en œuvre inter-domaines (version complète)
Technologie de navigateur : solutions de requêtes inter-domaines : JSONP (vulnérabilités qui reposent sur des balises de script sans restrictions inter-domaines), CORS (partage de ressources inter-domaines), postMessage, websocket, proxy middleware Node, proxy inverse nginx, windows.name+iframe , emplacement.hash+iframe, document.domain+iframe.
CORS prend en charge tous les types de requêtes HTTP et constitue la solution fondamentale pour les requêtes HTTP inter-domaines. JSONP ne prend en charge que les requêtes GET. L'avantage est qu'il prend en charge les anciens navigateurs et peut demander des données à des sites Web qui ne prennent pas en charge CORS. Qu'il s'agisse du proxy middleware Node ou du proxy inverse nginx , la raison principale est de n'imposer aucune restriction sur le serveur via la politique de même origine. Dans le travail quotidien, les solutions interdomaines les plus couramment utilisées sont CORS et le proxy inverse nginx. - Comment utiliser l'environnement virtuel Python dans Jupyter Notebook ?
Anaconda : Installer les plug-ins, conda install nb_conda - Puisqu’il existe des requêtes HTTP, pourquoi utiliser les appels RPC ? - Réponse de frère Yi
RPC : Restant VS RPC. RPC inclut : proxy inverse, sérialisation et désérialisation, communication (HTTP, TCP, UDP), gestion des exceptions
recherche sous-jacente
Une brève analyse du processus de la bibliothèque de requêtes Python
Implémentation de la bibliothèque de requêtes Python : socket->httplib->urllib->urllib3->requests. Le processus d'appel interne de request.get : request.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib).
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
Analyse des principes XGBoost et de leur mise en œuvre sous-jacente (appris)
XGBoost : Comprendre du point de vue du score de l'arbre (fonction objectif : fonction de perte (expansion du second ordre) + terme régulier), la structure de l'arbre (décision fractionnée (pré-tri)).
Compréhension approfondie de l'algorithme d'optimisation de l'histogramme Lightgbm
Lightgbm : Par rapport au pré-tri, lgb utilise un histogramme pour gérer la division des nœuds et trouver le point de division optimal. Idée d'algorithme : convertissez les valeurs de fonctionnalité en valeurs de bac à l'avance avant l'entraînement, c'est-à-dire créez une fonction par morceaux pour la valeur de chaque fonctionnalité, divisez les valeurs de tous les échantillons sur cette fonctionnalité en un certain segment (bin) , et enfin les valeurs des fonctionnalités sont converties de valeurs continues en valeurs discrètes. Les histogrammes peuvent également être utilisés pour l'accélération différentielle. La complexité du calcul de l'histogramme est basée sur le nombre de compartiments.
Analyse du code source du prétraitement du texte Keras
Keras - prétraitement du texte : 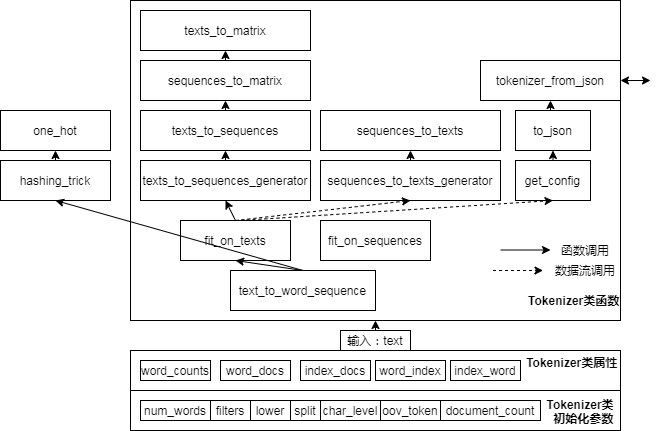
Analyse du code source du prétraitement de la séquence Keras
Mot2Vec
- Comprendre le modèle Skip-Gram de Word2Vec
- Implémentation du modèle Skip-Gram basé sur TensorFlow - Article de Tian Yusu
- Tutoriel Word2Vec - Le modèle Skip-Gram
- Tutoriel Word2Vec, partie 2 - Échantillonnage négatif
- Tutoriel d'intégration de mots Word2Vec en Python et TensorFlow
- analyse du code source tensorlflow word2vec_basic
- Un tutoriel Word2Vec Keras
- keras_word2vec@adventures-in-ml-code
Sécurité
technologie de sécurité
failles
- Compilation de la charge utile de la bibliothèque de vulnérabilités Wuyun et du plug-in auxiliaire Burp
- garçon-hack/wooyun-charge utile
- Le point de vue d’un chercheur sur la recherche sur la vulnérabilité dans les années 2010
Recherche sur les vulnérabilités : État actuel et tendances de la recherche sur les vulnérabilités au cours des 10 dernières années : 1. Dans l'ère post-PC, l'intégrité des flux de contrôle est devenue un nouveau mécanisme de protection de base pour la sécurité du système. 2. Fonctionnalités de sécurité matérielle surprenantes et vulnérabilités de sécurité matérielle. 3. Du vin nouveau dans de vieilles bouteilles, la conception sûre des appareils mobiles permet de dépasser dans les virages. 4. La bataille pour les accès au réseau s'intensifie. Les accès au réseau incluent : les navigateurs, les coprocesseurs WiFi, les bandes de base, le Bluetooth, les routeurs, les appareils de messagerie instantanée, les logiciels sociaux, les clients de messagerie, les PC et serveurs traditionnels. 5. L’exploration et l’exploitation automatisées des vulnérabilités doivent encore être améliorées.
Sécurité Internet
- Un article pour vous donner une compréhension approfondie des vulnérabilités : vulnérabilités XXE
Vulnérabilité XXE : Le principe de XXE : appel d'entités externes, utilisation de XXE : utilisation d'entités générales, d'entités paramètres, d'entités externes, d'entités internes pour lire des fichiers, détection d'hôte et de port intranet, RCE intranet (le support de l'extension attendu est requis sous PHP) ) - Techniques d'injection sans virgule MySQL
Attaques par injection : injection SQL, injection XML (un langage de balisage qui représente structurellement les données via des balises), injection de code (classe eval), injection CRLF (rn). Injection Mysql : utilisez des commentaires pour contourner les espaces, utilisez des parenthèses pour contourner les espaces, utilisez des symboles tels que %20 %0a pour remplacer les espaces ; sous la requête d'union, utilisez la jointure pour contourner le filtrage par virgule, select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); Utilisez select case when(条件) then 代码1 else 代码2 end pour contourner le filtrage par virgule, insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end)); - [CRLF Utilisation de la vulnérabilité d'injection et exemple d'analyse]([https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5% 88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html](https://wooyun.js .org/drops/CRLF Utilisation de la vulnérabilité d'injection et exemple d'analyse.html))
CRLF est l'abréviation de "retour chariot + saut de ligne" (rn). L'en-tête HTTP et le corps HTTP sont séparés par deux CRLF. L’injection CRLF est également appelée HTTP Response Splitting, ou HRS en abrégé. X-XSS-Protection:0 désactive la stratégie de protection du navigateur pour le filtrage XSS réfléchi. - Exploitation des vulnérabilités SSRF et combat getshell (sélectionné)
- Résumé de plusieurs méthodes pour contourner le filtrage (restrictions IP) dans les vulnérabilités SSRF
SSRF : Utiliser le saut 302 (xip.io, adresse courte, service auto-écrit) ; DNS rebinding (contourner les restrictions IP) ; utiliser le problème d'analyse de l'URL : http://[email protected]/ ; via divers protocoles non HTTP - Résumé des méthodes de contournement SSRF
SSRF : Utiliser @ ; utiliser une adresse courte ; utiliser un nom de domaine spécial xip.io ; utiliser la résolution DNS (définir un enregistrement sur le nom de domaine) ; - Analyse de vulnérabilité ThinkPHP 5.0.0 ~ 5.0.23 RCE
- Une brève analyse du codage de caractères et de l'injection SQL dans l'audit en boîte blanche (excellent, appris)
Attaque par injection basée sur l'encodage de caractères : un caractère chinois encodé en gbk occupe 2 octets, et un caractère chinois encodé en utf-8 occupe 3 octets. L'injection d'octets large profite des caractéristiques de mysql Lorsque mysql utilise l'encodage gbk, il pensera que deux caractères sont un seul caractère chinois (sous gbk, le code ascii précédent doit être supérieur à 128 pour atteindre la plage des caractères chinois ; l'encodage). plage de valeurs de gb2312 : bit haut 0xA1-0xF7 , bit bas 0xA1-0xFE et 0x5c , n'est pas dans la plage de bits faibles, donc 0x5c n'est pas l'encodage dans gb2312, il ne sera donc pas étendu à tous les encodages multi-octets, tant que la plage de bits faibles contient l'encodage de 0x5c , une injection d'octets larges peut être effectuée). Premier plan de défense : mysql_set_charset+mysql_real_escape_string , en tenant compte du jeu de caractères actuel de la connexion. Deuxième plan de défense : définissez character_set_client sur binary (binaire), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary . Lorsque notre mysql recevra les données du client, il pensera que son encodage est character_set_client , puis le changera en encodage de character_set_connection , puis entrera la table et le champ spécifiques, puis les convertira en encodage correspondant au champ. Ensuite, lorsque les résultats de la requête sont générés, ils seront convertis du codage de table et de champ en codage character_set_results et renvoyés au client. Par conséquent, si nous définissons character_set_client sur binary , il n'y aura aucun problème d'octets larges ou multi-octets. Toutes les données sont transférées sous forme binaire, ce qui peut effectivement éviter l'injection de caractères larges. Des problèmes peuvent également survenir lors de l'appel de iconv après la défense. Lorsque vous utilisez iconv pour convertir utf-8 en gbk, la méthode d'utilisation est錦' , car son encodage utf-8 est 0xe98ca6 , et son encodage gbk est 0xe55c , qui devient finalement %e5%5c%5c%27 , deux %5c C'est ' sont un nombre impair, ' échappera à la limite. Pourquoi ne pouvons錦' pas utiliser cette méthode ? Selon les règles d'encodage utf-8, (0x0000005c) n'apparaîtra pas dans l'encodage utf-8, donc une erreur sera signalée. - Problèmes de sécurité causés par les sessions client
- Un aperçu de DAST, SAST et IAST dans un article - une brève discussion sur la comparaison des technologies de test de sécurité des applications Web (appris)
- Parlez de SAST/IDAST/IAST
- Introduction aux méthodes de connexion PHP et comment attaquer PHP-FPM
- Une requête GET pour obtenir le drapeau ——Rédaction finale de XCTF 2018 PUBG (WEB 2)
Tests d'intrusion
- Un ensemble de questions pratiques d'entretien d'embauche pour les tests d'intrusion Fonctions d'exécution de code :
eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function ; fonctions d'exécution de commandes : system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open , img tag sauf l'attribut onerror ; D'ailleurs, existe-t-il un autre moyen d'obtenir le chemin d'accès de l'administrateur ? src spécifie un fichier de script distant pour obtenir le référent. - Un ensemble de questions pratiques d'entretien d'embauche pour les tests d'intrusion, le connaissez-vous ?
- Mon expérience d'entretien, tests d'intrusion
Vérification des codes
- Audit de code Java - avancement couche par couche
Sécurité des données
- NO.27 Discutez sur la sécurité des données Technologie et époque du Big Data, les données sont l'actif principal de nombreuses entreprises ; la frontière de sécurité traditionnelle est floue, nous devons supposer que notre frontière a été pénétrée, et en même temps avoir une défense en profondeur capacités à protéger la sécurité des informations. Par conséquent, tout en renforçant les méthodes de sécurité traditionnelles, nous devons concentrer directement la sécurité sur les données elles-mêmes. C’est ce que fait la sécurité des données. Avant de faire cela, il y a une prémisse : nous devons savoir que la sécurité sert toujours l'entreprise (dans la plupart des cas de sécurité d'entreprise, entreprise > sécurité), il faut donc peser la sécurité et la convivialité. Actuellement, les mesures couramment utilisées par les entreprises comprennent principalement : la classification des données, la gestion du cycle de vie des données, la désensibilisation et le cryptage des données, ainsi que la prévention des fuites de données.
- Construction d'un système de sécurité des données d'entreprise Internet
Sécurité du cloud
- La sécurité du cloud, de quoi s'agit-il exactement ?
Il existe trois axes de recherche majeurs en matière de sécurité cloud : la sécurité du cloud computing, la cloudisation de l'infrastructure de sécurité et les services de sécurité cloud. La collaboration sur la sécurité des données est également mentionnée dans les tendances de développement futures de la sécurité du cloud, indiquant que, quel que soit le scénario, les données sont au centre de la sécurité. Les services de sécurité cloud peuvent être considérés comme des chefs cuisinant (PPT de CDXY), du cloud computing (énergie), des algorithmes (outils), des données (matières premières), des ingénieurs (chefs), quel type de riz peut être fabriqué (services de sécurité qui peuvent être fourni) ) - L'avenir de la sécurité du cloud (long article en profondeur)
Idées d'écriture : Tendances du marché de la sécurité du cloud - "Produits de sécurité cloud traditionnels (produits de sécurité de la plate-forme cloud et produits de sécurité cloud tiers CWPP, CSPM, CASB) -" La combinaison de la sécurité du cloud et SD-WAN - "Native Cloud (DevOps, continu Livraison, microservices, conteneurs) Sécurité.
autre
- Informations sur la sécurité: Laborations d'entreprise, communautés de sécurité, équipes de sécurité, outils de sécurité, etc.
outils de sécurité
Scan de vulnérabilité
- Analyse de vulnérabilité à l'aide du mode proxy Xray
recherche sur la sécurité
Détection appropriée
- Détection APT basée sur l'apprentissage automatique
Modèle de détection APT : Cet article propose un modèle de détection APT en détectant plusieurs liens dans le cycle de vie APT, en corrélant les événements d'alarme dans chaque lien et en utilisant l'apprentissage automatique pour former le modèle de détection. Il est légèrement similaire à mon idée. Le but de cela est de décrire complètement l'ensemble des événements de sécurité dans un scénario APT, de réduire le taux de faux positifs, d'améliorer la précision et d'éviter les problèmes des négatifs manqués et des faux positifs causés par la détection traditionnelle de la liaison unique. Cependant, il y a également des problèmes dans cet article, tels que le manque de sources de données APT.
Échantillons malveillants
- Utilisez l'apprentissage automatique pour détecter le trafic externe malveillant HTTP (excellent)
MALICIEUX HTTP Détection du trafic externe : idée générale : 1. Collecte de données , exécuter des échantillons malveillants dans le bac à sable, collecter un trafic malveillant, distinguer manuellement le trafic malveillant du trafic blanc, puis classer le trafic malveillant dans les familles en fonction des renseignements sur les menaces. 2. Analyse des données (ingénierie des fonctionnalités): Pour la similitude du trafic externe malveillant de la même famille, vous pouvez envisager d'utiliser un algorithme de clustering pour regrouper le trafic de la même famille dans une seule catégorie, extraire leurs points communs, former un modèle, puis Utilisez le modèle pour détecter le trafic inconnu. 3. Algorithme: Phase de formation : Extraire HTTP Traffic de connexion externe ---> Extrait des champs d'en-tête de demande ---> Généralisation ---> Calcul de similitude ( pondération spécifique au champ dans l'en-tête de demande puis calcul de la similitude ) ---> hiérarchique Clustering ---> Générer un modèle de trafic externe malveillant (l'union de ce champ dans le cluster est utilisée comme valeur de ce champ dans le modèle). Étape de détection : Trafic externe HTTP inconnu ---> Extrait des champs d'en-tête de demande ---> Généralisation ---> Faire correspondre aux modèles malveillants ---> Déterminez si la similitude dépasse le seuil (détermination du seuil) - Construction de la plate-forme d'analyse automatisée Cuckoo Malware
- Environnement d'analyse des logiciels malveillants du coucou
- Jouer avec CUCUSO
Cuckoo Sandbox: J'ai rencontré de nombreux pièges dans le processus de construction de l'environnement d'analyse de Cuckoo Malecious. PY au dossier de démarrage; faites attention à la relation réseau entre Windows10, Ubuntu16 et Windows7, Nat et le mode hôte uniquement. Sur l'hôte physique, Windows 10 est installé avec VMware, VMware est installé avec Ubuntu16, Ubuntu16 est installé avec VirtualBox et Cuckoo Server, et VirtualBox est installé avec Windows7 comme agent. - Résumé des ressources d'analyse des échantillons malveillants
Lutter contre le trafic machine
- Rapport Bad Bot 2018
Le trafic de la machine de combat : la confrontation de la sécurité a favorisé l'évolution des méthodes d'attaque et est entré dans le stade de la confrontation automatisée. Le trafic machine est généré, tandis que les robots malveillants et d'autres robots malveillants imitent les demandes normales des utilisateurs pour générer un trafic de machine malveillant. sans tête. Le navigateur, les plus avancés peut simuler les mouvements et les clics de la souris. Le trafic machine peut être distingué en fonction de l'environnement réseau (ISP Amazon, centres de données, fournisseurs d'hébergement mondiaux), les outils utilisés (navigateurs du trafic automatique aiment se déguiser en Chrome, Firefox, Internet Explorer, Safari), et s'ils imitent l'homme Interactions, telles que les trajectoires de souris et les clics. Une fois qu'ils ont détecté nos tentatives de les arrêter, le trafic de machine malveillant avancé APB devient persistant et adaptatif, effectuant des transformations multimodales. Défense: Comprenez nos opérations et nos objectifs ennemis. Supprimez les fournisseurs de services d'hébergement bien connus; Échec de la connexion;
Détection d'URL malveillante
- Détecter les URL malveillantes
Après avoir lu les algorithmes de sécurité intérieure et les documents d'analyse des données de sécurité jusqu'à la fin, ils ont commencé à tourner leur attention vers les pays étrangers et à suivre le processus de développement des applications d'apprentissage automatique étrangères dans le domaine de la sécurité du réseau. Prenant l'exemple de la détection d'URL, de nombreux scénarios applicables peuvent être dérivés, notamment la détection de pages Web malveillants, les activités de communication malveillante et les logiciels Web malveillants. - Au-delà des listes noires: apprendre à détecter les sites Web malveillants à partir d'URL suspectes
Utilisez la détection d'URL malveillante comme méthode supplémentaire pour la détection de pages Web malveillante. Données: échantillons d'URL en noir et blanc, pas de fonctionnalités spéciales; Caractéristiques lexicales et fonctionnalités basées sur l'hôte, fonctionnalités moyennes, analyse et comparaison des fonctionnalités de chaque sous-catégorie, fonctionnalités moyennes; Aucune caractéristique, analyse et comparaison de chaque sous-catégorie Ce modèle n'a aucune caractéristique; Après tout, c'était un article écrit il y a dix ans. - Identification des URL suspectes: une application de l'apprentissage en ligne à grande échelle
- Exploiter la covariance des fonctionnalités dans l'apprentissage en ligne de grande dimension
Équipe rouge
- La pratique et la pensée de l'équipe rouge de 0 à 1 (apprise)
Définition de Red Team ---> Le but de l'équipe rouge (apprenez et utilisez des TTP des attaquants réels connus pour attaquer, évaluer l'efficacité des capacités de défense existantes, identifier les faiblesses du système de défense et proposer des contre-mesures spécifiques, utiliser des attaques simulées réelles et efficaces Pour évaluer l'impact potentiel de l'entreprise causé par les problèmes de sécurité) ---> qui a besoin d'équipe rouge ---> Comment fonctionne l'équipe rouge (composition de base: réserve de connaissance simulation; collaboration) ---> rouge La quantification et l'évaluation de l'équipe (couverture des TTP connus, taux de détection / temps de détection / stade de détection, taux de blocage / temps de blocage / stade de blocage) ---> GROPTION ET AMÉLIORATION DE L'ÉQUIPE ROUG et partage) - Résumé de l'organisation ATT & CK APT TTPS
- Résumé de la technologie d'attaque de plate-forme complète d'Att & CK
- Résumé des rapports d'analyse de l'organisation réelle APT
WAF
- Discussion technique | contourner la WAF au niveau du protocole HTTP
- Utilisez un transfert en morceaux pour vaincre tous les WAF
- Contourner les WAF du niveau du protocole HTTP et du niveau de base de données
- Quatre niveaux de recherche d'attaque et de défense WAF: contourner WAF
- Quelques connaissances sur WAF
Détection d'anomalie
- N Méthodes de détection des anomalies (apprises)
L'une des difficultés de la détection des anomalies est le manque de vérité du sol. À partir des séries chronologiques (moyenne mobile, en glissement annuel et par mois, STL + GESD), statistiques (distance Mahalanobis, boxplot), angle de distance (KNN), méthode linéaire (décomposition matricielle et réduction de la dimensionnalité PCA), distribution (L'entropie relative KL détecte les anomalies sous des angles tels que la divergence, le test du chi carré), les arbres, les graphiques, les séquences comportementales et les modèles supervisés (qui peuvent combiner automatiquement plus de fonctionnalités, telles que GBDT). - Algorithme de détection de l'apprentissage automatique (anomalie (1): forêt d'isolement
- Algorithme de détection de l'apprentissage automatique (anomalie (2): facteur local aberrant
- Algorithme de détection d'apprentissage automatique (Analyse des composants principaux: Analyse des composants principaux
- Qu'est-ce qu'une machine de vecteur de support à une classe (une classe SVM)?
- Algorithme de détection d'anomalie
- Extraction d'anomalies, forêt d'isolement
- Première tentative de détection d'anomalies
- Surveillance intelligente des anomalies de données de séries chronologiques alimentées par l'apprentissage automatique
- Exceptions minières dans les journaux de fonctionnement et de maintenance massifs
- Identification du prétraitement des données
- Une étude préliminaire sur l'application de la détection anormale et de l'apprentissage supervisé dans la détection d'anomalies
- Quels sont les algorithmes courants de la «détection d'anomalies» dans l'exploration de données? - Réponse affinée - Zhihu
1. Présenter des algorithmes et des expériences de détection d'anomalies non supervisées courantes; 1.1) Statistiques et modèles de probabilité: Test de distribution et d'hypothèse d'hypothèse, d'indépendance et de corrélation de caractéristiques unidimensionnelles et multidimensionnelles, de distance de caractéristiques, de distance euclidienne et de mahalanobis; Distance euclidienne et distance de Mahalanobis, PCA et PCA douce et SVM à une classe; 1.2) Vérifiez la connexion entre les algorithmes à partir de la limite de décision du graphique de résultat expérimental. 2.1) La comparaison des effets de détection du modèle, la forêt d'isolement et le KNN fonctionnent de manière stable; 3.1) Le volume des données et les dimensions des données ont également un impact sur la surcharge de l'algorithme. L'isolement est plus adapté aux espaces de grande dimension. 4.1) Les résultats expérimentaux apportent des idées pour la sélection du modèle de détection d'anomalies: KNN et MCD pour les ensembles de données de petite et moyenne taille sont relativement stables, et la forêt d'isolement pour les ensembles de données moyens et grands est stable; Comme PCA et MCD; 4.2) Pour un nouveau problème de détection d'anomalies, vous pouvez suivre les étapes suivantes pour analyser: A. Comprendre les données, la distribution des données et la distribution des anomalies, et sélectionner un modèle basé sur des hypothèses; Si c'est le cas, il ne peut pas être gaspillé; L'algorithme de sélection de points; Les caractéristiques des anomalies changent souvent. Les règles manuelles sont toujours très utiles, n'essayez pas de remplacer les règles existantes par des stratégies de données en une seule étape. - Peignant | détection d'anomalie
- Anomalie Detection Isolement Forest & Visualisation
- Détection d'anomalies avec prévision des séries chronologiques
Chiffres et sécurité
- Figure / Louvain / DGA Random Talk Le graphique porte des informations topologiques, et les informations topologiques peuvent être considérées comme une dimension caractéristique. Le point clé de l'algorithme de Louvain est le poids des bords du graphique, qui nécessite une étude spéciale dans des scénarios d'attaque et de défense spécifiques. des IP qui ont visité les noms de domaine A et B en même temps. Master CDXY a implémenté cette logique à l'aide de SQL.
- Algorithme de découverte de la communauté - Une étude préliminaire sur l'algorithme de déroulement rapide (louvian)
- Une analyse DGA DGA Odyssey PDNS
- Graph Computing a appris la mise en œuvre de la sécurité de base: l'implémentation de graphiques dans la détection des intrusions, la réponse d'intrusion, l'intelligence des menaces et l'UEBA. Détection d'intrusion: Direction de développement de la détection des intrusions d'entreprise et l'historique de développement des capacités d'analyse des données. Réponse d'intrusion: problèmes résolus pendant le processus (exhaustivité et richesse des journaux, analyse de corrélation des données massives et des fenêtres de longue date, une construction en temps réel et une requête des graphiques, une interaction et une visualisation). UEBA: Le développement de la confiance du cloud-natif et de la fiducie zéro - "Secure par défaut -" Obtenir des informations d'identification pour les services de confiance ", la chaîne d'approvisionnement" - "Détection d'intrusion fondée sur l'authentification -" Analyse du comportement et profilage. Résumé: Problèmes commerciaux -> Problèmes de données.
IA et sécurité
- Compilation du matériel d'apprentissage pour les scénarios de sécurité, les algorithmes de sécurité basés sur l'IA et l'analyse des données de sécurité
- Vers la confidentialité et la sécurité des systèmes d'apprentissage en profondeur: une enquête
Surface d'attaque de la sécurité de l'IA : En termes de données et de modèles dans la phase de formation et la phase de test, les attaques incluent l'intoxication des données et les échantillons adversaires, l'extraction du modèle et l'inversion du modèle, etc. - Détection intelligente des menaces: plate-forme de détection de l'apprentissage de la machine SOC basée sur Spark
Construction de la sécurité des entreprises
Développement sûr
- Construction de la plate-forme de détection automatisée à balayage de sécurité (BOX BLACK)
- Vous emmène pour lire l'analyse du code source de KunPeng de l'artefact
Tests de sécurité
- Planifiez la mise en place d'un contrôle des risques et d'un système d'alerte précoce
Contrôle des risques de sécurité des entreprises : détecter rapidement les anomalies et définir avec précision les risques. Découvrez des fragments et des entités anormaux grâce à des changements dans les indicateurs de base et découvrez toutes les entités sous le cluster anormal par le biais de méthodes de regroupement; - Le voyage de passage de la sécurité traditionnelle au domaine du contrôle des risques et de la discussion des tendances de l'industrie noire et de l'industrie des risques
Contrôle de la sécurité des entreprises : La lutte dans le domaine du contrôle des risques devient de plus en plus féroce. . Avec le judiciaire avec la répression à haute pression du gouvernement contre les produits noirs et gris, les grandes entreprises feront attention aux capacités des produits et à la légitimité de la conformité des fournisseurs de contrôle des risques à l'avenir. - Préparation d'entretien d'ingénieur du modèle de contrôle des risques - Chapitre technique
- Pratique du modèle de contrôle des risques - Compétition algorithme de contrôle des risques "Magic Mirror Cup"
- Méthode d'identification des utilisateurs de contrôle des risques
- github: sladesha
- Les algorithmes multiples identifient les utilisateurs anormaux tels que la farce des pouvoirs et la fraude des coupons
- DNS Tunnel Covert Communication Experiment && Tentatives de reproduire la détection du mode de réflexion sur la vectorisation
- HIDS for Enterprise Security Construction
- Assurer la sécurité IDC: conception d'architecture de cluster HIDS distribuée
- Dianrong Open Source Agentsmith HIDS --- Un système de HIDS léger
- Construction de la sécurité de l'entreprise - certaines idées sur la conception du système HIDS basé sur les agents
Système de détection d'intrusion de détection d'intrusion : la pratique systématique de Meituan mérite d'être apprise. À partir de la description de la demande, le chef de produit exprime la demande -> analyse la demande, résume les caractéristiques auxquelles l'architecture du produit doit se conformer -> Difficultés techniques, analyse les défis techniques rencontrés -> Conception d'architecture et sélection de technologie -> Cluster Distribué des HIDS Distributed Diagramme d'architecture -> Sélection du langage de programmation-> Implémentation du produit. - Méthode et implémentation de détection du tunnel ICMP basées sur l'analyse statistique
produits de sécurité
- Recueillir d'excellents projets de sécurité open source pour aider les praticiens de sécurité de la fête A pour constituer des capacités de sécurité d'entreprise (apprises) Produits de sécurité open source : y compris la gestion des actifs, le développement de la sécurité, l'audit de code automatisé, l'opération de sécurité et la maintenance, l'hôte de bastion, les HID et l'analyse du trafic réseau , Honeypot, WAF, Enterprise Cloud Disk, Phishing Site Web System, GitHub Survering, Control Control, Vulnerabilité Management, SIEM / SOC.
Opération sûre
- Ce que je comprends des opérations de sécurité
Les entreprises paient pour la production, pas les connaissances . Les opérations de sécurité sont orientées vers la résolution de problèmes. Responsabilités et exigences de compétences pour les opérations de sécurité: sécurité, R&D, fonctionnement et maintenance des compétences de communication ; certaines capacités de gestion de projet ; - Parlons de la raison pour laquelle les opérations sûres: les risques de sécurité sont visualisés et l'apparence est exposée;
Le quoi et comment les opérations sûres: saisissez les principales contradictions et contradictions secondaires et faites de votre mieux pour les résoudre.
Gestion de la sécurité
- La publication de la Skill Tree de Skill Skill Tree V1.0 de la sécurité d'entreprise comprend six parties: description, concept de sécurité, gouvernance de sécurité, compétences générales, compétences professionnelles et ressources de haute qualité.
Réfléchir
- Parlez de la direction de développement de la sécurité des entreprises Internet
Direction du développement de la sécurité de l'entreprise : De moins profond, il est divisé en quatre buts: 1. Poussé par l'élimination des vulnérabilités, le premier objectif est de faire de la naissance de chaque ligne de code par les ingénieurs. Recherche technique dérivée des produits. 2. SDL ne peut pas être à 100% sécurisé, donc le deuxième objectif est de permettre la découverte de toutes les attaques connues et inconnues à la première fois, et rapidement alerté et suivi. Défis: données massives et exigences complexes: puissance de super calcul et modèles tridimensionnels. 3. Le troisième objectif est de faire de la sécurité la compétitivité de base de l'entreprise et de vous approfondir dans les fonctionnalités de chaque produit pour mieux guider les habitudes d'utilisation des utilisateurs des utilisateurs. 4. Le dernier objectif est de pouvoir observer les changements dans toute la tendance de la sécurité Internet et de pratiquer un avertissement précoce des risques à l'avenir. Lorsque vous faites de la sécurité dans une entreprise Internet, vous devez avoir l'imagination et prêter une attention particulière au développement d'autres domaines techniques. être fait. - Promouvoir la défense par l'offensive: Réflexions sur la construction d'une armée bleue d'entreprise
- Ciso Blitz de Zhao Yan | Journey de formation de la sécurité de la fête A (appris)
Objets de portée (entreprise de l'entreprise, défis et besoins de sécurité (défense en profondeur, propre sécurité de la chaîne d'approvisionnement, autonomiser la sécurité tierce)) ---> Réglage des objectifs (réglage de la demande actuel et développement futur) ---> défis (à l'échelle de l'équipe Pile (structure des connaissances et compétences correspondant à la principale entreprise), capacités d'ingénierie, capacités de gestion) ---> Décomposition SYSTÈME DE SÉCURITÉ (SERIEUX CONSTRUCTION Sandbox dans les domaines général: sécurité de R&D, sécurité informatique, sécurité des infrastructures, sécurité des données, sécurité du terminal, sécurité des entreprises, confidentialité et conformité de la sécurité) ---> Implémentation et réponse (Cadre de gouvernance de la sécurité, référence de l'industrie (implémentation réelle capacité, la démo ne compte pas comme cette capacité), la recherche en sécurité). En général, il s'agit d'une vision technique complète (s'efforce de passer du niveau de compétences au niveau de vision technique) + des capacités de gestion de la sécurité.
architecture de sécurité
- Architecture de sécurité du réseau | Amélioration de la sécurité via l'architecture de sécurité] (https://mp.weixin.qq.com/s/m90wyaevhzfsdgnfhmgxcw)
Affrontement rouge et bleu
- [Confrontation rouge et bleue] Construction de l'équipe de sécurité de l'armée bleue pour les grandes entreprises Internet (apprise)
Le pourquoi de la confrontation rouge et bleue : tester le système de protection de la sécurité de l'entreprise;
Quelle est la confrontation du bleu rouge : taux de découverte des intrusions;
Le comment de confrontation rouge-bleu : simulez apt ---> L'équipe bleue doit développer une base de connaissances systématique et une bibliothèque d'armes de techniques d'attaque ---> framework matrix att && ck.
Les défis de la confrontation du bleu rouge avec l' efficacité / avantage;
L'avenir de la confrontation rouge : armée bleue à plusieurs niveaux et multi-scopes; plate-forme de pénétration automatisée de l'armée bleue / plate-forme de combat collaborative; - Construire une confrontation rouge bleu à l'ère de la sécurité du cyberespace (il existe des articles liés à la confrontation rouge-bleu en annexe)
Le combat réel est le seul critère pour tester les capacités de protection de la sécurité . Les tests de pénétration conviennent au stade initial de la construction du système de sécurité de l'entreprise ou de l'étape de l'épuisement, et la confrontation rouge-bleu est une version améliorée des tests de pénétration. Système de construction de sécurité . / peeping et autres champs du point de vue de la sécurité du cyberespace .
Sécurité intranet
- Intranet Security Attack Simulation et Anomalie Detection Rule Practice
L'idée d'écriture : Collection d'informations externes -> Percée aux limites -> Collecte d'informations, Escalade des privilèges -> Maintenance des privilèges -> Collection d'informations, Extraction des informations d'identification -> Mouvement latéral -> Vol de données -> Nettoyer les traces.
Sécurité des données
- Tencent Security lance la "carte des capacités de sécurité des données" au niveau de l'entreprise "
Idées de rédaction : La carte des capacités de sécurité des données comprend six aspects majeurs: la gestion des actifs et les capacités de contrôle des actifs, les capacités de l'opération de sécurité des données, la gestion et les capacités de contrôle de la sécurité commerciale des données, la gestion et les capacités de contrôle de la sécurité de l'environnement de données, le fonctionnement des données et la gestion de la sécurité et le contrôle de la sécurité de la maintenance capacités et capacités de perception de la sécurité des données.
Nouvelle technologie et nouvelle sécurité
Aperçu
- Modernisation des applications et changement de sécurité laissé dans la transformation numérique
Idées d'écriture : Nouvelle infrastructure -> Transformation numérique -> L'informatisation traditionnelle fait face à des défis -> Modernisation des applications axée sur l'entreprise -> Cloud natif, conteneurisation, DevOps, Microservices d'application, orchestration et autres nouvelles technologies -> Architecture de modernisation des applications -> Sécurité endogène (TOUS - Perception terminée, fiabilité, intervention de sécurité à pleine processus et fonctionnement sûr du réseau cloud).
natif de nuage
- Interprétation de la technologie de détournement transparent du réseau natif du cloud Native |
L'idée d'écriture : service de service-> istio-> plan de données-> Proxy réseau-> MOSN-> détournement de trafic efficace et transparent. Problème: rachat du trafic. Problèmes de résolution: adaptation de l'environnement, gestion de la configuration, performances du plan de données. - Cloud Native Intrusion Detection Tendance Observation
L'idée d'écriture : diversification des actifs, fragmentation du service, éruption de middleware, sécurité des infrastructures par défaut -> la détection d'intrusion "orientée vers les affaires", l'analyse comportementale deviendra la capacité de base. - Wang Renfei (AVFisher): équipe rouge pour le nuage (infraction au nuage et défense) (Mark)
Informatique de confiance
- Zhang OU: Pratique du réseau de confiance en banque numérique
Idées d'écriture : Le problème essentiel est: la défense en profondeur au niveau du réseau. Pourquoi le faire (défier) -> Idées et plans de mise en œuvre -> Défis et pensées dans le processus . - He Yi: La route de la pratique de l'architecture de sécurité zéro fiducie
Point de base : Le cœur de la confiance zéro est l'établissement de chaînes de confiance telles que les utilisateurs + les appareils + les applications, la vérification dynamique sécurisée et continue et le rétrécissement de la surface d'attaque. Travail effectué: passerelle réseau, passerelle hôte, passerelle d'application, SOC .
Devsecops
- "La sécurité nécessite la participation de chaque ingénieur" -Devsecops Philosophie et pensée (Mark)
développement sûr
développement personnel
entretien
- Entretiens en matière de sécurité, stages, etc.
Entretiens : Didi, Baidu (2), 360 (2), Alibaba (6), Tencent (3), Bilibili, Huawei, Tonghuashun, Mogujie. De manière générale, les grands sont si forts que la plupart de leurs choix sont le service de sécurité de la fête A. Ma compréhension: après avoir lu les interviews et les questions posées par les gros gars, il est vraiment divers Impossible de les copier rigidement. - Résumé des entretiens sur la sécurité du recrutement du printemps 2018 Résumé de l'interview
- Tencent 2016 Stage Recruitment Déteint Explication des réponses aux questions écrites du post de sécurité
Test écrit : Concevoir une solution d'authentification Web sécurisée: Front-end: Code de vérification + CSRF_TOKINE + Générer des nombres aléatoires en fonction du chiffrement à horaire; , port, protocole); - Entretiens pour les postes de technologie de sécurité dans les grandes entreprises
Entretien : Basics of Security Technology ---> Détails du projet (profondeur des connaissances, écrasant l'intervieweur dans les domaines d'expertise, empêchant l'intervieweur de poser des questions approfondies) ---> Comment gérer les questions difficiles (connaissances et cognitive de l'industrie La capacité ne s'écarte généralement pas du domaine de l'expertise et nécessite une lecture et une réflexion quotidiennes) ---> Capacité cognitive approfondie de l'industrie et planification de carrière - Quelle est la situation actuelle des références internes pour les stagiaires d'Alibaba en 2019? - Réponse de Zuo Zuo Vera - Zhihu (appris)
- Dix visages d'Ali, sept visages de gros titres, pensez-vous que je suis entré dans Ali?
Entretien : Version Java d'une excellente expérience d'interview, un incontournable pour Java. - Livre des épées et inimities: moi et Alibaba (trop fort)
- Questions d'entrevue de recrutement de sécurité (apprises)
Idées d'écriture : tests de pénétration (direction Web), recherche et développement en sécurité (direction Java), opérations de sécurité (direction d'audit de la conformité), architecture de sécurité (direction de la sécurité)
Apprentissage supplémentaire : CRLF, les différences, les avantages et les inconvénients du chiffrement symétrique et du cryptage asymétrique, du processus d'interaction HTTPS, de la politique d'origine, des demandes de domaine croisé. - À quoi ressemble un bon CV pour un recrutement sûr?
- Recrutement de sécurité: situation actuelle de l'industrie de la sécurité
- Qualités essentielles des praticiens de la sécurité pour le recrutement de sécurité
Idée d'écriture: qualité de base = capacité de base (auto-ajusté + apprentissage indépendant) + capacité professionnelle (attaque de pénétration et défense + développement logiciel). Qualités avancées = intelligence (IQ + Intelligence émotionnelle) + bravoure et optimisme + introspection . - Le processus d'entrevue pour le recrutement en toute sécurité est maintenant paresseux, et il coûtera plus cher pour le compenser plus tard.
- Un ingénieur de sécurité 2019
Idées d'écriture : ancienne piste et nouveau voyage - "Explorateur ou suiveur de l'industrie -" Échange transparent d'informations sur l'industrie - "Ajoutez un peu de sel à la vie".
développement de carrière
- Auto-culture des chercheurs en sécurité
- Auto-culture des chercheurs en sécurité (suite)
- Discussion sur la direction de développement du personnel de sécurité
Route de développement de la sécurité de la fête A : Type de technologie du core dure ---> Dachang Laboratories and Security Research Posts Type de technologie non dur -> Internet Enterprise Security Construction Red and Blue, Operations techniques, gestion de la sécurité - L'importance de l'existence de praticiens de la sécurité
Développement personnel : L'objectif est d'aider les problèmes de sécurité de la productivité avancée. Le problème de sécurité est un problème de confiance (soutien en fiducie, soutien d'origine), une science qui étudie la confrontation (confrontation entre les personnes) et un problème de probabilité (architecture de sécurité). La sécurité est une science appliquée. , y compris l'intelligence machine et la technologie de la blockchain. - Plusieurs identités de l'équipe de sécurité dans l'entreprise
团队发展:安全团队应该以服务者和协作者的身份,用专业的安全能力给出一类安全问题的解决思路和方案并解决,防止安全问题发生多次。
行业发展
安全格局
- 最新统计2005-2017年国内科研单位在国际安全顶级会议中发表文章量统计
- 从内容产出看安全领域变化
技术格局:企鹅等互联网巨头开始进行流量封锁,对安全从业人员影响很大,爬不到数据,api又有限,只能上升到app hook了;技术上安全分析、数据挖掘、威胁情报的比重越来越重, AI已经不仅仅是噱头了,智能安全势不可挡;安全的职业发展方面,越来越多大佬们开始转型业务安全、数据安全。 - 网络安全行业竞争格局浅析
市场格局:基础安全防护(传统安全防护能力),中级安全防护(海量数据建模与分析能力),高级安全防护(云端威胁情报与分析能力),中高级安全防护市场广阔。此外,全文在多处凸显了人工智能技术,智能安全开始迈入开悟之坡了吗? !半数以上的人看好智能安全,也有人不看好智能安全,未来会怎么样,让我们拭目以待! - ZoomEye 网络空间测绘——委内瑞拉停电事件对其网络关键基础设施和重要信息系统影响
- 2020安全工作展望
Logic of writing : Major events in 2019 : HW action changes safety from implicit to explicit, low frequency to high frequency, exposes problems, and promotes management to pay attention to safety. This is the background; Classification Protection 2.0 safety compliance is becoming more stringent . 2019大变化:领导重视了;实战化了。 2020甲方安全关注技术点:安全运营(覆盖率和正常率等指标、是否有验证思路:能否在一定时间内主动发现安全措施失效)和安全资产管理(CMDB、主机上数据、流量、扫描、人工添加)。 2020关注“人”的需求。 2020展望行业:甲方安全团队组织架构会发生剧烈变化,安全团队能否承受变化;甲乙两方相处之道;安全黑天鹅事件越来越多。
安全产品
- C端安全产品的未来之路
C端安全产品:移动端安全产品是否会像前几天PC端安全产品一样迎来春天?PC时代windows是一家独大的完全开放的平台,这让第三方安全公司能够在平台和用户之间产生价值的空间足够的大,但在移动端,安卓开始封闭,就不好说了。传统安全软件围绕病毒和欺诈,而围绕个人信息安全的C端安全产品有一线生机。 - 下一座圣杯- 2019
API安全:应用安全的发展:2015年预测,数据是新中心,身份是新边界,行为是新控制,情报是新服务。基础设施演进->交付方式的改变。2015年,应用安全领域的WAF产品是良机,由市场决定。新形势与新机遇:微服务、Serverless、边缘计算。市场中的交付方式发生变化。跨细分领域且跨基础设施:API安全横跨应用安全、数据安全和身份安全三大领域。API使用场景广泛,需要产品有全面覆盖多种不同基础设施的能力。
données
数据体系
- 数据分析师如何搭建数据运营指标体系? - 张溪梦Simon的回答
Core point : Collaboration process empowerment : Implementing the data-driven XX indicator system construction process requires cross-team collaboration. The processes include: demand collection, program planning, data collection, collection program evaluation, data collection and data verification online, and effect evaluation .规划数据指标体系的两个模型:OSM和UJM。 OSM强调业务目标,UJM强调用户旅程。指标分级体系:一二三级指标联动。 - 如何在企业中从0-1建立一个数据/商业分析部门?(学到了)
部门的定位和价值——>里程碑设计——->团队搭建——->构建IT数据——->前期管理。
定位和价值是一个部门立足公司的根本:做报表的部门VS做战略的部门;业务其他公司的定位和公司内其他部门的认可;一定要会放大部门的价值和一定要走高层路线。
设立长期目标并拆解里程碑:公司业务目标--->公司战略--->部门目标--->部门里程碑--->工作计划;设立里程碑的技巧?借势、共赢、取巧、筑基;借老板势,寻找1-2个老板的痛点问题解决;寻找利益相同的部门共建共赢;取巧摘已有的“桃子”;筑基数据链路梳理、数据清洗、系统互联、数据仓库设计、数据集市设计。
基于里程碑进行团队搭建:切忌一步到位;审慎拉帮结派;遇到人才不可错过;学会“画饼”;注意团队文化建设。
构建公司的数据IT能力:搭建基础且通用的数据流框架:应用层、归集层、加工层、分析层、展示层; 同时根据各种数据库选型指标选择对应的数据库存储产品,数据库选型指标比如容量、水平扩展性、查询实时性、查询灵活性、写入速度、事务、数据存储、处理数据规模、列扩展性。在搭建数据框架中需要注意的点是:需要实现公司级别的业务数据架构。基于业务对整个公司的数据进行体系化的梳理,任何的业务变化都会体现在数据之上,实现数据充分体现业务现状的目的。要完成这一步的关键是完成公司级别的主数据管理:明确各项数据的业务含义和口径、明确每个数据的职责单位、打通数据链路,推动数据共享。
引领团队走向胜利:做“排长”而不要做“军长”;让合适的人做合适的事;明确规则,及时兑现。
数据分析与运营
- 数据分析与可视化:谁是安全圈的吃鸡第一人(学到了)
数据分析与可视化:收集数据集--->观察数据集--->社群发现与社区关系--->玩家画像。 - 请分享一下数据分析方面的思路,如何做好数据分析?
核心点:数据分析的问题:业务的数据分析指标体系(点线面体)。数据分析的方法:分类和对比。
安全数据分析
- Data-Knowledge-Action: 企业安全数据分析入门(优秀,学到了)
综述: 1、让模型理解业务,基于业务历史行为建立异常基线,在异常的基础上检测威胁;将运营结果反馈到模型,将误报视作正常行为回流。2、安全运营可运营,降低事件调查成本,自动化信息收集与聚合。3、随着数据的积累,安全数据分析将向基于图结构的高级知识表达方式发展。(这点深表赞同)4、对场景、攻击模式、数据的认识深度,远比选择工具重要。 - Security Data Science Learning Resources
综述:作者的研究点也是安全数据科学,整理了一些学习方法和学习资源。学习方法主要分为三个方面:谷歌学术、Twitter、安全会议。谷歌学术关注知名研究者以及他们新出的文章,关注引用了你关注的文章的文章,Twitter关注细分安全领域的人群,关注安全会议以及会议议程。学习资源:书籍和课程。 - 快速搭建一个轻量级OpenSOC架构的数据分析框架(一)(学到了)
框架:行文思路:由粗变细(由框架到举例子(由框架到场景到实际架构))。OpenSOC介绍(框架组成和工作流程)---》构建轻量级OpenSOC(聚焦具体场景和工具及具体架构)---》搭建步骤(每一步的环境搭建及配置)---》效果展示。 - 先知talk:从数据视角探索安全威胁
- 大数据威胁建模方法论(学到了很多)
- 安全日志维度随想
- 数据安全分析思想探索
- DataCon 2019: 1st place solution of malicious DNS traffic & DGA analysis(学到了)
我的理解:涉及的知识点有:安全场景:DNS安全;数据处理:tshark工具的使用,MaxCompute和SQL的使用,PAI预分析和可视化;特征工程:DNS_type、src_ip维度的特征;异常检测算法:单特征3sigma检测;人工提取特征规则。
第一小题DNS恶意流量的异常检测:个人吸收80%,整理流程无障碍,每步流程中的细节和工具还未完全掌握,比如DNS安全场景了解不全面、tshark的大量数据解析、统计特征的全面提取、SQL语句做特征化;
第二小题DGA的多分类:个人吸收50%,流程搞懂了,但是对一些问题的理解还不到位,比如社区算法 - 基于大数据企业网络威胁发现模型实践
我的理解:问题:多源安全分析设备和服务(威胁数据)的横向和纵向联动。
algorithme
IA
算法体系
- 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
算法知识框架:主要从算法的定义、过程、代表性算法、优缺点解释回归、正则化算法、人工神经网络、深度学习||决策树算法、集成算法||支持向量机||降维算法、聚类算法||基于实例的算法||贝叶斯算法||关联规则学习算法||图模型。
个人理解:回归系列主要基于线性回归和逻辑回归衍生,包括回归、正则化算法、人工神经网络、深度学习;树系列主要基于决策树衍生,包括决策树和基于树的集成学习算法;支持向量机属于老牌算法;降维算法和聚类算法主要基于数据的内在结构描述数据;基于实例的算法实际上并没有训练的过程,代表性算法是KNN,基于记忆的学习;贝叶斯算法利用贝叶斯定理计算输出概率;关联规则学习算法能够提取数据中变量之间的关系的最佳解释;图模型是一种概率模型,可以表示随机变量之间的条件依赖结构。 - Categories of algorithms non exhaustive (学到了)
算法知识框架:学到了搭建自己的算法体系。
connaissances de base
- HTTP DATASET CSIC 2010
Security Data Set-CSIC2010 : A security data set automatically generated based on e-Commerce Web application, including 36,000 normal requests and 25,000 abnormal requests. Abnormal requests include: SQL injection, buffer overflow, information collection, file leakage, CRLF injection, XSS etc . - 分类模型的性能评估——以SAS Logistic 回归为例(3): Lift 和Gain
- 机器学习中非均衡数据集的处理方法?
非均衡数据集:上采样和下采样、正负样本的惩罚权重(scikit-learn的SVM为例:class_weight:{dict,'balanced'})、组合/集成方法(从大样本中抽取多个小样本训练模型再集成)、特征选择(小样本量具有一定规模的时候,选择显著型的特征) - 机器学习算法中GBDT 和XGBOOST 的区别有哪些?
算法比较:GBDT基分类器为CART,XGB的分类器可以是多种基分类器,比如线性分类器,这时候就相当于L1、L2正则项的逻辑回归或线性回归;传统的GBDT在优化时用到的是一阶导数,XGB则对损失函数进行了二阶泰勒公式的展开,精度变高;XGB并行处理(特征粒度的并行,对特征值进行预排序存储为block结构,在进行节点分类的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分类,那么各个特征的增益计算就可以开多线程进行),相对于GBM速度飞跃;剪枝时,当新增分类带来负增益时,GBM会停止分裂,而XGB一直分类到指定的最大深度,然后进行后全局剪枝;从最优化的角度来看,GBDT采用的是数值优化的思维,用的最速下降法去求解Loss function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长,而XGB用的是解析的思维,对Loss function展开到二阶近似,求得解析解,用解析解作为Gain来建立决策树,使得Loss function最优。 - SVM和logistic回归分别在什么情况下使用?
算法使用场景-SVM和逻辑回归使用场景:需要根据特征数量和训练样本数量来确定。如果特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型,则使用LR或线性核函数的SVM。 If the training samples are large enough and the number of features is small, better prediction performance can be obtained through SVM with complex kernel functions. If the samples do not reach millions, SVM with complex kernel functions will not cause the operation to be too slow .如果训练样本特别大,使用复杂核函数的SVM已经会导致运算过慢了,因此应该考虑引入更多特征,然后使用线性SVM或者LR来构造模型。 - gbdt的残差为什么用负梯度代替?
- 欧氏距离与马氏距离
- 机器学习算法常用指标总结
- 分类模型评估之ROC-AUC曲线和PRC曲线
apprentissage automatique
- 平均数编码:针对高基数定性特征(类别特征)的数据预处理/特征工程
- Mean Encoding
- kaggle编码categorical feature总结
- Python target encoding for categorical features
- Mean (likelihood) encodings: a comprehensive study
- 如何在Kaggle 首战中进入前10%
- kaggle竞赛总结
- 分享一波关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
- 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?
有监督学习-树系列算法:单模型,gradient boosting machine和deep learning是首选。gbm不需要复杂的特征工程,不需要太多时间去调参数,dl则需要比较多的时间去调网络结构。从overfit角度理解,两者都有overfit甚至perfect fit的能力,overfit能力越强,可塑性越强,然后我们要解决的问题就是如果把模型训练的“恰好”,比如gbm里有early_stopping功能。线性回归模型就缺乏overfit能力,如果实际数据符合线性模型的关系,那可以得到很好的结果,如果不符合的话,就需要做特征工程,可特征工程又是一个比较主观的过程。树的优势,非参数模型,gbm的overfit能力强。而random forest的perfact fit能力很差,这是因为rf的树是独立训练的,没有相互协作,虽然是非参数型模型,但是浪费了这个先天优势。 - 【总结】树类算法认知总结
有监督学习-树类算法:分类树和回归树的区别;避免决策树过拟合的方法;随机森林怎么应用到分类和回归问题上;kaggle上为啥GBDT比RF更优;RF、GBDT、XGBoost的认知(原理、优缺点、区别、特性)。 - LightGBM
- LightGBM算法总结
- 『我爱机器学习』集成学习(四)LightGBM
- 如何玩转LightGBM(官方slides讲解)
有监督学习-LightGBM-个人理解: LightGBM几大特性及原理:直方图分割及直方图差加速(直方图两大改进:直方图复杂度=O(#feature×#data),GOSS降低样本数,EFB降低特征数)-》效率和内存提升。Leaf-wise with max depth limitation取代Level-wise-》准确率提升。支持原生类别特征。并行计算:数据并行(水平划分数据)、特征并行(垂直划分数据)、PV-Tree投票并行(本质上是数据并行)。 - 快速弄懂机器学习里的集成算法:原理、框架与实战
- 时间序列数据的聚类有什么好方法?
无监督学习-时间序列问题:传统的机器学习数据分析领域:提取特征,使用聚类算法聚集;在自然语言处理领域:为了寻找相似的新闻或是把相似的文本信息聚集到一起,可以使用word2vec把自然语言处理成向量特征,然后使用KMeans等机器学习算法来作聚类;另一种做法是使用Jaccard相似度来计算两个文本内容之间的相似性,然后使用层次聚类的方法来作聚类。常见的聚类算法:基于距离的机器学习聚类算法(KMeans)、基于相似性的机器学习聚类算法(层次聚类)。对时间序列数据进行聚类的方法:时间序列的特征构造、时间序列的相似度方法。如果使用深度学习的话,要么就提供大量的标签数据;要么就只能使用一些无监督的编码器的方法。 - 凝聚式层次聚类算法的初步理解
无监督学习-层次聚类:算法步骤:计算邻近度矩阵--->(合并最接近的两个簇--->更新邻近度矩阵)(repeat),直到达到仅剩一个簇或达到终止条件。 - 推荐算法入门(1)相似度计算方法大全
无监督学习-层次聚类-相似性计算:曼哈顿距离、欧式距离、切比雪夫距离、余弦相似度、皮尔逊相关系数、Jaccard系数。
apprentissage profond
CPU环境搭建
- tensorflow issues#22512
Nature of the problem : Error: ImportError: DLL load failed, reason: missing dependencies, solution: pip install --index-url https://pypi.douban.com/simple tensorflow==2.0.0, dependencies will be installed automatically .
GPU环境搭建
- Tensorflow和Keras 常见问题(持续更新~)(坑点)
- Tested build configurations(版本对应速查表)
- windows tensorflow-gpu的安装(靠谱)
- windows下安装配置cudn和cudnn
问题本质:总的来说,是英伟达显卡驱动版本、cuda、cudnn和tensorflow-gpu之间版本的对应问题。最好装tensorflow-gpu==1.14.0,tensorflow-gpu==2.0需要cuda==10.0,10.2会报错,tensorflow-gpu==2.0不支持。 - win10搭建tensorflow-gpu环境
问题本质:CUDA的各种环境变量添加。
深度学习基础知识
- 深度学习中的batch的大小对学习效果有何影响?
- Batch Normalization原理与实战(还没完全看懂)
神经网络基本部件
- 如何计算感受野(Receptive Field)——原理感受野:卷积层越深,感受野越大,计算公式为(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel,思路为倒推法。
- 如何理解空洞卷积(dilated convolution)谭旭的回答空洞卷积:池化层减小图像尺寸同时增大感受野,空洞卷积的优点是不做pooling损失信息的情况下,增大感受野。3层3*3的传统卷积叠加起来,stride为1的话,只能达到(kernel_size-1)layer+1=7的感受野,和层数layer成线性关系,而空洞卷积的感受野是指数级的增长,计算公式为(2^layer-1)(kernel_size-1)+kernel_size=15。
- 空洞卷积(dilated convolution)感受野计算
- 空洞卷积(dilated Convolution)
- 直观理解神经网络最后一层全连接+Softmax(便于理解)
全连接层:可以理解为对特征的加权求和。
神经网络基本结构
- 一组图文,读懂深度学习中的卷积网络到底怎么回事?
卷积神经网络:卷积层参数:内核大小(卷积视野3乘3)、步幅(下采样2)、padding(填充)、输入和输出通道。卷积类型:引入扩张率参数的扩张卷积、转置卷积、可分离卷积。 - 卷积神经网络(CNN)模型结构
- 总结卷积神经网络发展历程- 没头脑的文章(很全面)
- 三次简化一张图:一招理解LSTM/GRU门控机制(很清晰)
循环神经网络:文中电路图的形式好理解。RNN:输入状态、隐藏状态。LSTM:输入状态、隐藏状态、细胞状态、3个门。GRU:输入状态、隐藏状态、2个门。LSTM和GRU通过设计门控机制缓解RNN梯度传播问题。 - gcn
- GRAPH CONVOLUTIONAL NETWORKS
图神经网络:相较于CNN,区别是图卷积算子计算公式。 - keras-attention-mechanism
神经网络应用
- [AI识人]OpenPose:实时多人2D姿态估计| 附视频测试及源码链接
- 使用生成对抗网络(GAN)生成DGA
- GAN_for_DGA
- 详解如何使用Keras实现Wassertein GAN
- Wasserstein GAN in Keras
- WassersteinGAN
- keras-acgan
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题- 综述和实践
NLP :传统的高维稀疏->现在的低维稠密。注意事项:类目不均衡、理解数据(badcase)、fine-tuning(只用word2vec训练的词向量作为特征表示,可能会损失很大效果,预训练+微调)、一定要用dropout、避免训练震荡、超参调节、未必一定要softmax loss、模型不是最重要的、关注迭代质量(为什么?结论?下一步?)
apprentissage par renforcement
- 深度强化学习的弱点和局限
- 关于强化学习的局限的一些思考
强化学习的局限性:采样效率很差、很难设计一个合适的奖励函数。
Domaines d'application
- 全球最全?的安全数据网站(有时间得好好整理一下)
- 初探机器学习检测PHP Webshell
- 基于机器学习的Webshell 发现技术探索
- 网络安全即将迎来机器对抗时代?
智能安全-智能攻击:国外已经在研究利用机器学习打造更智能的攻击工具,比如深度强化学习,就是深度学习和强化学习的结合,可以感知环境,做出最优决策,可能被应用到漏洞扫描器里,使扫描器能够自动化地入侵目标。
个人理解:国外已有案例Deep Exploit就是利用深度强化学习结合metasploit进行自动化地渗透测试,国内还没有看到过相关公开案例。由于学习门槛高、安全本身攻击场景需要精细化操作、弱智能化机器学习导致的机器学习和安全场景结合深度不够等一系列的问题,已有的机器学习+安全的大多数研究主要集中在安全防护方面,机器学习+攻击方面的研究较少且局限,但是我相信这个场景很有潜力,或许以后就成为蓝方的攻击利器。 - 人工智能反欺诈三部曲之:设备指纹
智能安全-业务安全-设备指纹:ip、cookie、设备ID ;主动式设备指纹:使用JS或SDK从客户端抓取各种各样的设备属性值,然后组合,通过hash算法得到设备ID;优点:Web内或者App内准确率高。 Disadvantages : Active device fingerprinting will generate different device IDs between Web and App and between different browsers, and cannot achieve device association across Web and App, and between different browsers; due to reliance on client code, fingerprinting It is less confrontational in anti-fraud scénarios.被动式设备指纹:从数据报文中提取设备OS、协议栈和网络状态的特征集,并结合机器学习算法识别终端设备。优点:弥补了主动式设备指纹的缺点。缺点:占用处理资源多;响应时延比主动式长。 - 风险大脑支付风险识别初赛经验分享【谋杀电冰箱-凤凰还未涅槃】
智能安全-业务安全-风控:个人理解见:https://github.com/404notf0und/Risk-Operation-Detection/blob/master/atec.ipynb。 - 机器学习在互联网巨头公司实践
入侵检测:机器学习和统计建模的主要区别:机器学习主要依赖数据和算法,统计建模依赖建模者对数据特征的了解。两者的优缺点:机器学习:打标数据难获取,如果采用非监督学习,则性能不足以运维;机器学习结果不可解释。所以现在机器学习在做入侵检测的时候,一般都要限定一个特定的场景。统计建模:数据预处理阶段移除正常数据的干扰(重点关注查全率,强调过正常数据的过滤能力,尽可能筛除正常数据),构建能够识别恶意可疑行为的攻击模型(重点关注precision,强调模型对异常攻击模式判断的准确性,攻击链模型),缺点是泛化能力不足、在入侵检测一些场景中,模型易被干扰。我们的最终目的:大数据场景下安全分析可运维。 - Web安全检测中机器学习的经验之谈
Web安全:从文本分类的角度解决Web安全检测的问题。数据样本的多样性,短文本分类,词向量,句向量,文本向量。文本分类+多维度特征。与传统方法做对比得出更好的检测方式:传统方法+机器学习:传统waf/正则规则给数据打标;传统方法先进行过滤。 - 词嵌入来龙去脉(学到了)
PNL :DeepNLP的核心关键:语言表示--->NLP词的表示方法类型:词的独热表示和词的分布式表示(这类方法都基于分布假说:词的语义由上下文决定,方法核心是上下文的表示以及上下文与目标词之间的关系的建模)--->NLP语言模型:统计语言模型--->词的分布式表示:基于矩阵的分布表示、基于聚类的分布表示、基于神经网络的分布表示,词嵌入--->词嵌入(word embedding是神经网络训练语言模型的副产品)--->神经网络语言模型与word2vec。 - 深入浅出讲解语言模型
NLP :NLP统计语言模型:定义(计算一个句子的概率的模型,也就是判断一句话是否是人话的概率)、马尔科夫假设(随便一个词出现的概率只与它前面出现的有限的一个或几个词有关)、N元模型(一元语言模型unigram、二元语言模型bigram)。 - 有谁可以解释下word embedding? - YJango的回答- 知乎
NLP :单词表达:one hot representation、distributed representation。Word embedding:以神经网络分析one hot representation和distributed representation作为例子,证明用distributed representation表达一个单词是比较好的。word embedding就是神经网络分析distributed representation所显示的效果,降低训练所需的数据量,就是要从数据中自动学习出输入空间到distributed representation空间的映射f(相当于加入了先验知识,相同的东西不需要分别用不同的数据进行学习)。训练方法:如何自动寻找到映射f,将one hot representation转变成distributed representation呢?思想:单词意思需要放在特定的上下文中去理解,例子:这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用输入单词x 作为中心单词去预测其他单词z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。 - Chars2vec: character-based language model for handling real world texts with spelling errors and…
- Character Level Embeddings
- 使用TextCNN模型探究恶意软件检测问题
恶意软件检测:改进分为两个方面:调参和结构。调参:Embedding层的inputLen、output_dim,EarlyStopping,样本比例参数class_weight,卷积层和全连接层的正则化参数l2,适配硬件(GPU、TPU)的batch_size。结构:增加了全局池化层。
学到了:一个trick,通过训练集和评价指标logloss计算测试集的各标签数量,以此调整训练阶段的参数class_weight,还可以事先达到“对答案”的效果。和一个T大大佬在datacon域名安全检测比赛中使用的trick如出一辙。 - 基于海量url数据识别视频类网页
CV-行文思路:问题:视频类网页识别。解决方式:url粗筛->视频网页规则粗筛->视频网页截屏及CNN识别。
行业发展
- 认知智能再突破,阿里18 篇论文入选AI 顶会KDD
认知智能:计算智能->感知智能->认知智能。快速计算、记忆、存储->识别处理语言、图像、视频->实现思考、理解、推理和解释。认知智能的三大关键技术:知识图谱是底料、图神经网络是推理工具、用户交互是目的。 - 未来3~5 年内,哪个方向的机器学习人才最紧缺? - 王喆的回答
要点简记:站在机器学习“工程体系”之上,综合考虑“模型结构”,“工程限制”,“问题目标”的算法“工程师”。我的理解:红利的迁移,模型结构单点创新带来的收益->体系结构协同带来的收益。 阿里技术副总裁贾扬清:我对人工智能的一点浅见
AI发展:神经网络和深度学习的成功与局限,成功原因是大数据和高性能计算,局限原因是结构化的理解和小数据上的有效学习算法。 AI这个方向会怎么走?传统的深度学习应用,比如图像、语音等,应该如何输出产品和价值?而不仅仅是停留在安防这个层面,要深入到更广阔的领域。除了语音和图像之外,如何解决更多问题?而不仅仅是停留在解决语音图像等几个领域内的问题。
综合素质
- 算法工程师必须要知道的面试技能雷达图(学到了)
个人发展-必备技术素质:算法工程师必备技术素质拆分:知识、工具、逻辑、业务。 On the basis of meeting the minimum requirements, algorithm engineers have relatively comprehensive capabilities in these four aspects, including both "algorithm" and "engineering", while big data engineers focus on "tools" and researchers focus on "knowledge" and "logic" .
针对安全业务的算法工程师就是安全算法工程师。为了便于理解,举个例子,如果用XGBoost解决某个安全问题,那么可以由浅入深理解,把知识、工具、逻辑、业务四个方面串起来:
1.GBDT的原理(知识)
2.决策树节点分裂时是如何选择特征的? (Connaissance)
3.写出Gini Index和Information Gain的公式并举例说明(知识)
4.分类树和回归树的区别是什么(知识)
5.与Random Forest对比,理解什么是模型的偏差和方差(知识)
6.XGBoost的参数调优有哪些经验(工具)
7.XGBoost的正则化和并行化分别是如何实现的(工具)
8.为什么解决这个安全问题会出现严重的过拟合问题(业务)
9.如果选用一种其他模型替代XGBoost或改进XGBoost你会怎么做? Pourquoi? (业务、逻辑、知识)。
以上,就是以“知识”为切入点,不仅深度理解了“知识”,也深度理解了“工具”、“逻辑”、“业务”。
- [校招经验] BAT机器学习算法实习面试记录(学到了)
个人发展-面试经验:根据面试常遇到的问题再深入理解机器学习,储备自己的算法知识库。 - 机器学习如何才能避免「只是调参数」? (Savant)
个人发展-职业发展:机器学习工程师分为三种:应用型(能力:保持算法全栈,即数据、建模、业务、运维、后端,重点在建模能力,流程是遇到一个指定的业务场景应该迅速知道用什么数据做特征,用什么模型,这个模型在工程上的时效性和鲁棒性,最终会不会产生业务风险等一整套链路。预期目标:锻炼得到很强的业务敏感性,快速验证提出的需求)、造轮子型(多读顶会跟上时代节奏,且拥有超强的功能能力,打造ML框架,提供给应用型机器学习工程师使用)、研究型(AI Lab,读论文+试验性复现)。 Personal development: Develop business and engineering capabilities. The growth plan for the next few years is still the full-stack algorithm route. I will be independent in technology and bring KPIs in business. I will be promoted quickly + lead the team in the future .同时保持阅读习惯,多学习新知识。 - 做机器学习算法工程师是什么样的工作体验?
个人发展-工作体验:业务理解、数据清洗和特征工程、持续学习(增强解决方案的判断力)、编程能力、常用工具(XGB、TensorFlow、ScikitLearn、Pandas(表格类数据或时间序列数据)、Spark、SQL、FbProphet(时间序列)) - 大三实习面经(学到了)
- 如果你是面试官,你怎么去判断一个面试者的深度学习水平?
个人发展-心得体会:深度学习擅长处理具有局部相关性的问题和数据,在图像、语音、自然语言处理方面效果显著,因为图像是由像素构成,语音是由音位构成,语言是由单词构成,都有局部相关性,可以构造高级特征。 - 面试官如何判断面试者的机器学习水平? - 微调的回答- 知乎
个人发展-心得体会:考虑方法优点和局限性,培养独立思考的能力;正确判断机器学习对业务的影响力;学会分情况讨论(比如深度学习相对于机器学习而言);学习机器学习不能停留在“知道”的层次,要从原理级学习,甚至可以从源码级学习,知其然知其所以然,要做安全圈机器学习最6的。 - 两年美团算法大佬的个人总结与学习建议
个人发展-心得体会:算法的基本认识(知识)、过硬的代码能力(工具)、数据处理和分析能力(业务和逻辑)、模型的积累和迁移能力(业务和逻辑)、产品能力、软实力。
Profession
职业规划
pensée
- 如何解决思维混乱、讲话没条理的情况? (Savant)
结构化思维->讲话有条理。 - 哪些思维方式是你刻意训练过的? (Savant)
结构化思维
金字塔思维:结论先行,以上统下,归类分组,逻辑递进。
金字塔结构:纵向延伸,横向分类。
如何得出金字塔结论:归纳法,演绎推理法。实际生活中,不是每时每刻都有相关的模型套用和演绎法的,这时候就用归纳法,自下而上进行梳理,得出结论,比如头脑风暴把闪过的碎片想法全部写下来,再抽象与分类,最后得出结论。 - 厉害的人是怎么分析问题的? (Savant)
Define the problem/describe the problem: The essence of the problem is the gap between reality and expectations ; clarify the expected value B', accurately locate the current situation B, and use the gap B--->B' to accurately describe the problème.
分析问题/解决问题:不能从现状B出发,找寻一条B--->B'的路径,要透过现象看本质。方法A,现实B,期望B',变量C。校准期望B',重构方法A,消除变量C。
communiquer
gérer
- “我是技术总监,你干嘛总问我技术细节?”
(快速发展期、平稳期、衰退期等业务发展时期作为时间轴)(中高层管理者)(需要掌握)(应用场景、技术基础、技术栈中的技术细节)。技术基础要扎实,技术栈了解程度深(对技术原理和细节清楚),应用场景不能浮于表面。总的来说就是一句话:技术细节与技术深度。 - 阿里巴巴高级算法专家威视:组建技术团队的一些思考(学到了)
行文思路:团队的定位(定位(能力、业务、服务)、壁垒(以不变应万变沉淀风险管控知识作为壁垒)和价值(提供不同层次的服务形式))-》团队的能力(连接、生产、传播、服务)-》组织与个人的关系-》招人-》用人-》对内管理模式(找对前进的方向、绩效的考核(3个维度:业务结果、能力进步、技术影响力))
学到了:建设技术体系解决某一类问题,而不是某个技术点去解决某一个问题。 - 26岁当上数据总监,分享第一次做Leader的心得
团队管理方面的基本功和方法论:定策略、建团队、立规矩、拿结果。
定策略:要明确公司高层的真实目的;对自己的团队了如指掌;管理者专精的行业知识和经验。
建团队:避免嫉贤妒能、职场近亲、玻璃心。
立规矩:立规矩守规矩。
拿结果:注意吃相。
管理中常见的误区:做管理后放弃原来专业(要关注行业发展方向和前沿技术);过度管理(要自循环的稳定成熟团队);过度追求团队稳定(衡量团队稳定的核心标准不是人员的稳定,而是团队的效率和产出是否能够有持续稳定的增长) - 什么特质的员工容易成为管理者
公司内部晋升管理者:天时:企业/行业所处的阶段;地利:部门/业务所处的阶段;人和:人际关系+自身能力。
跳槽成为管理者:大公司跳槽到小公司,寻找职业突破,弊端是跳出去容易跳回来难;成为行业内有影响力的人物,被大公司挖角。大部分人都是第一种情况,在大公司的同学要多一点耐心,通过努力在公司内晋升,因为曲线救国式的跳槽已经没有市场了。 - 技术部门Leader是不是一定要技术大牛担任?
核心点:Manager vs Tech Leader、方法论、软技能、赋能成员、综合。
pense
- 好的研究想法从哪里来
研究的本质是对未知领域的探索,是对开放问题的答案的追寻。“好”的定义-》区分好与不好的能力-》全面了解所在研究方向的历史和现状-》实践法/类比法/组合法。这就好比是机器学习的训练和测试阶段,训练:全面了解所在研究方向的历史和现状,判断不同时期的研究工作的好与不好。测试:实践法/类比法/组合法出的idea,判断自己的研究工作好与不好。 - 科研论文如何想到不错的idea?
模块化学习、交叉、布局可预期的趋势。 - 人在年轻的时候,最核心的能力是什么?
核心点:达到以前从未达到的高度:基本的事情做到极致、专注、坚持长久做一件事、延迟满足、认清自己+了解环境->准确定位、
Choses à noter
- 领域点-线-面体系:点:自己focus的领域;线:上游和下游;面:大领域。不要过度focus在自己工作的领域,要有全局化的眼光,特别是自己的上游和下游。
- 日常学习点-线-面体系:点:自己focus的安全数据分析领域;线:安全/数据分析;面:全局安全内容/行业发展/职业规划。 Study a small field for at least one hour every day; read intensively for at least half an hour every day/at least one quality article on security/data analysis/industry development/career planning; browse a large number of incremental articles/stock articles tous les jours.保持学习与思考的敏感性。
appendice
国外优质技术站点
- https://resources.distilnetworks.com
站点概况:专注于机器流量对抗与缓解。 - http://www.covert.io
技术栈:Jason Trost,专注于安全研究、大数据、云计算、机器学习,即安全数据科学。 - http://cyberdatascientist.com
站点概括:专注于安全数据科学,提供网络安全、统计学和AI等学习资料,并提供14个安全数据集,包括:垃圾邮件、恶意网站、恶意软件、Botnet等。没有secrepo.com提供的资料全面。 - https://towardsdatascience.com
站点概括:专注于数据科学。
国内优秀技术人
- michael282694
技术栈:数据分析挖掘产品开发、爬虫、Java、Python。 - LittleHann
技术栈:我也不知道该怎么描述,Han师傅会的太多了,C++、Java、Python、PHP、Web安全、系统安全,不过目前好像做算法多一些。 - FeeiCN
技术栈:专注自动化漏洞发现和入侵检测防御。 - xiaojunjie
技术栈:专注于代码审计、CTF。 - 云雷
技术栈:阿里云存储技术专家,专注于日志分析与业务,日志计算驱动业务增长。 - iami
技术栈:主要研究Web安全、机器学习,喜欢Python和Go。一直偷学师傅的博客。 - cdxy
技术栈:早先主要做Web安全,CTF,代码审计,现在主要做安全研究与数据分析,初步估算技术领先我1~2年,师傅别学了。 - csuldw
技术栈:专注于机器学习、数据挖掘、人工智能。 - molunerfinn
技术栈:专注于前端,北邮大佬,和404notfound同级。 - 刘建平Pinard
技术栈:机器学习、深度学习、强化学习、自然语言处理、数学统计学、大数据挖掘,相关tutorial非常棒。
abandonné
- Efficient and Flexible Discovery of PHP Vulnerability译文
- Efficient and Flexible Discovery of PHP Application Vulnerabilities原文
- The Code Analysis Platform "Octopus"
- A Code Intelligence System:The Octopus Platform


